-
-
HomePage
-
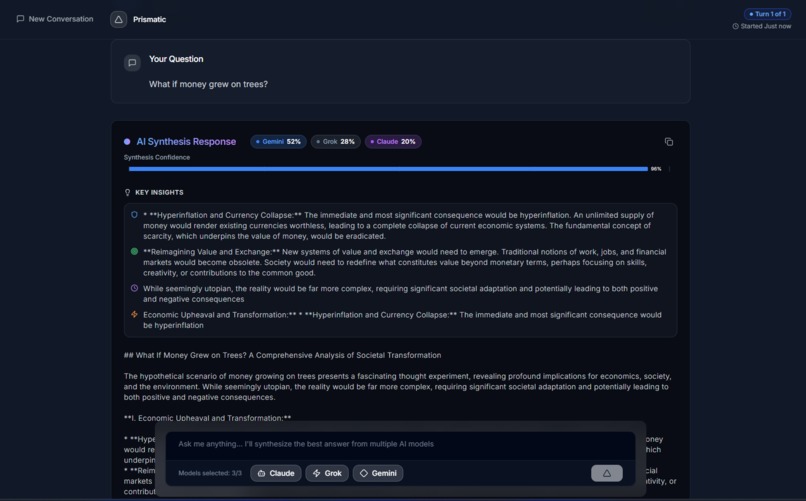
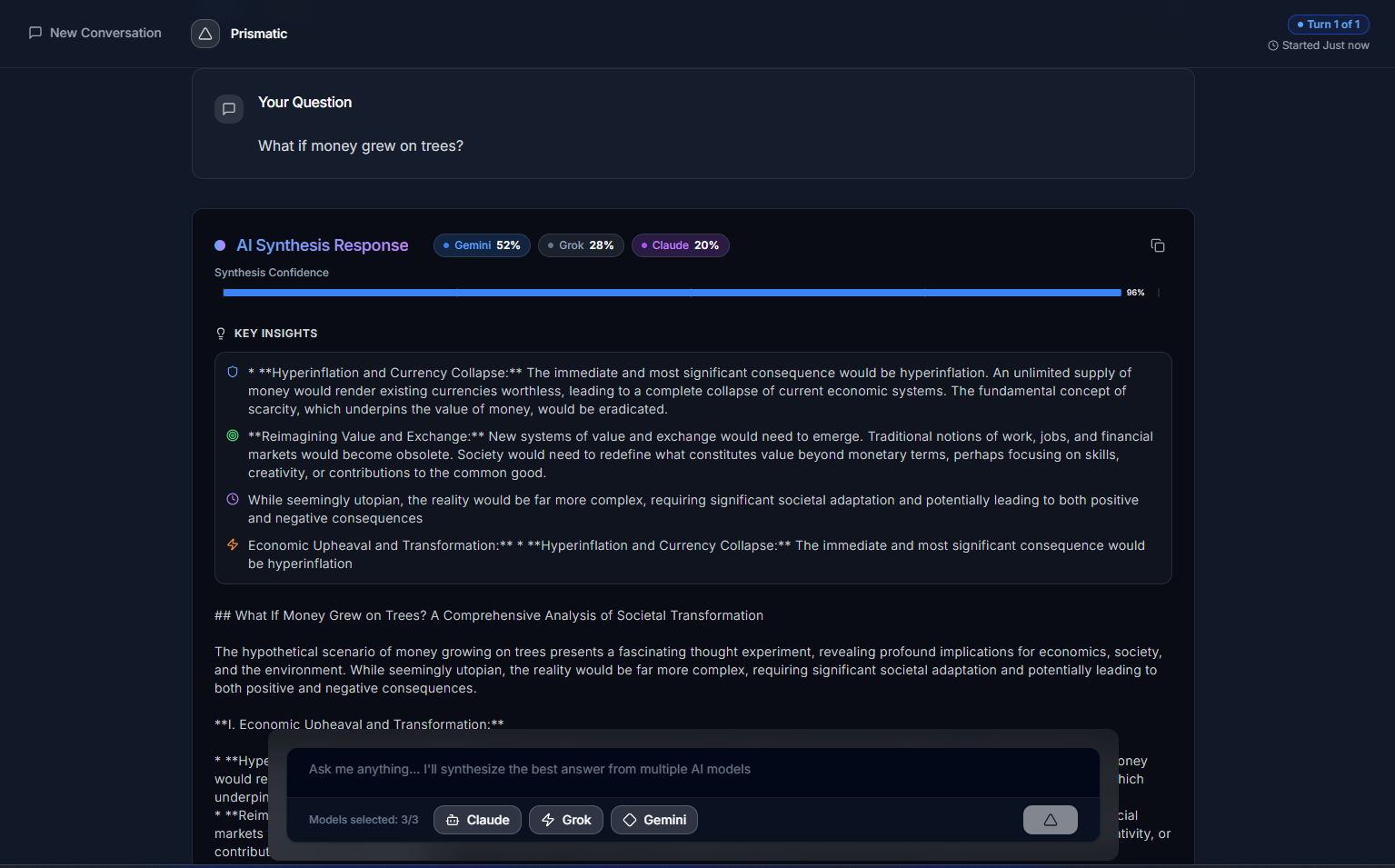
Prompt synthesised response
-
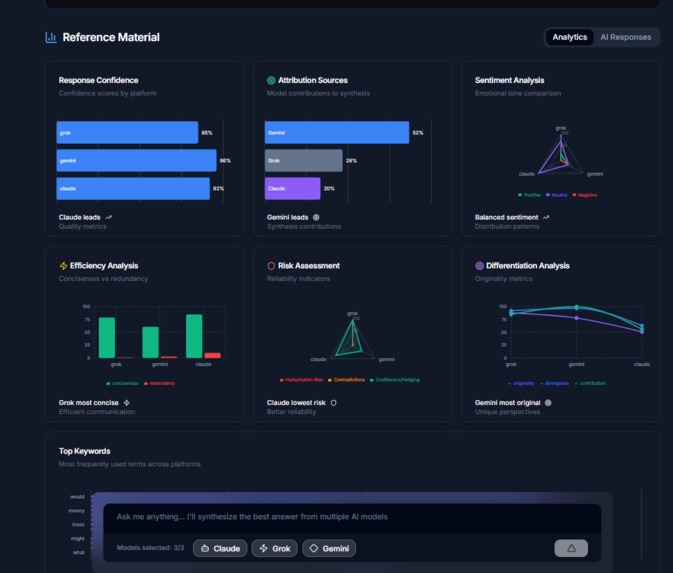
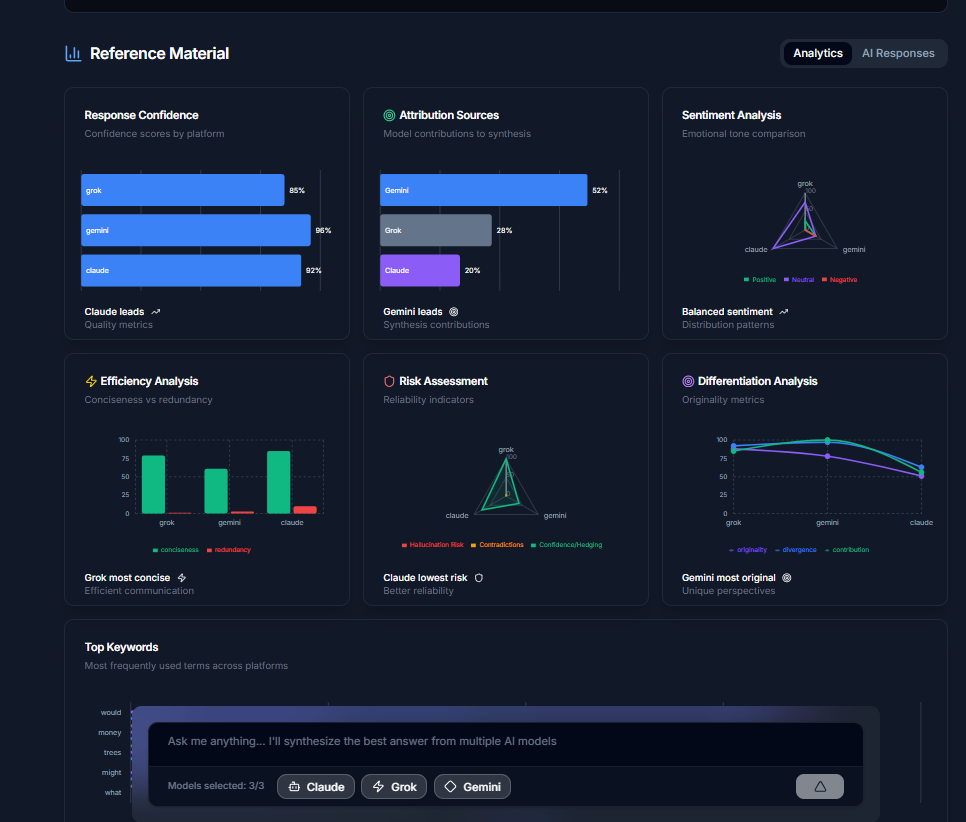
Prompt analysis
-
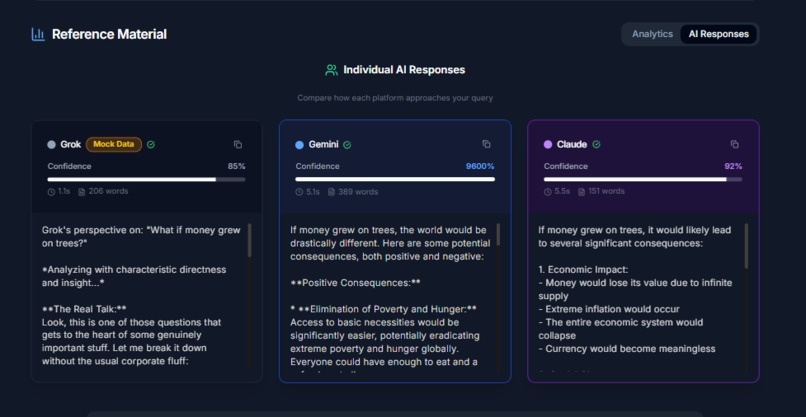
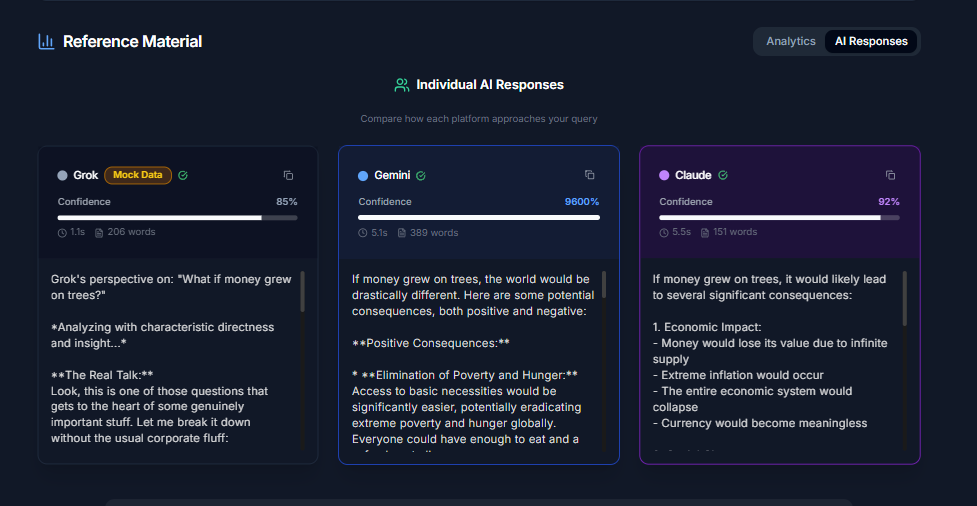
Ai Raw responses pre-synthesis

Inspiration
What it does
PrismaticAI allows you to:
- Prompt multiple LLMs (Claude, Grok, Gemini) simultaneously
- View and compare their raw responses side-by-side
- Automatically score outputs for clarity, correctness, and hallucination risk
- Generate a fused, synthesized response using the best parts of each
- Visualize model behavior with charts and analysis tools
- Leverage the power of synthetic data and cross-model inference for prompt testing and benchmarking ## How I built it
- Frontend: React + TypeScript, styled with TailwindCSS and ShadCN. Zustand for state management.
- Backend: Node.js + Express handles prompt routing, API calls, scoring, and synthesis logic.
- APIs:
