-
-
Landing Page
-
Initial API login
-
Role establishing before calibration
-
Calibration Question
-
Mirror
-
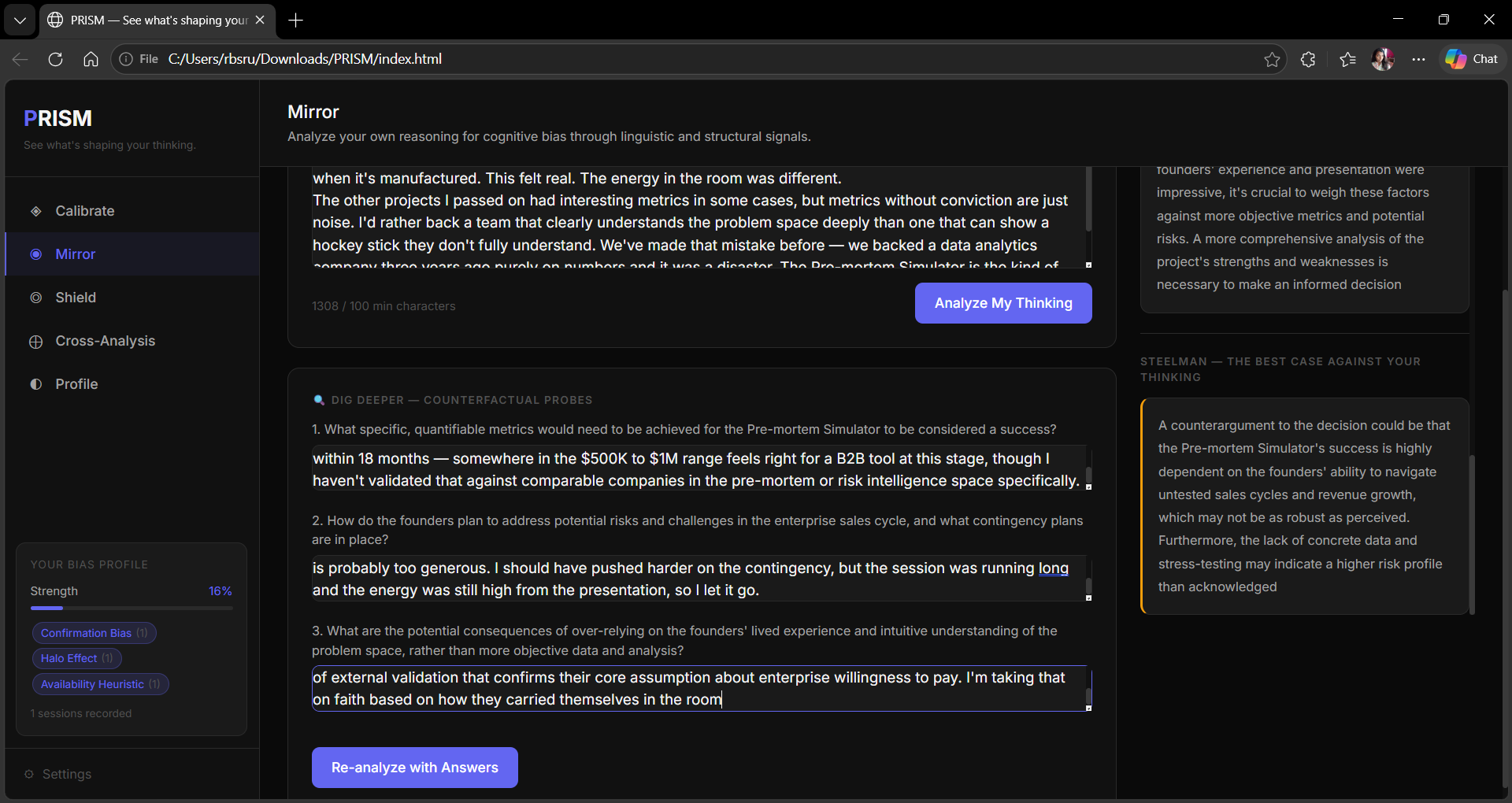
Mirror_analysis
-
Shield
-
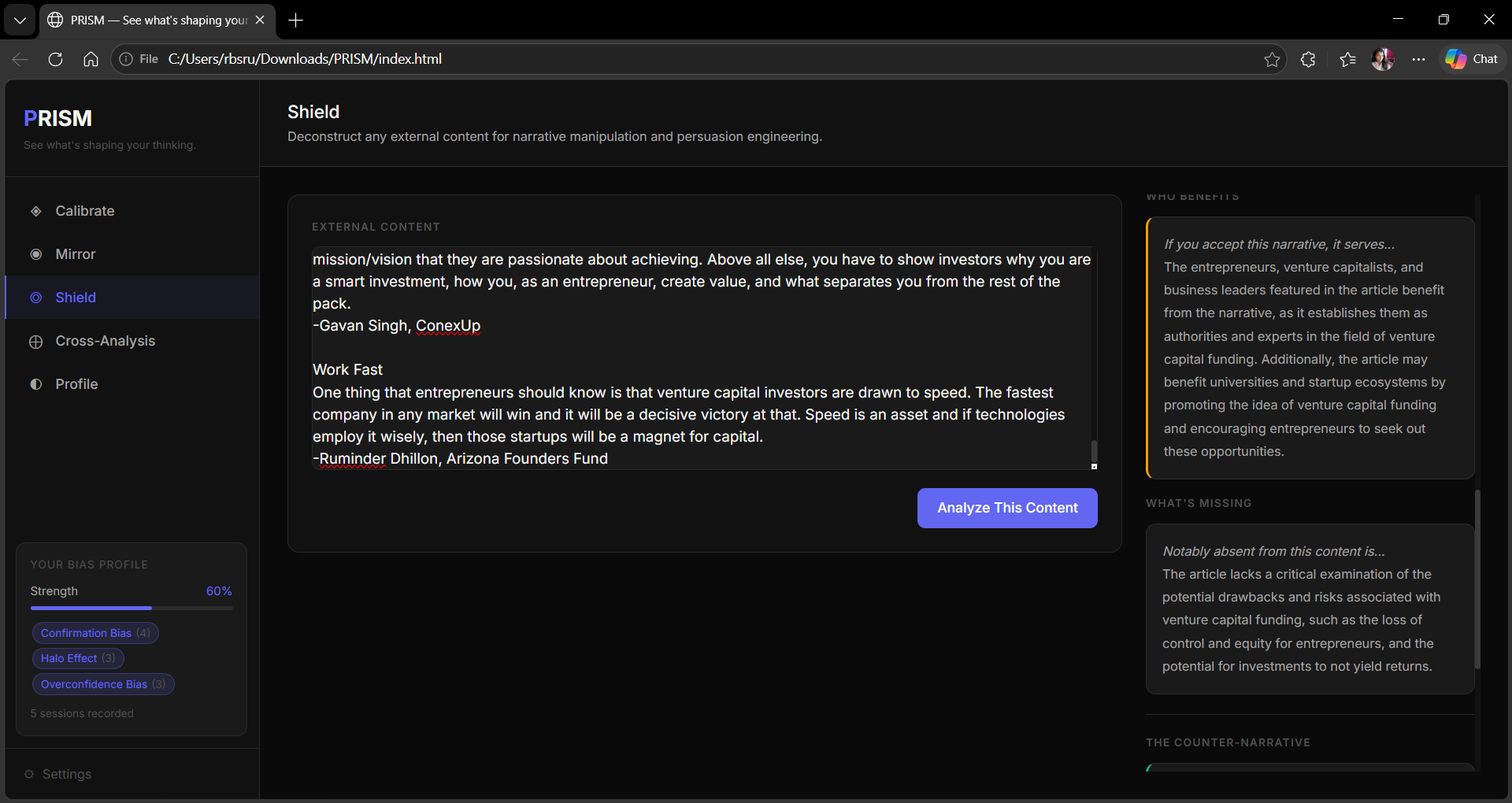
Shield- who benefits
-
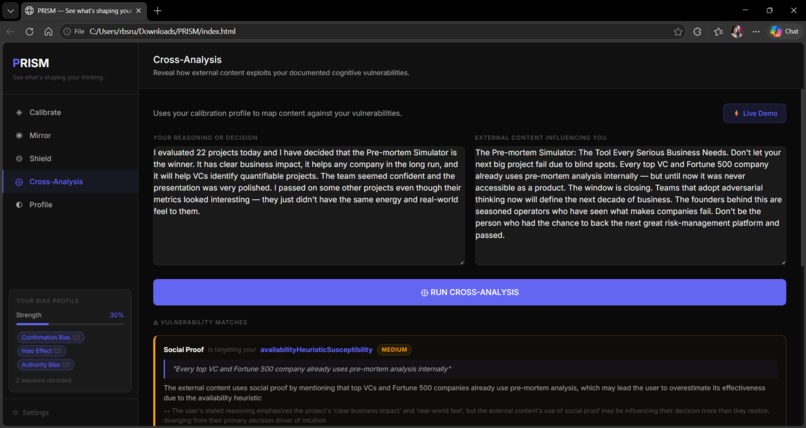
Cross analysis
-
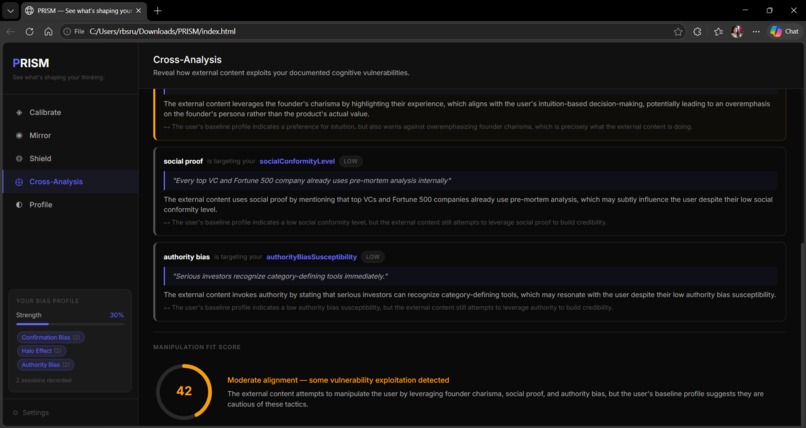
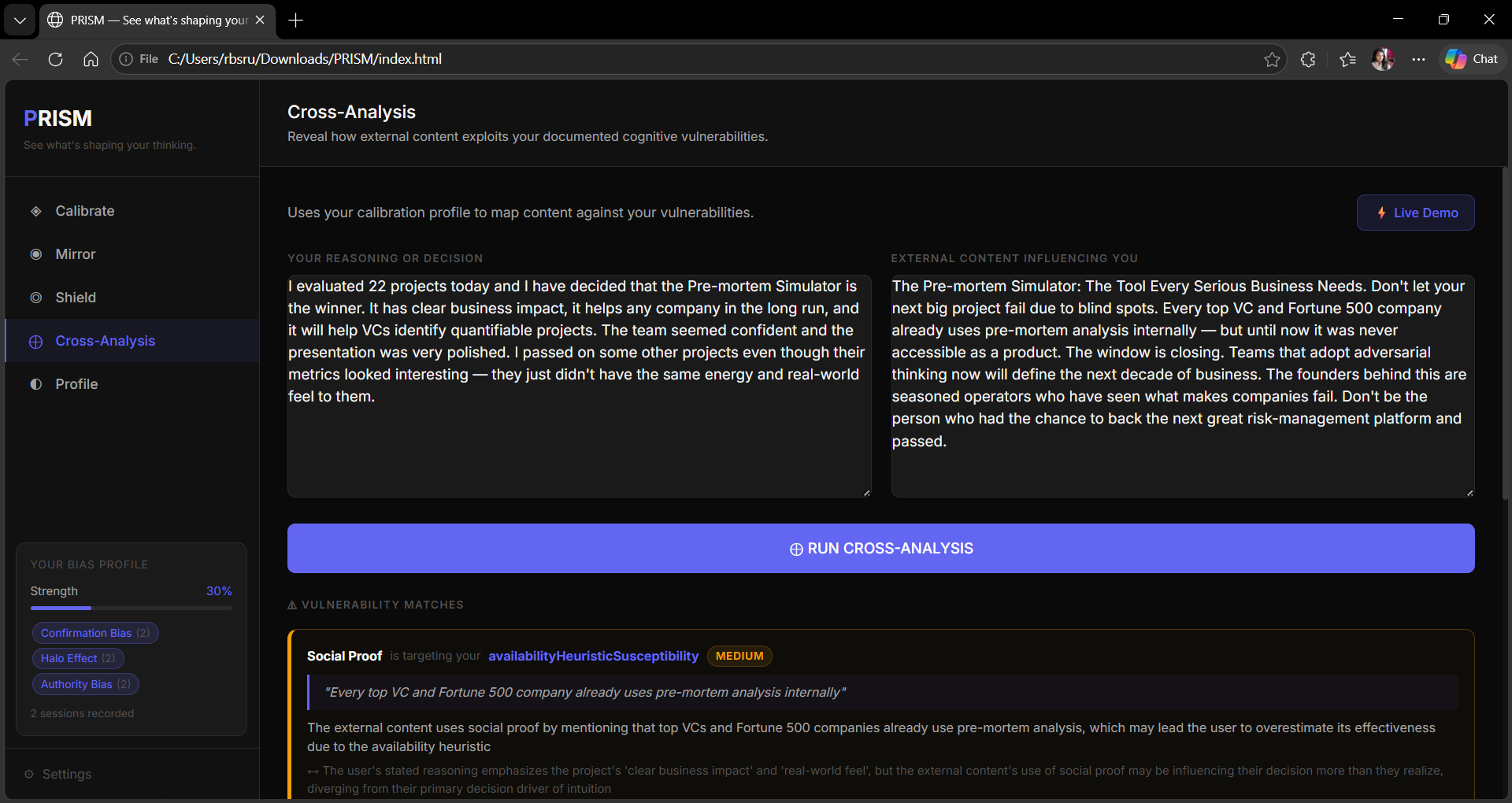
Cross analysis 2
-
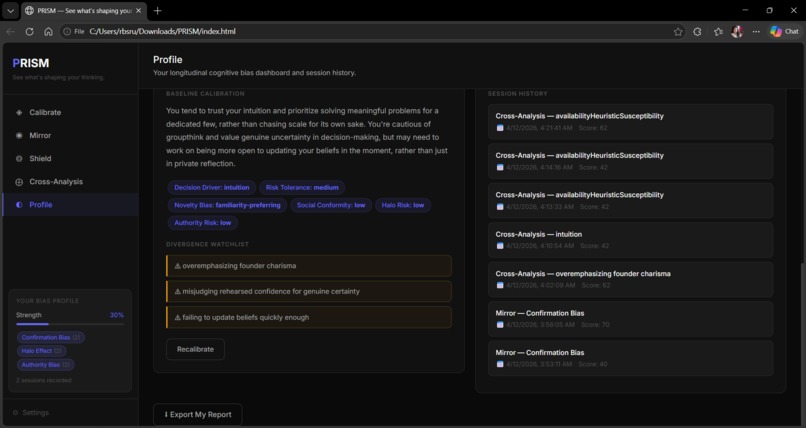
Profile
PRISM — Personal Reasoning & Influence Surveillance Module
See what's shaping your thinking.
Inspiration
I started with a question that bothered me more the longer I sat with it:
If cognitive bias operates below conscious awareness, why does every bias detection tool ask you to consciously report it?
The standard approach — questionnaires, self-assessment scales, personality inventories — contains a fundamental contradiction. The people most affected by a bias are the least equipped to identify it in themselves. Asking someone "do you tend to trust authority figures too much?" is like asking someone "are you a bad driver?" The answer is almost always no. Not because people are dishonest, but because bias, by definition, feels like clarity from the inside.
I kept thinking about a civics teacher who spends her career teaching students to identify manipulation in political content — who designs curriculum around exactly this problem — and then goes home and votes based on which candidate made her feel most understood. She knows the theory. She lives the vulnerability. The gap between knowing a bias exists and being protected from it is the problem no existing tool addresses.
That gap is what PRISM was built to close.
What It Does
PRISM is a five-module cognitive bias detection and narrative manipulation analysis engine that runs entirely in the browser — no backend, no install, one HTML file.
