-
-

PridePost
-
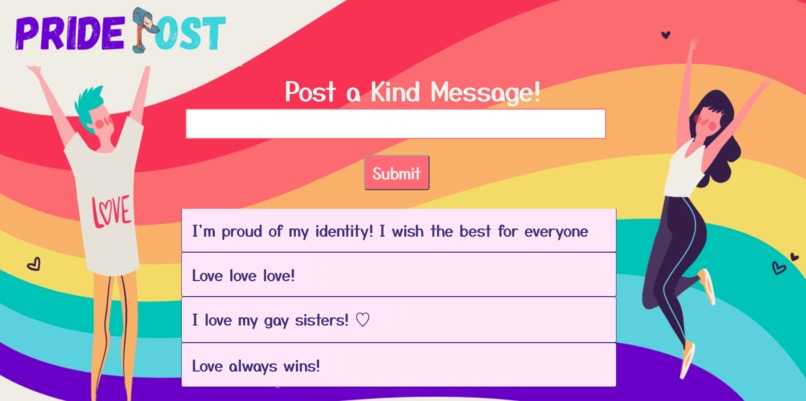
Website
-

Infographic on hate speech

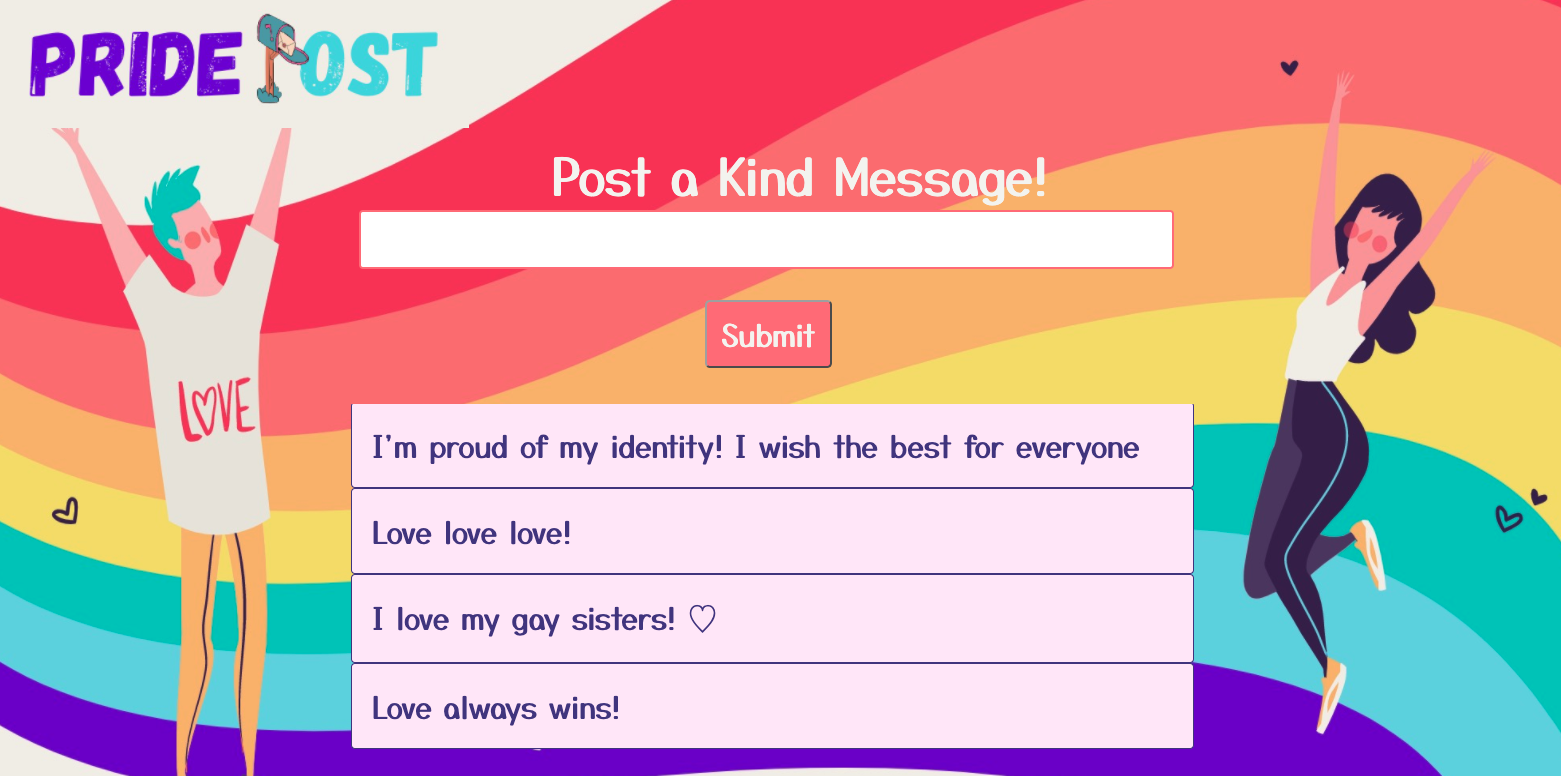

Inspiration
We were inspired by the need to provide safe spaces online for the LGBTQA+ community after facing harassing messages ourselves. Hate speech addressed to people based on gender identity or sexual orientation is a major contributor to the high suicide rate among queer people, so our solution aimed to remove all aspects of hate speech in an LGBTQA+ forum.
What it does
Our website allows users to post messages either anonymously or as themselves to the community board to support anyone who reads it, namely the LGBTQA+ audience. However, our machine learning model embedded in the website utilizes sentiment analysis to ensure that every post is positive and uplifting. For example, if a meanspirited user decides to upload a negative, especially homophobic, message, their post will be caught by our model and deleted before it is even uploaded.
How we built it
We built the machine learning model with Python using an nltk dataset to train it. Then, we used Flask to connect the machine learning model to the front-end of the website. We also created a database to store all the affirmative messages that users can upload. We additionally used Canva and Goodnotes to design the graphics on the site.
Challenges we ran into
Given the time constraints, it was difficult to find the best open-source dataset relating to sentiment analysis that fit our machine learning needs. Additionally, designing the website was challenging; we had to navigate Flask and quickly understand how best to make it appear aesthetic.
Accomplishments that we're proud of
This was the first machine learning model we built for a project, and we’re happy that it works and is able to detect positive versus negative messages!
What we learned
We learned how to build a machine learning model using Python and expanded our knowledge on using Flask to make websites. We also used other resources to supplement the website’s graphic designs, including Canva and Goodnotes.
What's next for PridePost
With more time, we would love to make a more accurate machine learning model by using a larger dataset to train it.





Log in or sign up for Devpost to join the conversation.