-
-
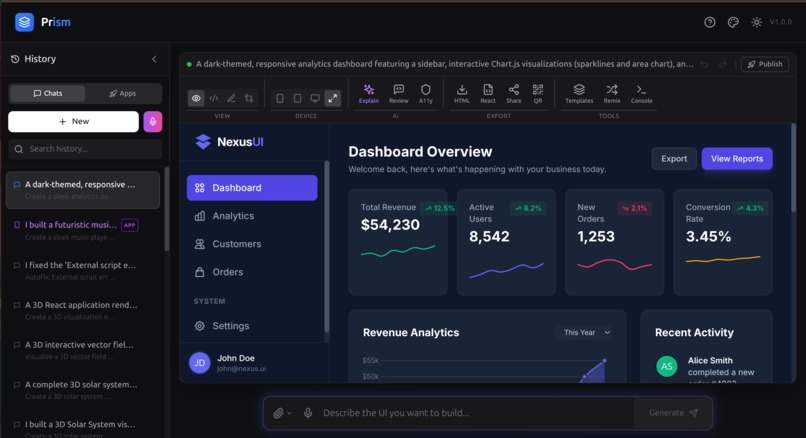
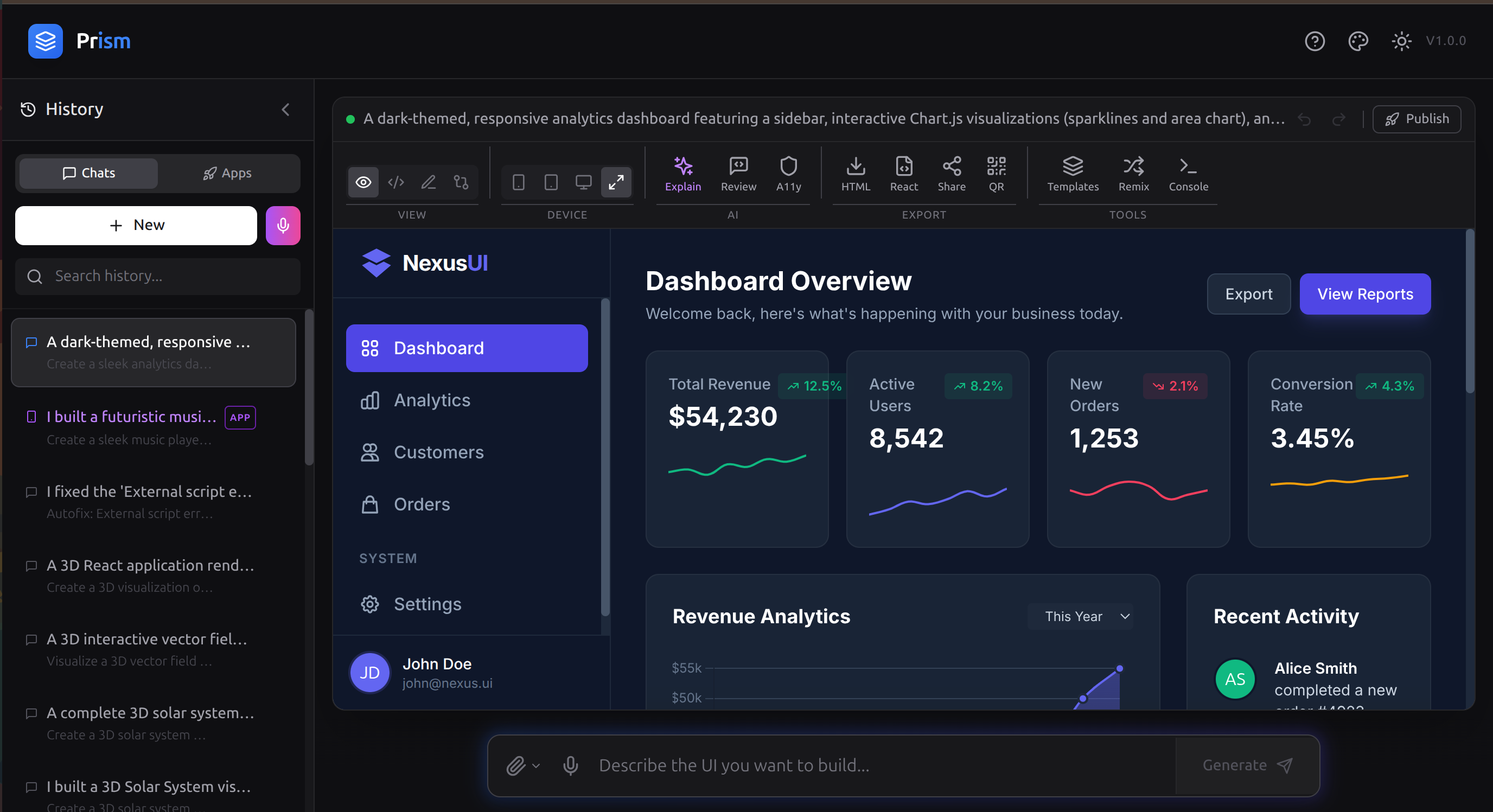
Interactive Dashboard
-
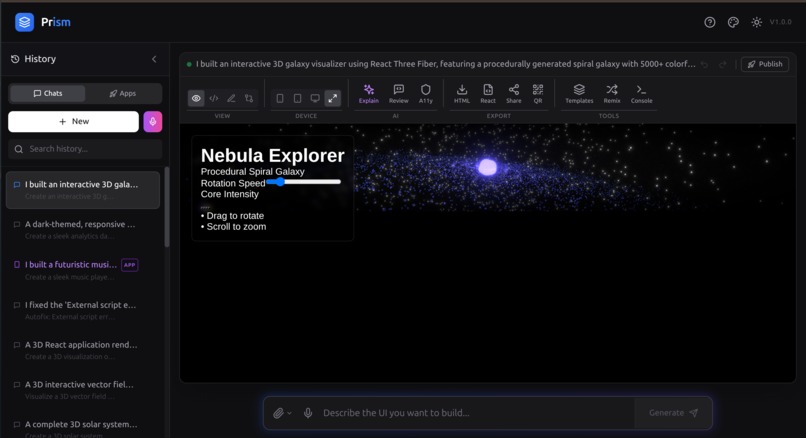
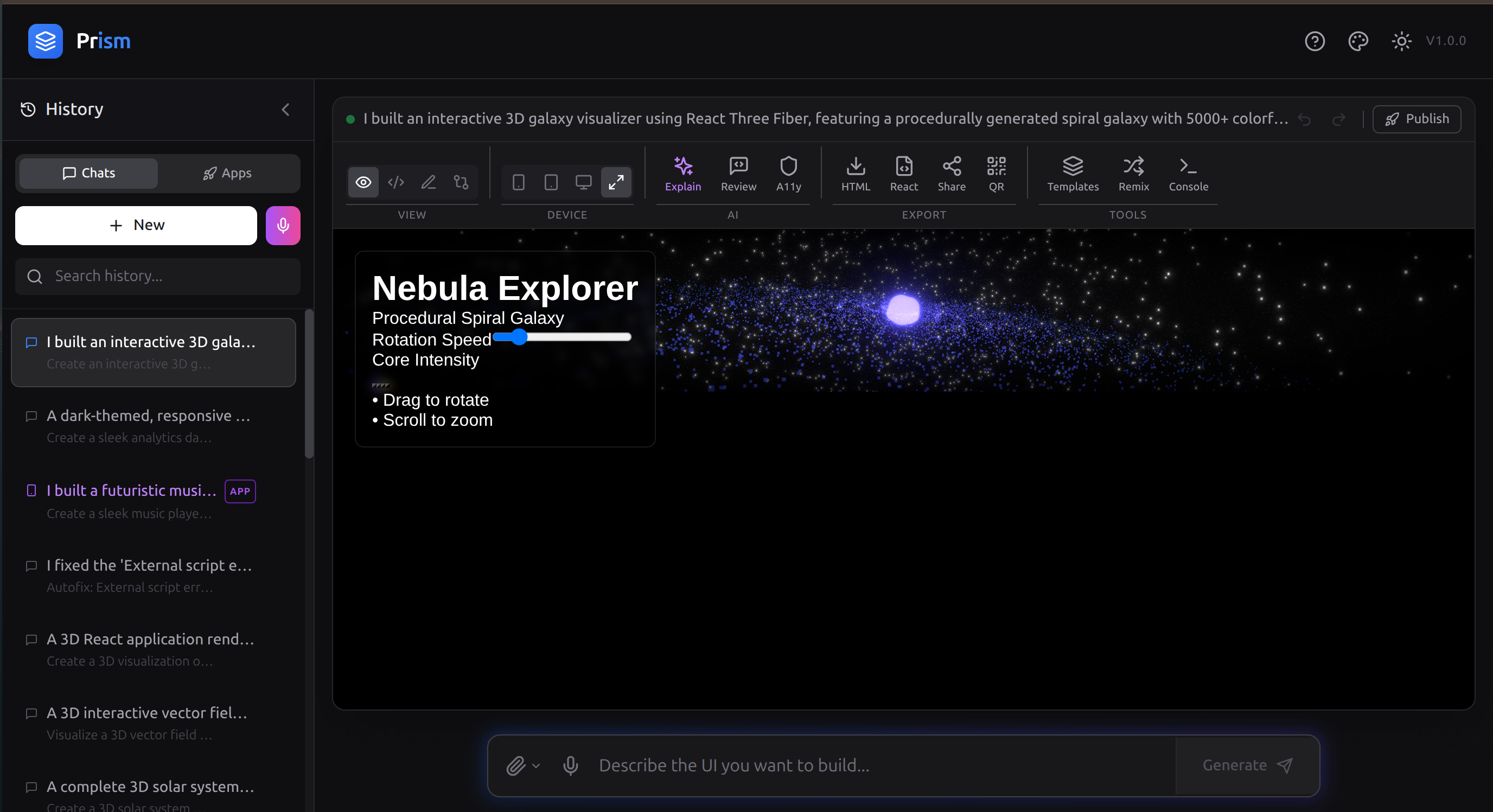
