-
-

Chrome extension UI
-
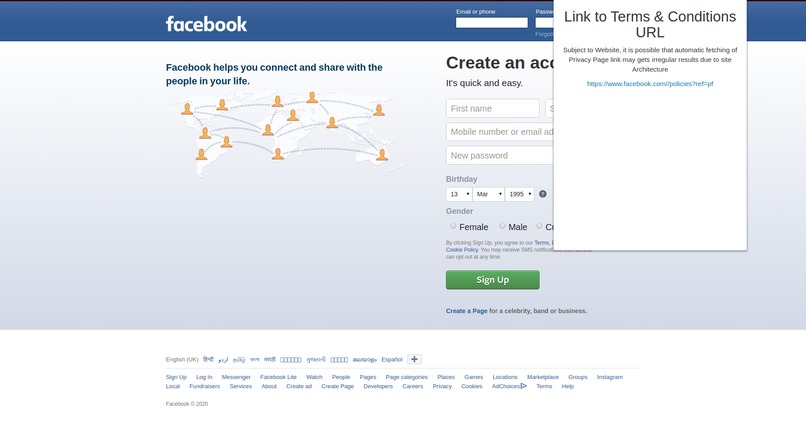
Found FB policy link
-
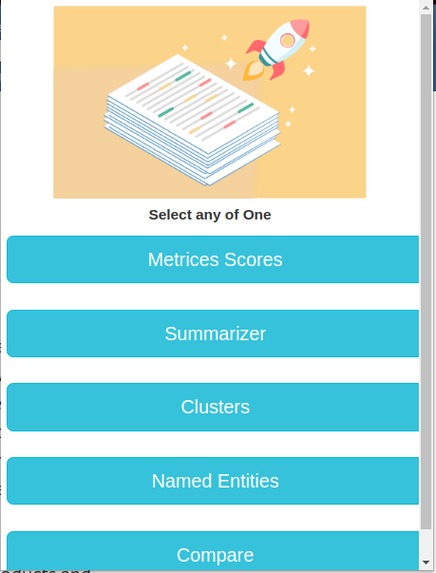
Extension List
-
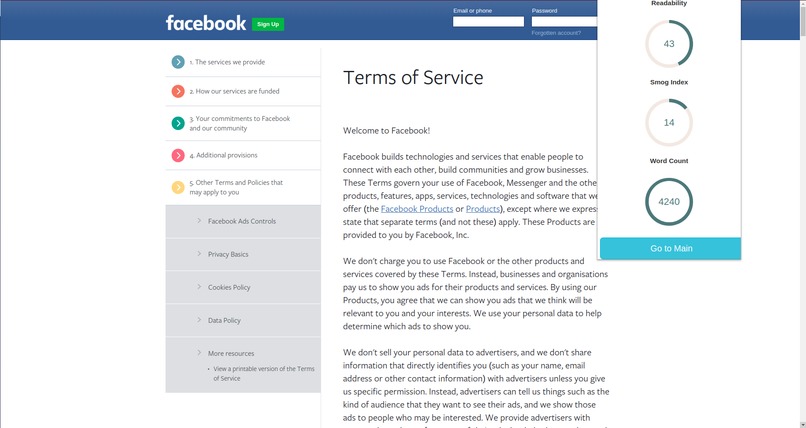
Readability Metrics
-
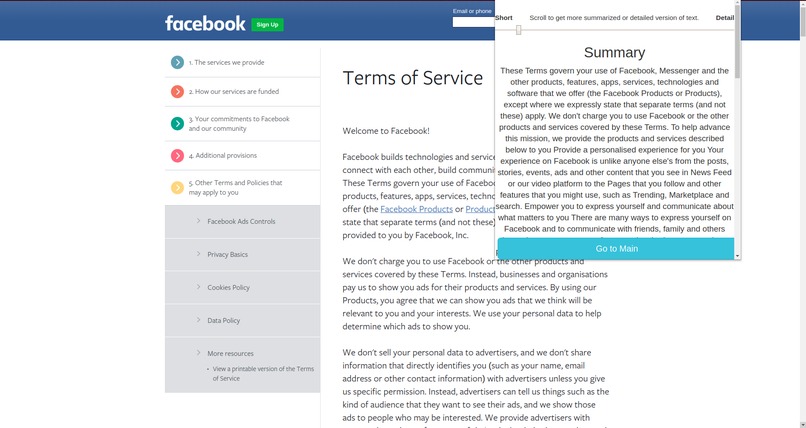
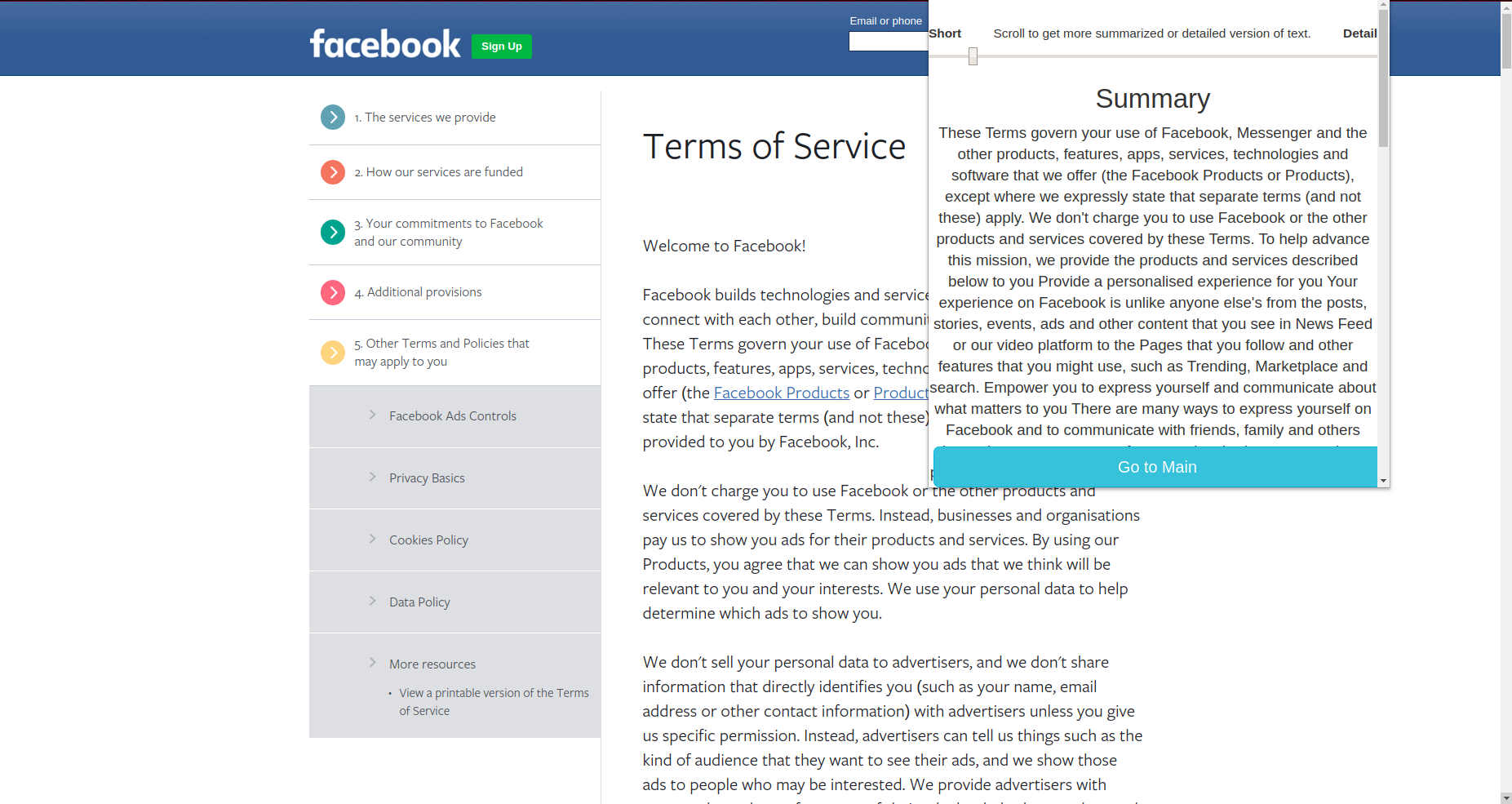
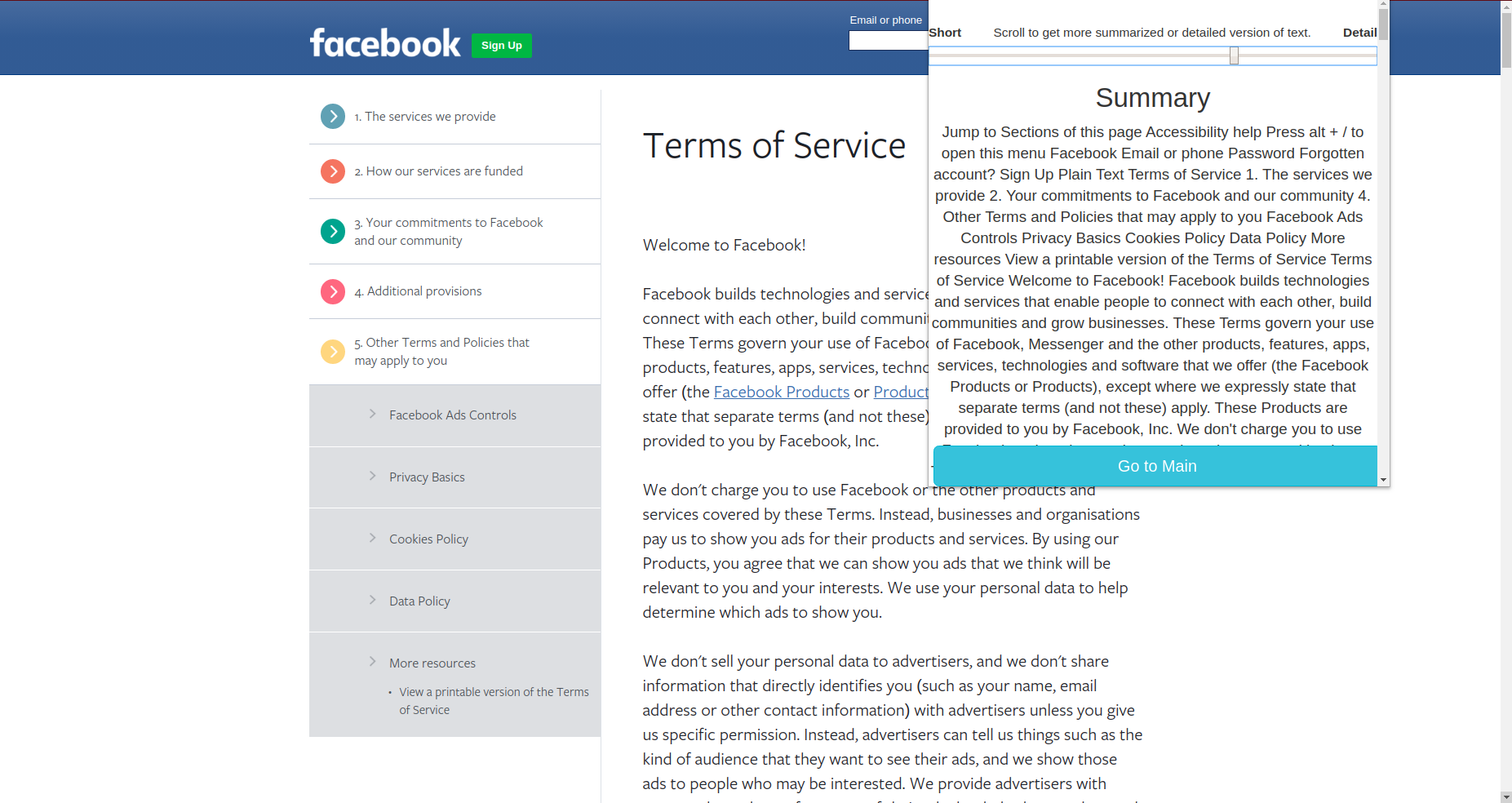
Short Summary
-
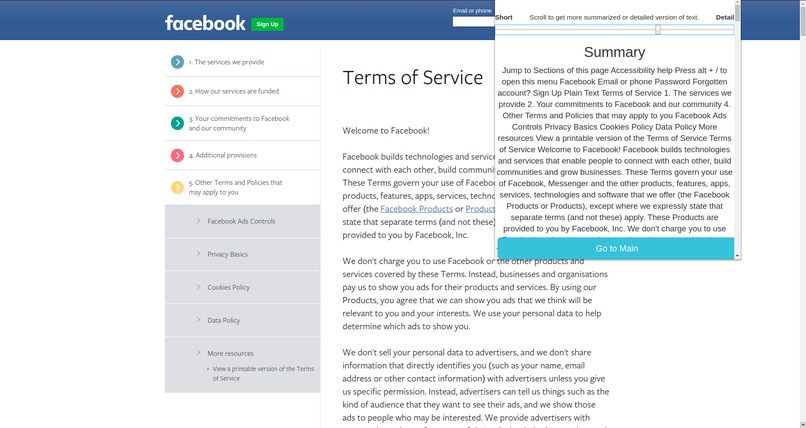
Detailed Summary
-
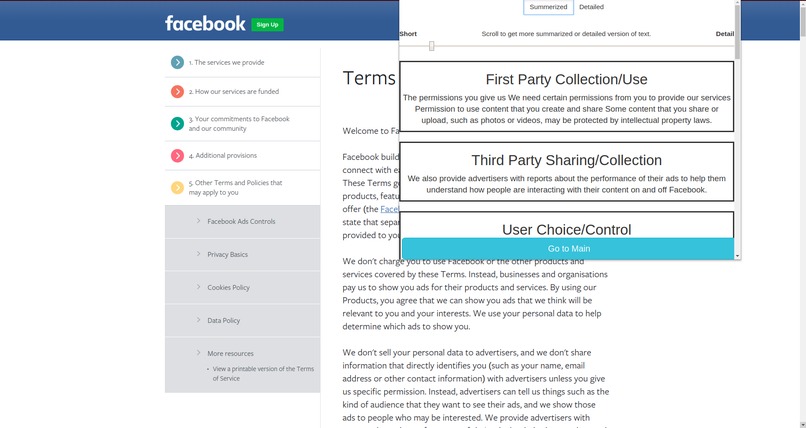
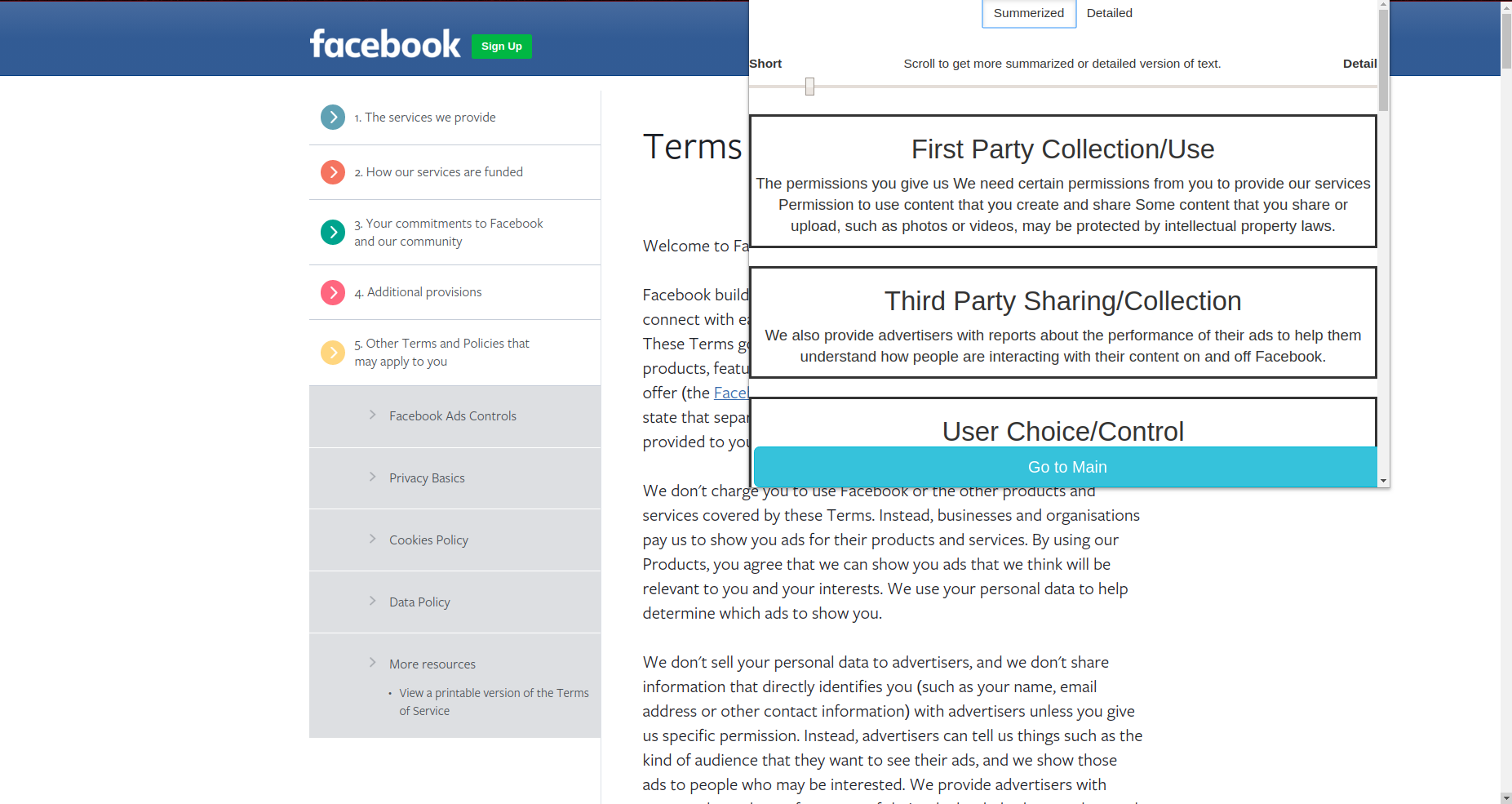