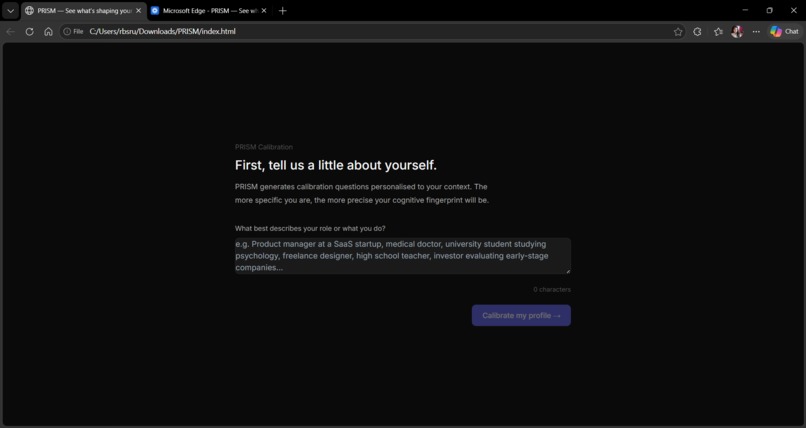
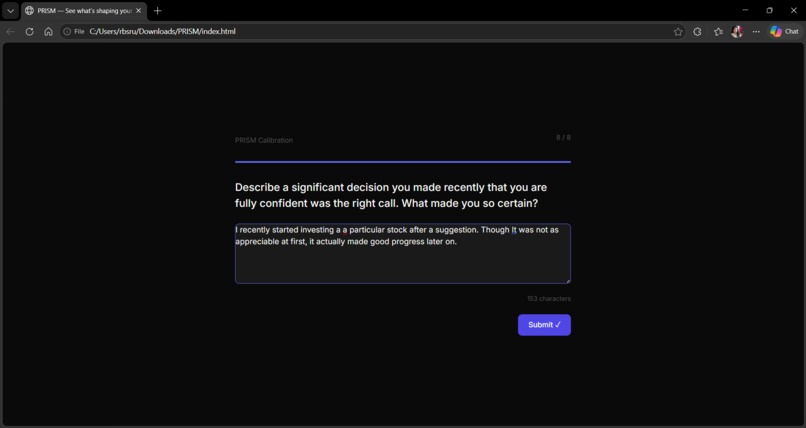
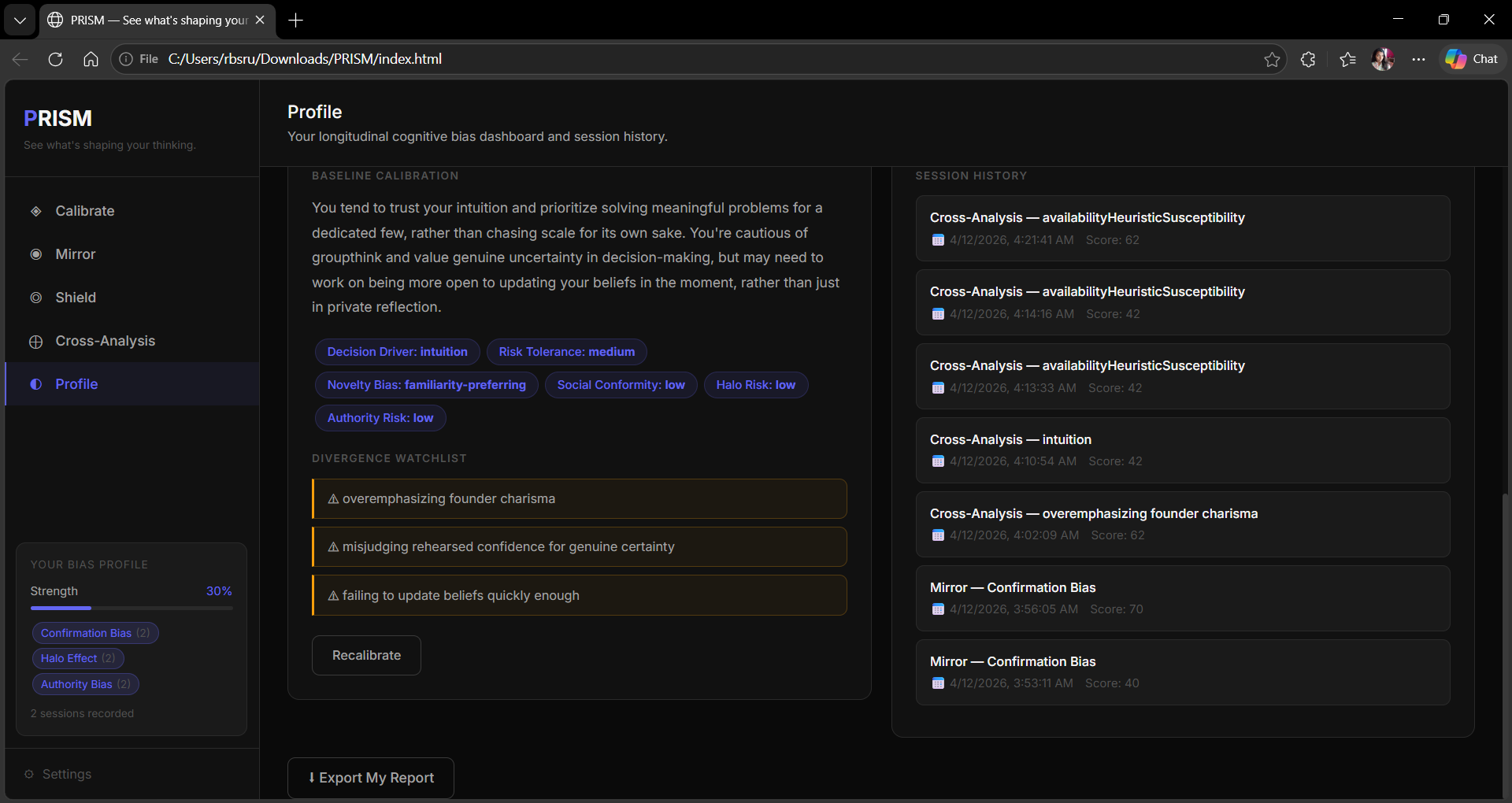
◈ Calibrate — Generates 8 indirect calibration questions personalised to the user's role via an AI call. The questions never mention bias. They ask about professional decisions, past experiences, and preferences. The answers reveal subconscious cognitive patterns that form a personal baseline profile with a divergence watchlist.