3D Scene
-
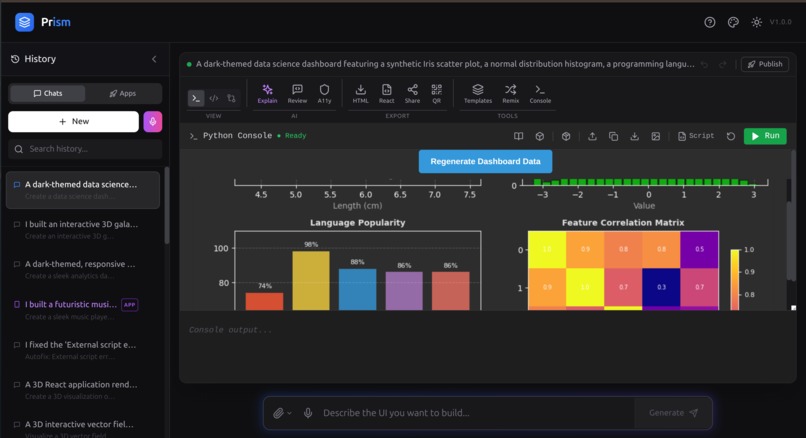
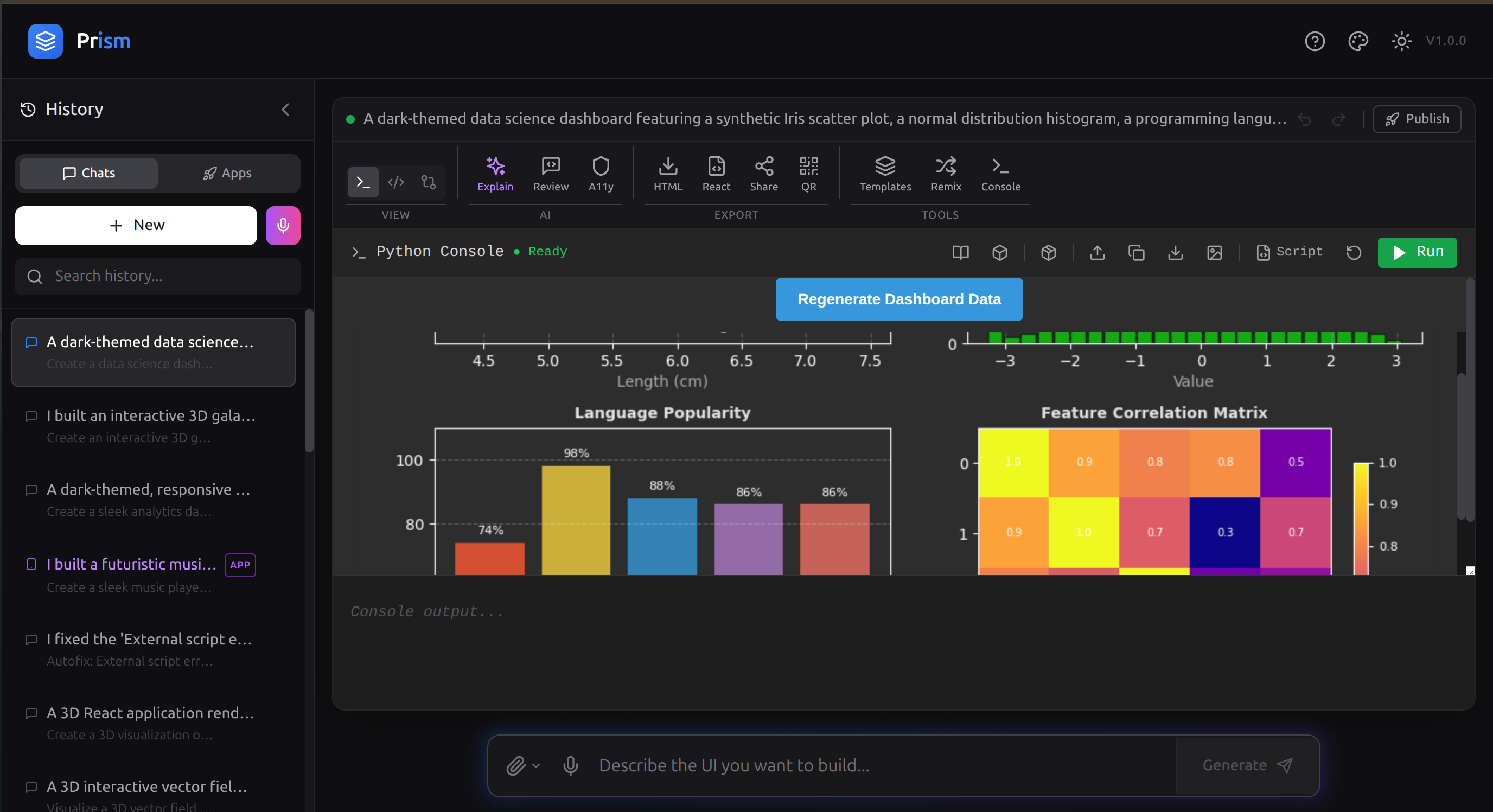
Python Console
-
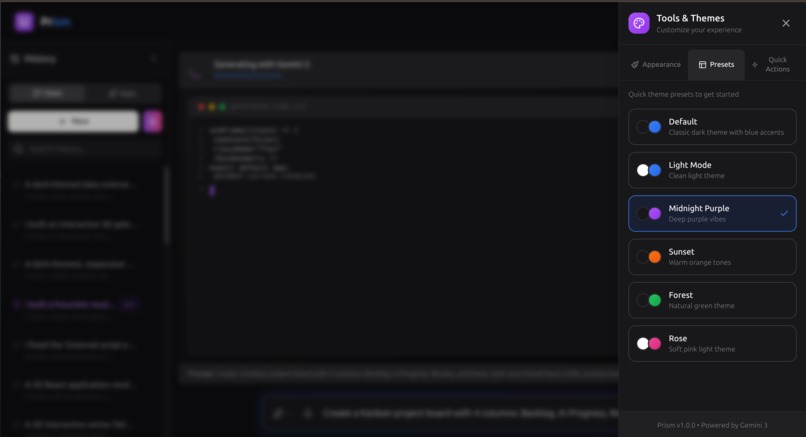
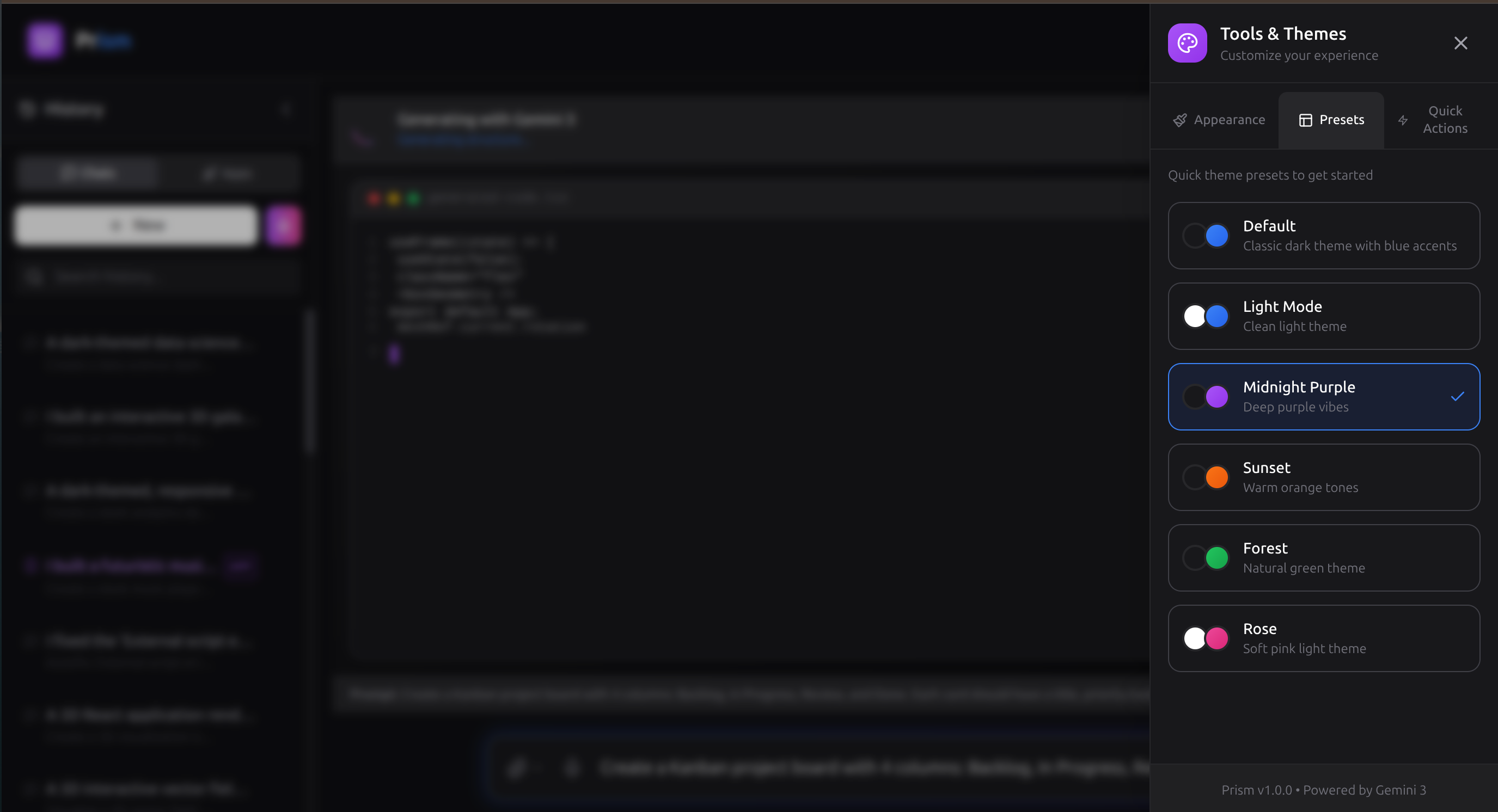