Clusters Summary (short)
-
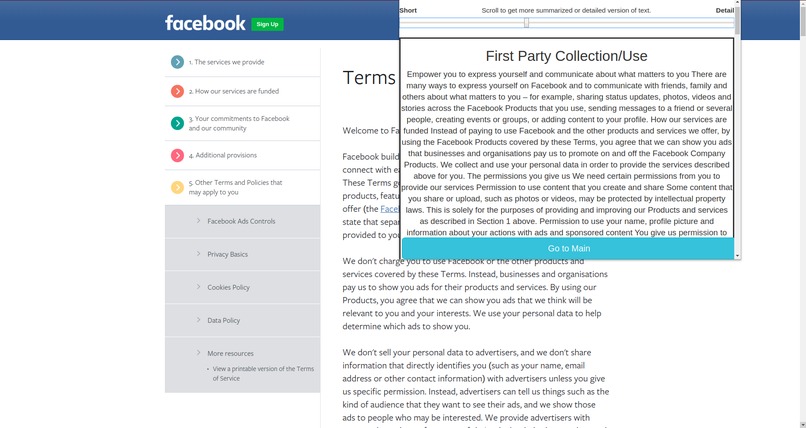
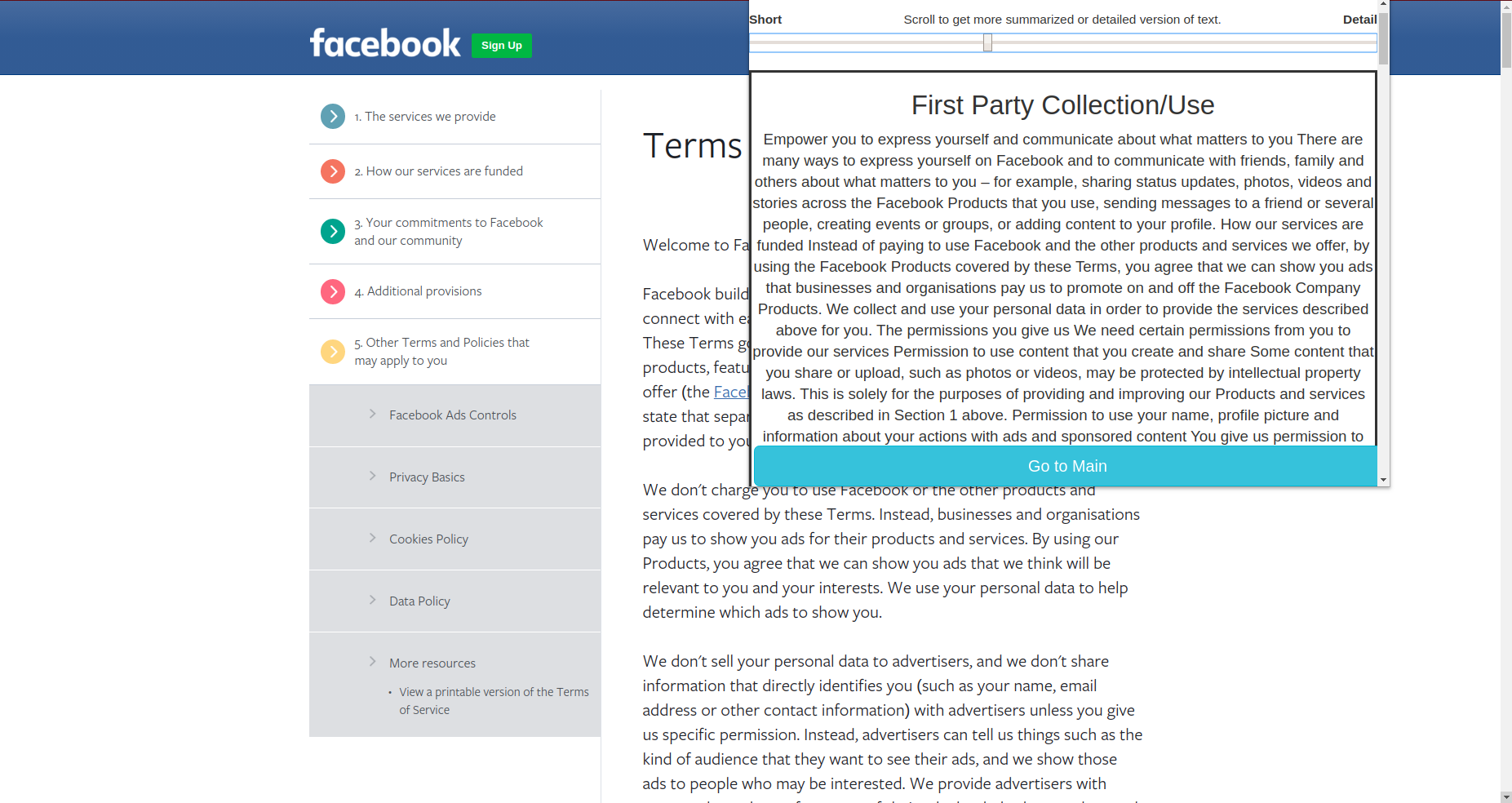
Clusters Summary (detailed)
-
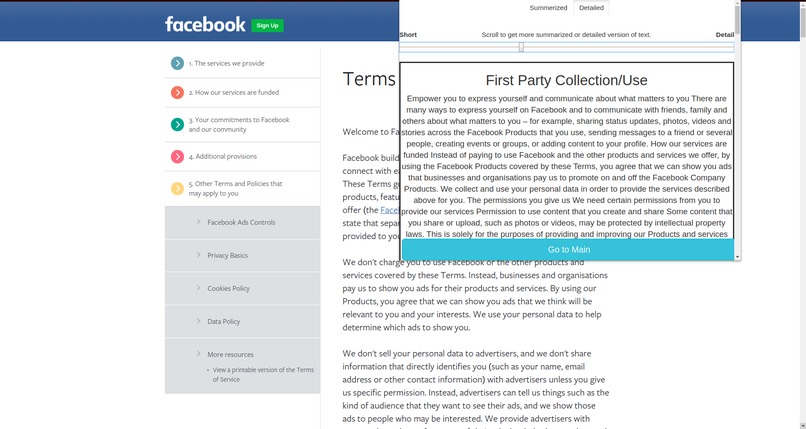
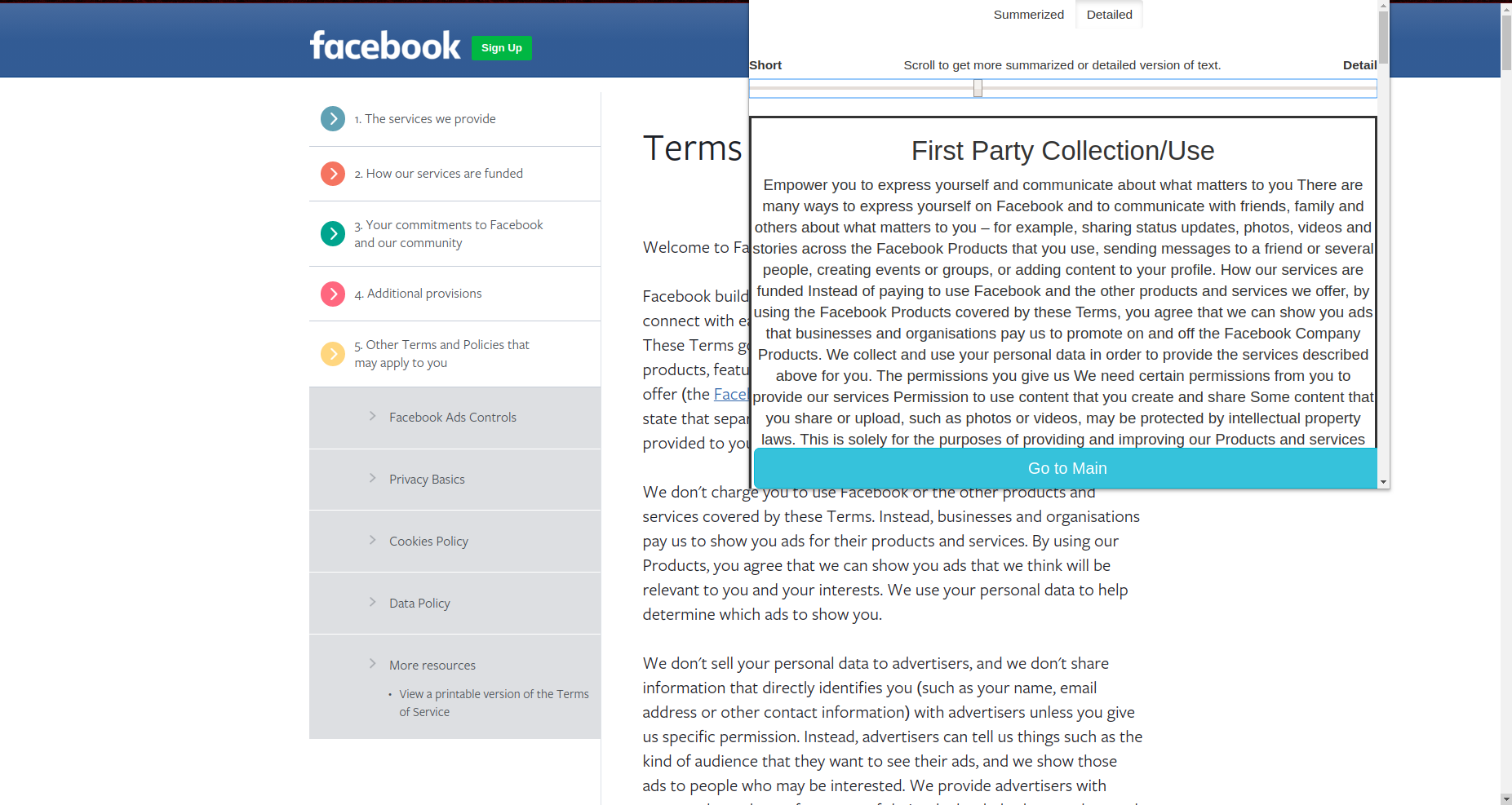
Clusters detailed
-
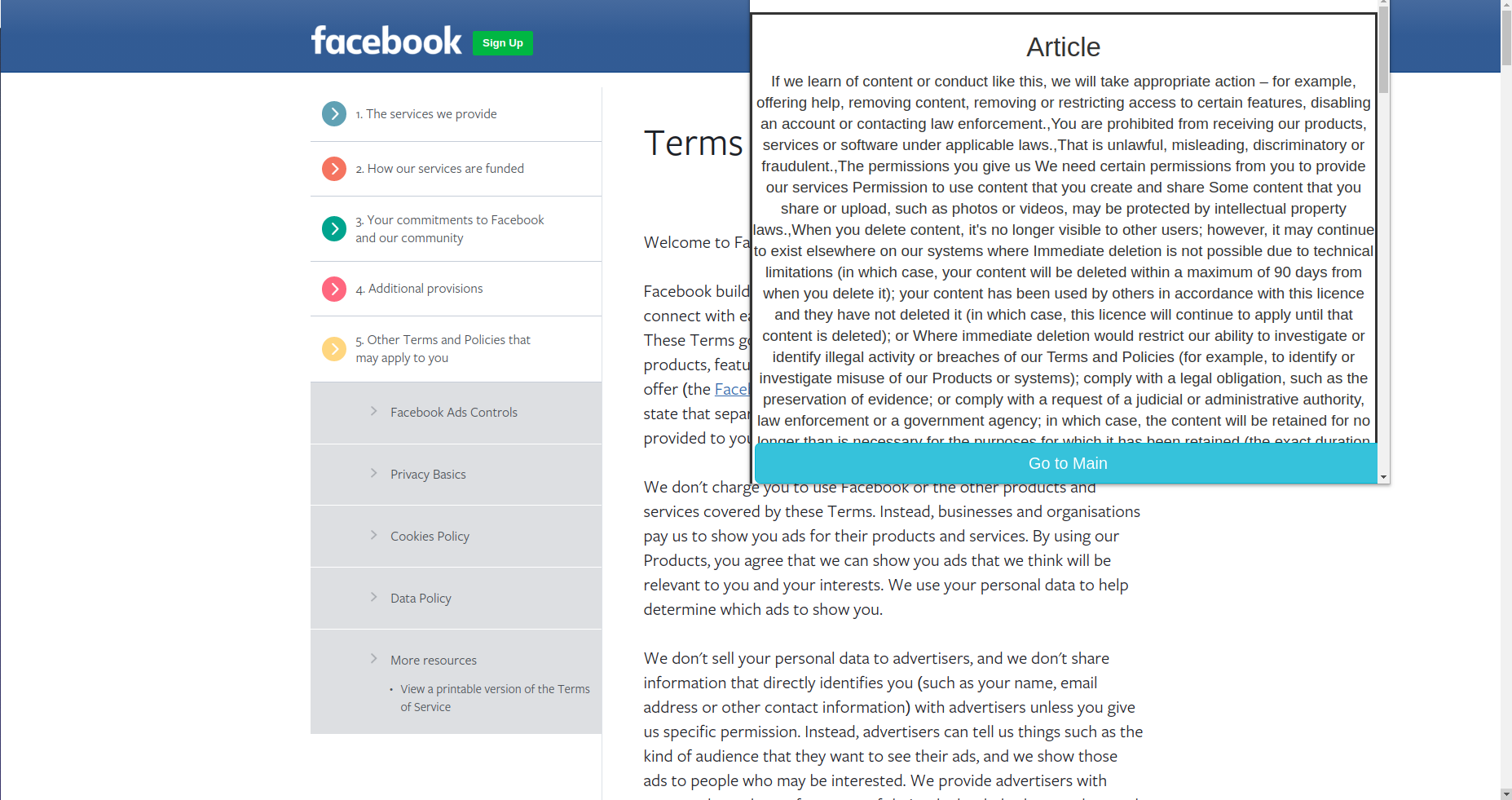
Entity Recogntion
-
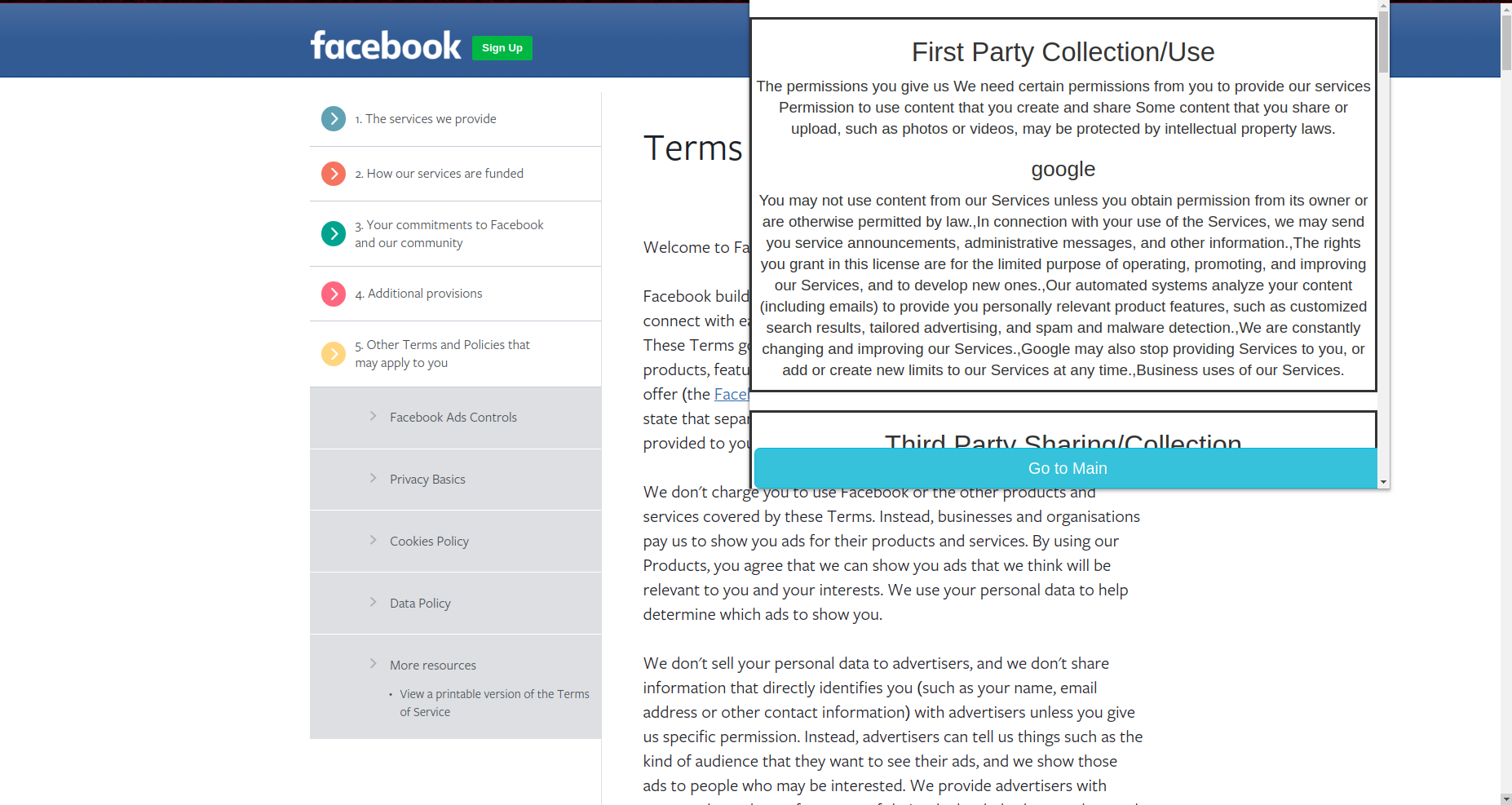
Comparison with Google
-
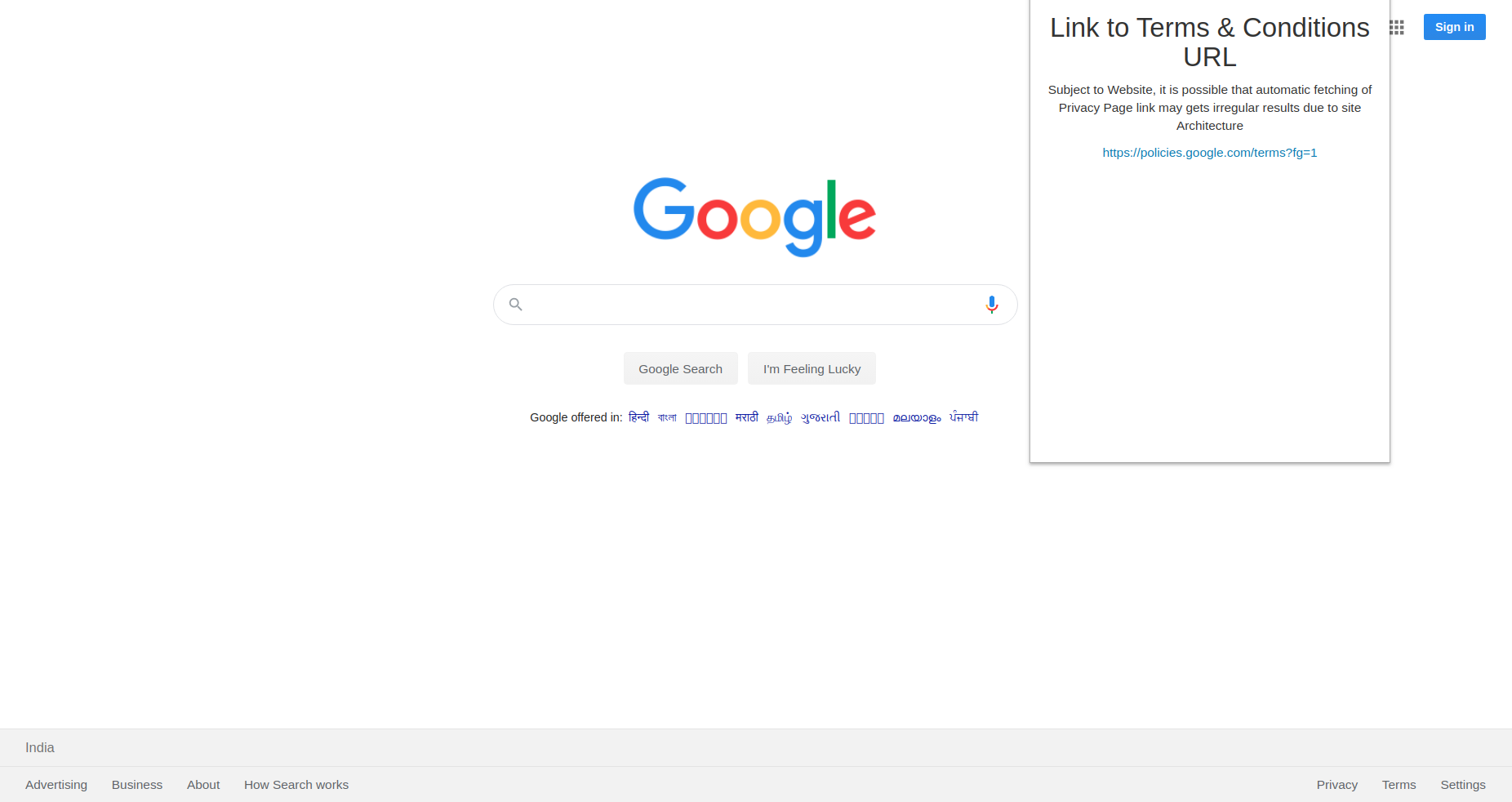
Google Policy link
-
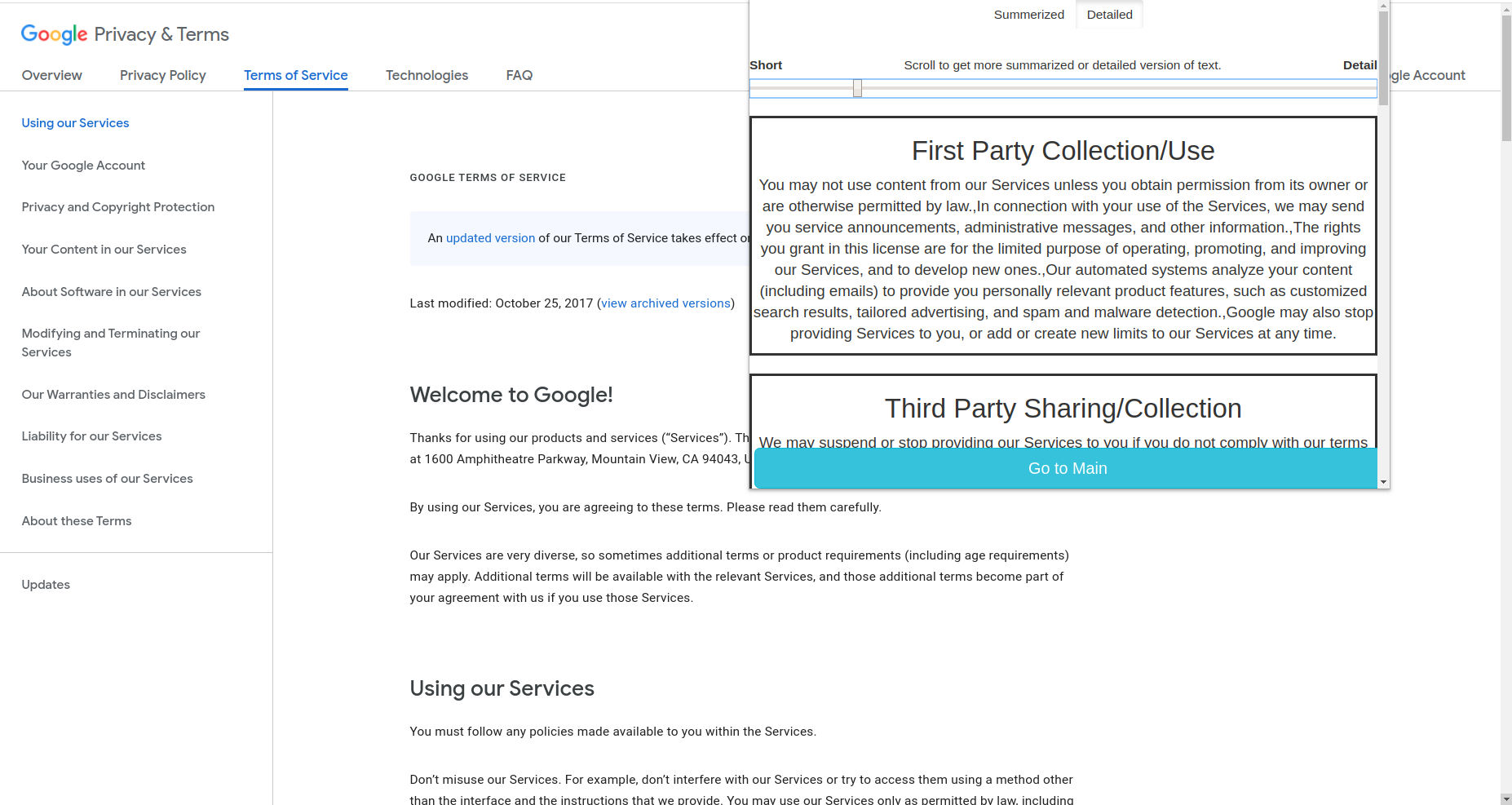
