-
-

PRISM App Icon: The lens through which your career truth is focused.
-

The Portal: A minimalist, glass-morphic entry point powered by Flutter & Serverpod.
-
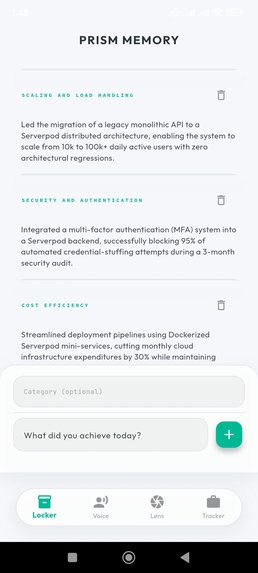
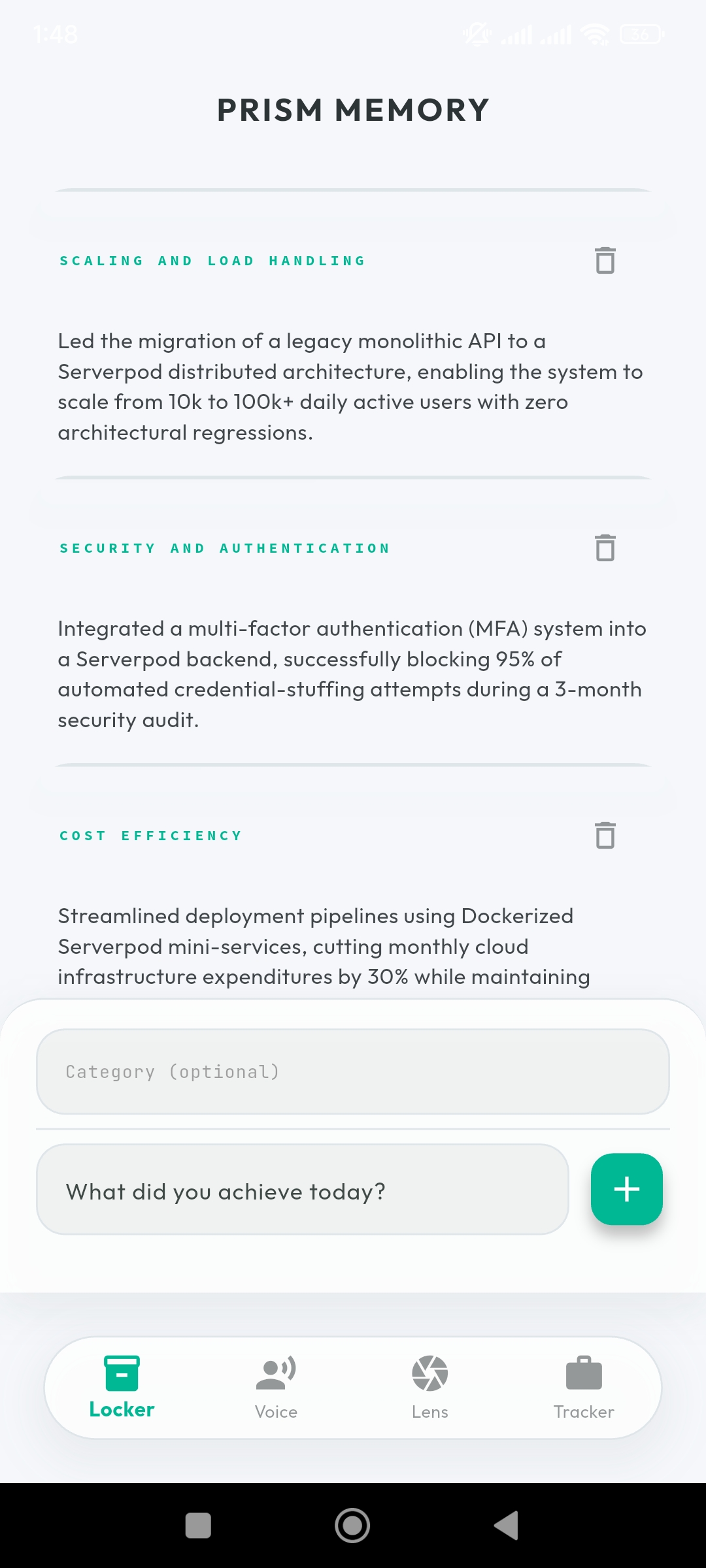
Atomic Locker: Your career facts, serialized and stored securely in PostgreSQL.
