-

Animated logo
-
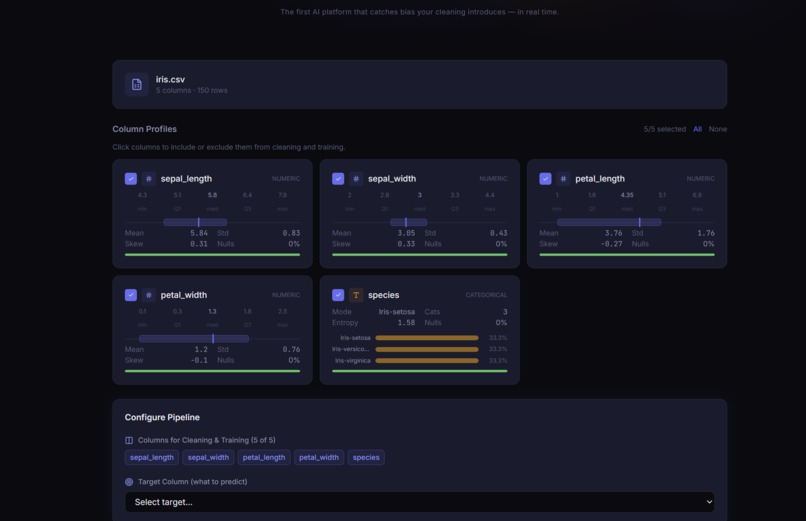
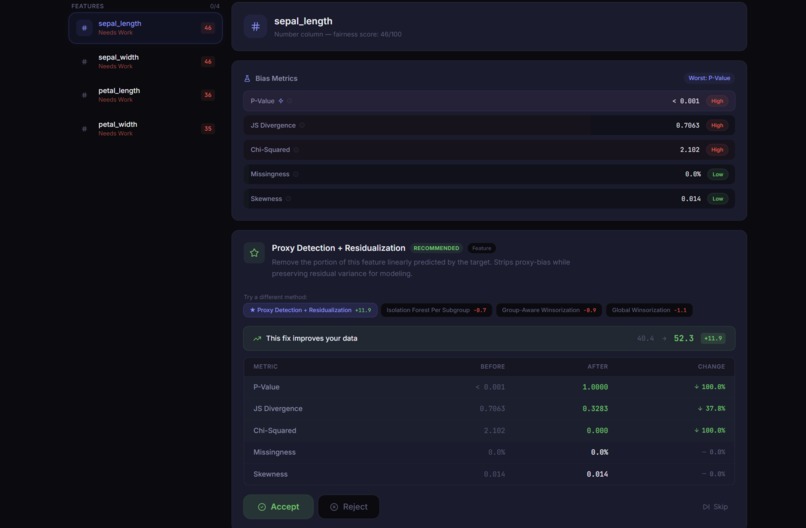
Raw statistics profile
-
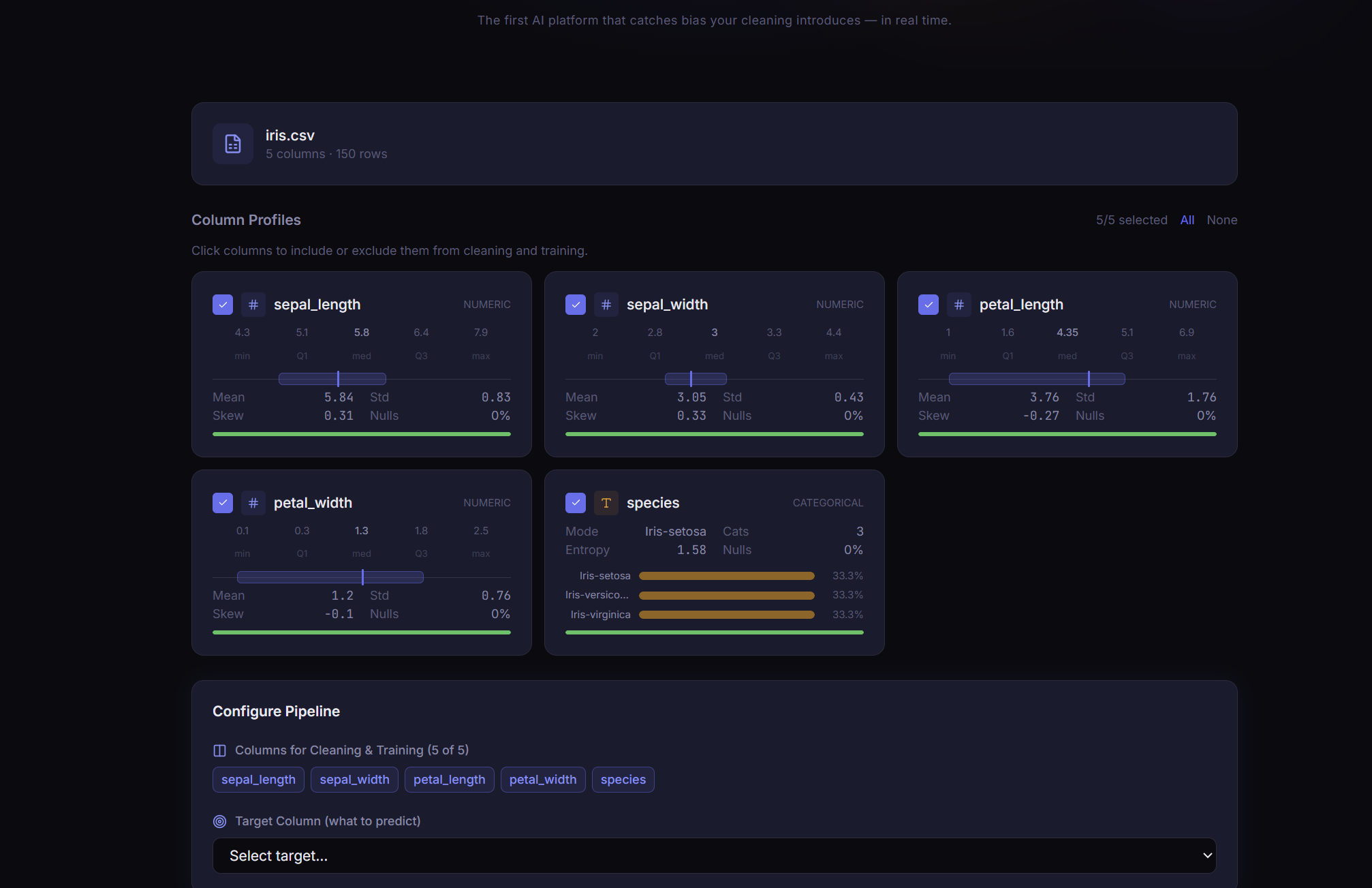
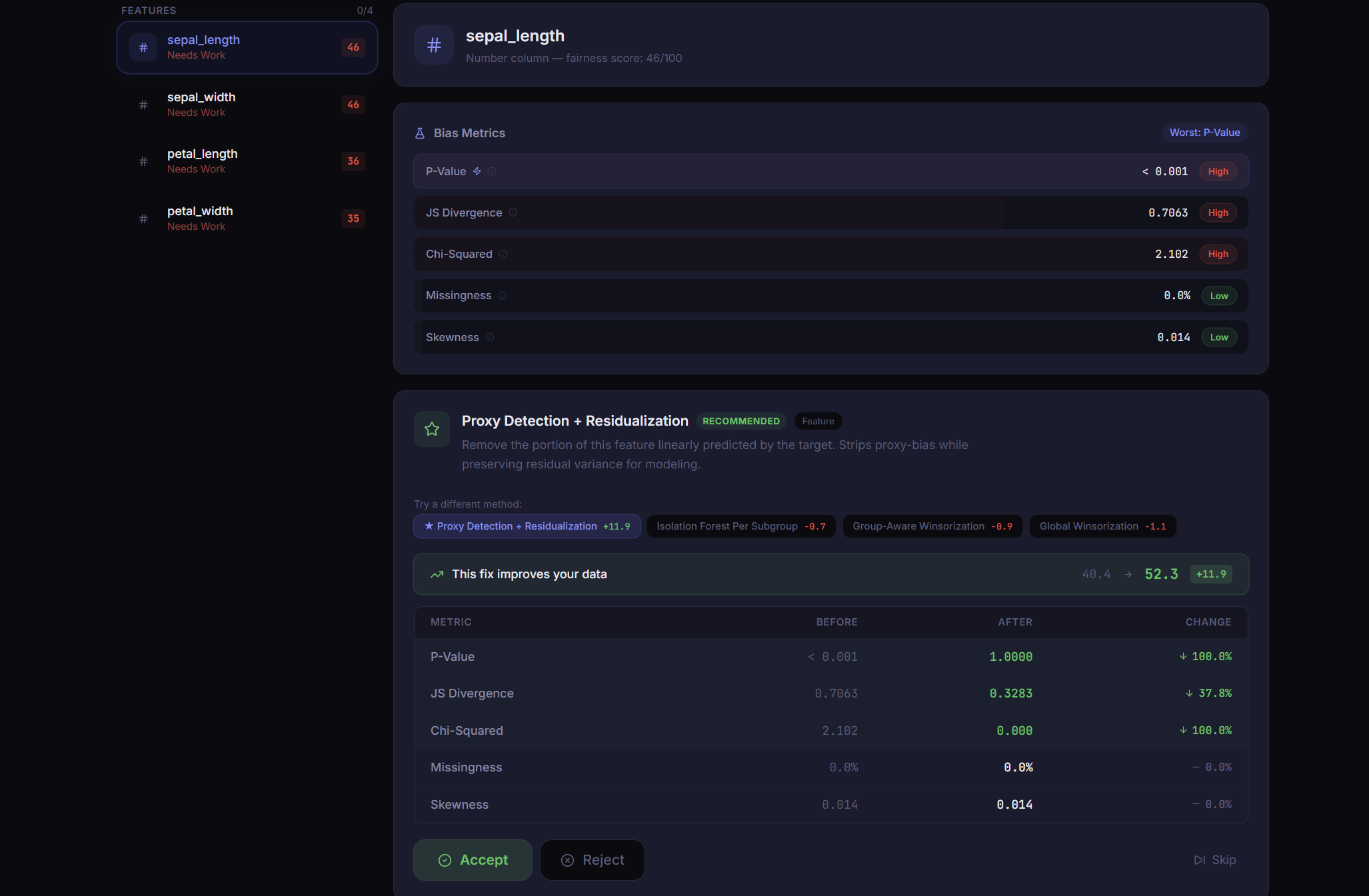
Cleaning suggestions

Inspiration
Over 80% of real-world datasets contain hidden biases: class imbalances, missing values concentrated in demographic subgroups, and feature distributions that silently encode discrimination. Yet the standard ML workflow treats data cleaning as an afterthought and model fairness as someone else's problem. We wanted to build a tool that makes responsible AI the default, not the exception.
What it does
PRISM is a five-stage guided pipeline for training bias-aware machine learning models on tabular data. You drop in a CSV, and PRISM profiles every column, then computes a multi-dimensional fairness score using Jensen-Shannon Divergence, class imbalance ratios, missingness disparity, Cohen's D, and Chi-squared tests. An interactive cleaning session proposes targeted fixes and lets you preview, commit, or revert each change with live bias re-scoring. A Bias Gate then acts as a hard checkpoint: pass the