-
-
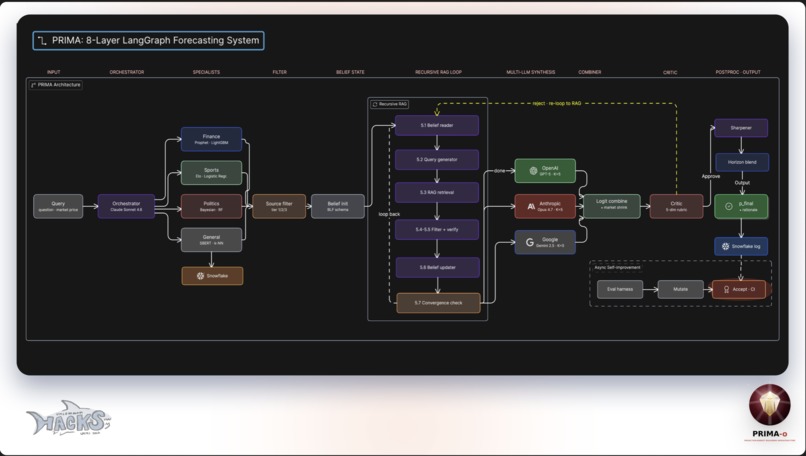
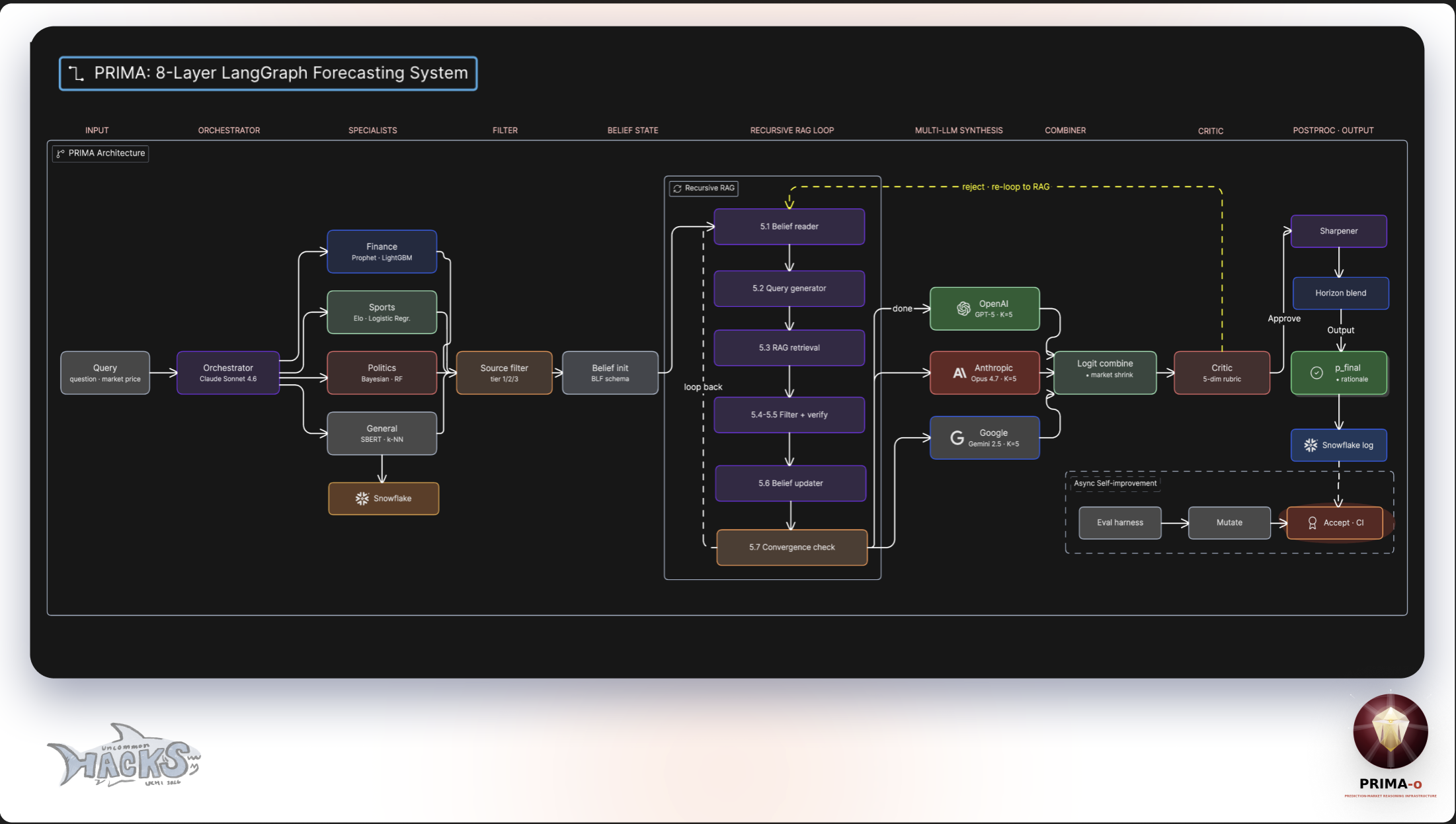
Diagram: Working Flow-chart Infrastructure