-
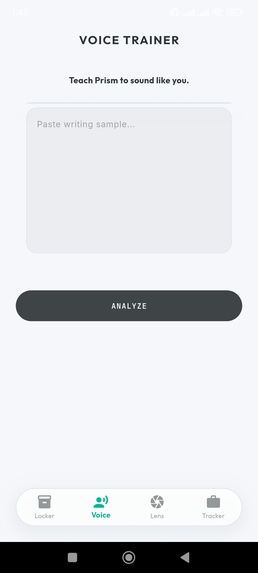
Voice Modeling: The AI analyzes your past writing to ensure the resume sounds like YOU.
-
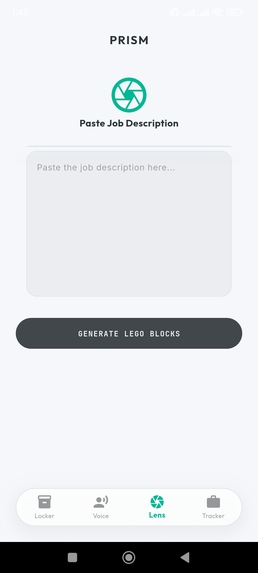
The Lens: Paste any Job Description here to trigger the Contextual Retrieval Engine.
-
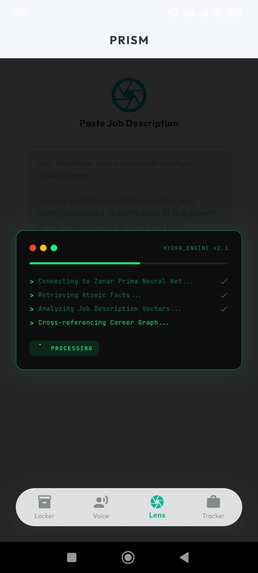
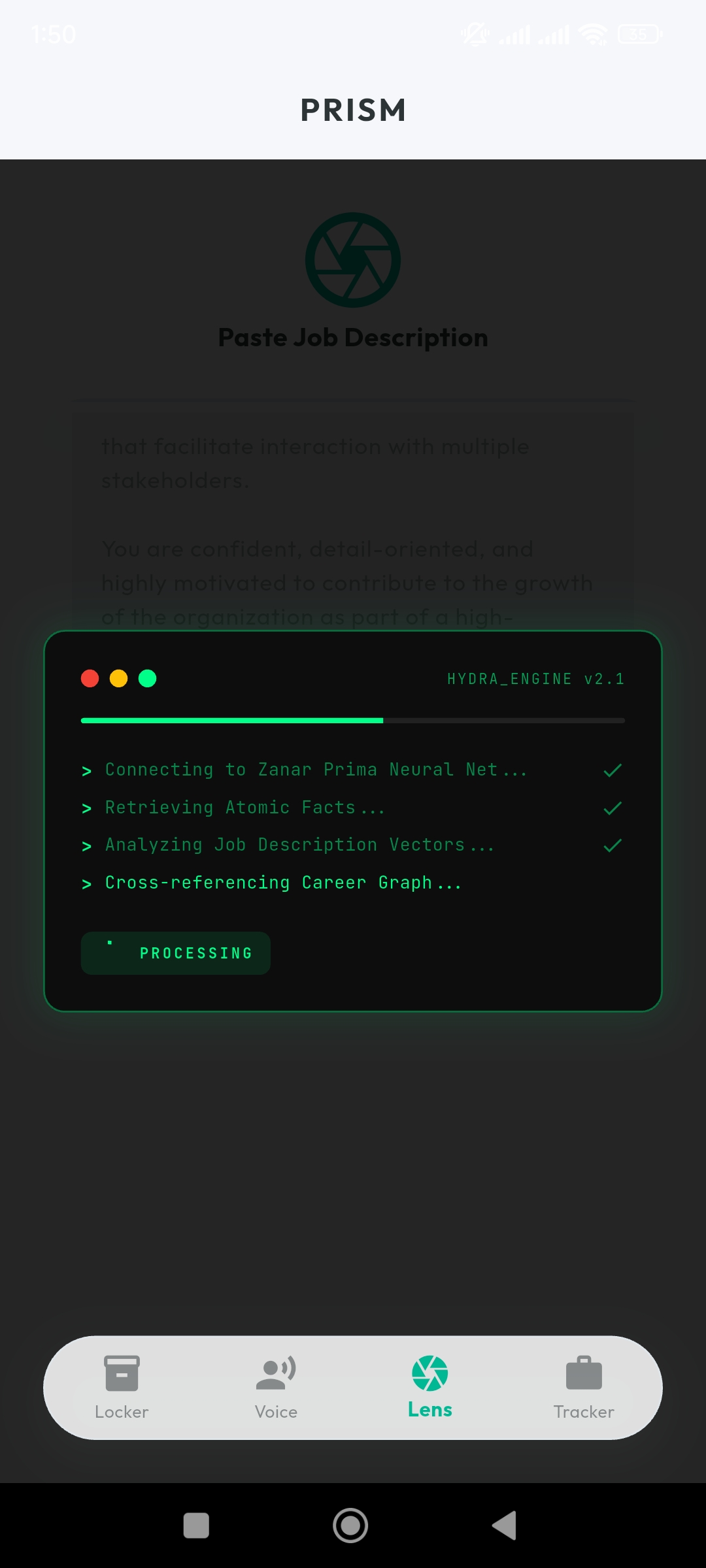
Hydra Engine in Action: Pollinations AI filtering your facts against the Job Requirements.
