-
-
Website https://prism.abhi1520.com
-
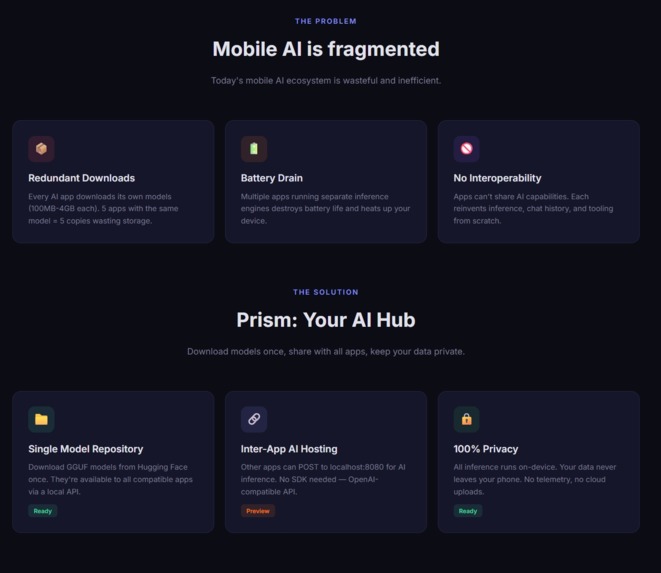
Prism goals
-
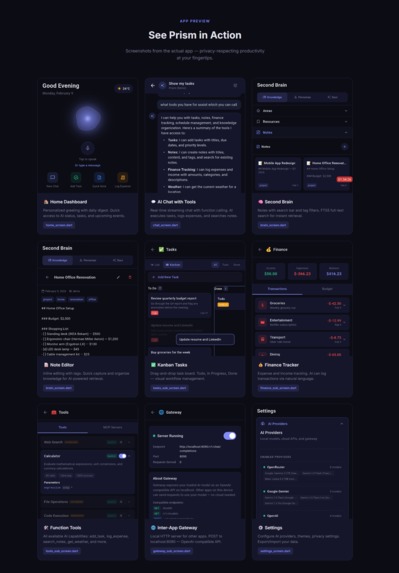
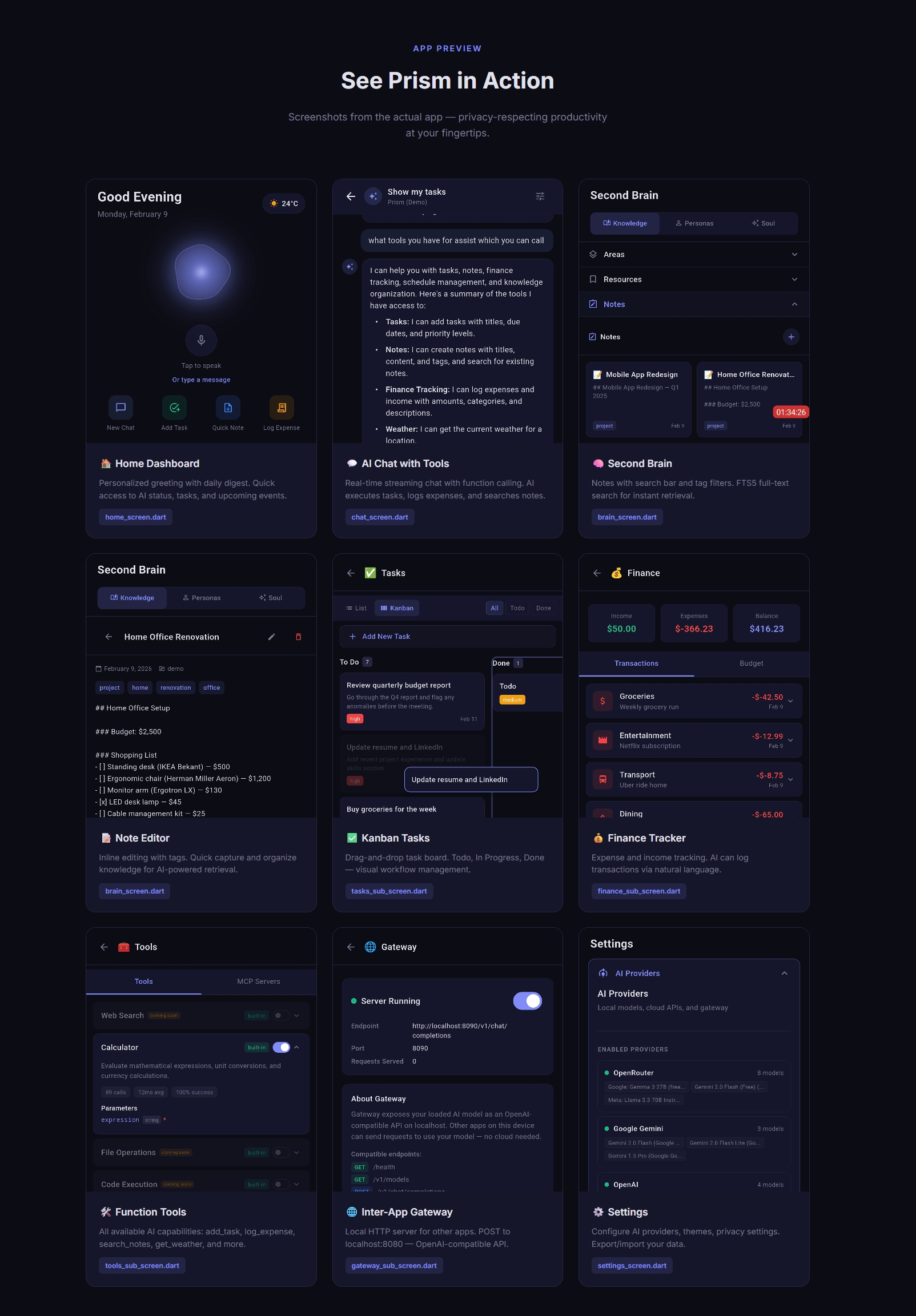
Screenshots with the usecases
-
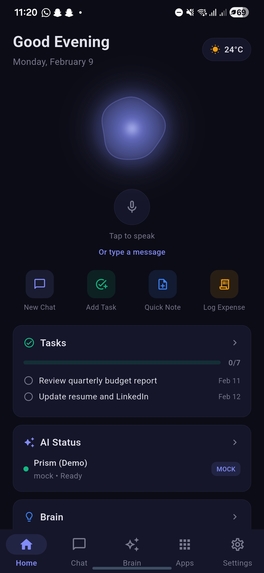
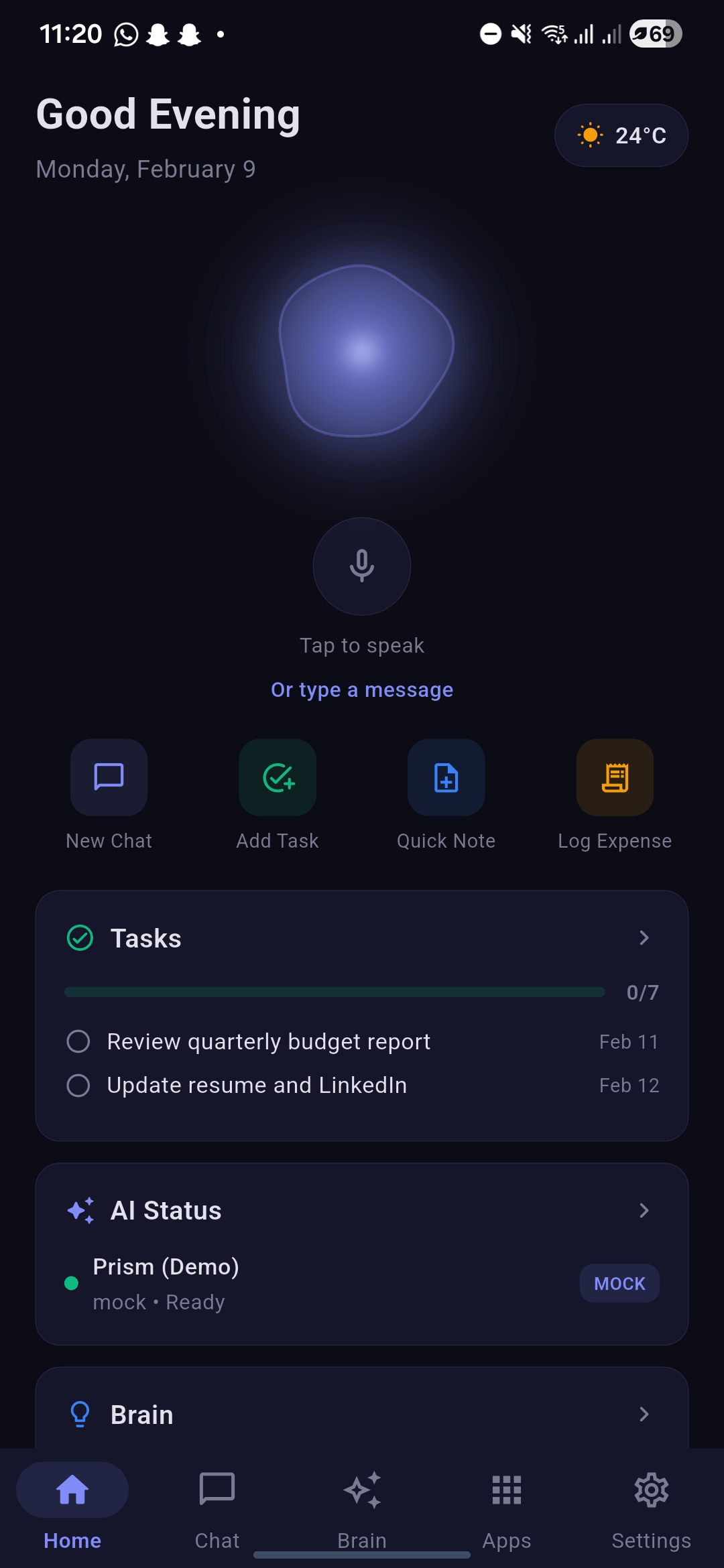
Home section with welcome
-
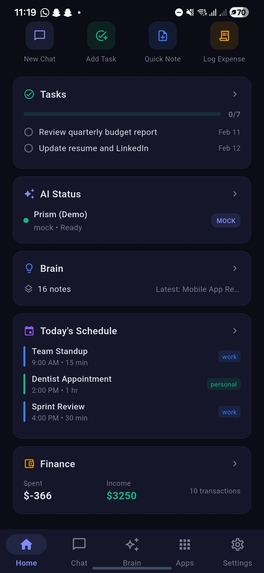
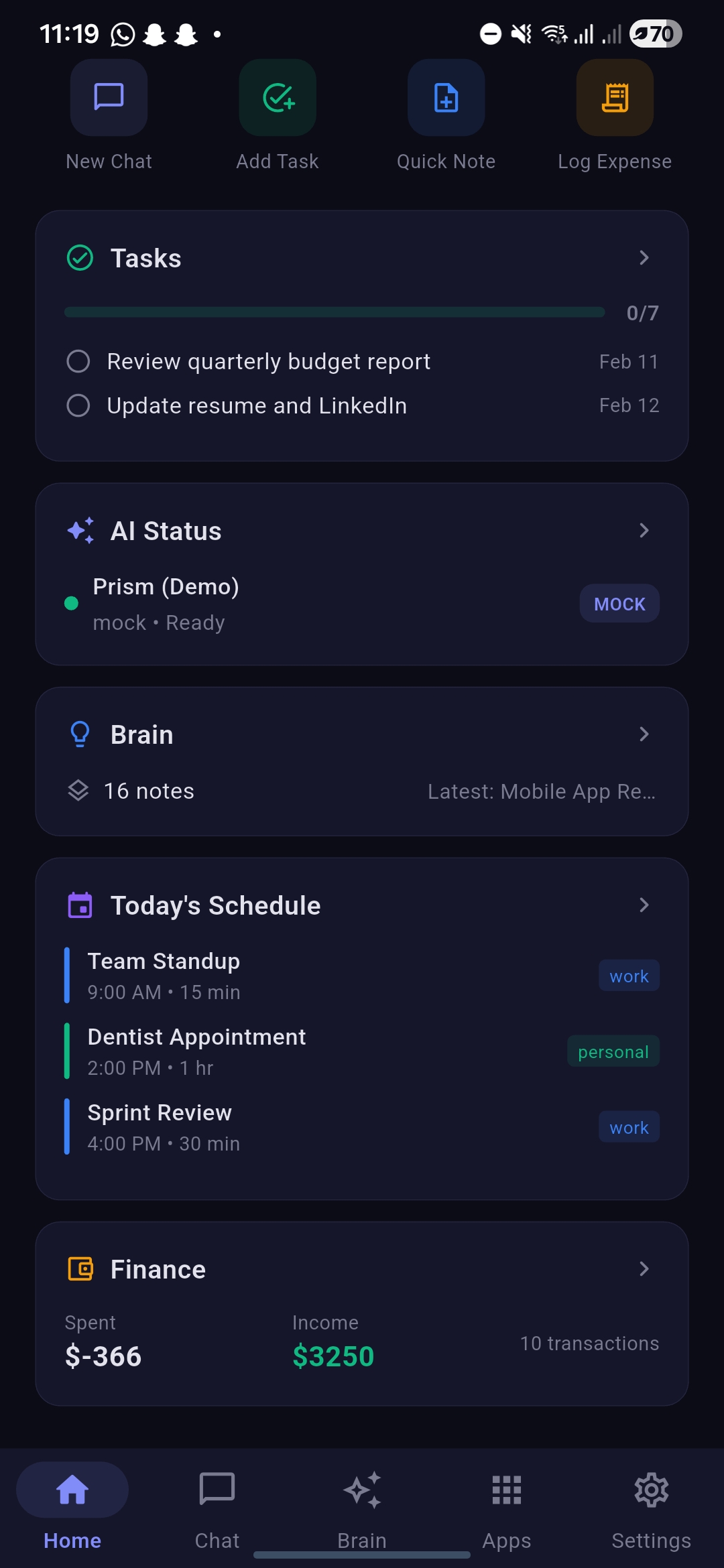
Home section scrolled, showcasing tasks, ai status, schedule, finance
-
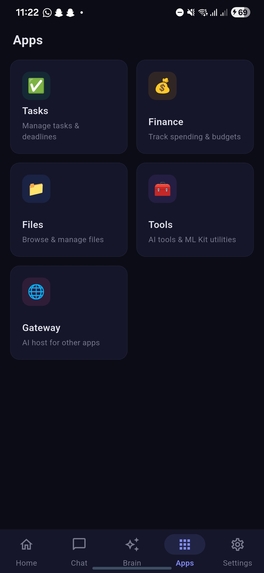
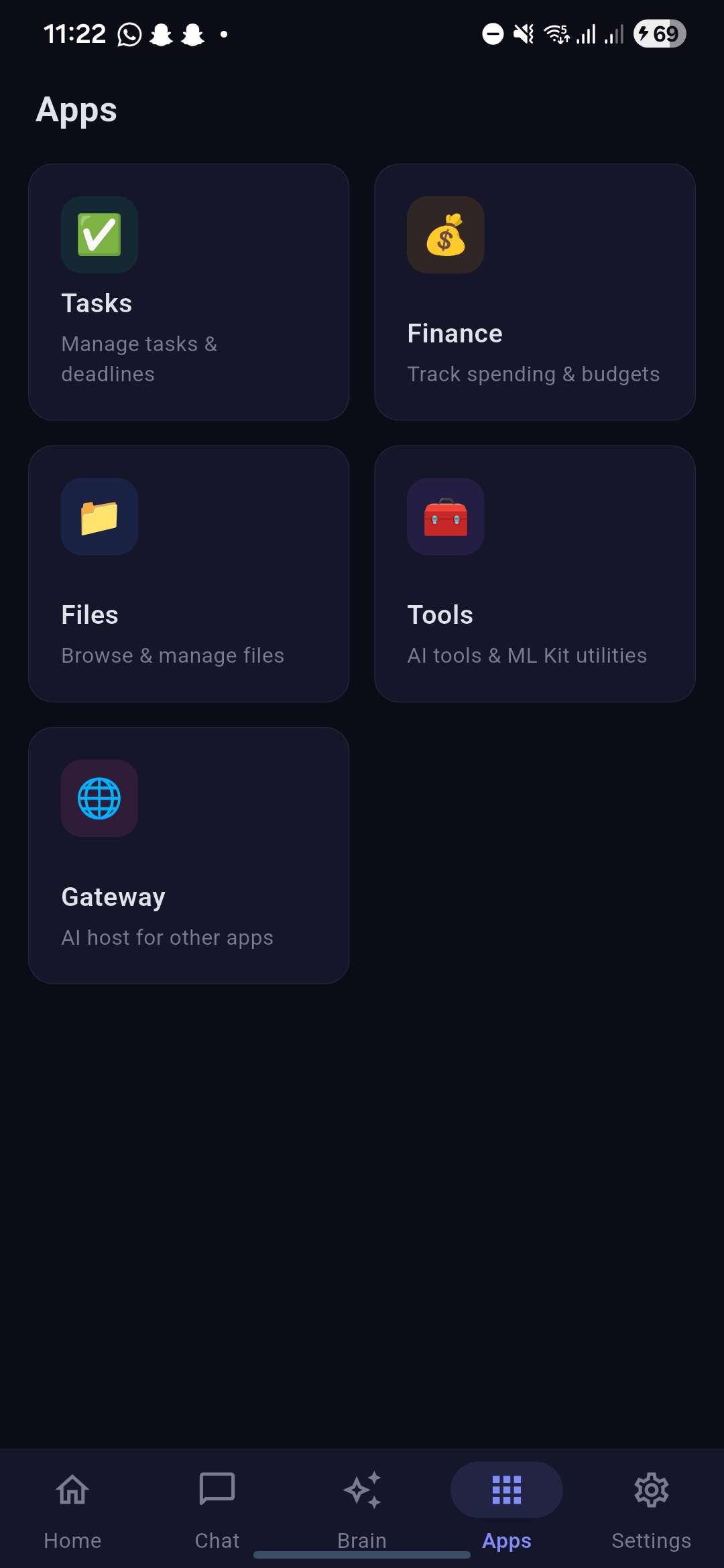
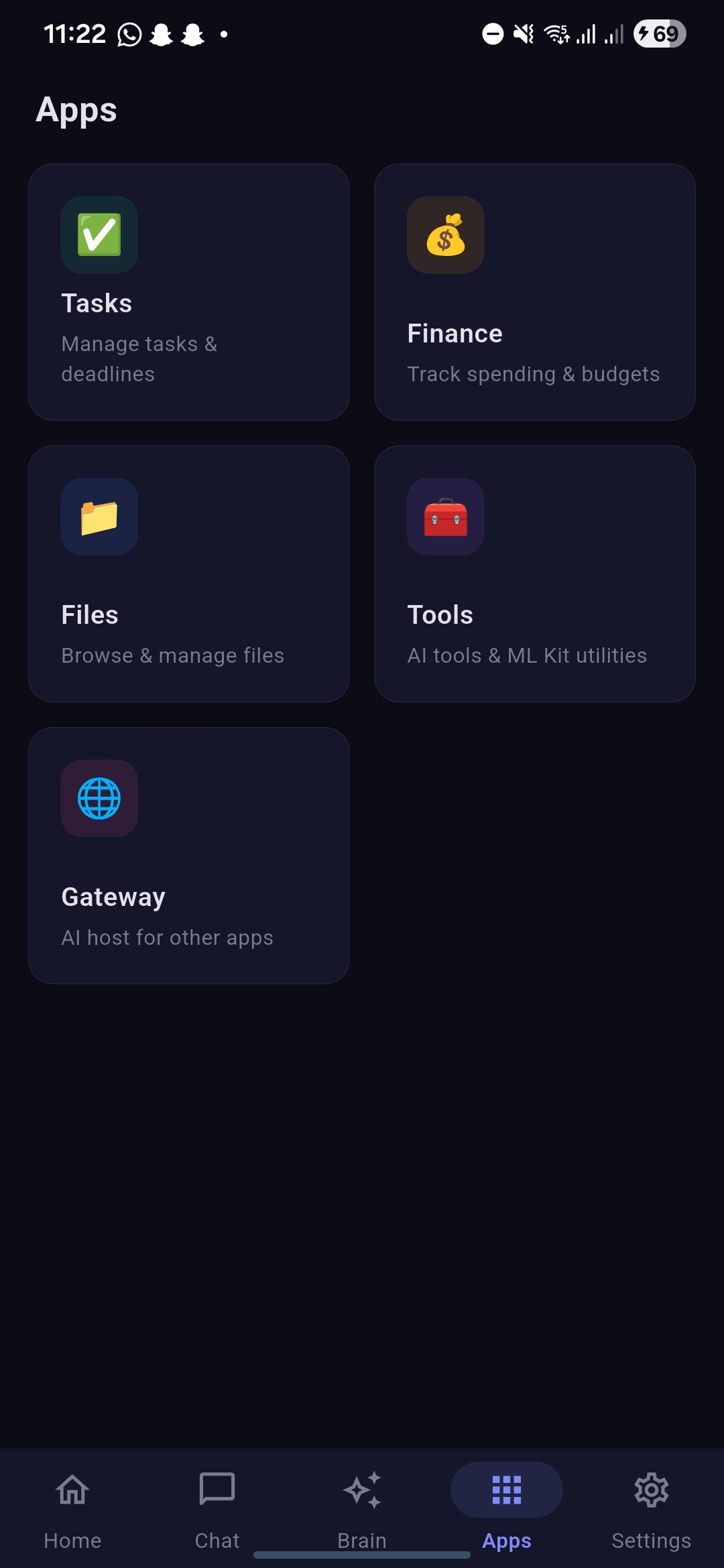
Apps screen showcasing tasks, finance and other options
-
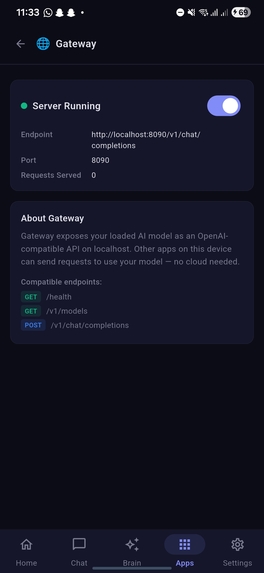
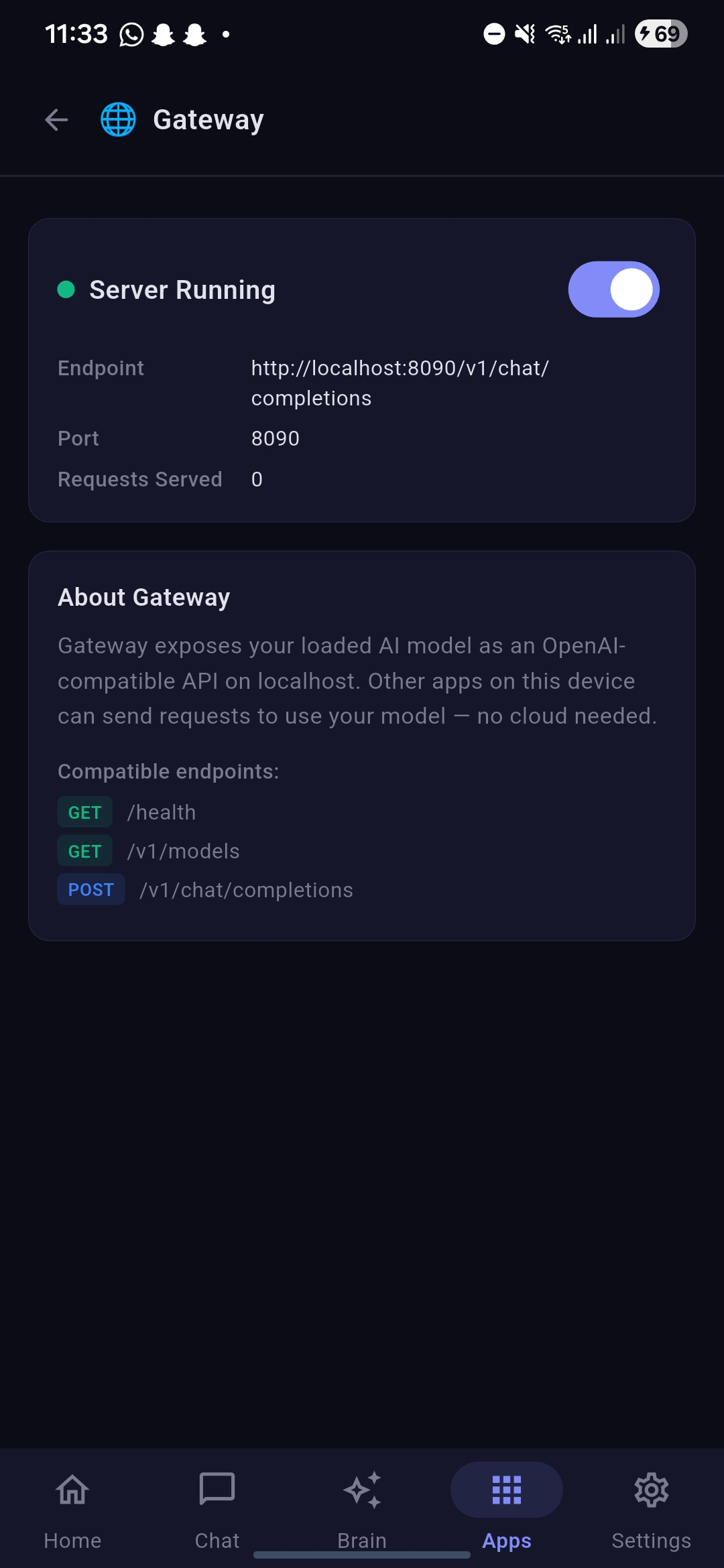
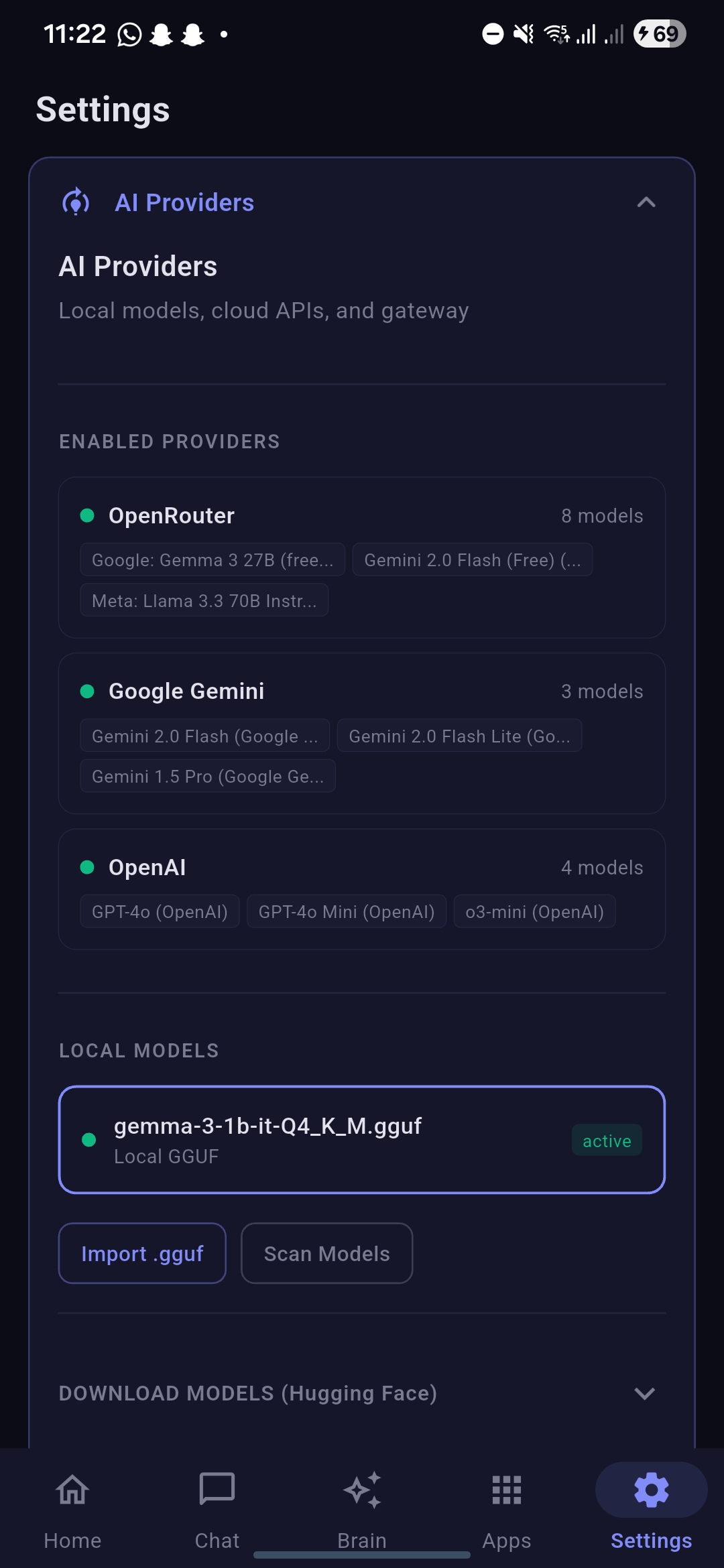
Gateway option enabled under app showcasing the server running
-
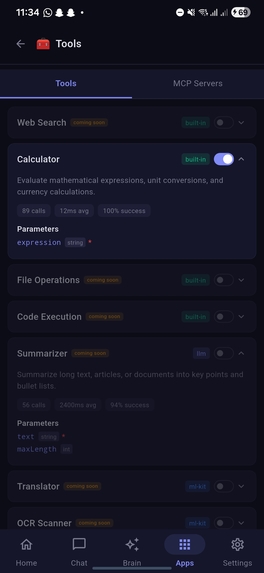
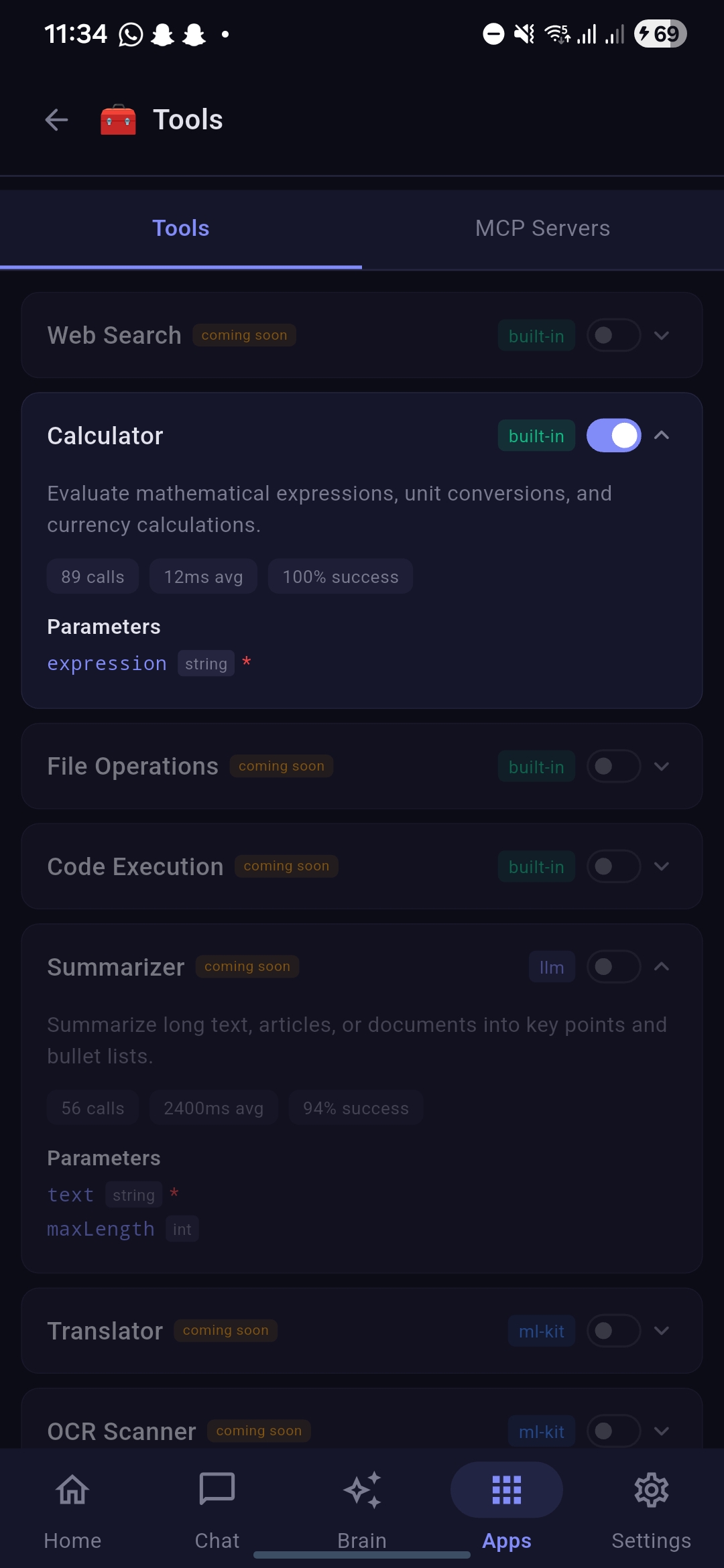
Tools under Apps showcasing tools available for llm
-
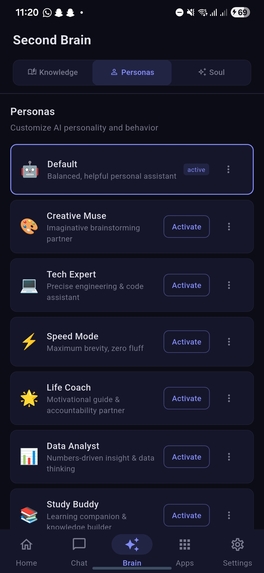
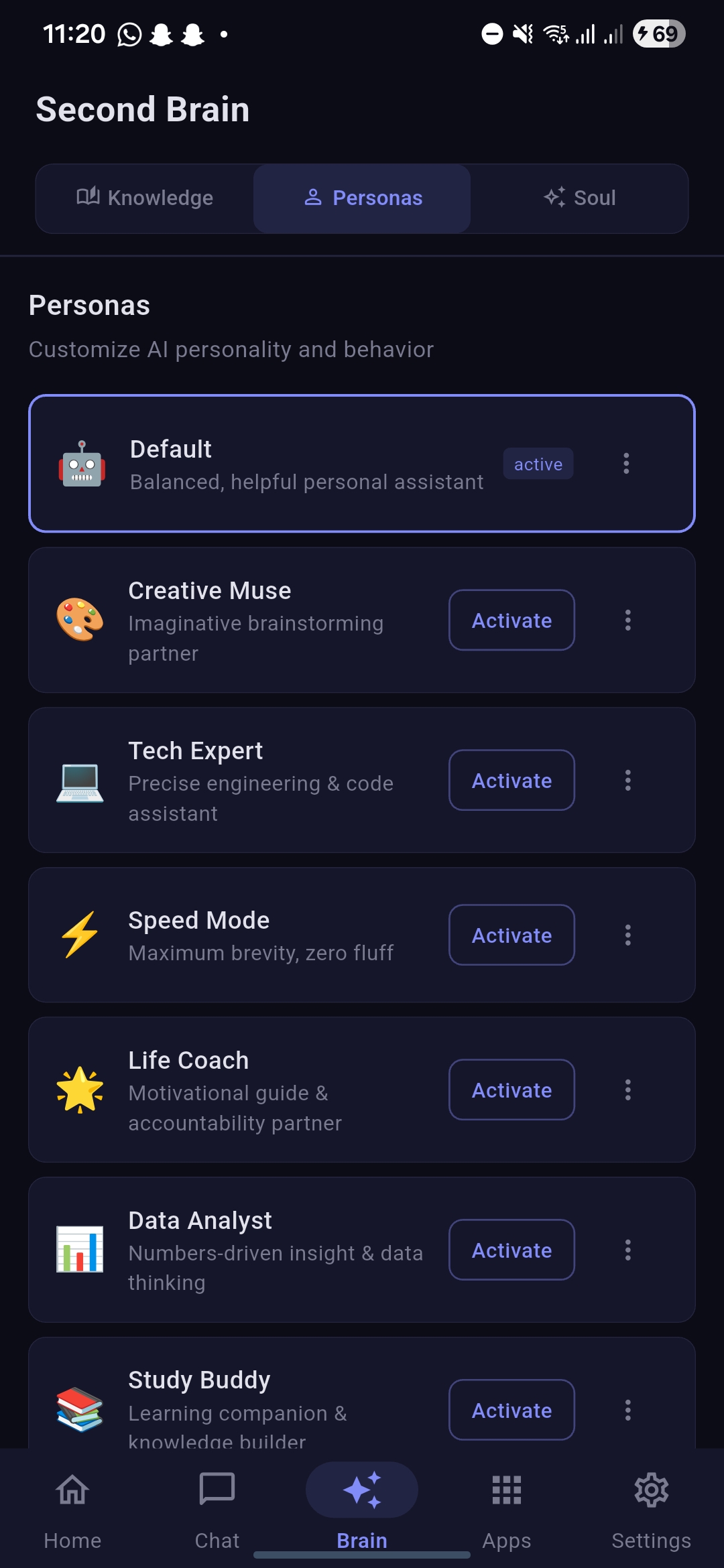
Brain Persona section
-
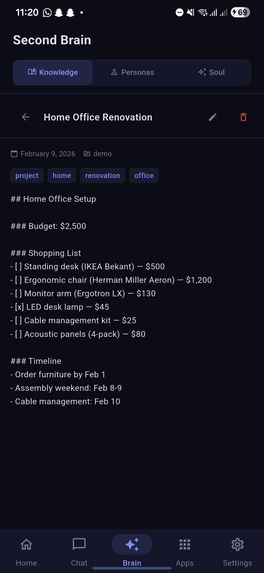
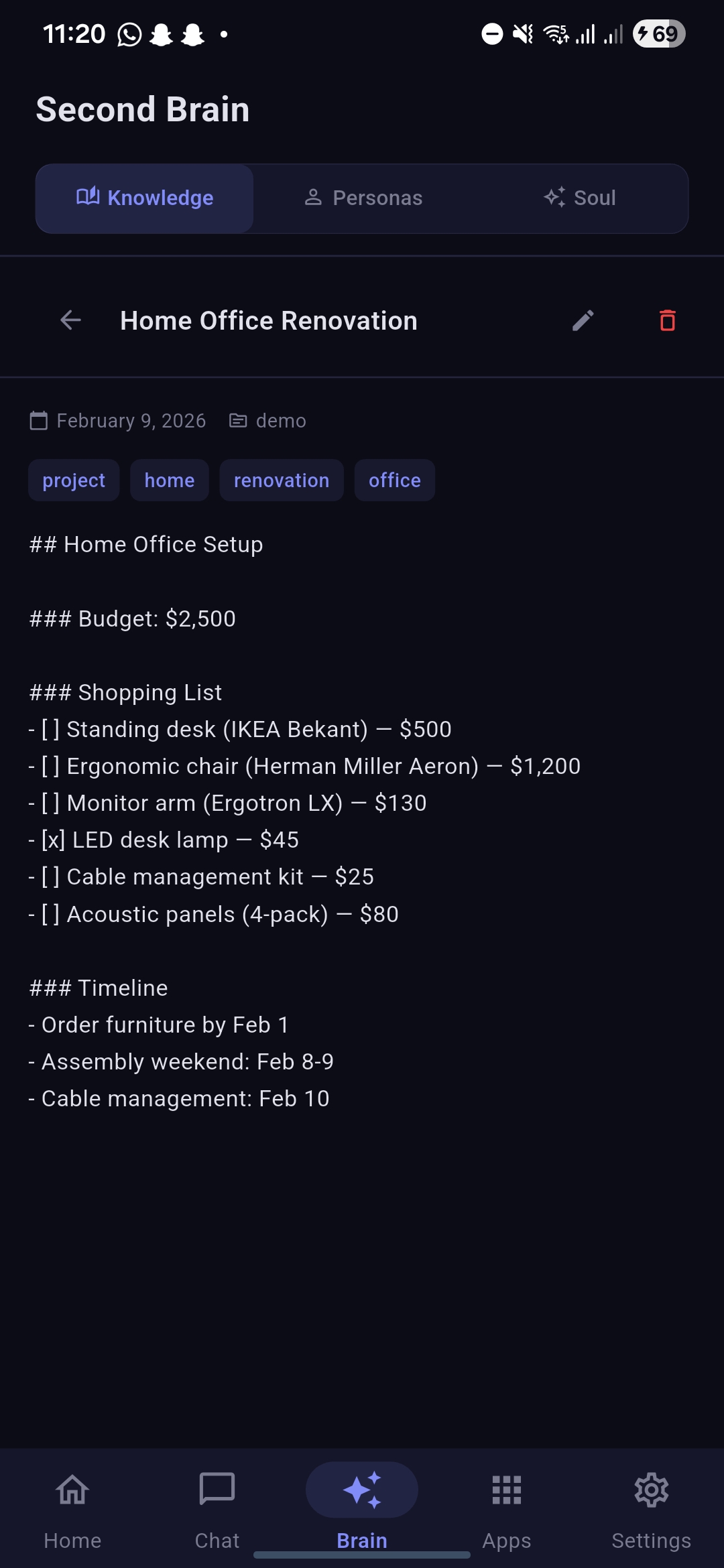
Knowledge section open note showcasing editor