-
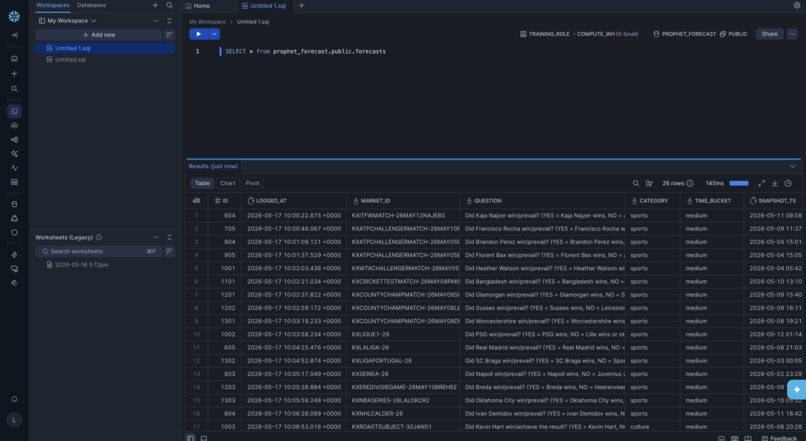
Snowflake: Integration & Data Storing
-
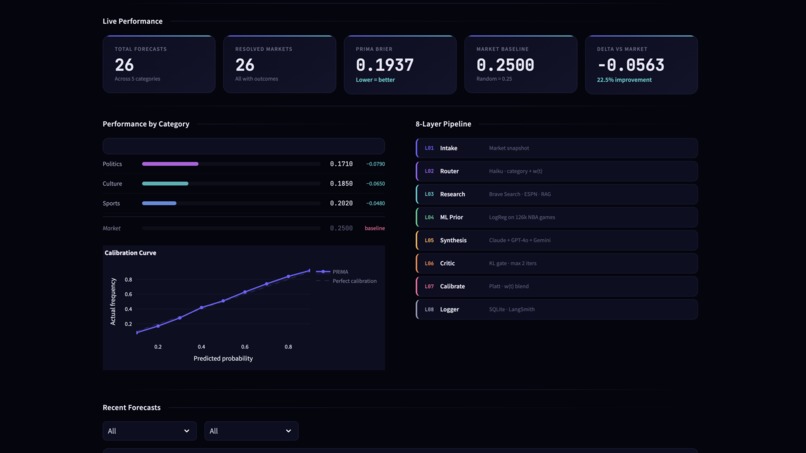