-
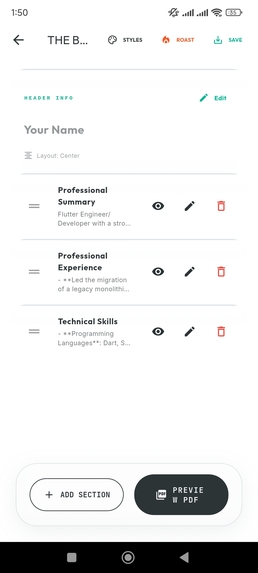
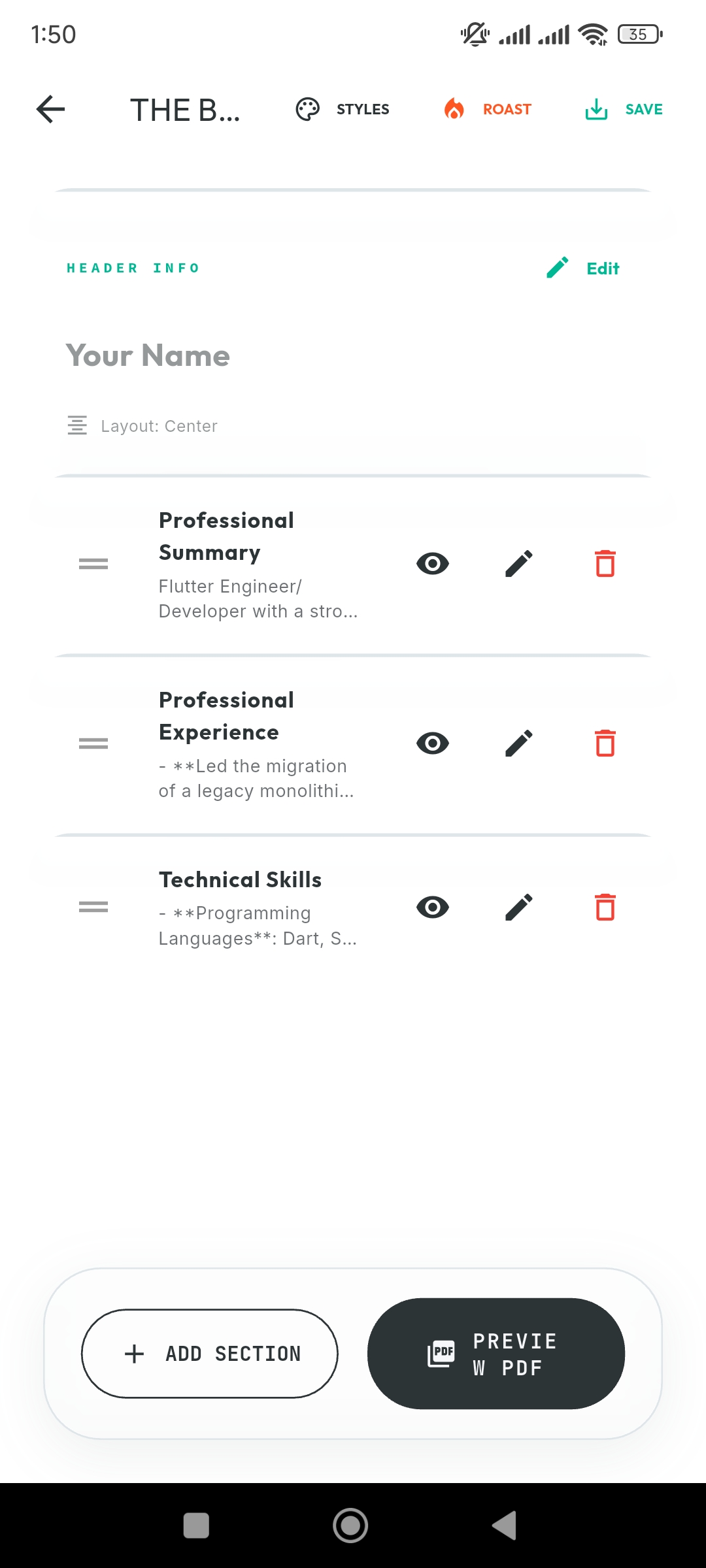
Architect Workspace: Real-time PDF generation with 60fps Flutter rendering.