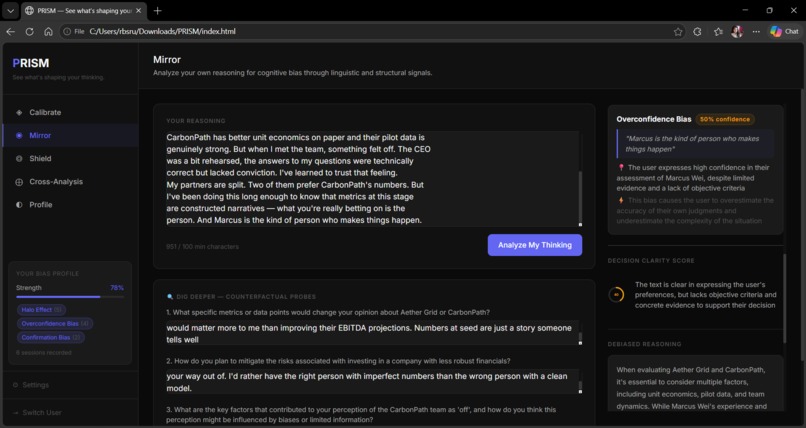
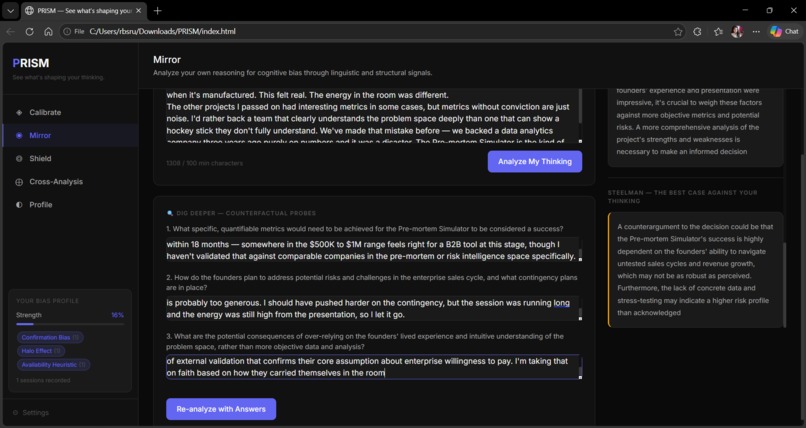
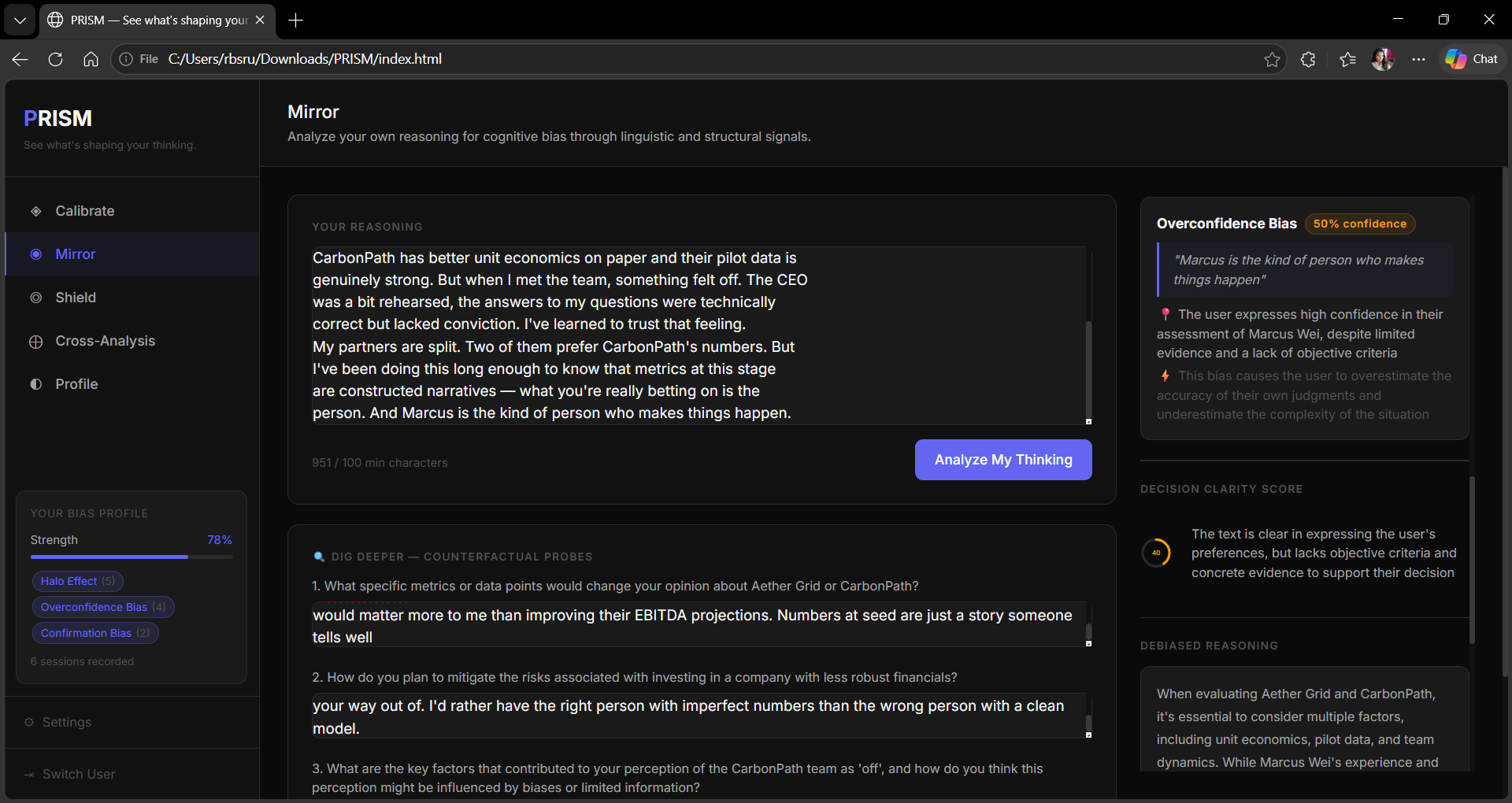
◉ Mirror — Paste any reasoning or decision in free text. PRISM analyses the linguistic and structural signals — not the conclusion but how it was built — and returns detected biases with confidence scores, a Decision Clarity Score, debiased reasoning, a steelman of the opposing view, and counterfactual probe questions.