Tools and Themes Tab
-
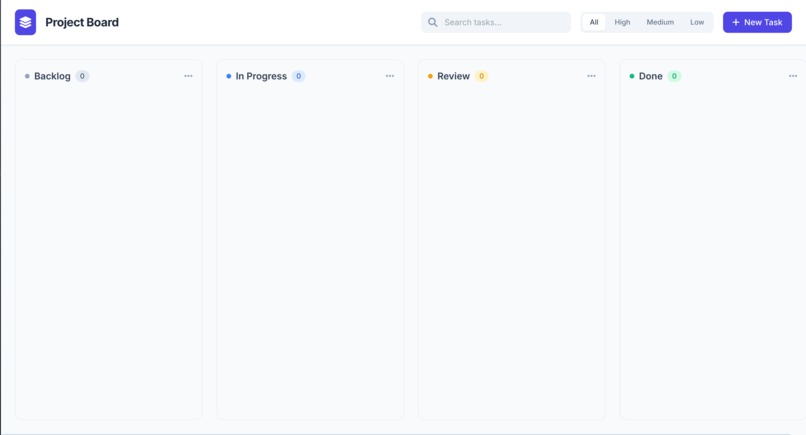
Project Board Website launched by Prism
-
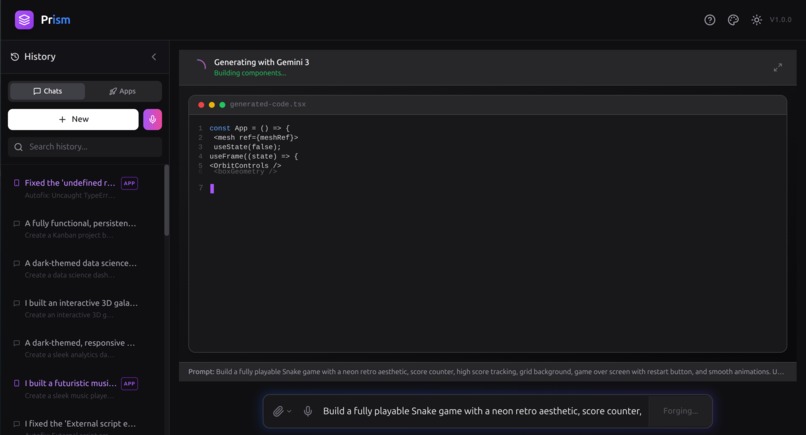
Code being written
-