-
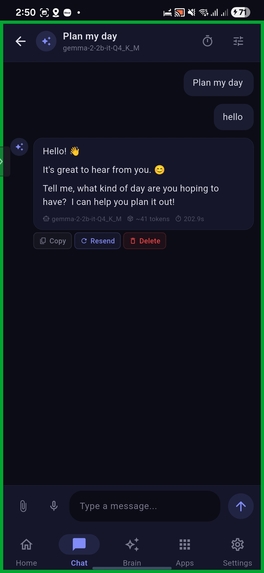
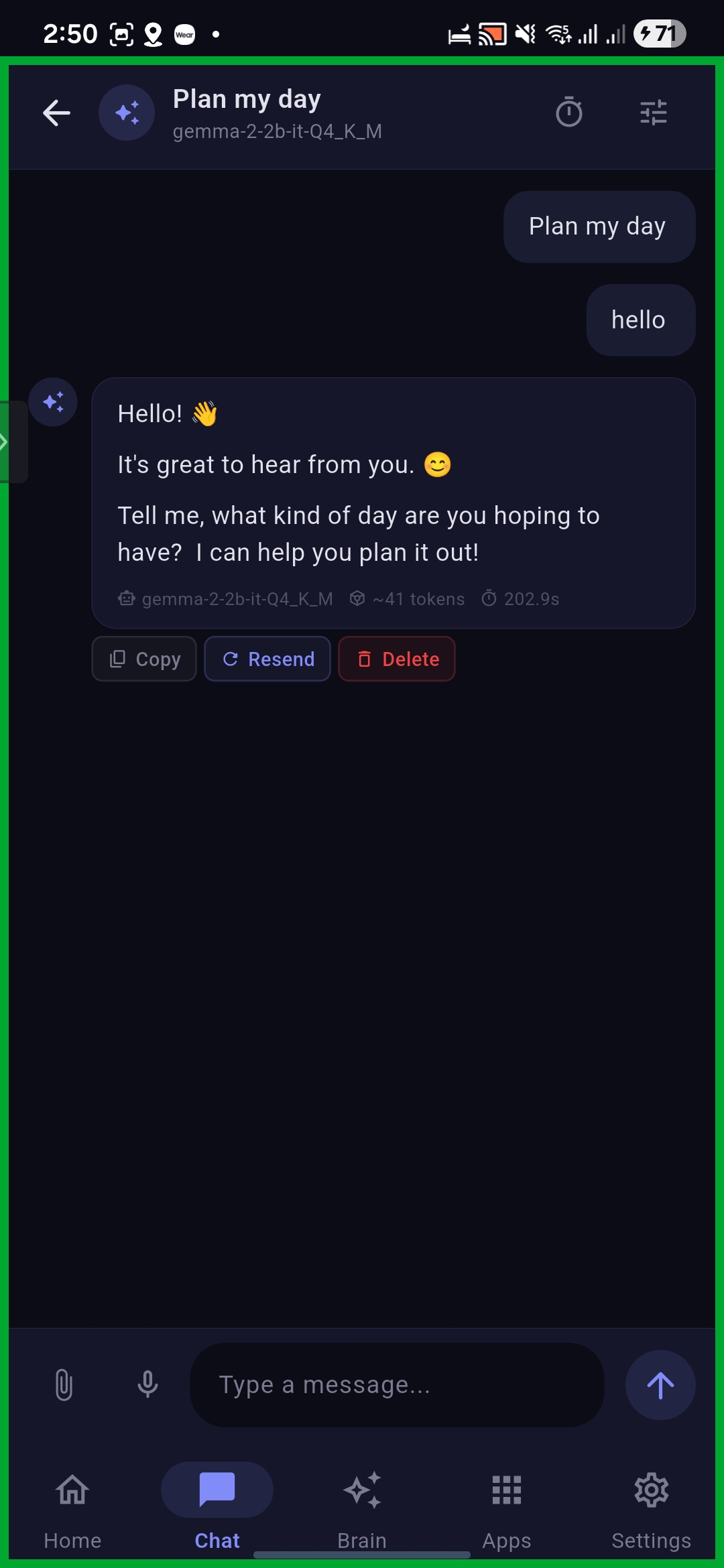
Conversations with local model
-
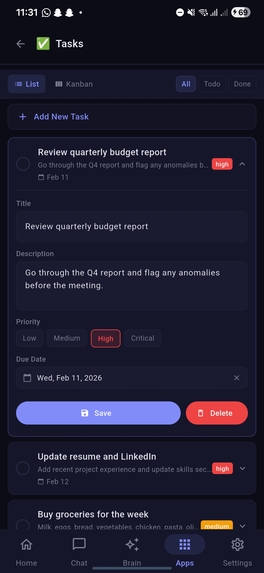
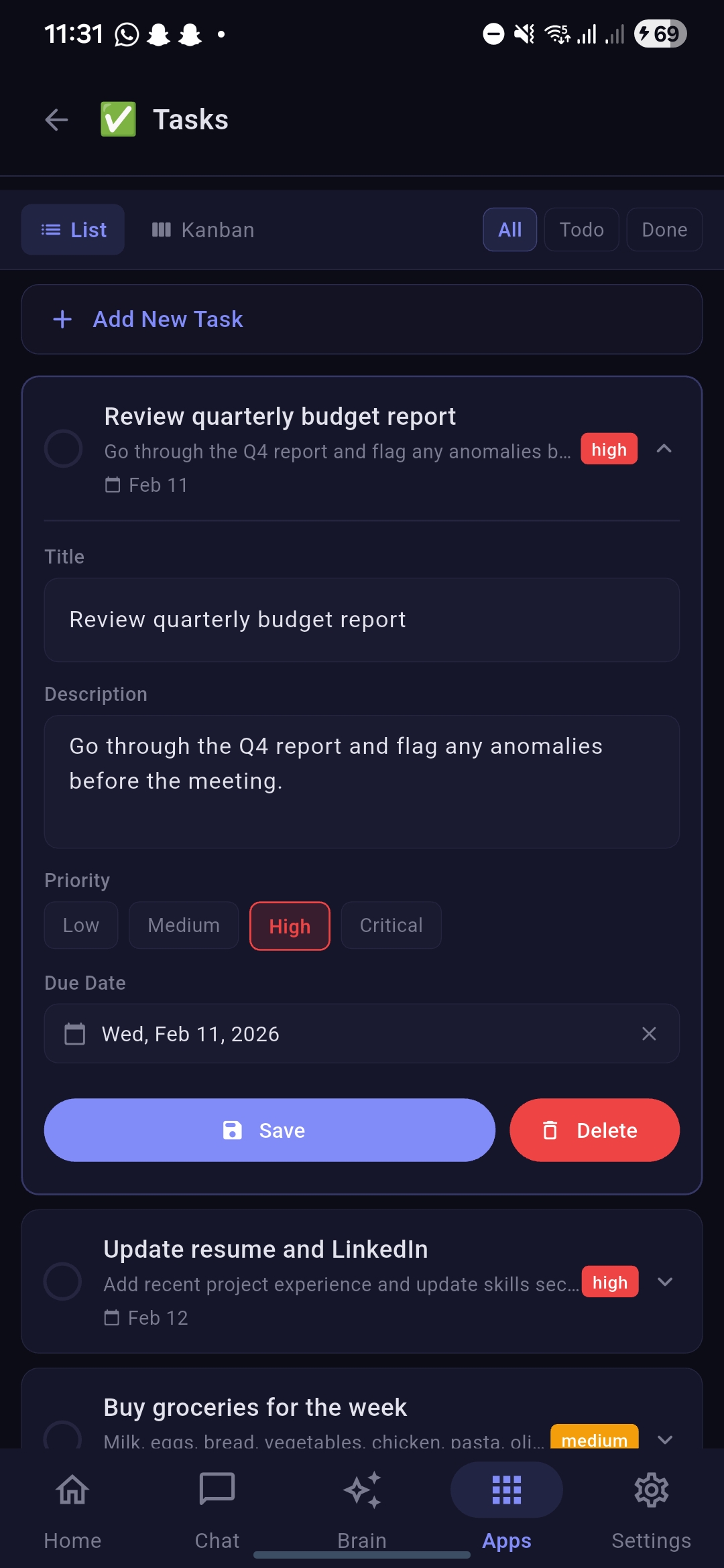
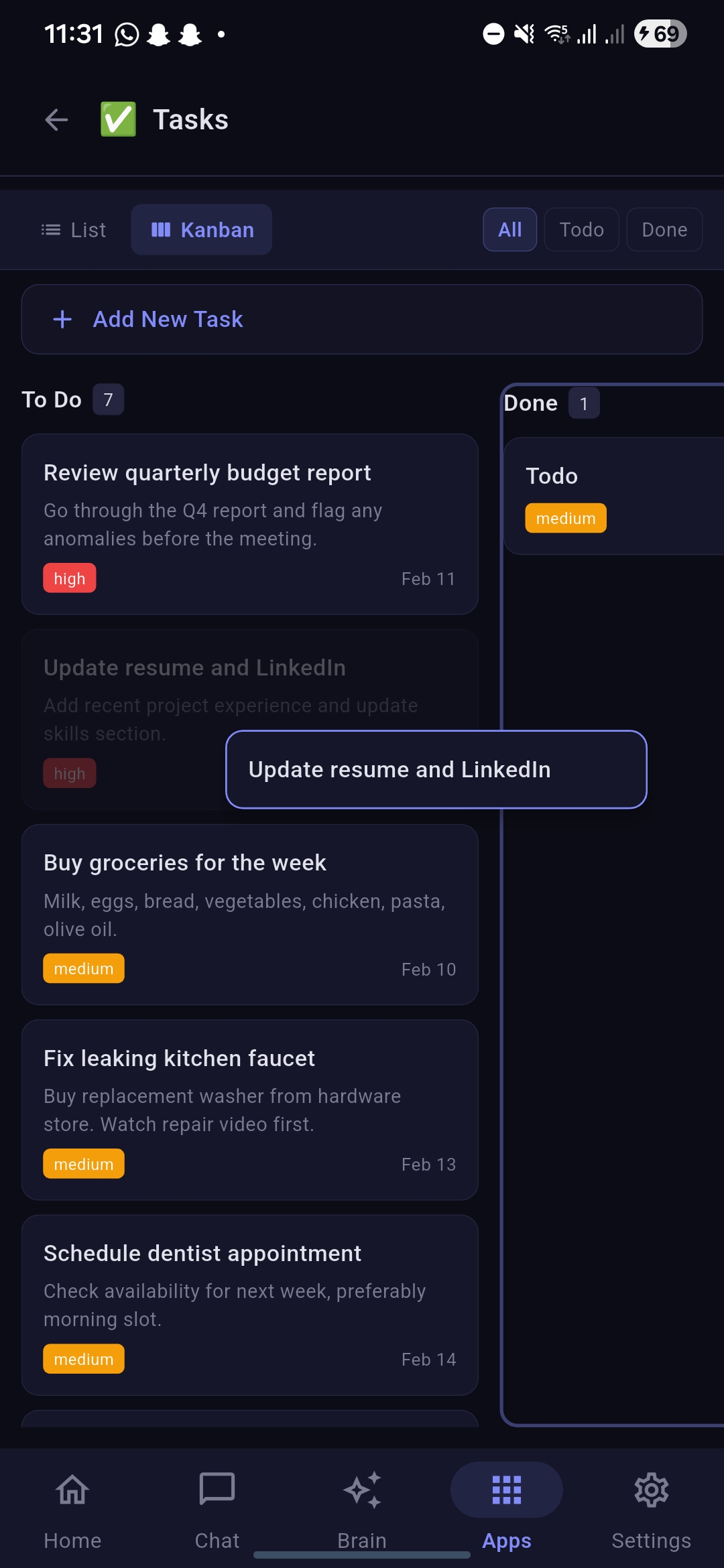
Tasks section under apps with item open in list view
-
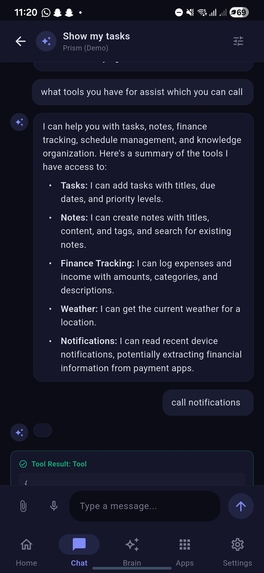
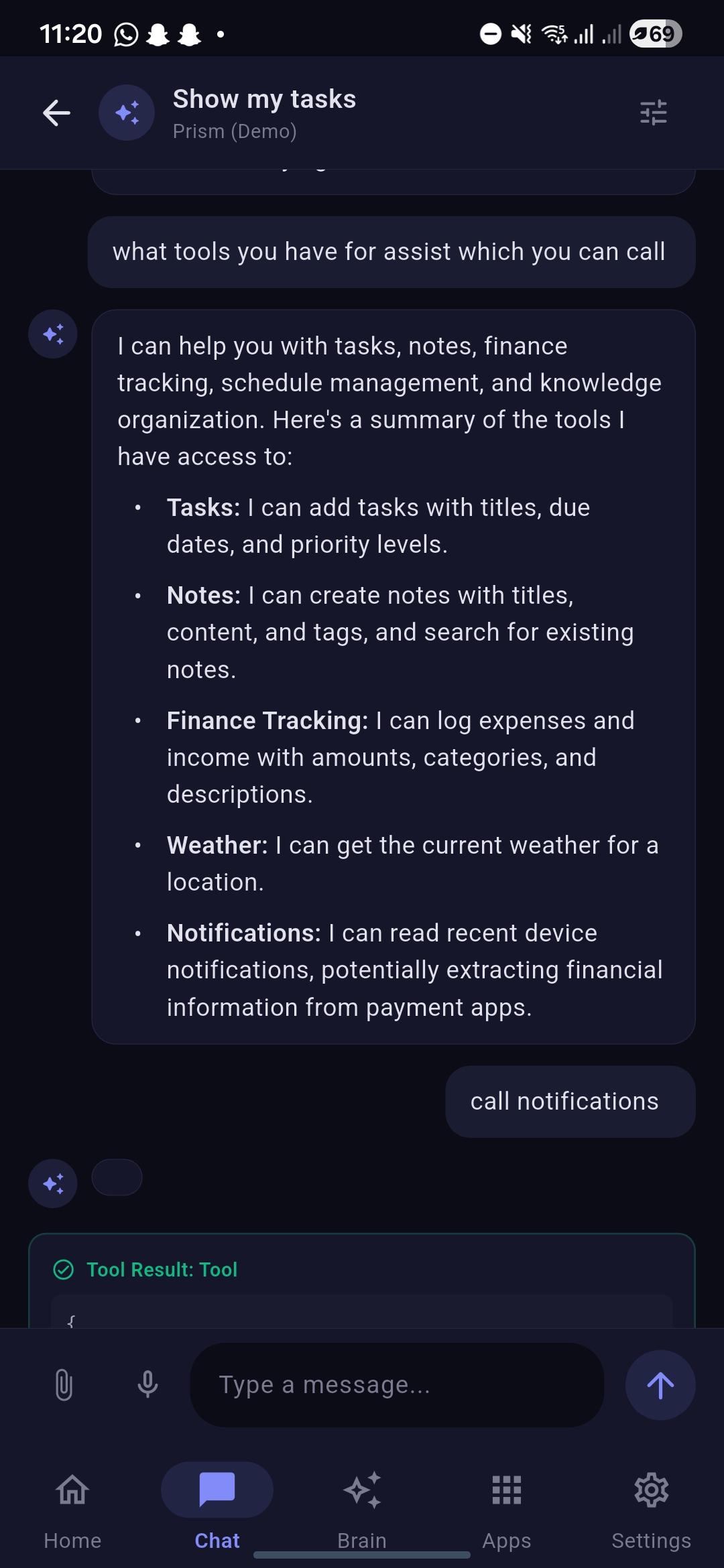
Chat with showcasing available tools reply from model and tool calling
-
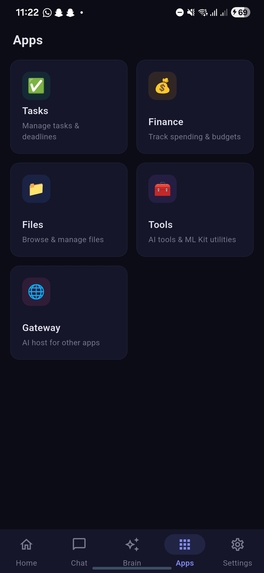
Apps screen showcasing tasks, finance and other options
-
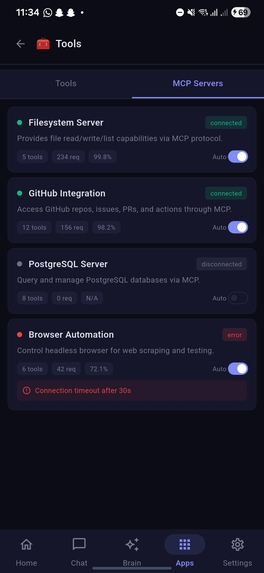
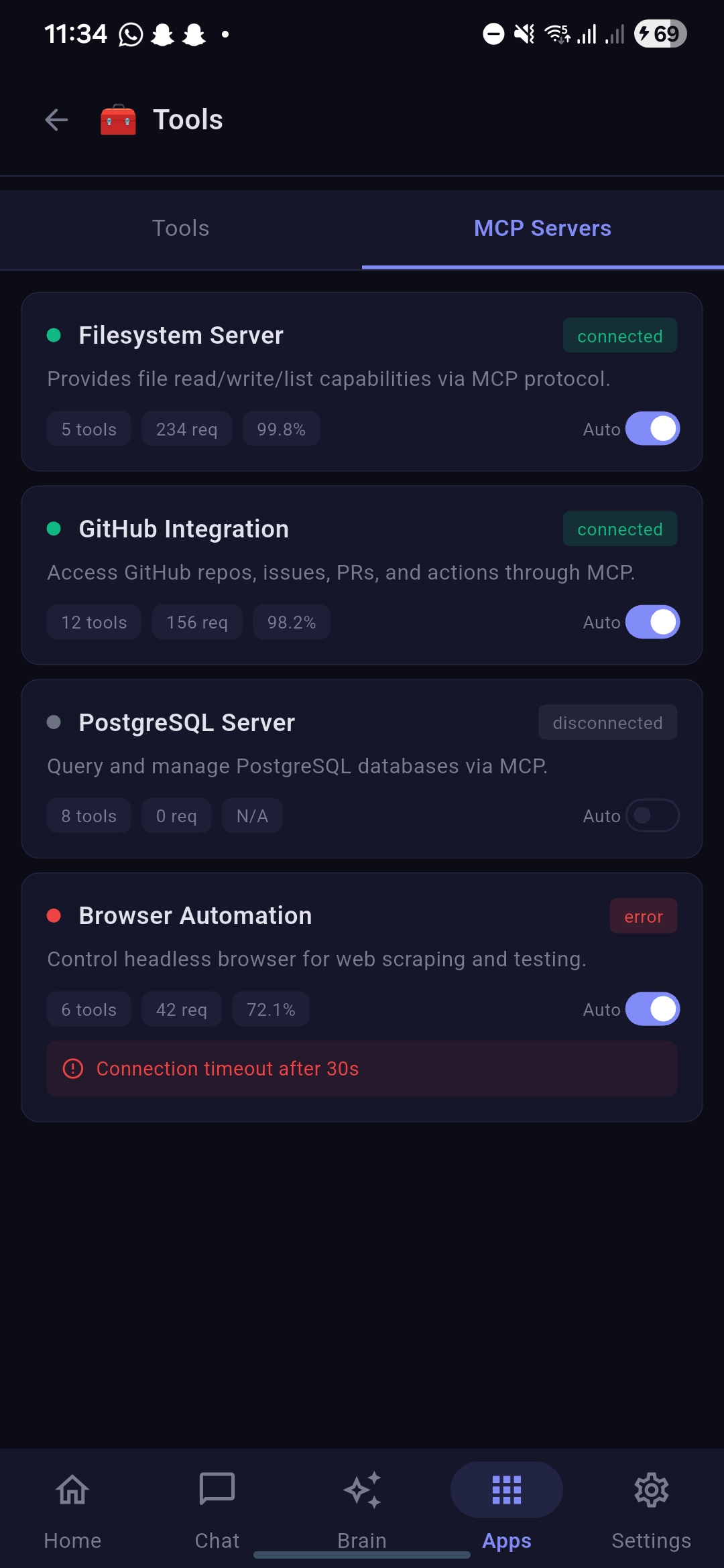
MCP Servers under Tools in Apps
-
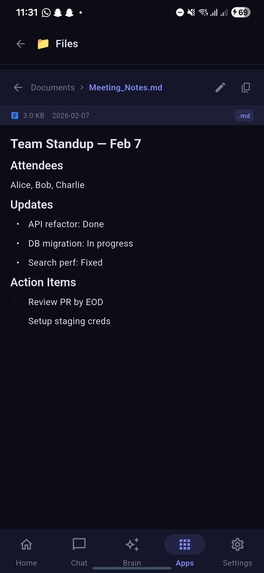
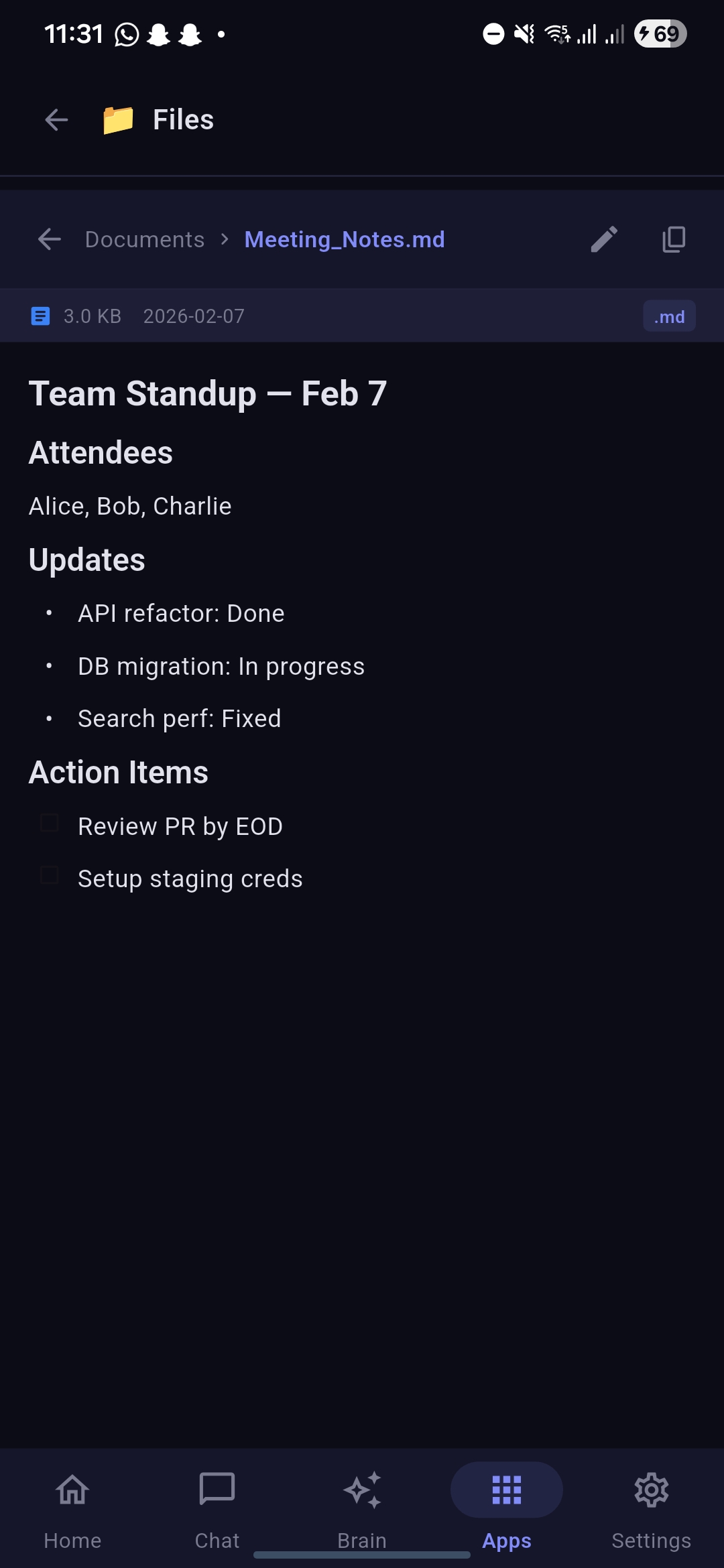
Markdown file open in Files Section from Apps
-
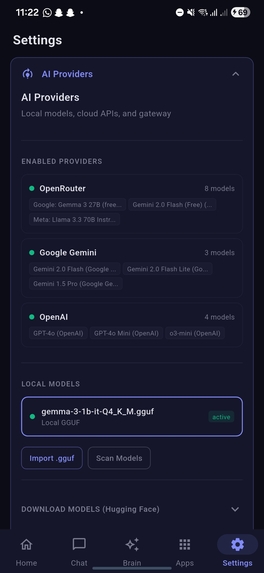
SettingsPage
-
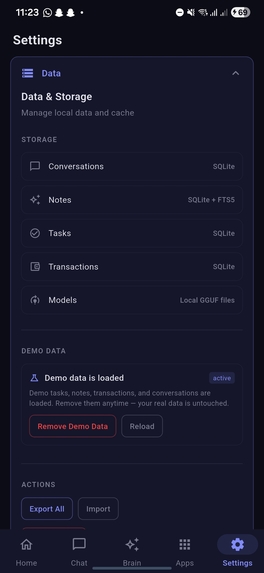
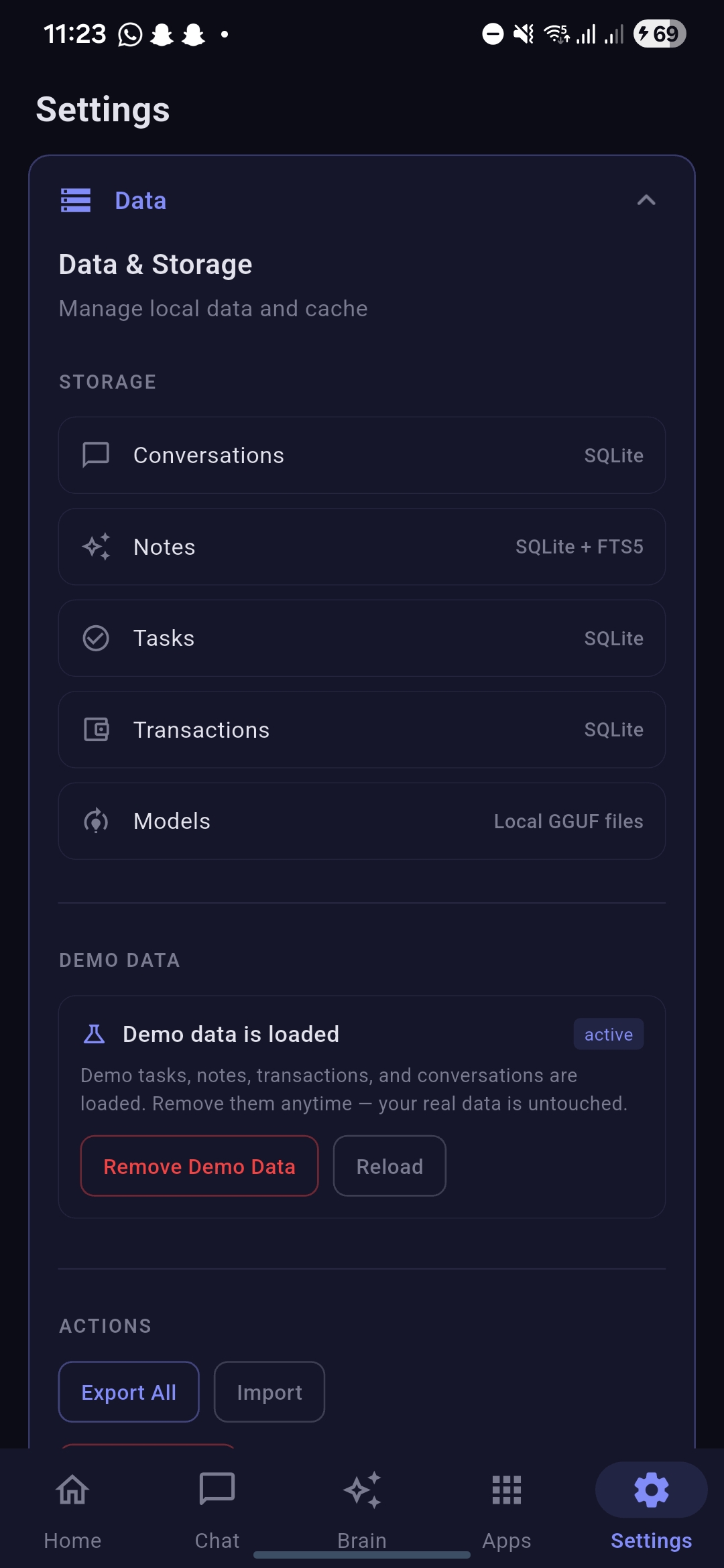
SettingsPage2-with data & storage
-
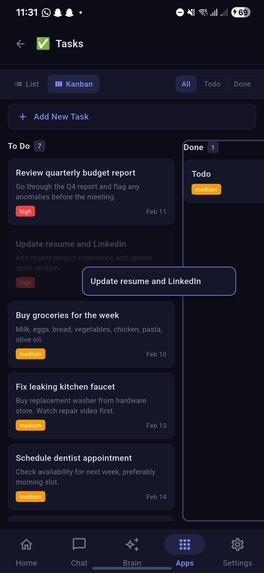
Tasks section under apps with item moved in kanbanboard
-
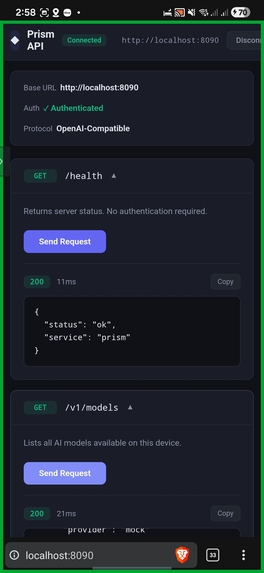
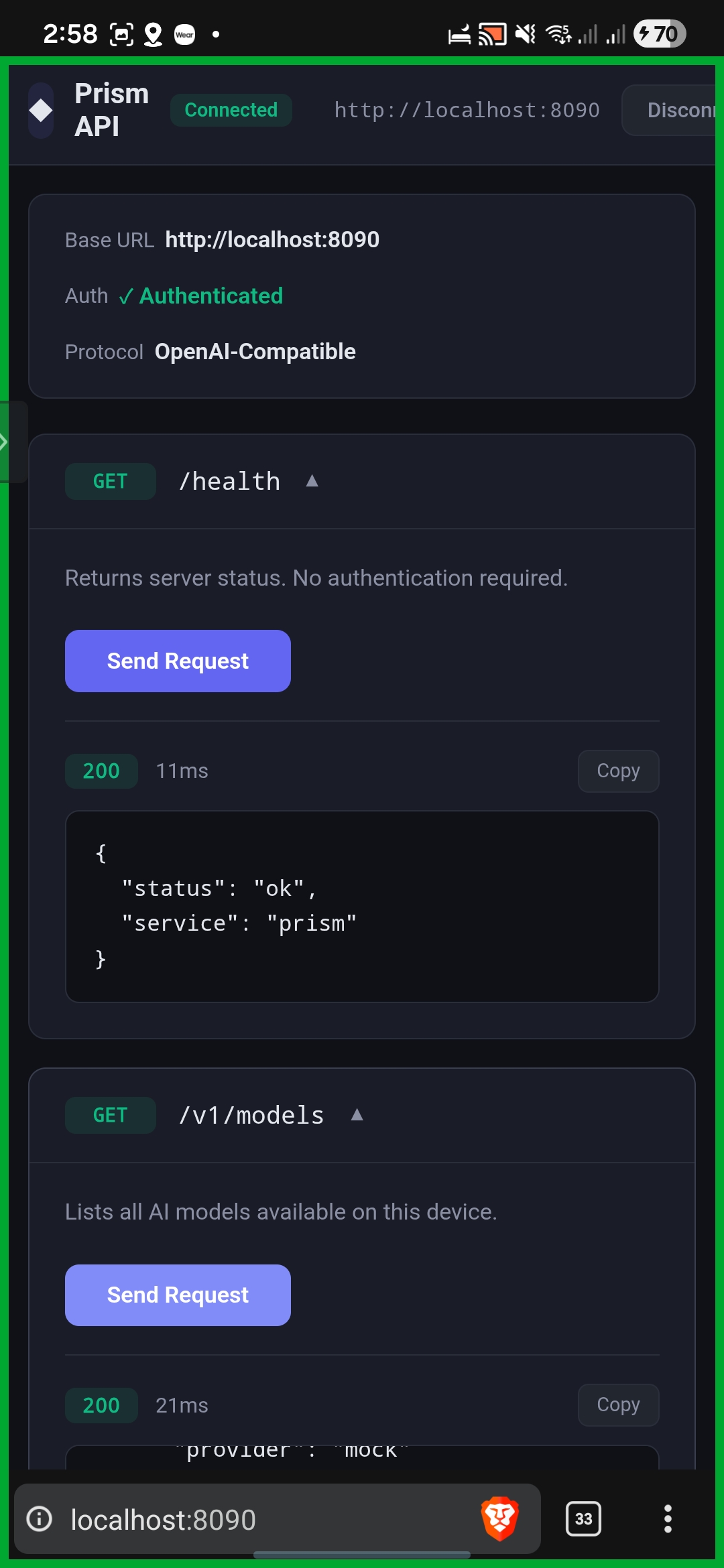
Prism API via localhost
Project Links
- Website: prism.abhi1520.com
