💡 Inspiration
We’ve all seen Tony Stark interact with J.A.R.V.I.S. and E.D.I.T.H.—AI assistants that don't just "chat," but actually perceive the world. Most current AI is trapped in a text box. We were inspired to break that barrier. With the release of Gemini 3, we finally had a reasoning engine powerful and fast enough to act as a Spatial Operating System. We wanted to build a tool that feels like specialized hardware—a digital layer over reality that identifies, extracts, and reasons about your physical environment in real-time.
🚀 What it does
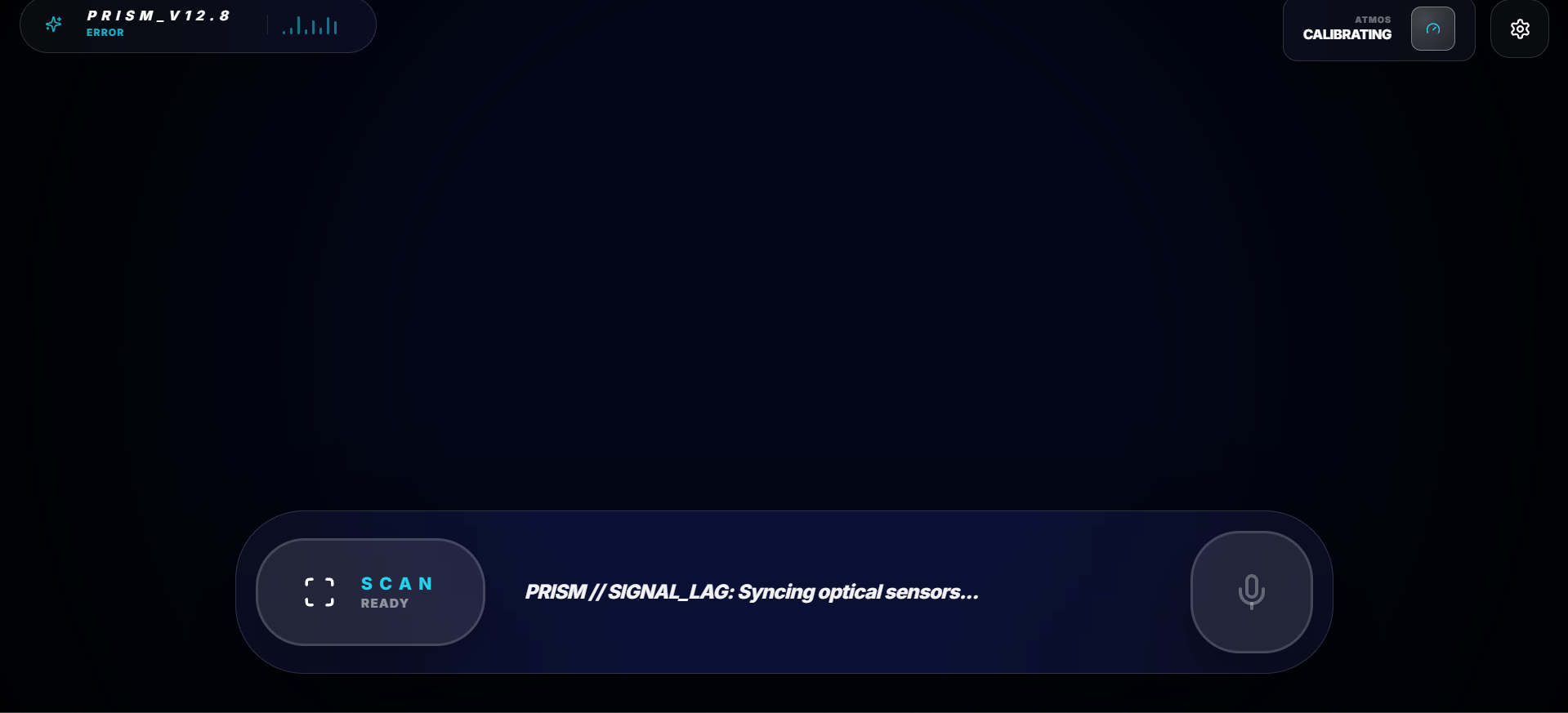
PRISM (Perceptive Real-time Integrated System Manager) is a J.A.R.V.I.S.-class spatial HUD. Tactical Scan: Using the device's camera, PRISM scans the environment and identifies key objects (ROIs).
Visual Extraction: Unlike other apps, PRISM physically "extracts" high-resolution thumbnails of detected objects into a visual tray for inspection. Logic Stream: Users can view the AI’s internal reasoning monologue scrolling in a terminal, showing exactly how Gemini 3 is analyzing the scene. Mission Protocols: PRISM adapts its intelligence based on the mode—whether it's technical Field Repair, Safety Protocols, or Wellness Scans.
🛠️ How we built it
We built PRISM using Next.js 15 and the new Gemini 3 SDK (@google/genai). The Core: We utilized Gemini 3 Flash Preview to achieve a balance between high-IQ reasoning and conversational speed. Vision: We leveraged media_resolution_high to ensure the AI could provide precise X/Y coordinates for objects.
Processing: We developed a custom "serial cropping engine" using the HTML5 Canvas API to take the AI's coordinates and physically extract the thumbnails from the video feed. UI/UX: The interface is built with Tailwind CSS and Framer Motion, utilizing experimental glassmorphism to create a "specialized hardware" aesthetic.
🧠 Challenges we faced
The biggest challenge was Coordinate Syncing. Translating Gemini’s percentage-based coordinates into exact pixel crops for thumbnails while maintaining a high frame rate was difficult. We also had to implement a robust fallback logic system and isProcessing state locks to manage Gemini 3's preview-tier rate limits, ensuring the app never crashed during a tactical scan.
🏆 Accomplishments that we're proud of
We successfully bridged the gap between raw LLM output and Augmented Reality. Seeing PRISM accurately "tag" a laptop on the screen and then instantly display a zoomed-in, cropped photo of that laptop in the tray felt like a true "Iron Man" moment. We also achieved a near-zero latency feel by optimizing Gemini 3's thinking_level: low setting.
📖 What we learned
We learned that Gemini 3's Thought Signatures are a game-changer for spatial assistants. By maintaining the "logic state" across turns, the AI remembers why it flagged a hazard or identified a tool, making follow-up questions feel incredibly natural.
🔭 What's next for PRISM
We see PRISM as the software layer for future Smart Glasses. We plan to integrate Agentic Tool Use (via the Google ADK) to allow PRISM to control smart home devices or deploy code based on the hardware it "sees" on your desk.
Built With
- canvas-api
- framer-motion
- gemini
- gemini-3-api-flash-preview
- next.js
- tailwind
- typescript
- web-speech-api

Log in or sign up for Devpost to join the conversation.