Google Policy analysis
-
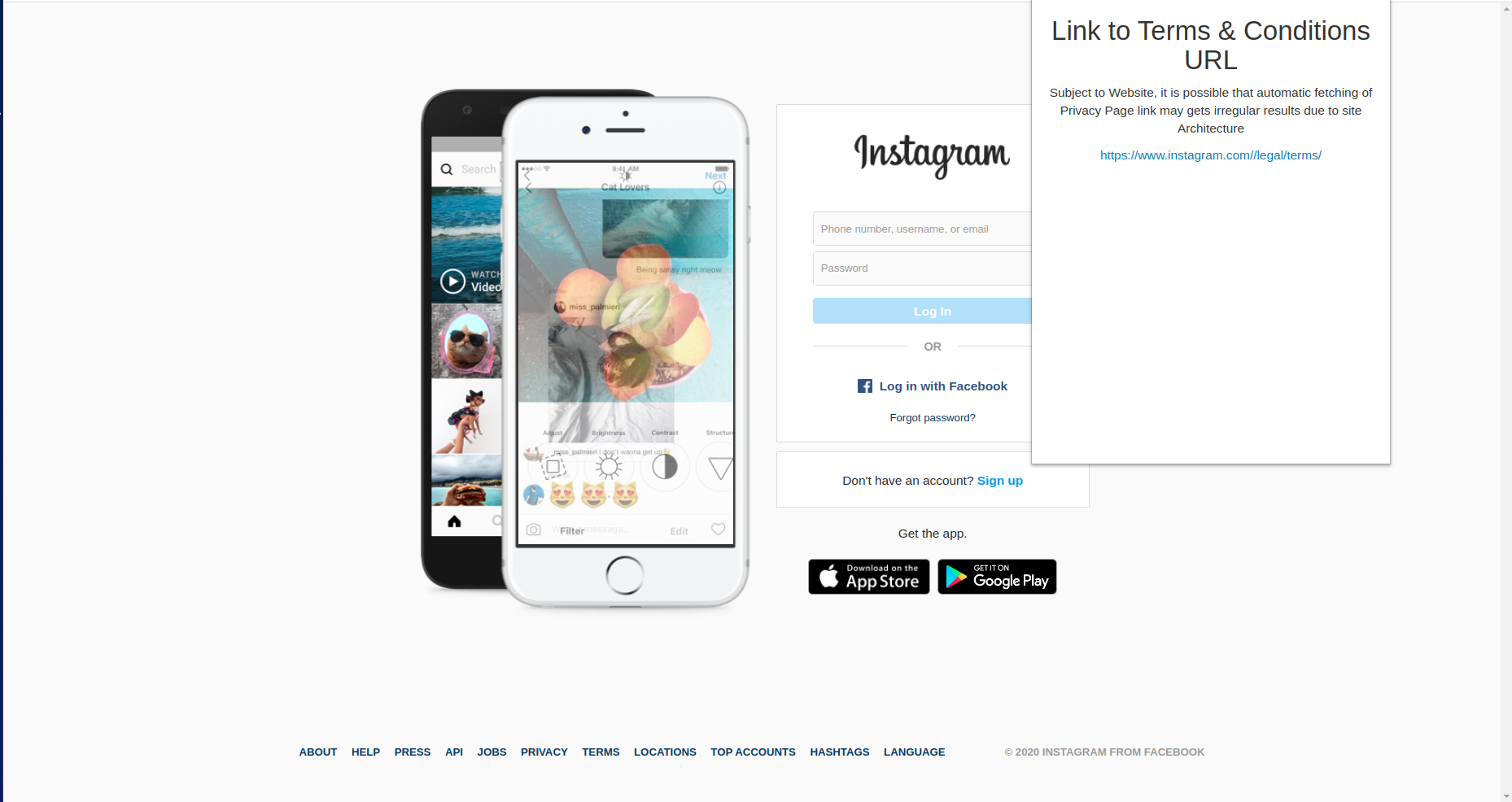
Instagram Policy Link
-
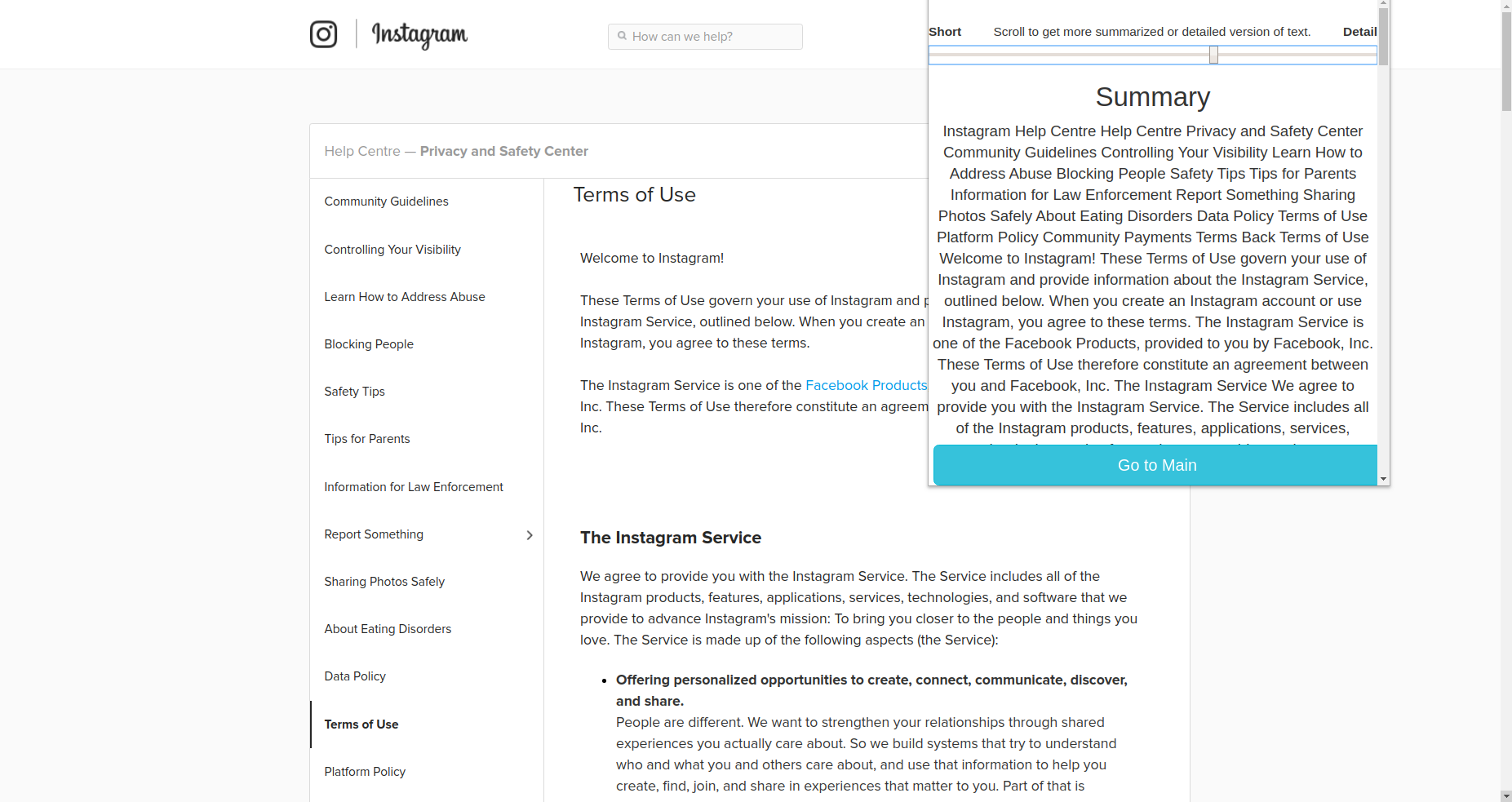
Instagram Policy analysis
-
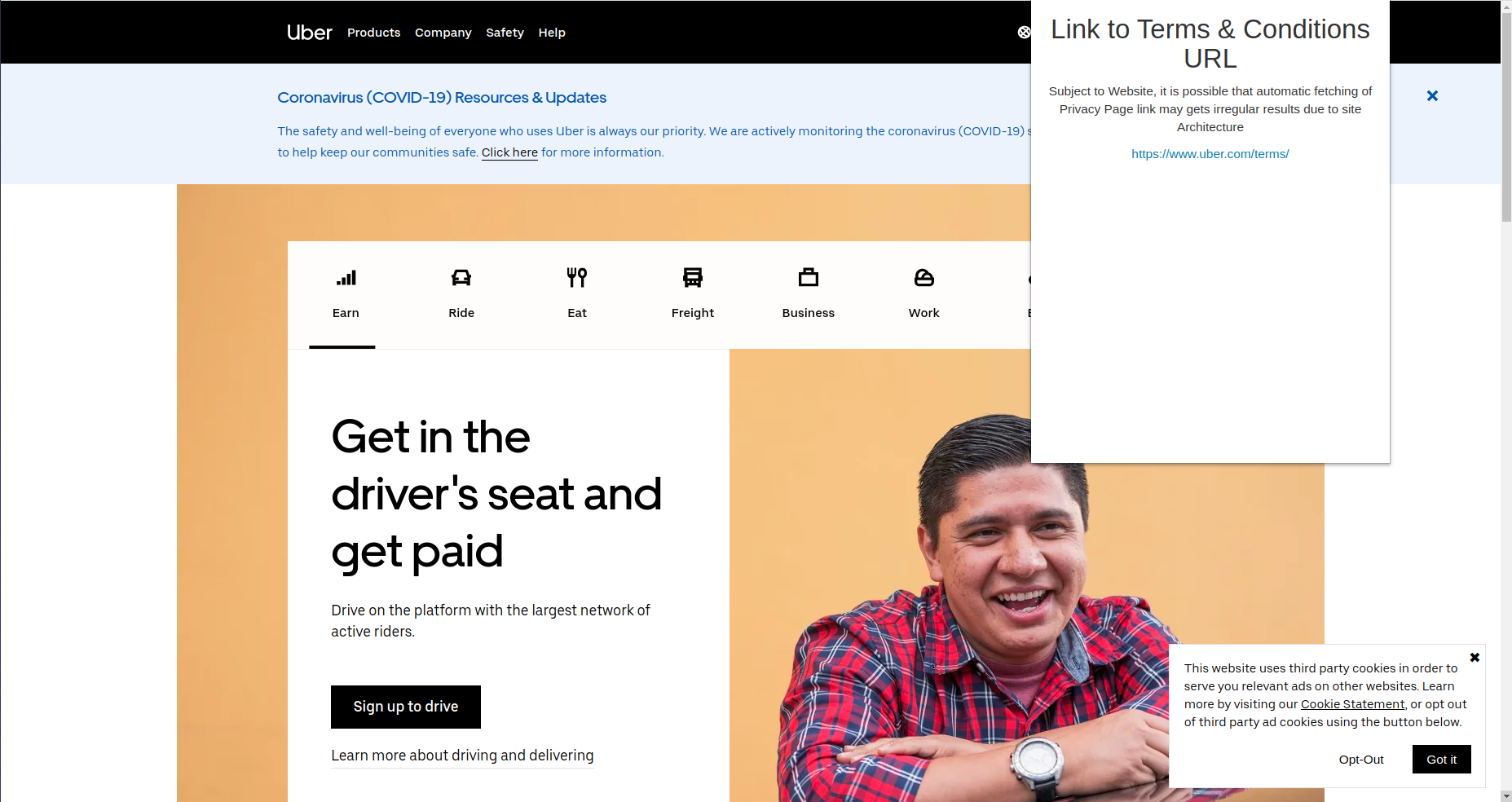
Uber Policy Link
-
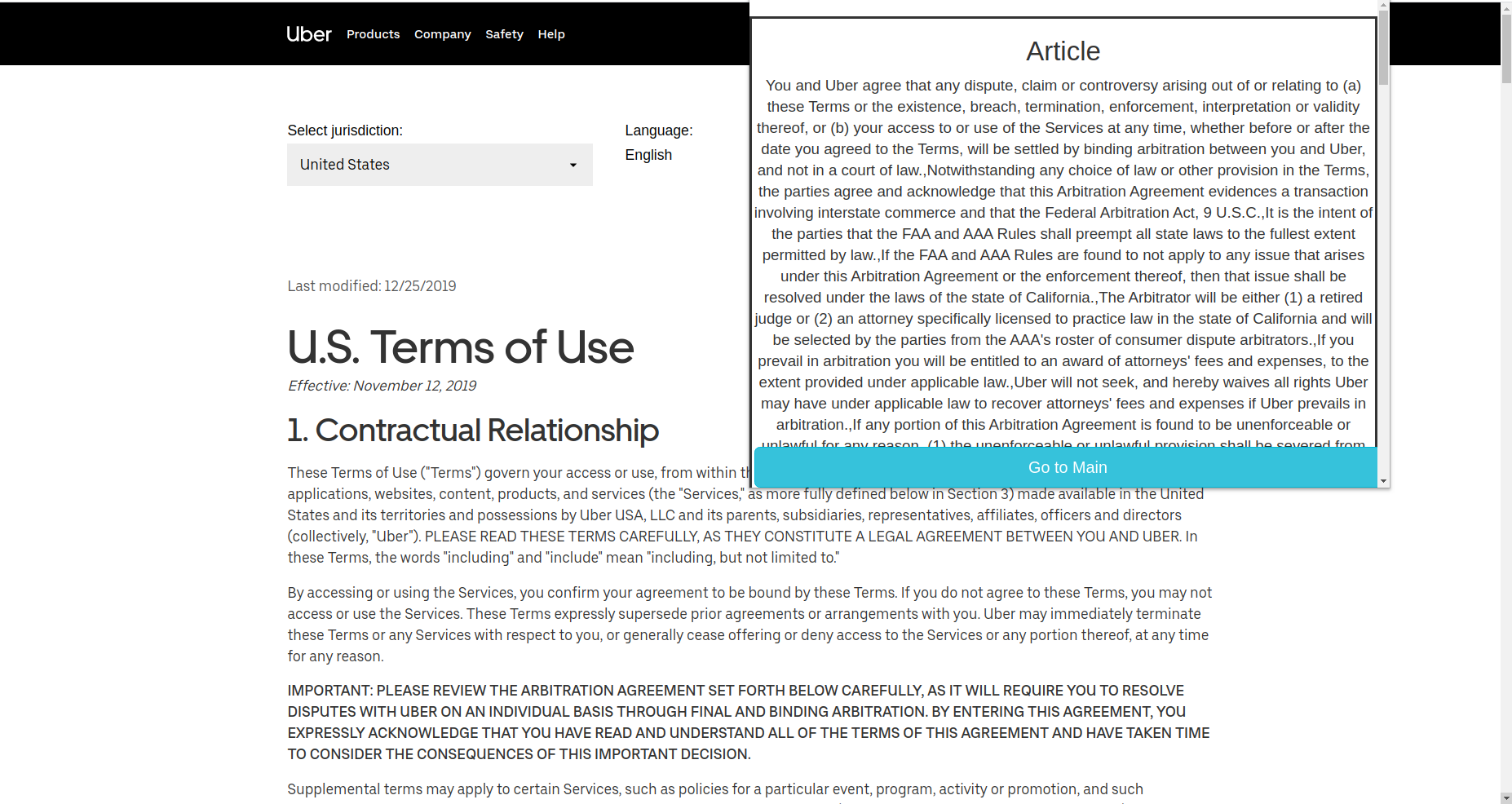
Uber Policy analysis
-
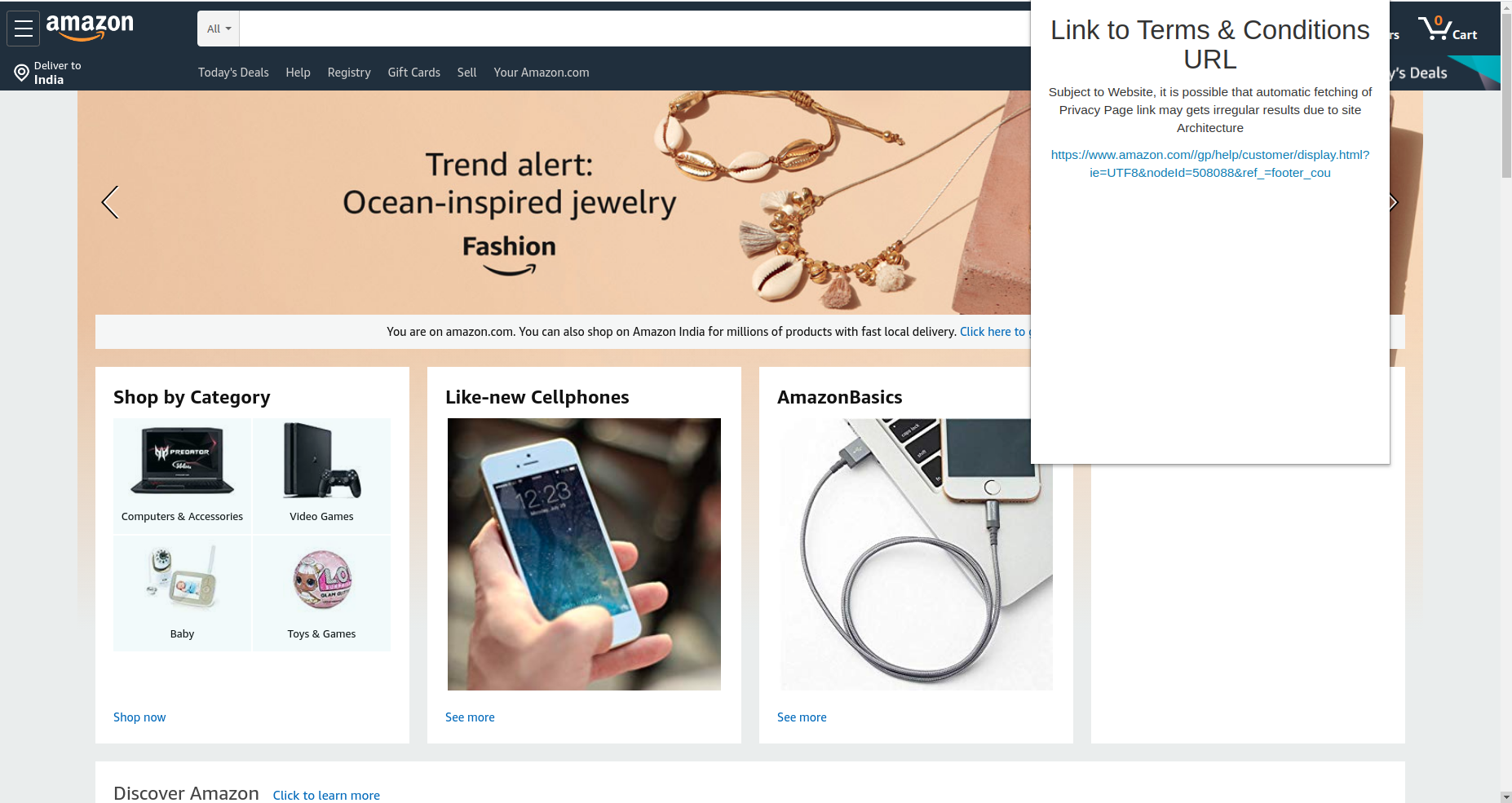
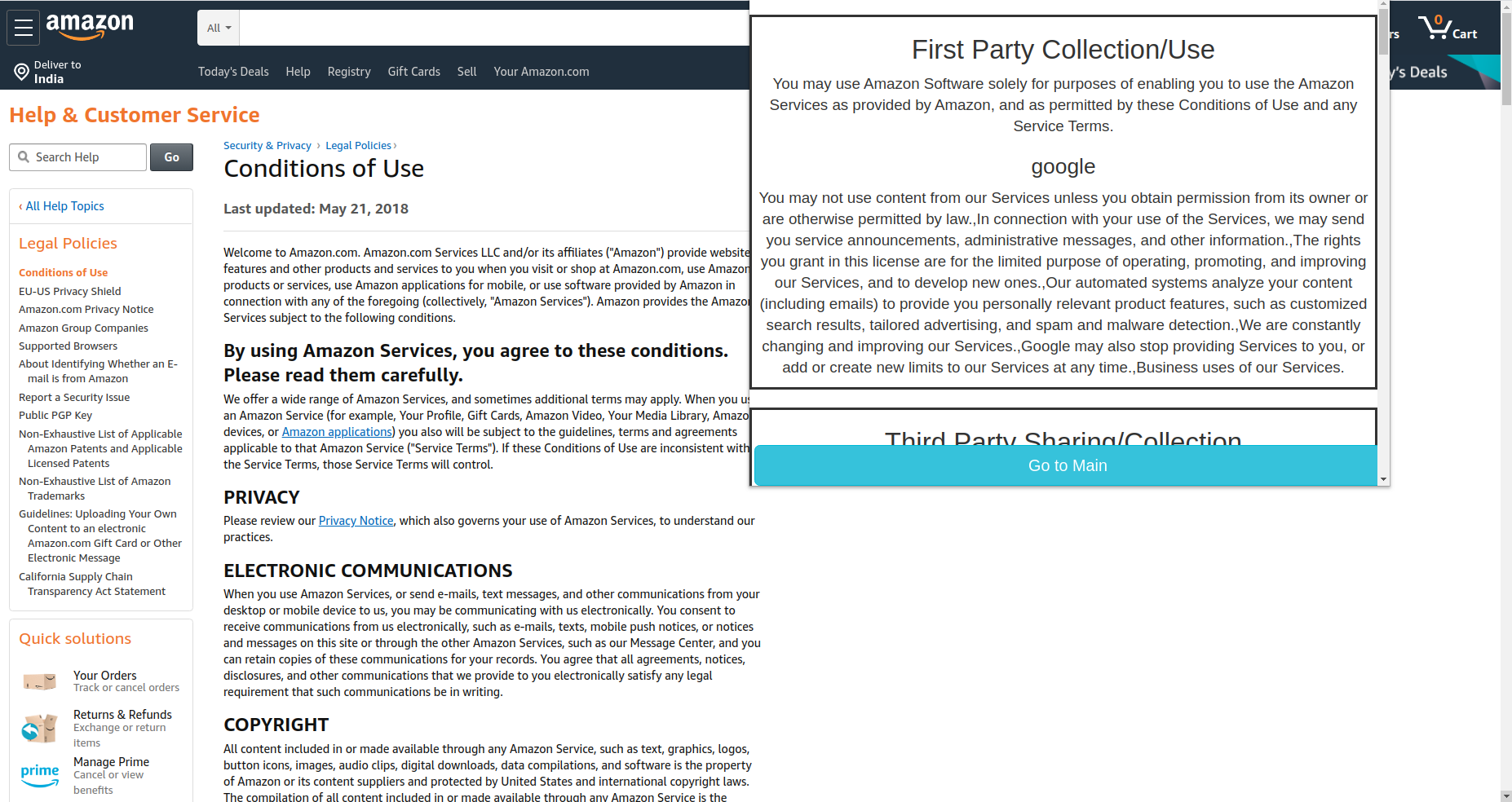
Amazon privacy policy
-
Amazon Privacy Policy analysis
-
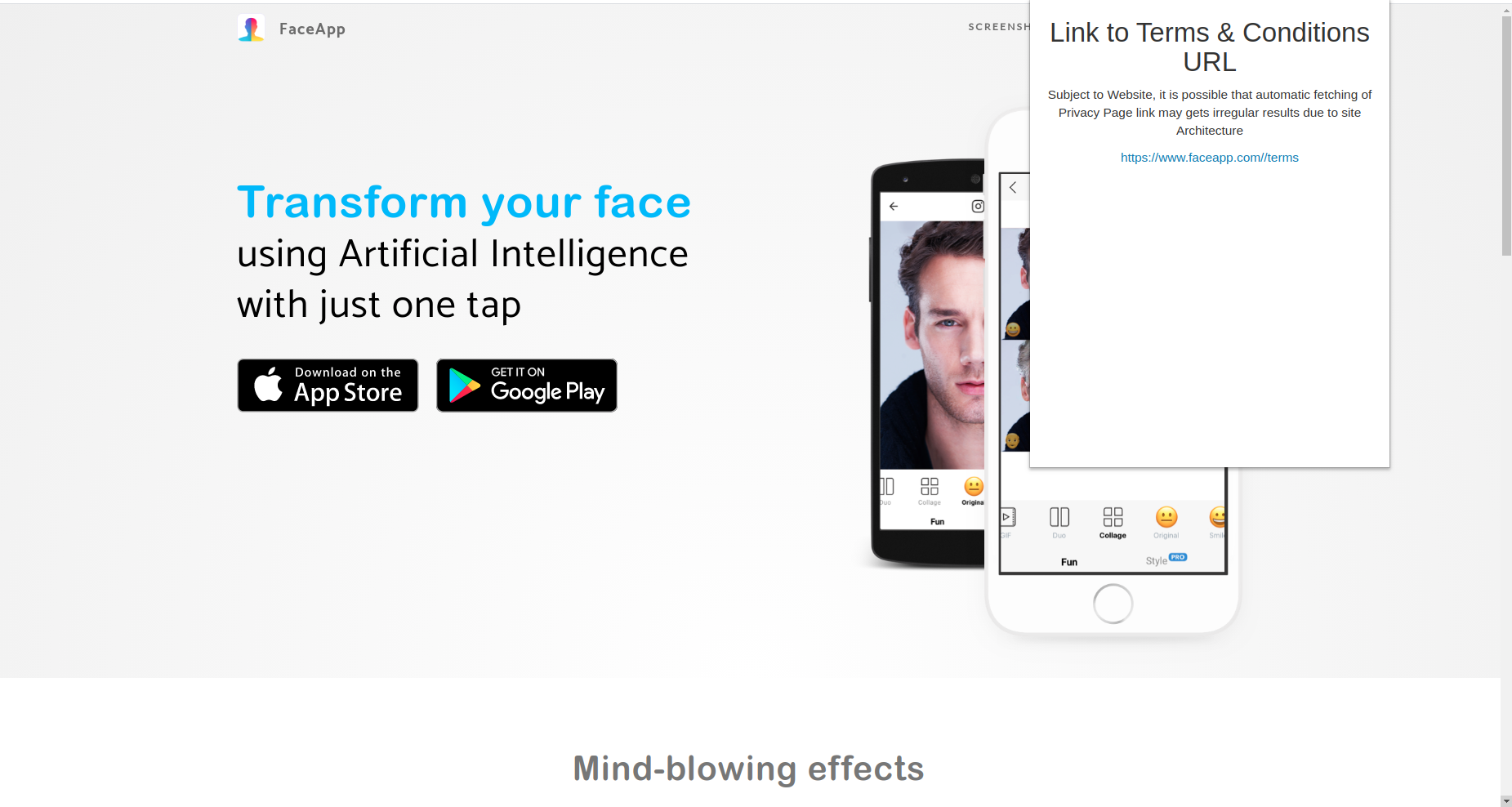