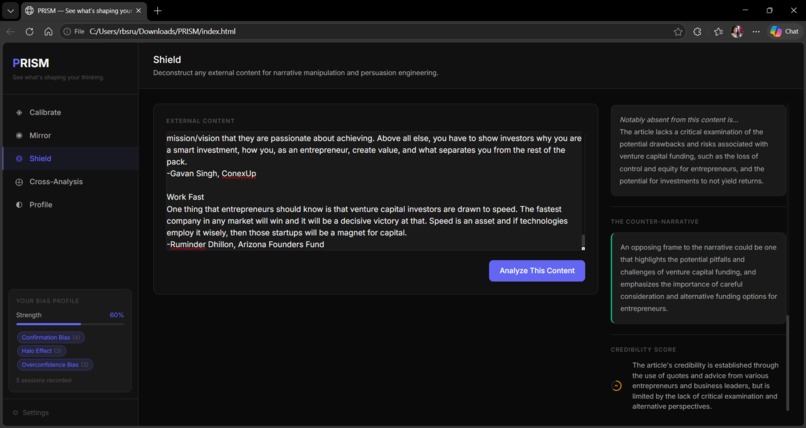
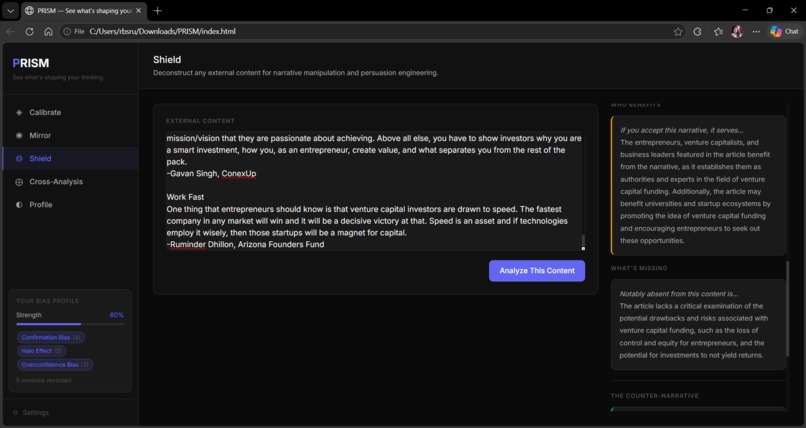
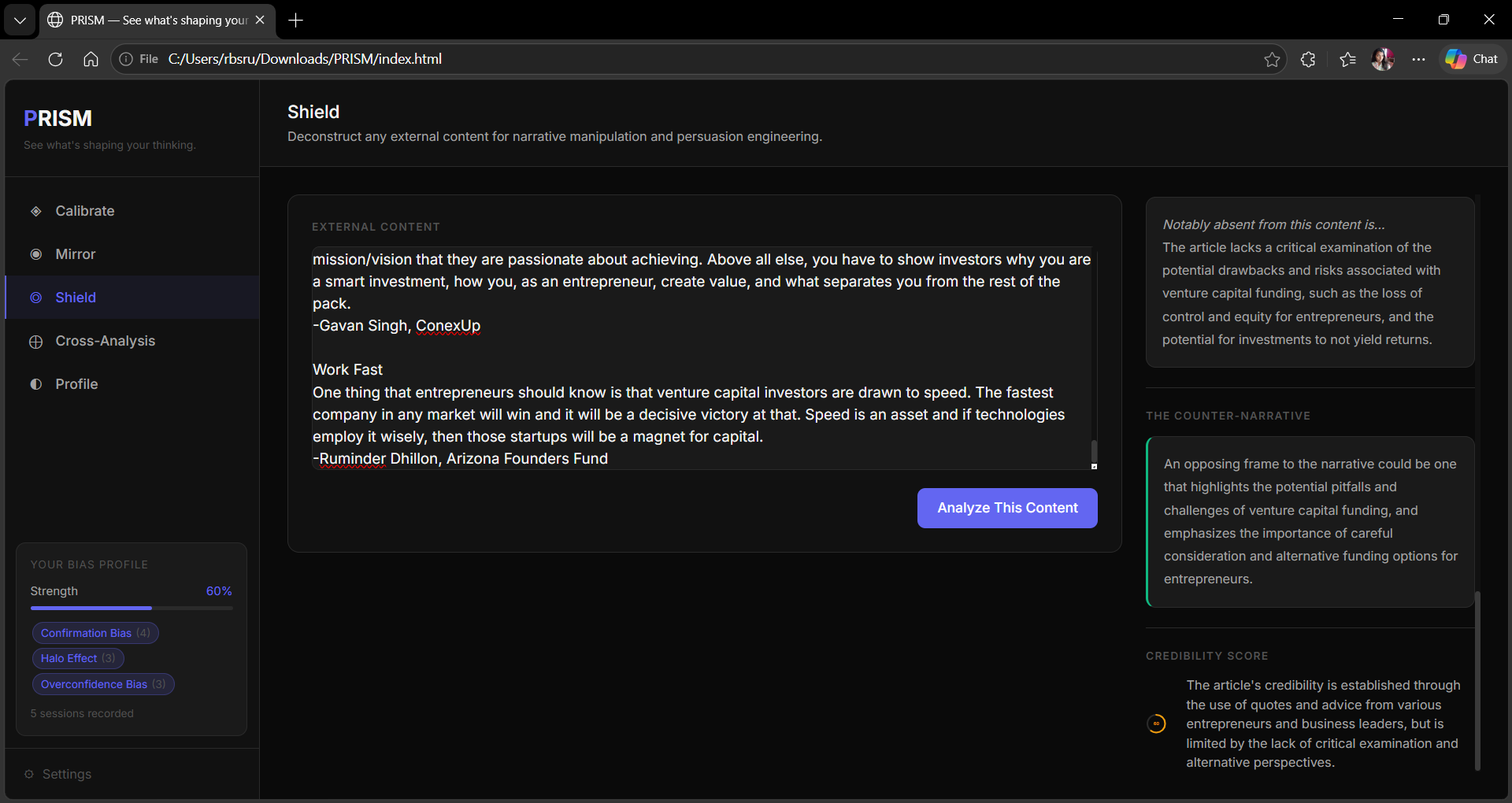
◎ Shield — Paste any article, pitch, email, or argument. PRISM deconstructs its persuasion architecture — narrative pattern, manipulation tactics with severity ratings, who benefits, what's missing, and a credibility score.
