-
-
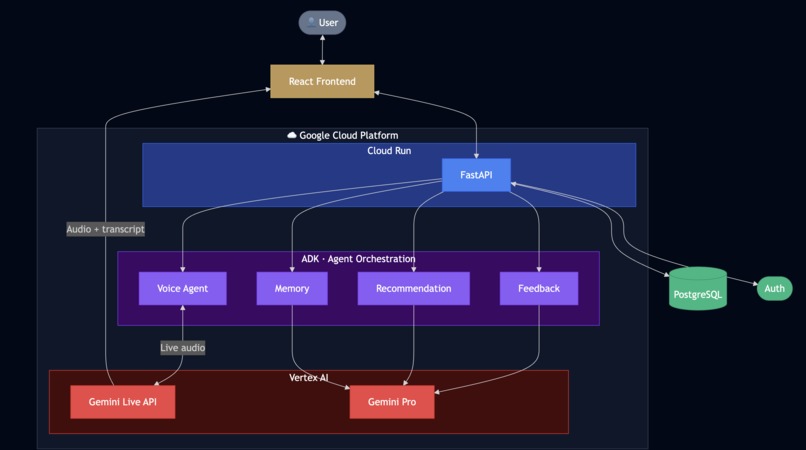
Architecture Diagram
Inspiration
I recently made the switch from software development to product management and realized PM interviews are quite different from Engineering interviews. There's no binary pass/fail, it's conversational, ambiguous, and the feedback loop barely exists.
The options are limited, practice with friends who sugarcoat, or rehearse alone with no feedback at all. Neither really tells you whether you are improving or not. Primed was built to fill that gap.
What it does
Primed conducts real-time mock interviews, evaluates performance against a skill rubric, and adaptively recommends the next interview based on the candidate's weakest area. After each session, three ADK agents are invoked
- FeedbackAgent that evaluates the transcript against the skill rubric
- UserSummaryAgent that updates the candidate's living profile (a light-weight memory layer)
- RecommendationAgent that selects the next interview
How we built it
The key components of the app are built using ADK and Live API
Voice interview: The live session uses ADK's Agent class with run_live() for bidirectional audio streaming with the gemini-live-2.5-flash-native-audio model. The RunConfig is built per session and enables session resumption, context window compression, proactive audio, and affective dialog. A few mechanics worth noting:
- Agent speaks first: The Live API is reactive by default — it waits for the user to speak. To make the agent open every session naturally, a synthetic
[SESSION_READY]content turn is injected intoLiveRequestQueuebefore audio tasks start. The system prompt interprets this cue to greet the candidate and read out the problem statement. - Graceful hangup: A single
end_interviewtool is injected into the agent. The downstream event loop watches for itsfunction_responseand closes the queue cleanly, letting the agent finish its closing remarks before teardown rather than cutting the connection abruptly. - Timeout warning: At T-3 minutes, a
[SYSTEM: ...]text turn is injected directly into the live queue. The system prompt instructs the agent to acknowledge the warning, wrap up the interview, and callend_interview. - Natural interruptions:
StreamingMode.BIDIcombined withProactivityConfig(proactive_audio=True)makes the model stop generating the moment it detects the user speaking. The frontend (raw WebSocket + Web Audio API) immediately clears its playback queue on theinterruptedsignal from ADK, so there is no residual audio tail. The conversation can be interrupted mid-sentence, just like a real call.
Post-session pipeline: Three LlmAgent instances - FeedbackAgent, UserSummaryAgent, RecommendationAgent are invoked via a shared run_agent_once utility. Each is Pydantic-validated at the output boundary. The pipeline runs as a background async task so candidates see the feedback state immediately without being blocked.
Backend: FastAPI (Python 3.12), UV package manager, PostgreSQL, ADK, Live API (via Vertex), Gemini API (via Vertex), Cloud Run
Frontend: React 18, TypeScript, Vite, TailwindCSS, Firebase Hosting
Challenges we ran into
Keeping the interview agent focused. Without proactive audio enabled, the agent responded to off-topic questions as well. Prompt engineering helped somewhat, but the agent still generated responses to irrelevant inputs, spending tokens producing nudges to get the user back on track. Enabling proactive audio changed this entirely, the model simply stopped responding to inputs it determined were irrelevant to the interview context
Session continuity past 10 minutes. A real screening interview runs for ~30 minutes. The Gemini Live API has a hard 10-minute WebSocket connection limit. Session resumption handles reconnection transparently, but it has to be paired with context window compression, otherwise the context accumulates past the 128K limit and the session hard-stops mid-conversation regardless. Getting the token thresholds right (trigger at ~78% of 128K, target at ~62%) took calibration to ensure compression fired with enough headroom to avoid cutting off mid-turn.
The regional conflict in ADK. Gemini 3+ LLMs on Vertex require location="global", but the Gemini Live API requires a specific region (us-central1). ADK's default Gemini class reuses one client for both paths — which silently breaks one or the other. We had to subclass it, overriding _live_api_client as a @cached_property to pin Live API calls to us-central1 while letting text inference stay on the global endpoint
Accomplishments that we're proud of
An early user cleared a PM interview screening round using Primed. That is the validation that matters most
Making a ~30 min uninterrupted voice sessions work reliably required solving three problems simultaneously, session resumption, context compression, and regional routing. Getting all three stable and calibrated for the full interview duration was the most rewarding part of the project
What we learned
Proactive audio is critical for real-world voice agents and affective dialog is what makes the agents feel human. Without proactive audio, the agent responded to everything. With it enabled, the model demonstrates real contextual awareness about what is relevant to the session. Ex - Given a Google Meet problem statement, it responds fully to questions about metrics and user behavior, but when asked questions like "Do you live in Silicon Valley?" or "Do you use an Android phone?", it simply doesn't respond. It is a meaningful safeguard for any voice agent deployed at scale where you expect users to test its limits. Affective dialog complemented this by making the speech more lively and natural, responses felt genuinely human rather than robotic, which is very crucial for building an empathetic interview coach Discovering how well these features work and how critical they are for any real-world voice agent deployment was one of the biggest learnings for us
Going all-in on ADK pays off quickly. The post-session agents were originally built directly on the
google-genailibrary with a custom wrapper handling retries, output parsing, and error handling for each agent separately. Migrating everything to ADKLlmAgenteliminated ~300 lines of that custom code, retries, Pydantic output schema enforcement, and failure handling became consistent across all agents with no extra work
What's next for Primed
The long-term vision is the complete interview pipeline: job discovery, resume customization, and targeted mock interviews, all connected. Primed today handles the hardest part (the live screen), but candidates preparing for a PM role need help at every stage.
Beyond product management, the same architecture - voice agent, skill rubric, adaptive interviews, applies to marketing, design, and engineering interview prep. The modular design was built with this in mind

Log in or sign up for Devpost to join the conversation.