- Claude via Anthropic
- Gemini via Google AI Studio
- Grok via xAI’s OpenAI-compatible REST endpoint
- Scoring and synthesis: Claude / Gemini (as a fallback) is used to analyze and merge model outputs.
- UI/UX: Recharts for visual feedback, Framer Motion for transitions, and a clean split-pane layout for analysis.
Challenges I ran into
- LLMs all require different prompt formats, auth headers, and error handling strategies.
- Merging outputs into a single synthesized answer required careful prompting and tuning.
- Accurately measuring correctness and hallucination potential across models is complex but essential.
- Building a seamless multi-model interface under hackathon time constraints pushed prioritization and scope discipline. ## Accomplishments that I'm proud of
What I learned
- The differences in LLM reasoning are subtle but meaningful—and fascinating to explore.
- Prompt engineering is both an art and science—especially across models.
- Synthesizing multiple outputs improves trust, clarity, and accuracy.
- Measuring outputs for hallucination, truthfulness, and task fit is as important as generating them.
- A great UX is essential when your product is working with nuanced, high-stakes content. ## What's next for Prismatic
- 🔬 Add token usage and cost estimates per run
- 🧠 Integrate deeper scoring for hallucination risk, factual consistency, and persona alignment
- 🧪 Expand support for synthetic data generation and multi-model inference testing
- 📘 Enable prompt versioning and session history
- 🧰 Launch user accounts with shared workspaces, versioned prompt sets, and model testing campaigns
- 👥 Build team collaboration features: see what your teammates are prompting, reviewing, or sharing
- 🧩 Add more models (OpenRouter, Mistral, Perplexity, GPT-4)
- 📊 Develop dashboards showing which LLMs perform best on different prompt types and personas
- 🧱 Build a “prompting notebook” experience for researchers and analysts
- 💳 Explore monetization via tiered usage plans or API proxying

Log in or sign up for Devpost to join the conversation.