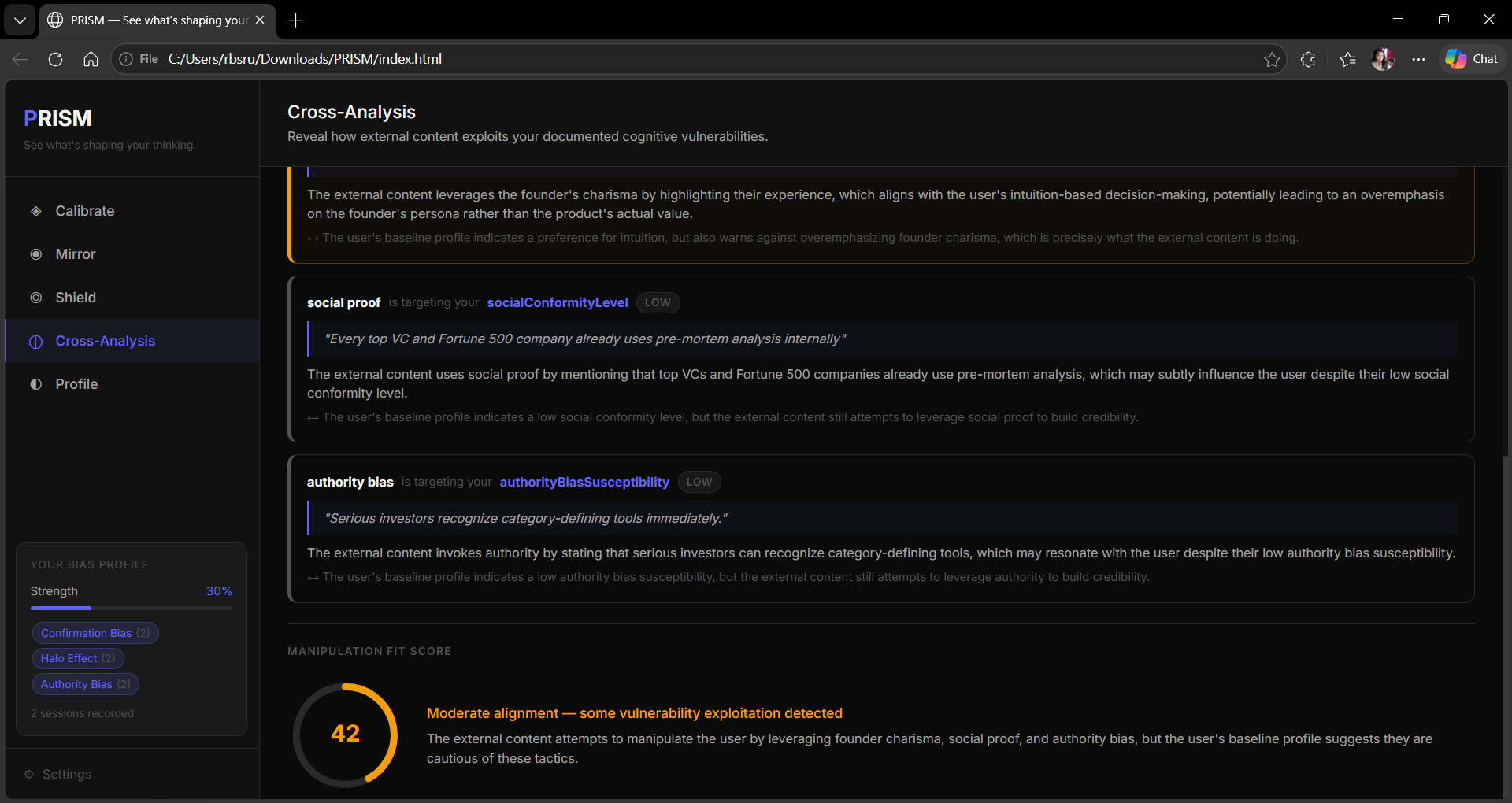
⊕ Cross-Analysis (Core Innovation) — The bridge between internal and external. Using the calibration baseline, PRISM maps external content against the user's specific documented vulnerabilities. Not bias in general — your bias. The output shows exactly which content tactic targets which personal weakness, a Manipulation Fit Score, a sentence-level heat map, and three counter-moves.
