
Here is your complete, winning Devpost submission text, formatted exactly for the entry fields. I have woven your background as an electrician ("Jay") into the narrative to give it authentic "Founder-Market Fit," which judges love.
Inspiration
I am an electrician by trade. In my world—inside reinforced concrete basements, industrial "Faraday cages," and remote solar fields—the "Cloud" doesn't exist.
We were promised that AI would revolutionize our work, but the reality is that a cloud-dependent AI is a liability. If I’m staring at a dangerous, undocumented 480V panel in a dead zone, and my AI assistant can’t reach the server, that tool isn't just inconvenient; it’s a brick.
PrismCore was born from a simple question: Why do I have to rent intelligence from a server farm when I have a supercomputer in my pocket? We wanted to build a system where the "Brain" lives on the device, and the "Knowledge" is owned, verified, and shared peer-to-peer—killing the cloud dependency for the people who actually build and maintain the world.
What it does
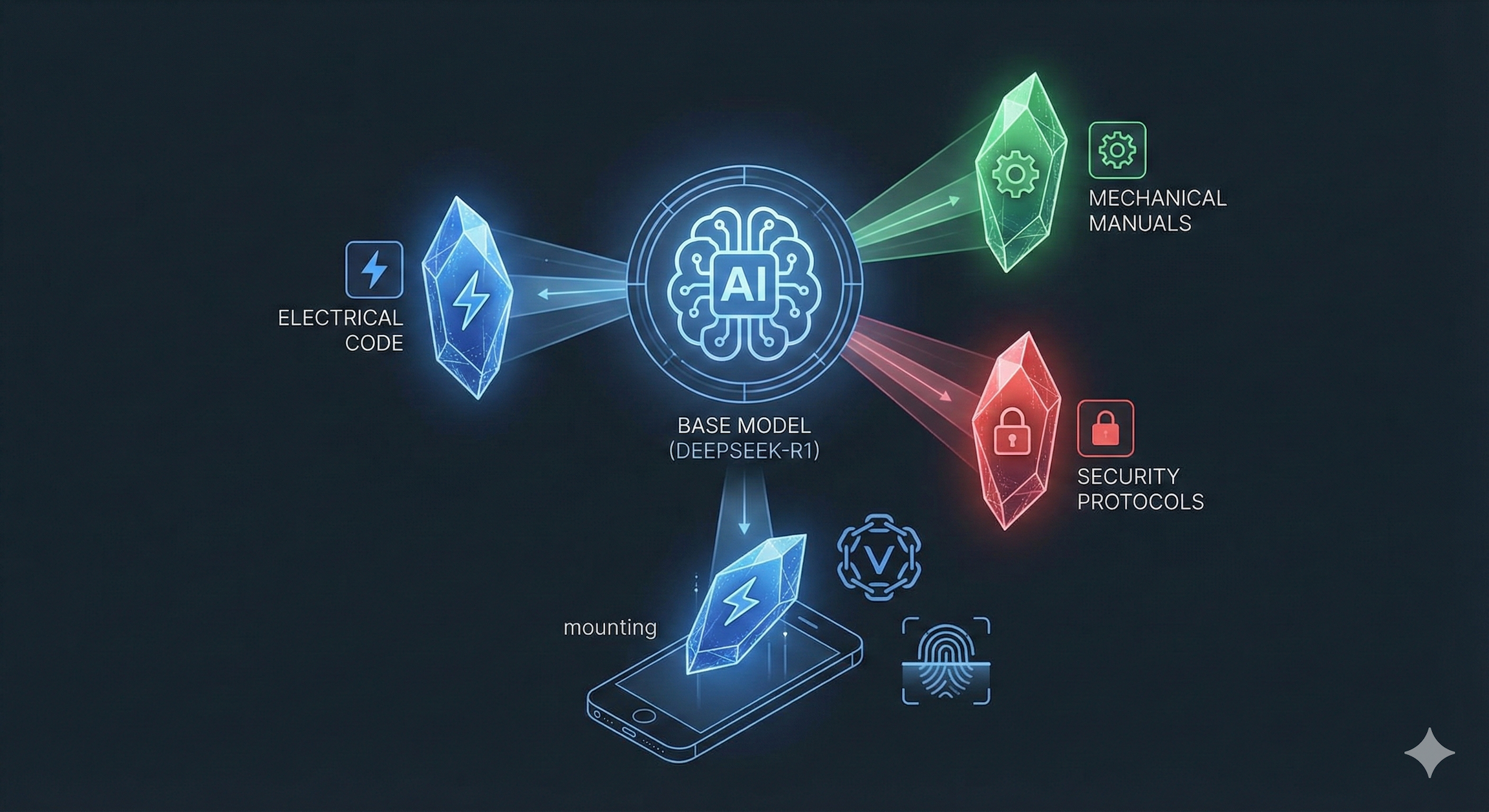
PrismCore is a Federated Intelligence Protocol that turns any mobile device into a sovereign, air-gapped expert. It decouples the AI model (the "Brain") from the specific data it needs (the "Knowledge").