-
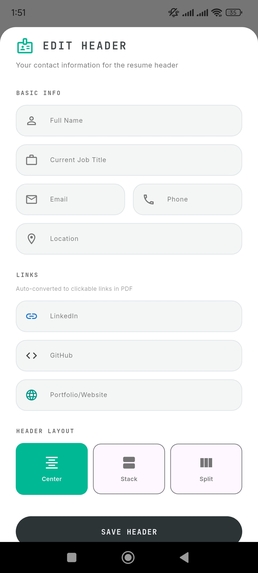
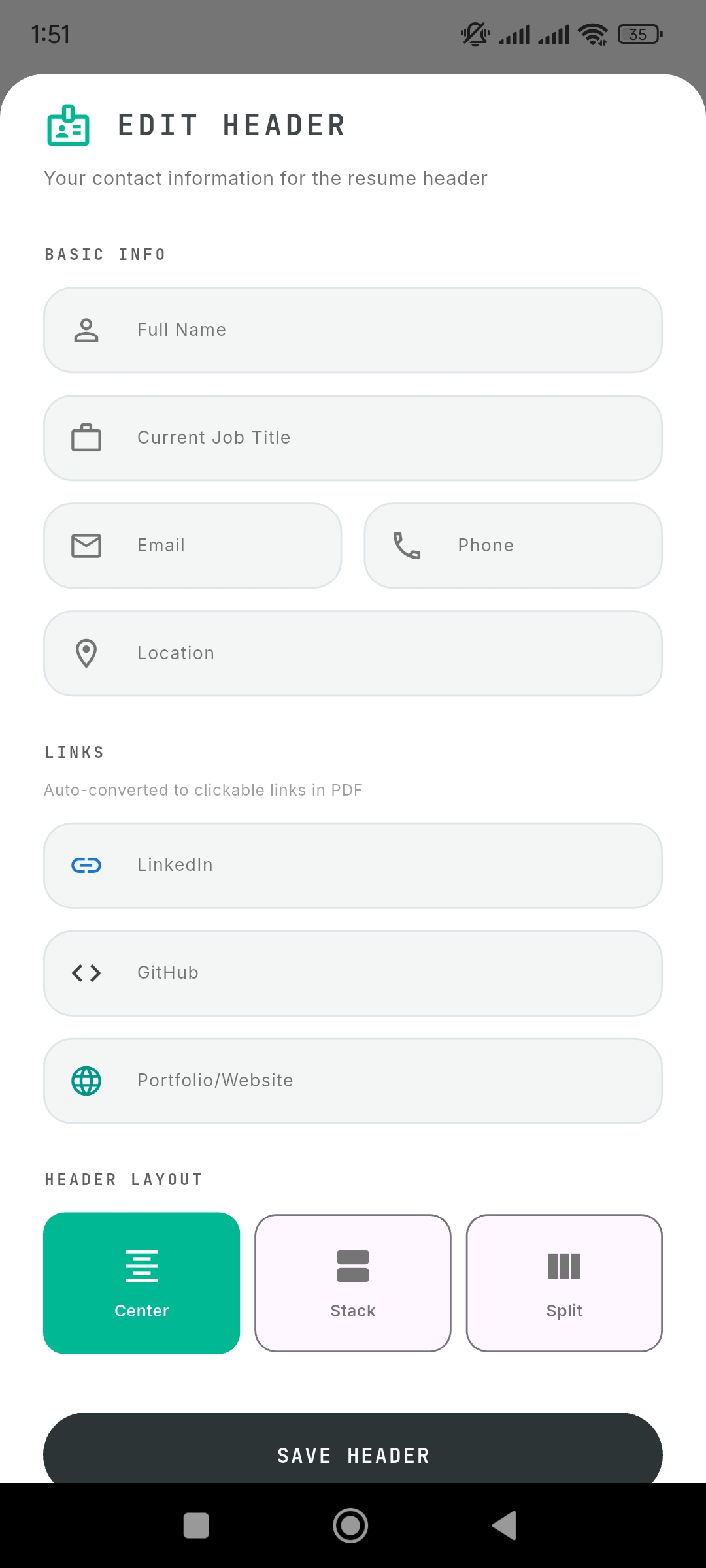
Live Data Binding: Update contact details with instant preview. Zero latency.