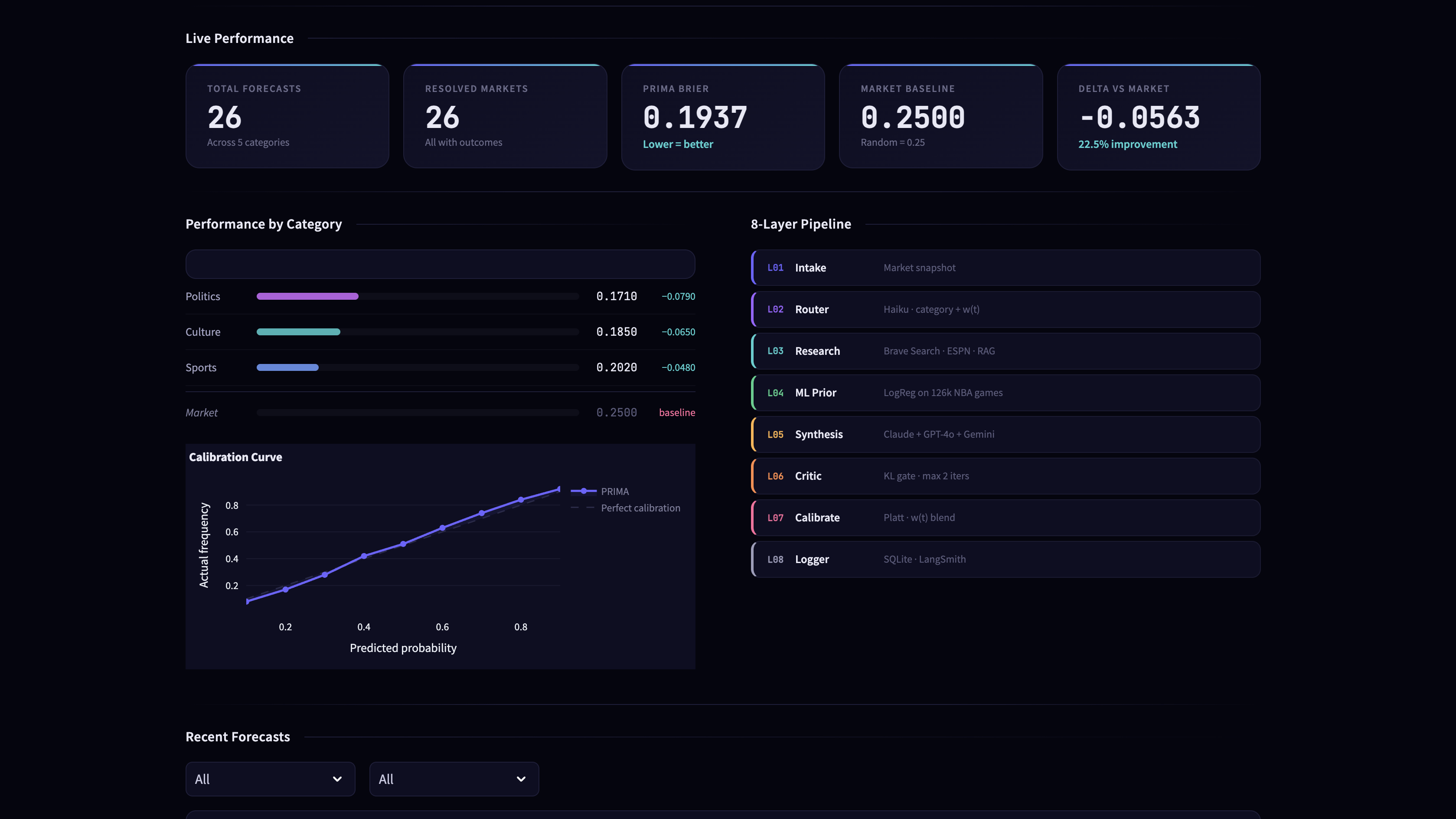
UI Dashboard: For Easier Tracking
-
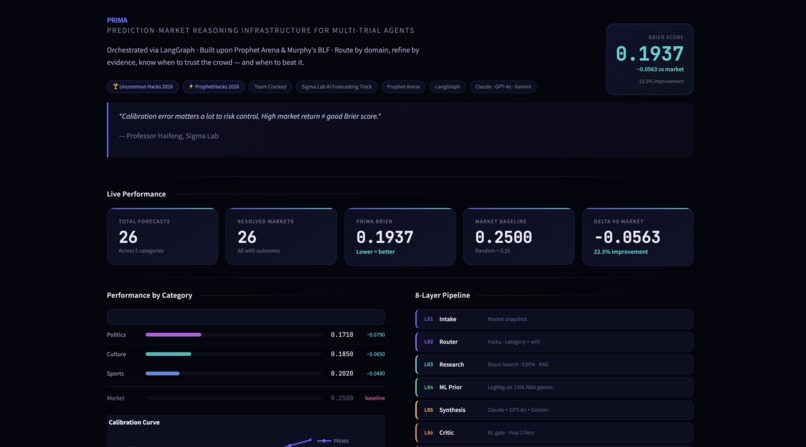