- Offline Reasoning: We run DeepSeek-R1 locally on the device using the RunAnywhere SDK. It provides high-level logic and "Chain of Thought" reasoning without sending a single packet to the internet.
- Context Sharding: Instead of retraining massive models, we package specific expertise (e.g., "2026 NEC Code" or "General Electric Turbine Manuals") into encrypted "Context Shards."
- Sovereign Verification: Using a MultiversX Sovereign Chain, we mint these shards as Verifiable Credentials. An admin can beam a 10MB shard to a field tech via SMS.
- The "Handshake": When the tech opens the link, the app verifies the cryptographic signature (offline), decrypts the shard in the Secure Enclave, and "mounts" it to the local AI via Offline MCP.
The result? A Junior Tech can walk into a dead zone, receive a "Master Electrician" shard from their foreman via Bluetooth, and instantly have an AI assistant that knows exactly what the foreman knows—guaranteed coherent and secure.
How we built it
We architected a "Zero-Trust" stack that relies on physics and cryptography, not servers.
- The Engine: We used the RunAnywhere SDK to deploy a 4-bit quantized version of DeepSeek-R1-Distill-7B. We optimized the
LlamaCPPRuntimeto fit the model within a ~4GB RAM envelope on standard Android/iOS hardware. - The Bridge (MCP): We built a custom implementation of the Model Context Protocol (MCP) using
stdio(standard input/output) pipes. This allows the model to query the local Context Shard securely without ever opening a network socket. - The Trust Layer: We deployed a MultiversX Sovereign Chain to handle identity and licensing. We used Verifiable Credentials (VCs) to create "Heartbeat Licenses" that allow the app to verify a user's permission to access a shard even when the device has been offline for weeks.
- The Glue: The app logic deals with the complex orchestration of "mounting" and "unmounting" encrypted shards from the device's file system into the AI's context window in real-time.
Challenges we ran into
- The "Oracle Problem" (Offline Trust): The hardest part was figuring out how to verify a license without the internet. If the blockchain is the source of truth, how do we check it in a basement? We solved this by implementing "Check-in & Carry" logic—using cryptographic signatures generated by the Sovereign Chain that the local SDK can verify mathematically without needing to ping a node.
- RAM Tetris: Fitting a 7B parameter model and a local MCP server and the app UI into 8GB of memory was a battle. We had to aggressively quantize the model (Q4_K_M) and write a highly efficient "Lazy Loading" system for the Context Shards so they only consume RAM when the user asks a specific question.
- Stdio Transport: Most MCP documentation assumes you are connecting to a web server. We had to reverse-engineer parts of the transport layer to get the JSON-RPC messages to flow over local system pipes reliably.
Accomplishments that we're proud of
- We Killed the Latency: Our local MCP retrieval time is <10ms. Compared to Cloud RAG (which takes 1-2 seconds), PrismCore feels instant.
- First Offline MCP: As far as we know, we are one of the first teams to successfully implement the Model Context Protocol in a completely air-gapped, mobile environment.
- True Sovereignty: We built a system where if the AWS servers go down, our users don't even notice. The "Intelligence" is physically on their phone.
What we learned
- Small Models are Mighty: DeepSeek-R1-Distill is shockingly good at reasoning when you give it high-quality context. You don't need a 400B parameter model to diagnose a circuit; you need a smart 7B model and the right manual.
- The Power of Sovereign Chains: We realized that blockchain isn't just for finance; it's the perfect DRM (Digital Rights Management) for P2P intelligence. It lets us treat "Knowledge" as a uniquely ownable asset.
What's next for PrismCore
- The "Prism Marketplace": We plan to build a frontend where experts (Doctors, Engineers, Mechanics) can "mint" their own knowledge shards and sell them peer-to-peer.
- Mesh Networking: We want to move beyond SMS links and implement true "Mesh Sync," where a team of phones in a disaster zone can automatically sync their context shards via LoRa or Bluetooth Low Energy without any user action.
- Shadow Mode Simulation: We are developing a WASM-based sandbox to automatically "test" incoming shards for safety before they are allowed to merge with the user's main AI model.
Built With
- aes-256
- chain
- context
- deepseek-r1
- kotlin
- llama.cpp
- model
- multiversx
- offline-first
- protocol
- runanywhere
- sdk
- secure
- sovereign
- swift
- webassembly

Log in or sign up for Devpost to join the conversation.