fairness threshold to proceed, or submit a written justification to override, creating an audit trail. Finally, PRISM trains your chosen model with stratified splits and hyperparameter tuning, then generates feature importances and subgroup performance breakdowns to certify equitable behavior.
How we built it
The frontend is React and TypeScript on Vite, styled with Tailwind CSS, with Framer Motion for stage transitions and Zustand for pipeline state. The backend is a Python Flask API powered by NumPy, Pandas, SciPy, and scikit-learn. The cleaning architecture uses server-side sessions with in-memory DataFrames so the client can propose, preview, and roll back operations independently without touching the live session state.
Challenges we ran into
Defining a single fairness score meaningful across wildly different datasets required combining four independent metrics into a weighted composite and carefully calibrating the output so the numbers felt actionable. Real-time preview without committing required a shadow-copy session model where every proposed operation runs against a temporary DataFrame clone. Building a gate override path that does not trivialize the checkpoint while still allowing legitimate edge cases required the most UX iteration of anything we built.
Accomplishments that we're proud of
We delivered a fully self-contained pipeline from raw CSV to certified model in a single browser session with no external ML platform required. The cleaning session's commit and revert architecture with live re-scoring is something we would genuinely use ourselves, and the Bias Gate as a first-class product concept is something almost no ML tooling offers.
What we learned
Fairness in ML is not one number. It is a family of orthogonal concerns that can pull in opposite directions, and any single metric will mislead you. Designing for responsible defaults changes the entire product feel: when the tool treats bias as a property to measure and own rather than a bug to patch, it shifts how you think about the whole ML process.
What's next for PRISM
The most immediate addition is protected attribute detection, automatically flagging demographic proxies and computing metrics like equalized odds and demographic parity.

Log in or sign up for Devpost to join the conversation.