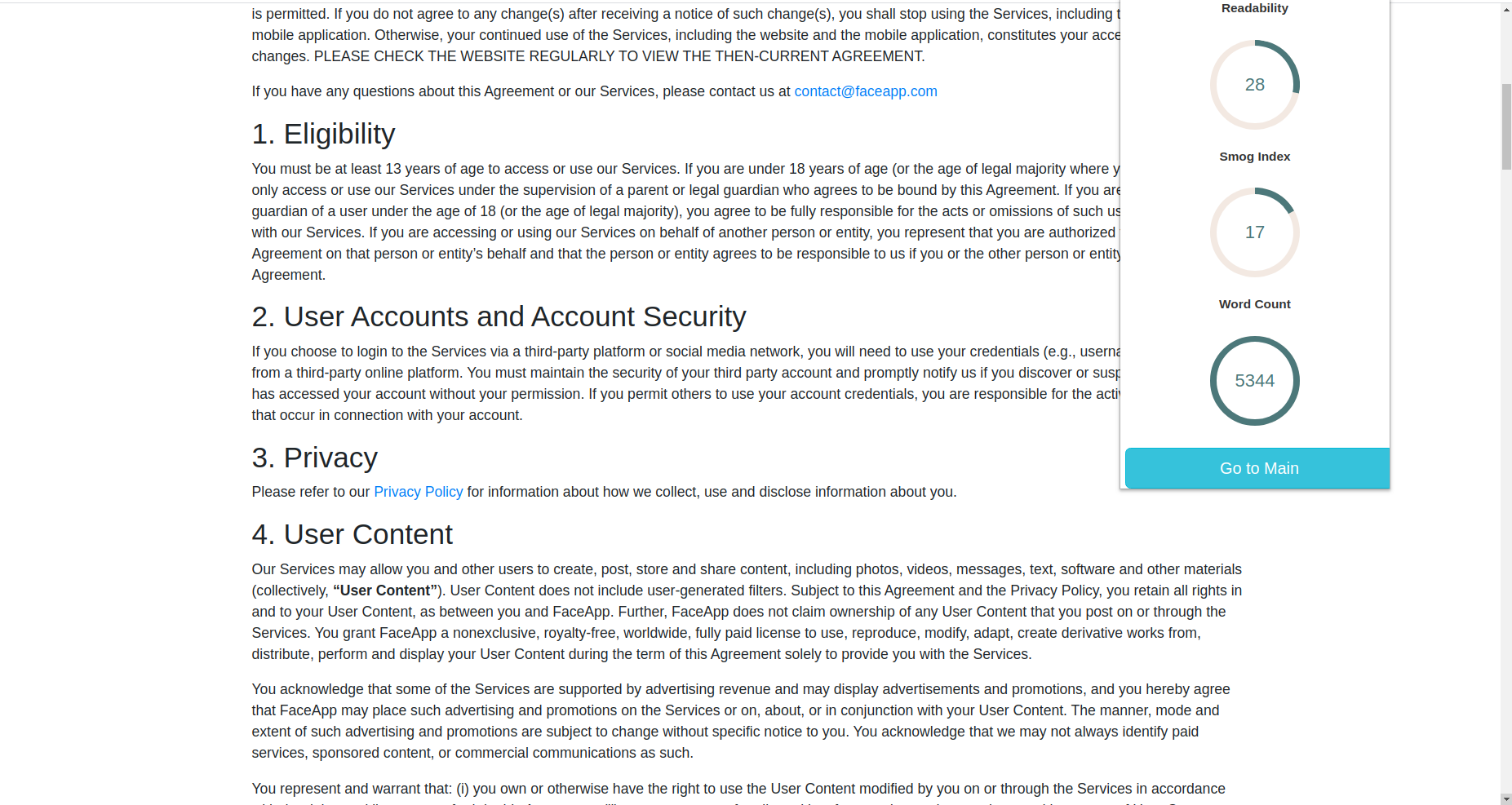
Faceapp privacy policy
-
Faceapp Privacy Policy analysis

Inspiration
Privacy is one of the top concerns of this decade. After multiple incidences, users are now more aware of their data. But what we, as a user, always forget or ignore the one thing which the organizations have for us. Those are Privacy Policies.
We ignore them and just accept them as it is without even going through the terms and conditions. Our human minds