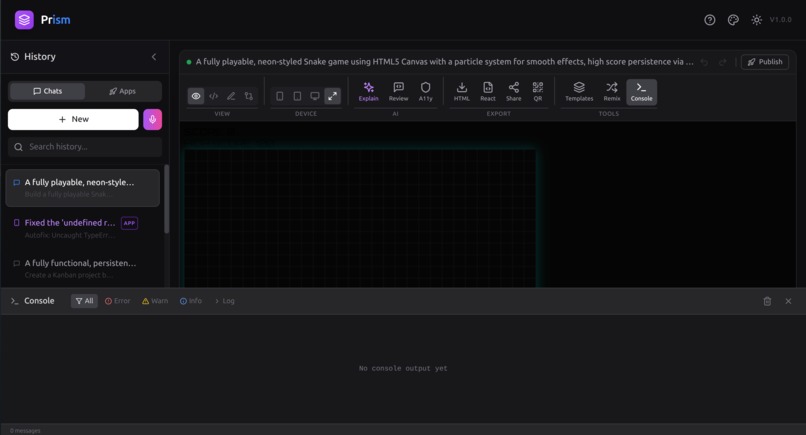
Built-in Console
-
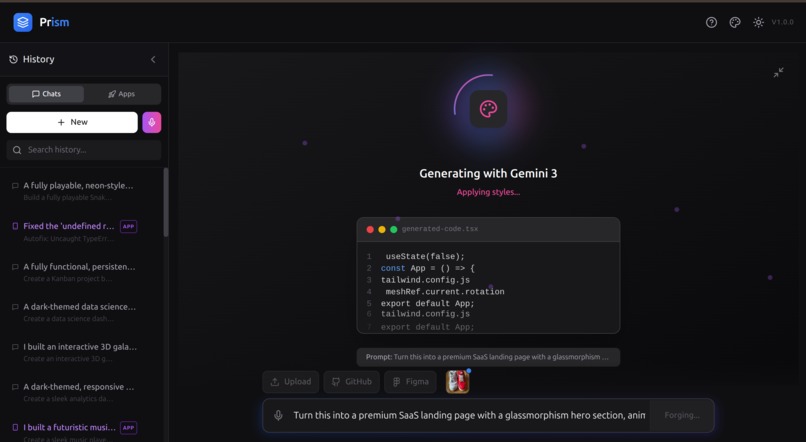
Image Upload for generation
Inspiration
As a Mechanical Engineering and Physics student at UNC Charlotte, I work across hardware and software every day — designing drone control stacks with ROS2 at SmartNet Lab, building Arduino-based EMG sensors for cerebral palsy patients, and leading CAD workshops as an Autodesk Design and Make Ambassador. Across all of these, I kept hitting the same bottleneck: turning ideas into working software prototypes is painfully slow.