-
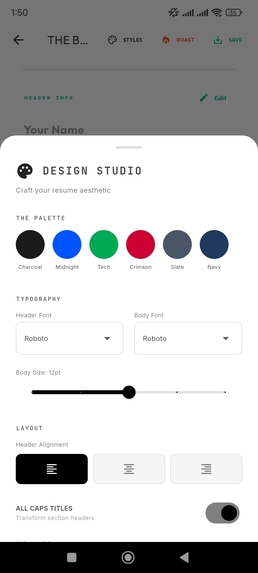
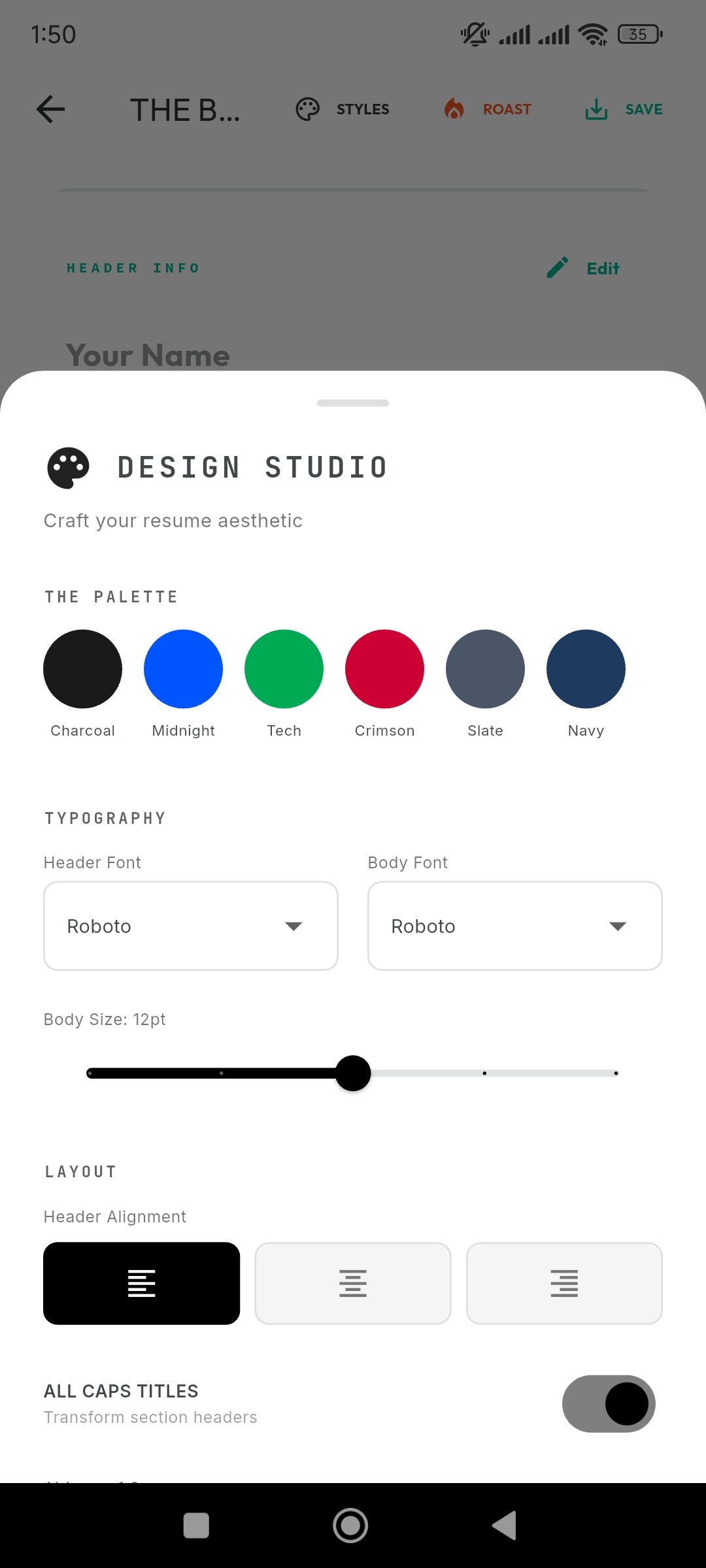
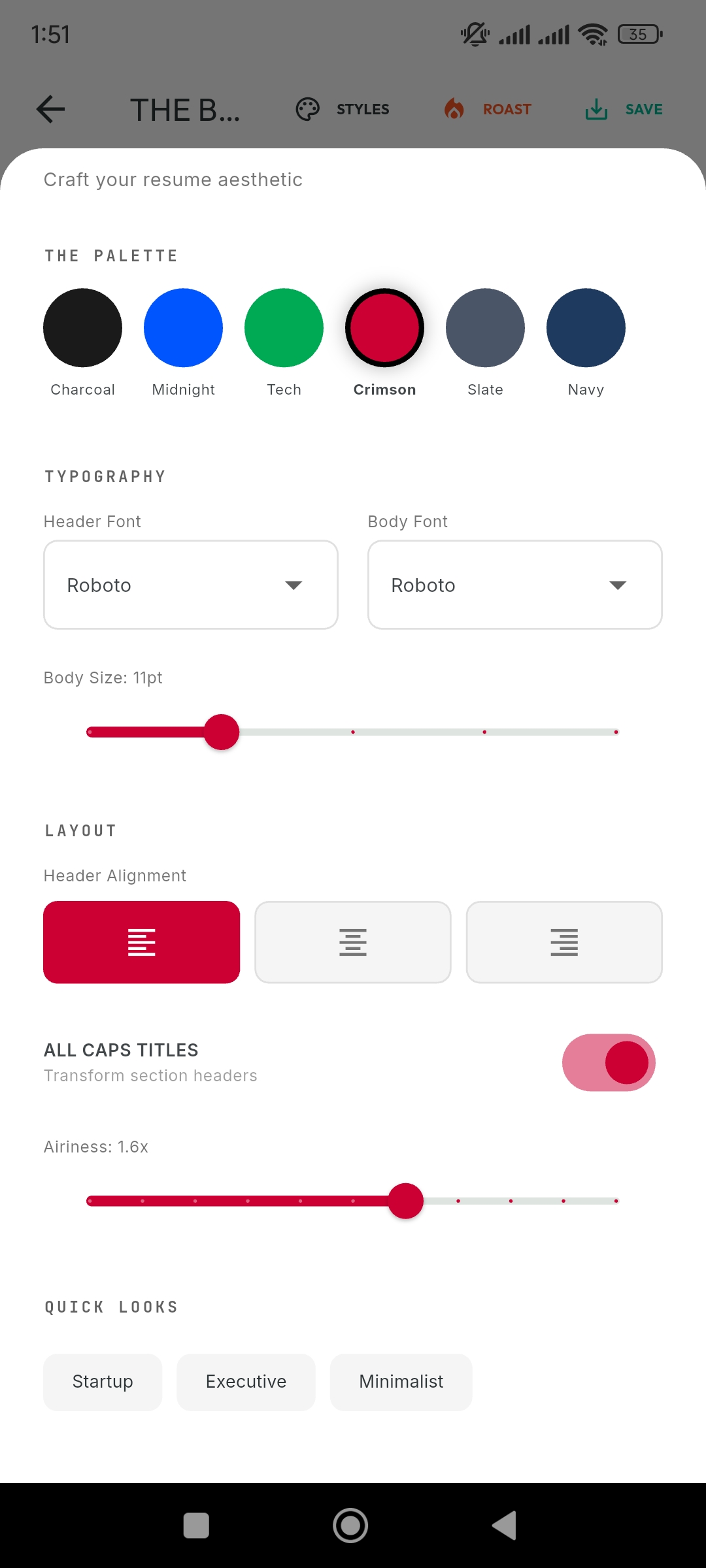
Neural Blueprints: Swapping entire design systems (fonts, spacing, layout) with one tap.
-
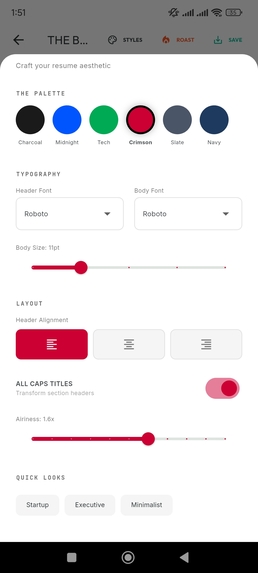
Adaptive Styling: From 'Harvard Classic' to 'Modern Creative' instantly.