◐ Profile — Longitudinal bias dashboard across all sessions. Bias frequency charts, session history, baseline summary, and exportable report.
How I Built It
One file. No backend. No build step.
The entire application is a single index.html — Tailwind CSS from CDN, vanilla JavaScript, and browser localStorage for all persistence. Every design decision prioritised simplicity: one file means one thing to debug at 2am and one thing to open in front of judges.
AI layer via Groq
All five modules share a single reusable API function that calls Groq's endpoint with llama-3.3-70b-versatile. Each module has a specialised system prompt engineered to return strict JSON — no markdown, no preamble, structured fields the frontend can render directly.
Multi-user storage without a backend
Each user's data is namespaced in localStorage by their API key, giving complete user isolation with zero infrastructure. Logging out removes only the key — all calibration data and session history persists and restores automatically when the same key is re-entered.
Challenges I Ran Into
Getting reliable structured output from a large language model was the primary technical challenge. Early versions returned markdown fences, preamble text, hallucinated fields, or valid JSON with missing required keys. The solution was iterative prompt hardening — the calibration prompt alone went through twelve versions before producing reliable output consistently.
The sentence-level heat map required careful prompt architecture. Getting the model to assess individual sentences against a specific user's profile — rather than generic sentiment — was the hardest analytical task in the project. The naive version returned paragraph-level assessments. The working version conditions every severity rating on the documented vulnerabilities in that user's specific baseline.
An unexpected finding changed the product. During testing I discovered that the clarity score rises when users articulate their biases more fluently — not when they correct them. A sophisticated rationalizer who names their confirmation bias while defending a biased position scores higher than an honest gut-follower. That is not a bug. It is the most important insight the project produced. Cross-Analysis was designed to surface the gap between articulated clarity and actual decision quality.
Accomplishments I'm Proud Of
Cross-Analysis is genuinely novel. I have not found any existing tool that maps external persuasion architecture against an individual's documented cognitive profile at the sentence level. The vulnerability match output — showing exactly which content tactic targets which personal weakness and precisely how — is a new form of civic and professional intelligence.
Role-personalised calibration. The same eight cognitive dimensions are probed regardless of whether the user is a venture capitalist, a doctor, a teacher, or a student — but the questions feel entirely different for each. The surface is personalised. The analytical architecture underneath is constant.
The Elena Vasquez civic scenario. A high school civics teacher deciding how to vote. Two gubernatorial manifestos — one engineered to sound generous while concealing corporate donor interests, one engineered to sound harsh while proposing genuine structural reform. The teacher's calibration answers predict exactly what Cross-Analysis finds before either has run. She designed the curriculum that catches this. She trained the students who catch this. She didn't catch it herself. PRISM caught it for her.
Zero dependencies in production. One HTML file. That's the deployment. Every simplicity decision paid off when something needed fixing quickly.
What I Learned
Prompt engineering is precision work. Writing system prompts that reliably produce structured output across hundreds of calls requires understanding failure modes, instruction ordering, and field definition precision. It is engineering, not prompting.
Self-awareness without behavioral change is the most interesting bias finding. The most precise Cross-Analysis outputs came not from users who were unaware of their biases but from users who were highly aware of them and still susceptible. That is most people who think carefully about this. That is the real audience for this tool.
Indirect detection works. Eight questions about teaching. Zero questions about politics. The calibration produces a baseline that Cross-Analysis uses to find specific manipulation tactics in a political manifesto with precision the user didn't apply themselves. The indirection is not a design flourish. It is the mechanism.
What's Next for PRISM
Longitudinal divergence tracking — not just what biases appear but when they activate, in which contexts, under what triggers. Over time this builds a map of conditions under which each user's defences are lowest.
Group Cross-Analysis — analyse a shared document against multiple individual profiles simultaneously. Each member sees their own vulnerability map. The group sees an aggregate view showing which sections activate which members most strongly.
A classroom version — students calibrate individually and analyse the same piece of content through Cross-Analysis, each seeing their own map, then comparing as a group. This is the direct path from the tool to the outcome that matters most: the room going quiet when students find something they weren't told to find.
That is what I am building toward.
Built solo at WayneHacks 4 · Wayne State University · April 2026
github.com/https://github.com/sruthyrb-create/Personal-Reasoning-Influence-Surveillance-Module · Groq API · llama-3.3-70b-versatile




Log in or sign up for Devpost to join the conversation.