- GitHub Repo: github.com/abhijeet1520/prism
- Download APK: github.com/Abhijeet1520/Prism/releases
Inspiration
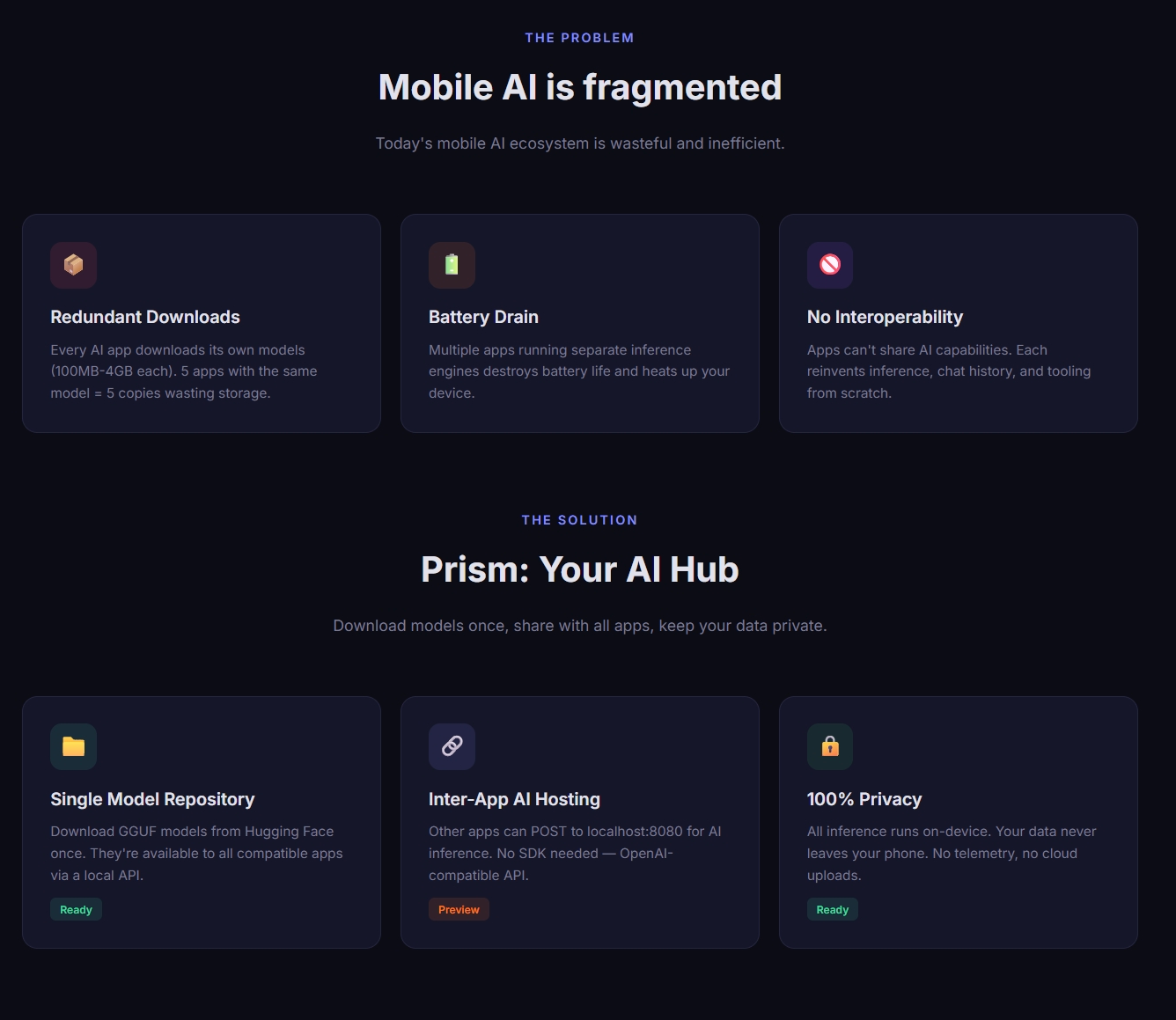
I noticed a frustrating pattern in the mobile AI ecosystem: every AI-powered app downloads and bundles its own copy of language models. As someone who loves trying new AI apps, I had 5 different AI using apps on my phone – each with its own 500MB-2GB model files. That's potentially 10GB of storage for what's essentially the same capability repeated 5 times.
This made me think: What if there was a central "AI hub" on your phone? One app that manages all your AI models, and other apps can simply request AI capabilities from it instead of bundling their own. Like how Android's MediaStore works for photos, but for AI.
The technical spark that truly set this in motion was Google's FunctionGemma. I was deeply intrigued by how Google optimized a smaller, efficient model specifically for action calling and agency. It proved that you don't need massive parameters to be useful, you need agency. Seeing FunctionGemma’s ability to bridge natural language with executable code inspired me to build Prism not just as a chatbot, but as an agentic OS layer that combines local inference (via Gemma GGUF) and cloud APIs (Gemini) to empower the entire device.