-

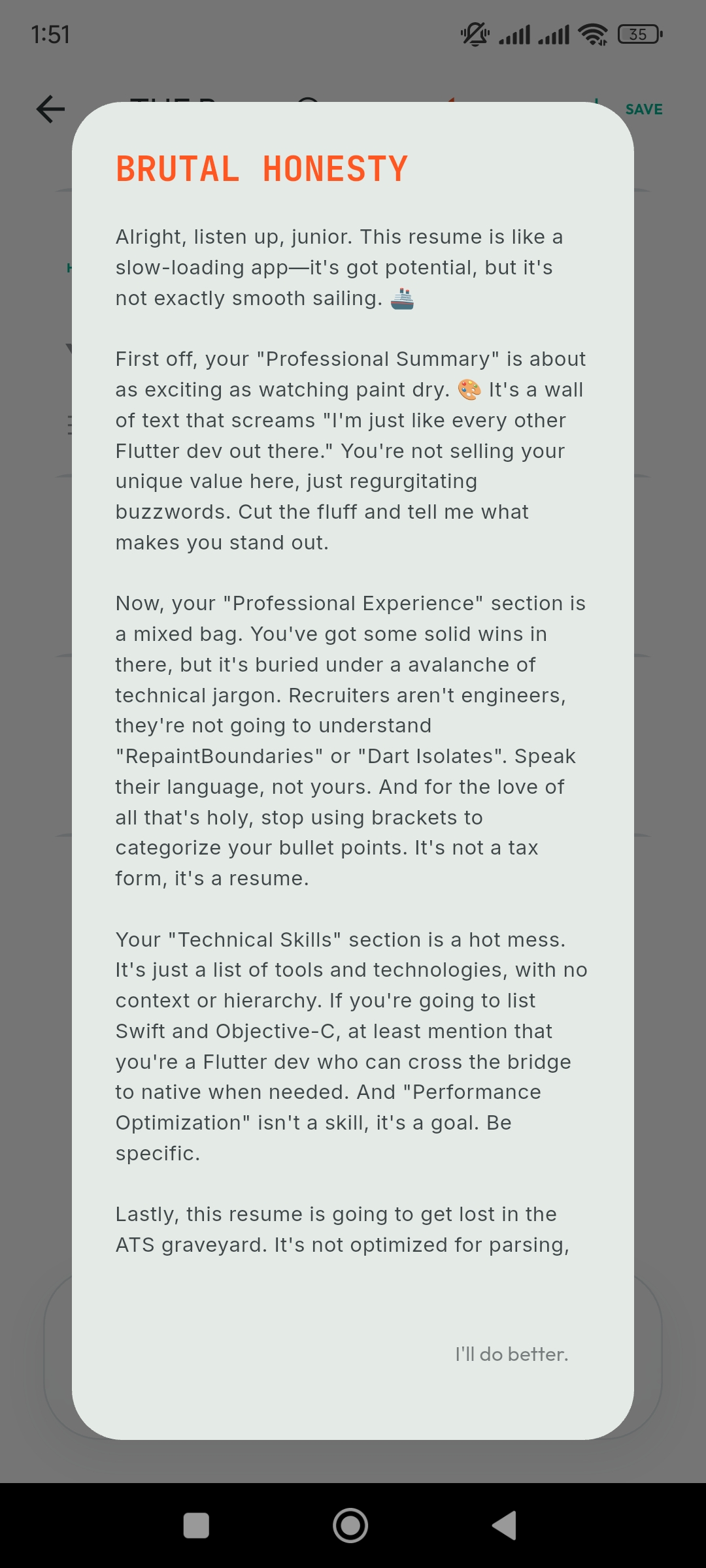
Protocol Override: Initializing the 'Roast' module for critical feedback.
-
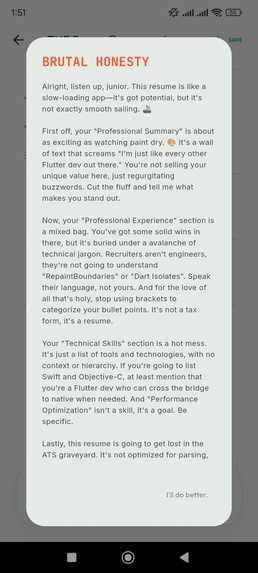
The Roast: A cynical Senior Engineer AI reviewing your resume for red flags.
-
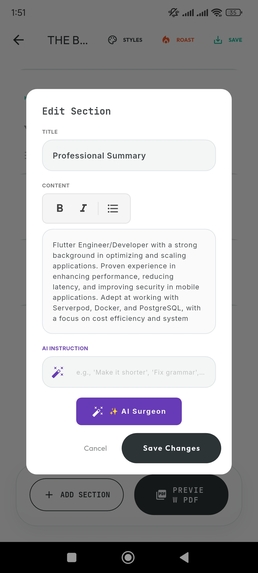
AI Surgeon: Granular, context-aware rewriting without hallucinating new facts.
-
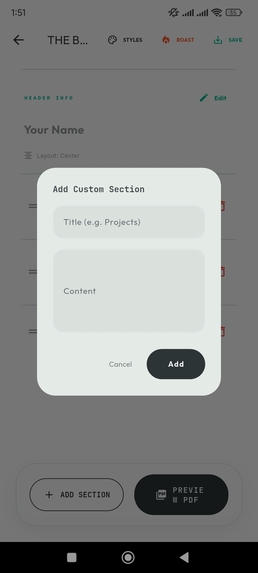
Dynamic Expansion: Injecting new evidence blocks backed by verified Atomic Facts.
-

The Output: High-fidelity, ATS-friendly PDF ready for immediate submission.