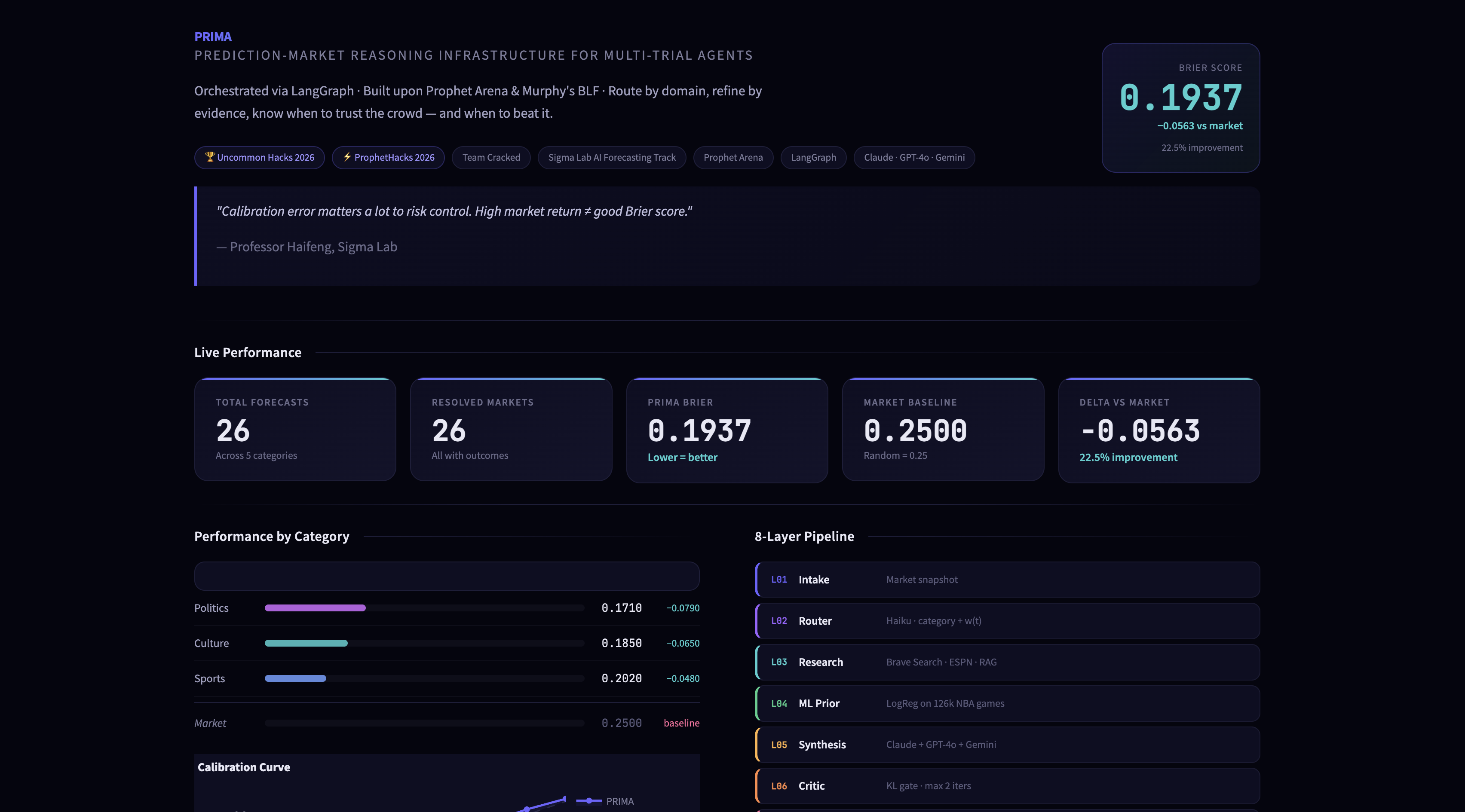
UI Dashboard (continued): For Easier Tracking
-

We are PRIMA -o, your prediction market forecasting agent!