just go for the fruits instead of going through the "cost of the fruit". Most of us accept the terms without bothering to read the fine print. But with these contracts, there is a danger in clicking “agree” without reading or understanding them.
A survey conducted by Deloitte of 2000 customers in the US showed that 91% of people consent to legal terms and services conditions without reading them.
One of the recent cases include FaceApp that stored its users' uploaded photos. Users, without any hesitation, accepted the terms and conditions.
Also, in an experiment by Jonathan Obar and Anne Oeldorf-Hirsch at the University of Connecticut, they created a fake social networking website and the users, without reading the terms and conditions, agreed to give up their firstborn child and the NSA will be informed of the things which they share.
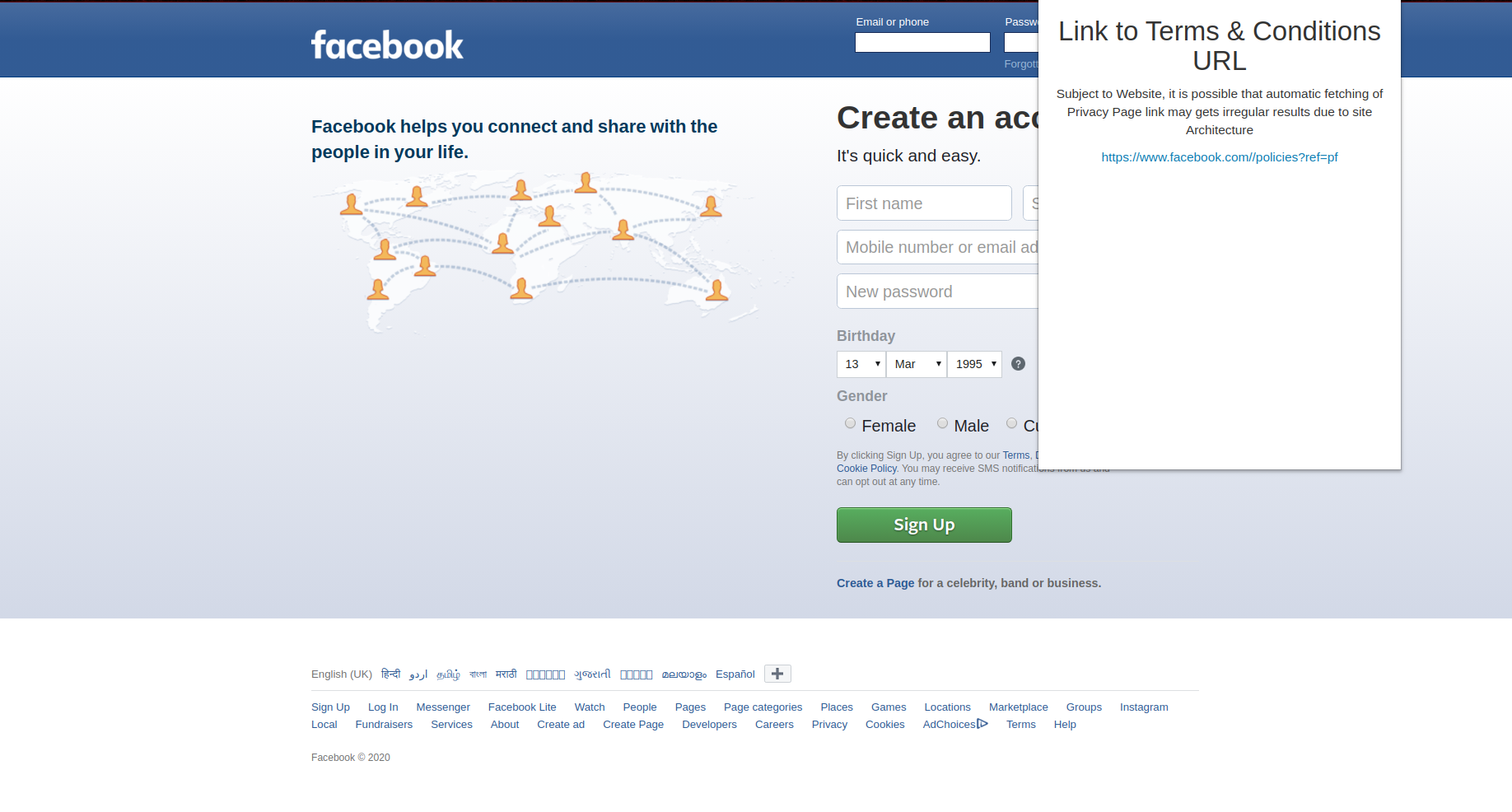