PRISM
A Career Architect Built on Serverpod
Inspiration: The “Resume_Final_v2” Problem
PRISM emerged from a familiar and persistent frustration in modern job hunting.
Most professionals maintain multiple versions of the same resume—tailored for different roles, companies, or platforms—often stored as poorly named PDFs such as Resume_Final, Resume_Updated_v3, or Resume_Last_Last.
Existing AI resume tools do not meaningfully solve this problem. They generate verbose, generic content and treat resumes as creative writing exercises.
A resume, however, is not prose.
It is a structured query over verified career data.
This led to a core insight: professional history should be stored as atomic, verifiable facts, and assembled into narratives only when required by context.
PRISM was designed as a Career Architect—a system that preserves truth first and generates language second.
What PRISM Does
PRISM inverts the traditional resume-writing workflow by separating data storage, retrieval logic, and presentation, with Serverpod acting as the unifying layer.
Atomic Locker (Structured Career Storage)
- Users store raw, factual achievements rather than documents
(e.g., “Reduced API latency by 40%”) - Each achievement is serialized and stored as structured data in PostgreSQL
- These entries function as immutable units of truth used by the system
Voice Modeling
- The system analyzes the user’s prior writing samples
- Learns tone, syntax, and phrasing patterns
- Ensures generated content reflects the user’s authentic voice rather than a generic AI style
Contextual Retrieval Engine (Hydra)
- Users provide a job description
- PRISM queries the Atomic Locker for relevant experience only
- Matching facts are assembled into a role-specific draft without introducing new information
Architect’s Workspace
- A Flutter-based visual workspace for assembling and refining resumes
- Supports drag-and-drop composition and targeted AI-assisted refinement
- Produces a high-fidelity PDF output suitable for professional submission
System Architecture and Technology Stack
PRISM is implemented as a full-stack Dart application, with Serverpod 3.0+ as the architectural foundation.
Backend: Serverpod
Serverpod was a critical enabler, not an auxiliary tool.
- Shared data models between backend and Flutter eliminated manual serialization
- Strong type safety across the entire stack reduced runtime errors
- Code generation enabled rapid iteration under hackathon constraints
- Business rules and truth enforcement were centralized in the backend
This allowed the system to treat data integrity as a first-class concern.
Database: PostgreSQL
- Stores structured Atomic Facts, user profiles, and generated resume states
- Schema design optimized for deterministic retrieval rather than free-text generation
- Enables strict validation of AI outputs against stored facts
Frontend: Flutter
- Custom workspace UI designed for complex state interactions
- Clean, minimal aesthetic focused on clarity and usability
- Tight integration with Serverpod’s generated client models
AI Orchestration
- AI requests are managed exclusively by the backend
- User data is sanitized before prompt construction
- Generated responses are validated against verified Atomic Facts
- The AI is restricted from introducing unsupported claims
Infrastructure
- Entire application stack is containerized using Docker
- Enables portability, reproducibility, and scalability
Key Technical Challenges
Preventing AI Hallucination
The primary challenge was ensuring the AI could not invent experience.
This was addressed by enforcing strict retrieval logic at the Serverpod layer:
- If a fact does not exist in the Atomic Locker
- If it is not explicitly retrieved by the query engine
- It cannot appear in the generated output
This constraint transformed the AI from a creative generator into a controlled assembler.
Complex State Synchronization
The Architect’s Workspace required careful coordination between:
- User interactions
- Backend state
- AI refinement cycles
Serverpod’s generated client simplified data consistency, though achieving a smooth experience required rigorous testing and iteration.
Key Learnings
Serverpod as a Force Multiplier
Serverpod’s schema-driven development model significantly accelerated development.
Changes made at the database level were immediately reflected across the backend and frontend, eliminating boilerplate and reducing cognitive overhead. This allowed more time to be spent on system design and user experience.
Designing Data for AI Systems
PRISM required deliberate modeling of career data—dates, metrics, roles, and outcomes—into schemas that are both human-meaningful and machine-queryable.
This reinforced the importance of data architecture when building reliable AI-assisted systems.
Future Work
PRISM is built on a scalable foundation designed to evolve. Our roadmap includes features that transition the app from a tool into a career ecosystem.
PRISM demonstrates how Serverpod enables trustworthy, scalable AI systems by unifying data, logic, and interface under a single, type-safe architecture.
Built With
- dart(v3.2+server/v3.8+client)
- docker
- flutter(v3.32.0)
- google-fonts
- pdf&printing
- pollinations.ai
- postgresql16(pgvector)
- redis(v6.2.6)
- serverpod(v3.2.3)
- serverpod-auth-idp

Log in or sign up for Devpost to join the conversation.