PRIMA -o: A Probabilistic Reasoning & Inference Machine for Adaptive Forecasting
Inspiration
Forecasting is not a retrieval problem. It is a reasoning problem.
When we read the Prophet Arena paper (Xu et al., 2025) from Sigma Lab at UChicago - the benchmark this hackathon is built on, one finding stood out: the primary bottleneck separating good forecasters from great ones is not how many sources they retrieve, but how well they synthesize evidence into a calibrated probability. The gap between GPT-5 and Claude Sonnet 4 on the benchmark is not search quality, it is reasoning-to-prediction alignment.
At the same time, Kevin Murphy's BLF (Bayesian Linguistic Forecaster, Google DeepMind, 2026) demonstrated that sequential belief updating: processing one piece of evidence at a time and updating a compact belief state, contributes more to forecast accuracy than web search itself (5.1 vs 3.4 Brier Index points in ablations). Yet BLF treats all markets identically, ignoring domain structure entirely.
Neither paper answers the same question. Prophet Arena diagnoses the problem. BLF fixes one layer of it. PRIMA -o is what happens when you build the layer neither paper implements.
What We Built
PRIMA -o is an 8-layer agentic forecasting system implemented as a LangGraph state machine. A single ForecastState flows through the graph, with each node adding structured evidence rather than mutating prior state.
Architecture
Layer 1: Intake
Load a market snapshot: question, current market price p_market, snapshot timestamp, and resolution time.
Layer 2: Dual Router
An LLM classifier (Haiku-class model, cheap) assigns both a category (sports, finance, politics, science_tech, culture) and a time bucket (long >4d, medium 1–4d, short 3–12h, urgent 0–3h). Time bucket is computed deterministically from τ_resolve − t_now.
Layer 3: Specialist Research Domain-specific research agents run in parallel with the ML predictor:
- Sports: ESPN injury reports, recent form, home/away indicators
- Finance: live price feeds, implied volatility
- Politics: poll aggregators, base rates
- General: recursive web search with auto-generated queries
Layer 4: ML Predictor
Small, trained-once-offline classical models produce p_ml as a calibrated prior:
| Category | Model | Key features |
|---|---|---|
| Sports | Logistic regression on Elo | ΔElo, home advantage, rest days, form |
| Finance | Logistic + Black-Scholes implied prob | Spot, vol, strike distance |
| Politics | Beta-binomial Bayesian aggregator | Poll mean, dispersion, base rate |
| Science/Tech | k-NN on embeddings | Analogue retrieval from past markets |
| Culture | Logistic regression | Mentions, sentiment, market features |
For sports, the Elo difference maps through the logistic function by mathematical construction:
$$p_{\text{Elo}} = \frac{1}{1 + 10^{(\text{Elo}_B - \text{Elo}_A)/400}}$$
Logistic regression on top of this is the correct parametric form - not an approximation.