The Gemini API competition was the perfect opportunity to build this vision. Prism combines local model inference (via Gemma GGUF files), cloud APIs (Gemini, OpenAI), and exposes a local HTTP server so any app on the device can leverage AI without duplicating models.
What it does
Prism is three things in one:
A Modern AI Chat App: Beautiful, fast chat interface with real-time streaming, conversation management, voice input, and function calling tools.
A Model Manager: Download GGUF models from Hugging Face, manage local and cloud providers (Gemini, OpenAI, Ollama), and switch between them seamlessly.
An AI Server for Other Apps: Exposes OpenAI-compatible endpoints on
localhost:8080. Any app – React Native, native Android, even shell scripts – canPOST /v1/chat/completionsand use Prism's models.
Key capabilities:
- Chat with local models (Gemma 3 1B, Phi-4, TinyLlama) 100% offline
- Connect to Gemini API for cloud inference
- Second Brain with PARA methodology (Areas → Resources → Notes)
- Function Calling: Add tasks, log expenses, search notes, check weather (Inspired by FunctionGemma's architecture)
- On-device ML Kit: OCR, entity extraction, smart reply
- 7 theme presets with AMOLED dark mode
How I built it
Tech Stack:
- Framework: Flutter 3.10.8 (cross-platform, single codebase)
- AI Backend: LangChain.dart for chain orchestration + llama_sdk for GGUF inference via FFI
- Database: Drift (SQLite) with FTS5 full-text search – 10 tables for conversations, messages, tasks, notes, areas, resources
- State Management: Riverpod 2.6 with code generation
- UI: Moon Design 1.1.0 components with custom theme system
- Inter-App Server: Shelf (Dart HTTP server) running on localhost
Development Process:
- Started with UX mockups to nail the interaction model
- Built the Drift database schema with PARA methodology in mind
- Integrated LangChain.dart for multi-provider AI abstraction
- Added
llama_sdkFFI bindings for on-device GGUF inference - Implemented streaming chat with real-time token updates
- Added function calling tools using LangChain's ToolSpec
- Built the Shelf server for inter-app AI hosting
- Polished UI with Moon Design and custom theming
Challenges I ran into
1. FFI Complexity for Local Inference