To solve this issue and for the user to know what they are dealing with, we introduce you to Priv. Here your privacy is simplified.
What it does
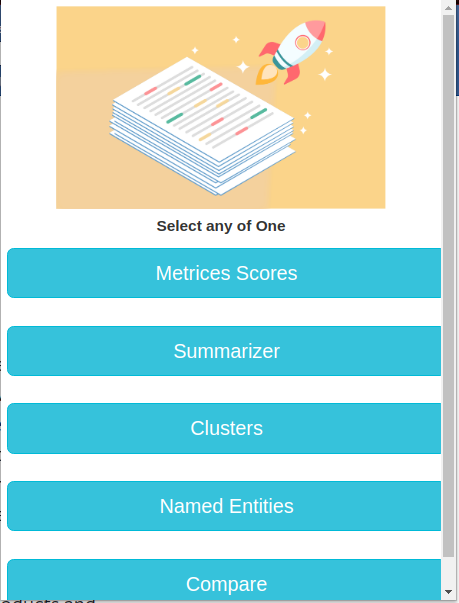
Priv is a Chrome Extension that provides the user the ability to categorize, summarize, understand and compare Privacy Policies. It has a simple User Interface that gives the user the power to understand the critical aspect of privacy policies. They can select how much granularity they want in their summary or they can go for detailed one too.
