-
-
python sheet beginning
-

design doc beginnning

Inspiration
As a team, we enjoy tackling challenges that delve into social good. Regardless of whether we produce something that will be widely used, we think it’s important to work on projects that can serve to improve the lives of people or the world in some way. Regarding why we chose NewsQ’s challenge over others, we all have a budding interest in applying and incorporating machine learning into our algorithms to produce really useful results. This project gave us a great opportunity to combine both for a well-defined problem.
What it does
This project ranks news for people to read based on an algorithm we designed. This project is specific to general and health news from Australia, and it takes in the top headlines from Australia and orders them based on a combination of three main factors: credibility, or how trustworthy an article is based on its content, readability, based on a reading level algorithm called the Flesch Reading Ease, and time elapsed since publication. Each factor is weighed and processed in an equation, whose output leads to the overall news ranking. Equation output is ranked high to low; the highest ranking articles have the highest numerical combination of the three factors.
How we built it
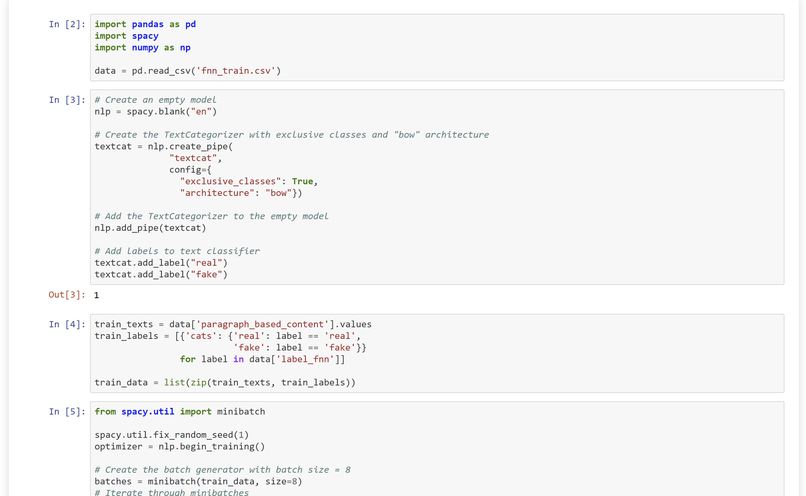
We built PriorityNews with the help of an API (NewsAPI) and python’s BeautifulSoup and Urllib packages, among others, to webscrape headline news from Australia. With this initial data, we made calls to a machine learning model built on bag-of-words that predicted the probability of the article content being trustworthy. We also analyzed the readability level of each article’s content using a python package to abstract Flesch’s reading ease algorithm. We combined these factors, along with other factors such as time-since-published into a testing-tuned equation to achieve a relevant ranking of general and health news articles. Our design document for our specific challenge was made with LaTeX.
Challenges we ran into
While the machine learning model was trained on a cleaned dataset of news articles, our web scraper was pulling much messier strings with headings and markdown punctuation. This made our model seem to make predictions almost randomly. However, taking some time to clean the strings made the model more consistent again. But overall, the accuracy of the model may have reduced a bit when predicting our web scraped data compared to the clean data it was trained on.
Accomplishments that we’re proud of
We are proud of the progress made through this hackathon. The idea phase is always one of the more difficult portions of the hackathon, and after looking through the challenges, the Newsq challenge allowed us to express our skillset the best. Most of the members on the team are new to machine learning, and with our constant desire to improve and persevere through difficult times, we were able to train several data sets and develop an algorithm that ranked news sources with high efficiency. After constant trial and error, we were able to think of an algorithm that worked with the data sets and were satisfied with the results.
What I learned
Planning is a necessity. Training the machine models took a really long time, and one of the ones we ran throughout Friday night actually ended up having poor accuracy. The model ended up not liking the formatting of some of the webscraped data, so we had to reformat the data. We also learned about html parsing to extract article data with web scraping, particularly because of the challenges such as decoding character sets and trimming return content.
What's next for PriorityNews
We hope to improve the accuracy of the machine learning model when it predicts real and fake news. Hopefully, we can train more powerful models like convolutional news networks or ensemble models that combine neural networks and bag-of-words.
Built With
- beautiful-soup
- jupyter-notebook
- latex
- machine-learning
- natural-language-processing
- newsapi
- python
- spacy
- webscrape


Log in or sign up for Devpost to join the conversation.