Getting llama.cpp to work via Dart FFI was challenging. Memory management, threading, and callback handling required careful attention.
Solution: Wrapped everything in isolates with message passing.
2. Streaming Token Performance
Initial implementation caused UI jank during token streaming.
Solution: Fixed by batching state updates and using StreamBuilder with careful rebuild minimization.
3. Model Download Management
Large GGUF files (500MB-4GB) need resumable downloads, progress tracking, and storage management.
Solution: Implemented chunked downloads with dio and local file caching.
4. Database Schema Evolution Started with flat tables, realized PARA methodology needs many-to-many relationships. Solution: Migrated to junction tables (ResourceAreas, NoteResources) with proper cascading deletes.
5. Balancing Local vs Cloud Users want seamless switching between local (fast, private) and cloud (smart, capable). Solution: Built a provider abstraction in LangChain.dart that handles both uniformly.
Accomplishments that I'm proud of
- Sub-100ms chat latency on local Gemma 3 1B (Samsung S24 Ultra)
- Zero external dependencies for core chat functionality – works fully offline
- Clean architecture with Riverpod + GoRouter that scaled from 2 screens to 15+
- FTS5 search across all notes and messages in <50ms
- Inter-app AI hosting via Shelf – tested with a React Native app successfully calling Prism's models
- Beautiful UI that doesn't look like a typical dev project – thanks to Moon Design
What I learned
- Dart FFI is production-ready: You CAN run C/C++ ML inference in Flutter apps with good performance
- LangChain patterns translate well to Dart: Chains, tools, and streaming work elegantly with Dart's async model
- Drift is incredible: The combination of typed SQL, reactive streams, and code generation makes database work a joy
- Mobile AI is compute-constrained: Had to carefully choose Q4_K_M quantization to balance quality vs speed
- Privacy sells: Early testers were more excited about "runs on device" than any feature
What's next for Prism & A Personal Note
Winning the Gemini API Developer Competition would be a life-changing milestone for me. This project isn't just a hackathon entry; it is a manifestation of my passion for efficient, on-device AI and agentic workflows.
I am deeply fascinated by the research coming out of Google DeepMind, particularly regarding smaller, capable models like Gemma and specialized tools like FunctionGemma and VaultGemma. My long-term career goal is to join the Google DeepMind research team to work on exactly these kinds of problems–bridging the gap between theoretical model capability and real-world, efficient application.
On a personal level, the prize would be transformative. It would help clear my student loans, granting me the financial freedom to dedicate myself fully to this project. I want to build a future where AI is "accessible by the people, for the people"–a future where users own their data and their models.
Prism is my contribution to that sovereign AI future. I would be incredibly grateful for the opportunity to clear my financial hurdles so I can continue building this open ecosystem for everyone.
Future Roadmap:
- iOS Support: Flutter makes this straightforward; just need to handle iOS-specific model storage paths.
- Plugin System: Let developers add custom tools (MCP protocol support).
- Model Fine-tuning: Simple LoRA fine-tuning interface for personalization.
- Desktop: Windows/macOS builds for power users who want the same AI across devices.
- App Ecosystem: SDK for other apps to integrate with Prism (Android library).

Log in or sign up for Devpost to join the conversation.