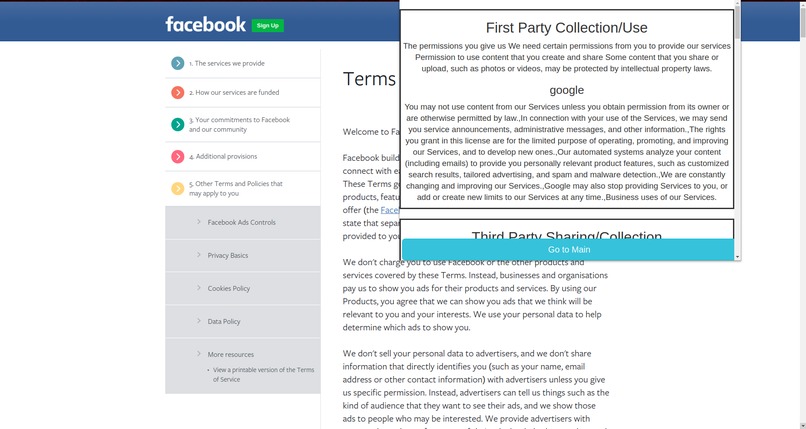
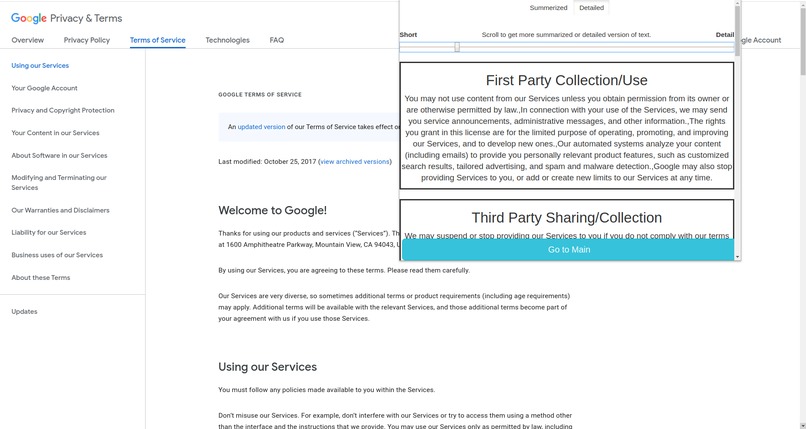
We divided the privacy policy into 10 parts or clusters. They are as follows -
- First Party Collection/Use
- Third-Party Sharing/Collection
- User Choice Control
- Data Security
- International and Specific Audiences
- User Access, Edit, and Deletion
- Policy Change
- Data Retention
- Do not track
- Others
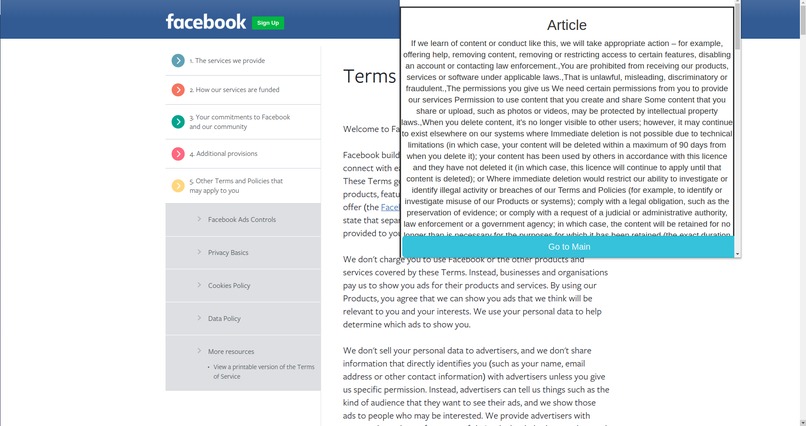
This allows users to focus on certain topics in a proper manner. To further understand and capture the multidimensionality of the policies, we made use of Named Entity Recognition which was custom made for law and policies. We divided it into 4 parts -
- Article
- Court
- Legality
- Activity
Priv also allows users to compare the websites' privacy policies. For comparison, we have added Facebook's, Google's, Amazon's and Youtube's privacy policies with other websites. This allows users to compare how organizations use or collect their data.
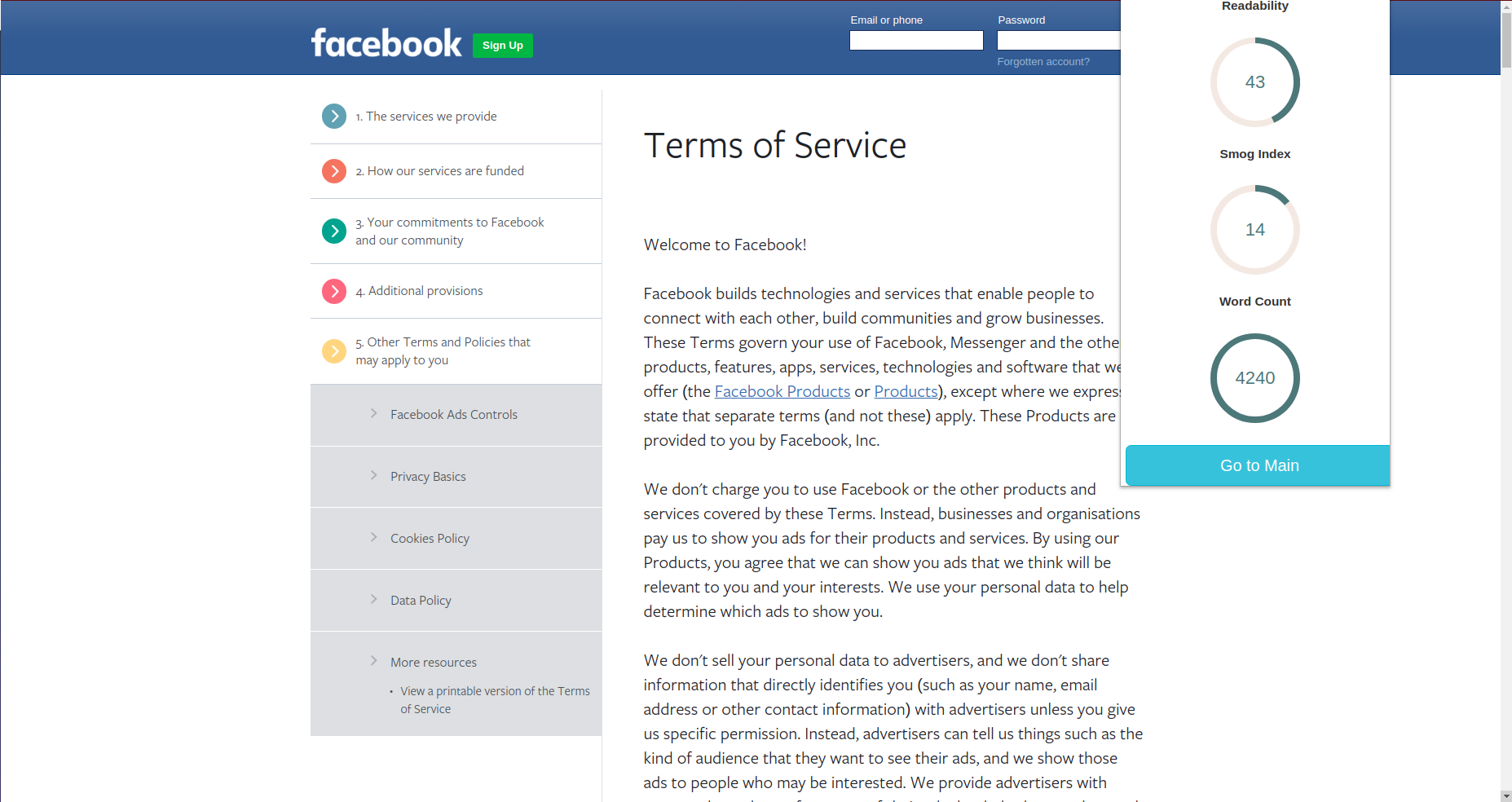
It also provides users with Readability metrics, word count and Smog index. Smog Index is a measure of readability that estimates the years of education needed to understand a piece of writing.
Pytorch is a very powerful tool with lots of flexibility and in this extension, it gives the power to the user to know what is happening with their privacy and it is an attempt to make internet more transparent to all.
How we built it
First of all, our backend was built using Pytorch. The important sentences are identified using TextRank summarization. We made use of Summa for this. For flexibility, in the Chrome Extension, we have given the user an option to control the granularity of the sumaary. We made use of Pytorch text classification with 1 embedding layer. Using a API, we communicate the backend results to the chrome extension. The creation of pipeline was one of the most important task. We had to fine tune our model to understand terms based on policies and train them accordingly.
Readability and complexity scores of the document are calculated and assigned using textstat library which uses the Flesch–Kincaid Grading method.
For the chrome extension, we found out all the <a> tags when the user clicks Find Link. Then we searched for terms like terms, conditions, privacy, legal, policy etc, and try to find the most apprpriate link. When a user clicks on it, they will get a new page of the Privacy Policy. Where they can summarize the data or visit other links accordingly.
Challenges we ran into
One of the challenges was to find the dataset for privacy policies and understanding them for each and every parameter. After that, cleaning of the data was the major part. The data and time being less, pushed us to test our limits with various methods.
Other challenges include the UI and building of the extension. We learnt and studied how to build extensions as we were new to it and also learned how to connect it with out model using API. We tested out first with some temporary placeholder APIs and learnt on the way.
Accomplishments that we're proud of
The possibilities it addresses and the power it brings to a user which makes them aware of their data and its usage. This is a baby step to ensure that users know what they are signing up for and what they are doing with their data.
How to run it
Priv is divided into 2 parts-
Backend
- Install Pytorch and select how you want to install it.
pip install summapip install textstatpip install torchtextorpip install torchtext --upgradepip install nltkpip install flaskpip install flask-corspip install flask_restplus- Visit the
Priv-backendfolder and runexport FLASK_APP=Server. - After this, run
flask run -h localhost -p 5000.
Our OS was Ubuntu 18.04 and Python version was 3.6.10
Chrome Extension
- Go to
Settingsin Google Chrome. This can be found in the right hand corner where there are 3 vertical dots. - Select
Extensionsfrom left hand pane. - Click on
Load unpackedand select the folderPriv-extension.
You are good to go after this.
What we learned
Integrating a machine learning model in a real-life situation with a chrome extension. Thanks to Pytorch documentation and tutorials for making it easier to adapt and learn. Also, learning about how to optimize and decrease the fetching time for real-time usage.
What's next for Priv
Making it public for on the Chrome extension store and Firefox extension store. Incremental upgrades regarding scalability are also on our minds rearding its expanditure to handle different types of websites and better results and better granularity in Named Entity Recognition.
Built With
- api
- chrome
- extension
- html
- javascript
- natural-language-processing
- python
- pytorch
- readability-metrics
- summa
- torchtext






Log in or sign up for Devpost to join the conversation.