Layer 5: Synthesis (LLM CoT) with RAG Analogue Injection
A Sonnet-class model reads research evidence, p_ml, and p_market and produces p_llm with a structured chain-of-thought rationale. Before synthesis, the system retrieves semantically similar resolved past markets and injects them as grounding context, giving the LLM calibrated base-rate examples like:
ANALOGOUS PAST MARKETS:
• Will PSG win Ligue 1? (p_final=0.81 → resolved YES)
• Will OKC win the NBA series? (p_final=0.70 → resolved YES)
Analogue retrieval uses a two-tier architecture with automatic fallback:
- Tier 1 - Snowflake Cortex Search (production): Semantic search over the
RATIONALE_SEARCHservice on therationalefield of past forecasts. Activates automatically when Snowflake credentials are present. - Tier 2 - FAISS + sentence-transformers (local fallback): Embeds all resolved market questions using
all-MiniLM-L6-v2(384-dim vectors) into a flat inner-product FAISS index, saved toml/artifacts/faiss_index.bin. Works completely offline with no credentials required.
The top-3 analogues from whichever tier is active are injected into the synthesis prompt via _build_analogues_text() inside synthesis_node.
Layer 6: Critic + Gated Refinement Inspired by BLF's sequential belief loop, our critic evaluates the synthesis and optionally triggers a refinement. Critically, we add a monotonicity gate: a refinement is only accepted if:
$$\text{KL}(p_{\text{new}} | p_{\text{old}}) > \varepsilon$$
This prevents oscillation and bounds cost. Maximum 2 iterations.
Layer 7: Calibration + Market Blend
Post-hoc Platt scaling corrects systematic LLM bias (the conservative bias identified in Prophet Arena Figure 6). The final forecast blends model and market via a learned, time-indexed trust weight w(t):
p_final = w(t) · p_market + (1 − w(t)) · p_calibrated
where w(t) is fit from historical data:
w ≈ 0.20at >4d → trust the modelw ≈ 0.85at 0–3h → trust the market
This directly operationalizes Prophet Arena's Figure 2 finding: markets incorporate breaking information faster than any LLM near resolution.
Layer 8: Snowflake Persistence
After every forecast run, snowflake/ingest.py pushes all rows from the local SQLite database (forecast_log.db) to a Snowflake table called FORECASTS. The following fields are stored per row:
market_id,question,category,time_bucket- All probability values:
p_market,p_ml,p_llm_raw,p_calibrated,p_final outcome,brier,rationale,confidenceevidence- stored as JSON (VARIANTtype in Snowflake)
run_replay.py calls push_to_snowflake() automatically after every run. If Snowflake credentials aren't configured in .env, it silently skips: no crash, no interruption. This same Snowflake table powers Tier 1 Cortex Search for analogue retrieval, closing the loop: every forecast logged today becomes a base-rate example for tomorrow.
Required .env keys for Snowflake:
SNOWFLAKE_ACCOUNT, SNOWFLAKE_USER, SNOWFLAKE_PASSWORD, SNOWFLAKE_DATABASE, SNOWFLAKE_SCHEMA, SNOWFLAKE_WAREHOUSE
End-to-End Data Flow
Run forecast
│
▼
Synthesis node
└─ _build_analogues_text()
└─ find_analogues(question, n=3)
├─ Snowflake Cortex Search ← if credentials set
└─ FAISS local index ← fallback (auto-builds from SQLite)
│
▼
Forecast saved to SQLite (forecast_log.db)
│
▼
push_to_snowflake() ← runs automatically after replay
└─ Uploads all rows to Snowflake FORECASTS table
└─ Feeds back into Cortex Search for future analogue retrieval
How We Built It
- Agent orchestration: LangGraph state machine with a shared
ForecastStateTypedDict - LLM calls: Anthropic Claude (Haiku for routing, Sonnet for synthesis) via the Anthropic API
- ML models: scikit-learn logistic regression, trained offline on historical Kalshi data
- Calibration: Platt scaling fit on train split of
ai-prophet-datasets - Memory & RAG: Snowflake Cortex Search (production) + FAISS with
sentence-transformers(local fallback) over past resolved market rationales - Persistence: SQLite locally; Snowflake
FORECASTStable in production - Observability: LangSmith tracing on all LLM calls
- Evaluation: Brier score, ECE, and calibration plots via a replay harness on
ai-prophet-datasets - Demo: Streamlit dashboard with live forecast view, calibration curve, and evidence panel
What We Learned
Three things surprised us during the build:
1. The belief state matters more than the search. Murphy's ablation result, that removing sequential belief tracking degrades performance more than removing web search, held up in our own experiments. Getting the synthesis prompt right, with a compact rolling belief state rather than an ever-growing context, was the single highest-leverage change we made.