During my Drone Swarm Simulation research, I needed quick dashboard UIs to visualize multi-agent telemetry — position vectors, velocity fields, coordination metrics.
But every time I wanted to see this data rendered as an interactive chart, I'd lose hours to React boilerplate before writing a single line of actual research code. The same friction surfaced when building Polly — my sub-40 EMG sensor for cerebral palsy patients. I needed a companion app to visualize muscle signal progression, but the frontend work alone was a barrier.
Meanwhile, tools like v0.dev and Bolt.new only generate basic HTML or React — no 3D, no Python, no voice input, no code review. I realized what was missing: a truly universal code generator powered by the multi-modal intelligence of Gemini 3.
The name came naturally. Like light through a prism, one input should refract into infinite outputs. Prism was born.
What it does
Prism transforms natural language, images, and voice into production-ready code in seconds — powered entirely by Gemini 3.
Multi-modal input, universal output. Speak an idea, upload a wireframe, or type a prompt. Gemini 3 Pro Preview processes all modalities in a single request and generates working code across four output modes:
- React Components & Dashboards — production-ready UI with Tailwind CSS
- 3D WebGL Scenes — interactive React Three Fiber visualizations with physics and post-processing (no other AI code tool does this)
- Python + Data Visualization — matplotlib charts and numpy calculations running in-browser via Pyodide WebAssembly (no other AI code tool does this either)
- Standard HTML/CSS/JS — landing pages, forms, and modern static sites
Beyond generation, Prism uses Gemini 3 Flash Preview to power:
- AI Code Review — quality scores across performance, accessibility, and structure
- WCAG 2.1 Accessibility Auditing — automated compliance checking
- Code Explanation — structured breakdowns of how generated code works
- Auto-fix — automatic runtime error detection and repair
Users can export to React (TSX), Vue 3 (SFC), or Svelte, share via compressed URLs or QR codes, remix multiple generations together, and publish apps with custom names, emoji icons, and categories — all from a ribbon-style toolbar.
How we built it
Prism is a zero-backend application — everything runs client-side. The entire architecture centers on Gemini 3 as the intelligence layer.
Gemini 3 Integration (Core)
Gemini 3 Pro Preview handles all code generation through multi-modal content requests:
const response = await ai.models.generateContent({
model: 'gemini-3-pro-preview',
contents: {
parts: [
{ inlineData: { mimeType: 'image/png', data: imageBase64 } },
{ text: userPrompt }
]
},
config: {
systemInstruction: SYSTEM_INSTRUCTION,
tools: [{ googleSearch: {} }] // Search grounding for current APIs
}
});
Key Gemini 3 capabilities we leverage:
- Multi-modal understanding — text, images, and audio processed in a single API call
- Vision analysis — wireframe/screenshot to pixel-accurate UI code
- Google Search grounding — real-time access to current documentation and APIs
- Structured output — JSON response format for code review and accessibility audits
Gemini 3 Flash Preview powers the fast-feedback features:
- Audio transcription — converts voice recordings to text prompts
- Code explanation — analyzes generated code and returns structured breakdowns
- Improvement suggestions — recommends optimizations via
responseMimeType: 'application/json'
Smart Mode Detection
Rather than asking users to pick an output mode, Gemini 3's reasoning capabilities automatically detect intent:
- Python keywords (matplotlib, numpy, pandas)
- 3D/spatial keywords (orbit, sphere, scene)
- Default Tailwind CSS HTML with embedded JavaScript
Frontend Architecture
| Layer | Technology |
|---|---|
| AI | Gemini 3 Pro Preview, Gemini 3 Flash Preview via @google/genai |
| Framework | React 18, TypeScript, Vite |
| Styling | Tailwind CSS |
| Code Editor | Monaco Editor (VS Code engine) |
| 3D Graphics | React Three Fiber, Three.js, Drei |
| Python Runtime | Pyodide (WebAssembly) |
| Storage | IndexedDB via idb-keyval |
| Sharing | LZ-String compression, QR code generation |
The live preview runs in a sandboxed iframe with hot-reload, error overlay, responsive viewport controls, and a console — so users see results the instant Gemini returns code.
Challenges we ran into
Getting reliable, runnable code from Gemini. LLMs sometimes wrap output in markdown fences, produce browser-incompatible imports, or generate partial code. I built a post-processing pipeline that strips markdown artifacts, validates HTML structure, injects missing CDN dependencies, and handles edge cases — making Gemini's output reliably executable on the first try.
Running Python in a browser sandbox. Pyodide's WebAssembly bundle is ~20MB. I implemented lazy loading so it only downloads when a Python generation is detected. The harder problem was matplotlib — it expects a native display backend that browsers don't provide. I bridged this by intercepting plt.show() calls and redirecting output to an inline SVG renderer within the iframe.
3D scenes in sandboxed iframes. React Three Fiber requires ESM import maps for three, @react-three/fiber, and @react-three/drei to resolve correctly inside a sandboxed context. Getting CORS, module resolution, and WebGL renderer initialization working reliably across Chrome, Firefox, and Safari required extensive iteration.
Multi-modal prompt orchestration. Combining image + text + voice context into a single coherent Gemini request — while preserving user intent — required careful prompt construction. A user might upload a wireframe, add a text refinement, and have prior conversation history. Structuring this as a multi-turn, multi-part content array for Gemini 3 was non-trivial.
Accomplishments that we're proud of
- First AI code generator with 3D WebGL output — no existing tool (v0.dev, Bolt.new, or otherwise) generates interactive React Three Fiber scenes from natural language
- First AI code generator with in-browser Python — full Pyodide runtime with matplotlib, no server infrastructure
- True multi-modal pipeline — text, voice, and image all feed into a single Gemini 3 generation call
- Zero-backend architecture — the entire app runs client-side, making it fast, private, and free to scale
- Gemini 3 powers 6 distinct features — code generation, voice transcription, code explanation, code review, accessibility auditing, and improvement suggestions
- 15+ built-in templates spanning dashboards, landing pages, games, 3D scenes, and data visualizations
- App publishing system — users can name, categorize, tag, and manage a library of AI-generated apps
- Sharing via URL compression — using LZ-String where compressed size satisfies $S_c \approx S_o \cdot \frac{H(X)}{\log_2 |\Sigma|}$, making entire apps shareable as a single link
What we learned
Gemini 3's multi-modal reasoning is genuinely different. Processing text + image + audio in one request isn't just a convenience — it changes what's possible. A user can photograph a whiteboard sketch, say "make it dark mode with a sidebar," and get a working app. That workflow doesn't exist anywhere else, and it's only feasible because Gemini 3 Pro Preview handles all three modalities natively.
Search grounding is underutilized. By enabling tools: [{ googleSearch: {} }] in our Gemini config, Prism generates code that references current APIs and documentation — not stale training data. This is especially valuable for fast-moving ecosystems like React and Three.js.
System prompt engineering is as important as the model. The difference between Gemini producing clean, self-contained, runnable code versus code that crashes the sandbox came down to iterative refinement of system instructions. Specifics like "do not use markdown fences," "include all CSS inline," and "use CDN imports only" made the output dramatically more reliable.
Frontend-only architectures are more powerful than people think. By combining IndexedDB, Pyodide (WASM), sandboxed iframes, and client-side Gemini API calls, I built a full-featured application with zero server infrastructure. No database, no backend, no DevOps — just a static deploy on Vercel that scales infinitely.
What's next for Prism
- Collaborative editing — real-time multiplayer code generation using CRDTs, so teams can prompt and iterate together
- Plugin system — let users add custom output modes (Flutter, SwiftUI, React Native) beyond the built-in four
- Version branching — fork any generation and explore different directions, with visual diff between branches
- Gemini-powered debugging — when code errors occur, automatically send the error + code back to Gemini for intelligent fixes with explanations
- Backend generation — expand beyond frontend to generate Express/FastAPI servers alongside the UI, creating full-stack apps from a single prompt
- Community template marketplace — let users publish, share, and remix templates, building a library of community-contributed starting points
- Mobile companion app — voice-first prototyping on the go, leveraging Gemini Flash for low-latency generation
Built With
- css3
- drei
- gemini
- google/genai
- html
- idb-keyval
- indexeddb
- javascript
- lucide
- lz-string
- monaco
- pyodide
- python
- react
- tailwind
- three.js
- typescript
- vercel
- vite

Log in or sign up for Devpost to join the conversation.