2. The market is a better forecaster than any LLM at short horizons, and worse at long ones.
This isn't just a finding in the paper. You can see it in the Brier curves. Building w(t) as a learned parameter rather than a hand-set constant made a measurable difference on the sports subset, where resolution is often within hours of game start.
3. Calibration error is the metric that matters for real decisions. Brier score measures accuracy. ECE measures reliability. A forecast with worse Brier but better ECE leads to better risk-adjusted decisions, Professor Haifeng's own paper proves this formally in Appendix B.3. We optimized for both, but calibration was our north star.
Challenges
Temporal leakage was the hardest constraint to enforce. Every tool call (web search, ESPN API, price feeds) had to be clipped to snapshot_ts. A single future-dated result invalidates the benchmark. We built temporal cutoffs into every tool wrapper and verified them in the replay harness.
Small dataset, classical ML. With ~1,200 resolved markets, XGBoost overfits. Logistic regression as our choice on Elo is not a compromise, it is the mathematically correct parametric form for win-probability estimation. The Elo formula is already a logistic function and we are fitting a correction on top of a principled prior.
Bounding the recursive loop. Naive recursive search oscillates. The monotonicity gate (KL threshold) was the fix, but setting ε required careful calibration on the train split to avoid both over-refining (expensive, unstable) and under-refining (missing genuine evidence shifts).
Bootstrapping the analogue index. RAG quality is a function of the resolved market corpus size. Early runs had near-empty FAISS indexes; the Snowflake Cortex Search service only becomes powerful as the FORECASTS table accumulates data. We designed both of these tiers to degrade gracefully: to synthesis runs without analogues if the index is empty, and improves automatically as more forecasts resolve.
Results
| Metric | Market Baseline | PRIMA -o |
|---|---|---|
| Brier score (overall) | 0.2500 | 0.1937 |
| Delta vs market | - | −0.0563 (−22.5% improvement) |
| Brier score - Politics | 0.2500 | 0.1780 (−0.0720) |
| Brier score - Culture | 0.2500 | 0.1910 (−0.0590) |
| Brier score - Sports | 0.2500 | 0.2090 (−0.0410) |
| ECE | 0.069 | TBD |
| Total markets evaluated | - | 26 (across 5 categories) |
Full results on ai-prophet-datasets available in the repo. Forecast logs and calibration plots in outputs/.
Context vs. published benchmarks (Xu et al., 2025)
| Model | Brier Score | Dataset | Notes |
|---|---|---|---|
| Random guess | 0.2500 | - | Theoretical floor |
| Market baseline | 0.2500 | 1,367 events | Xu et al. 2025 |
| Llama 4 Scout | 0.2190 | 1,367 events | Xu et al. 2025 |
| Gemini 2.5 Flash | 0.1970 | 1,367 events | Xu et al. 2025 |
| PRIMA -o | 0.1937 | 26 markets | This work, practical, and built in 24h |
| Claude Sonnet 4 | 0.1940 | 1,367 events | Xu et al. 2025 |
| Grok 4 | 0.1890 | 1,367 events | Xu et al. 2025 |
| GPT-5 | 0.1840 | 1,367 events | Xu et al. 2025 |
PRIMA -o achieves 0.1937 on 26 real resolved markets, placing between Gemini 2.5 Flash and Claude Sonnet 4 in the published benchmark rankings, without a full enterprise retrieval pipeline or multi-thousand-event training set. The architecture is the edge, not the model size.
Links
- Final ZIP submission: https://drive.google.com/drive/folders/1Cy-dGhaADTUf65Lj0uvMhx0zV1proTKo?usp=sharing
- Presentation: https://www.figma.com/deck/XhGqkfo4g928W8WTymcABe


Log in or sign up for Devpost to join the conversation.