Inspiration
The idea for PriceSift emerged from a problem the four of us faced when developing the website for a startup we are working on. The startup, called IWant_, helps users meet their dietary goals at restaurants, by scraping restaurant data from the internet. However, we consistently faced the problem of scattered, and unreliable data, for which there was no workaround. But it's not just us. Many companies struggle with getting good data when web-scraping, which is why we decided to create a solution.
What it does
PriceSift works like a chatbot, and on the outside, it looks like a simple GPT wrapper, but its so much more than that. When a user asks a question, PriceSift grabs the top reliable sources from Google Chrome related to the question, and feeds them to our AI agent, that generates responses based on those sources.
How it works
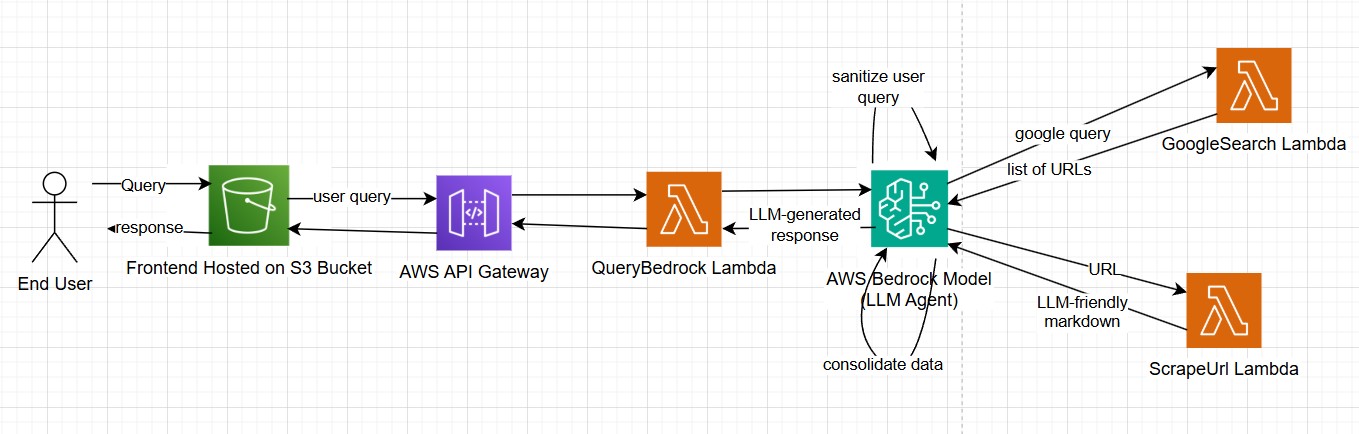
PriceSift works in a multi-step process to input a user question, and return a result after scraping data from the internet.
Step 1
The user asks the chatbot a question
Step 2
The user query is converted into a form suitable for search engines.
Step 3
The Bedrock Agent uses the GoogleSearch Lambda tool to retrieve hundreds of related URLs.
Step 4
The Bedrock Agent uses the ScrapeUrl Lambda tool to convert the HTML code of select URLs into LLM-friendly markdown format.
Step 5
The LLM consolidates the received data and generates a response to fit the user query to deliver to the frontend.
How we built it
We built PriceSift by creatively utilizing technologies from the AWS Suite. The entire architecture was based around using Lambda functions to create each part of the functionality, from cleaning the query, to retrieving results from chrome, to extracting html and converting it to an LLM-friendly format. At its center lies an AI Agent made in Bedrock, which combines all of these tools (made in lambda functions) where one of the tools helps clean up the user query and pass it to a google search library. Our scraping tool takes the urls and obtains the HTML content from the website, thus enabling the LLM to make informed decisions for further analysis. The LLM then sends its response to the front end, so the user can see the final decision made with the web scraping.
Challenges we ran into
One problem we faced involved our struggle with an oversized library that Lambda kept rejecting. Eventually, after many hours of struggle, we ultimately had to change the language our lambda function was programmed in to one that had a lighter library with the same functionality.
Accomplishments that we're proud of
Sometime around 3:30 A.M, we passed out on our beds after a lambda function that was supposed to retrieve a response from the AI agent kept failing, no matter what we tried. Even though it was our final task, none of us knew whether or not we were going to finish. However, by some miracle, at 5:00 A.M, the four of us woke up, almost simultaneously, with the same goal in mind: fix the error, complete the solution. We restructured our approach. Using YouTube to find code, and ChatGPT to debug our code in a frenzy wasn't working. So, we scraped through the AWS documentation, until, just when we thought it was too late, we found what we were looking for. We scrambled to finish, implementing new code based on the documentation, and debugging rapidly. We were handling interactions between our services, and before we knew it, we were finished.
What we learned
While we were building this project, we learned about perseverance, but we also learned about a much more computer-science-specific issue: the importance of documentation. Not only that, but after multiple misunderstandings about the functionality of our individual tasks, and a lot of time wasted, we learned the importance of understanding the full system architecture to prevent miscommunications.
What's next for PriceSift
We could improve PriceSift's reliability by:
Improving Data Collection Accuracy
- By enhancing our web scraping algorithms to handle different website structures more efficiently, we can return improved responses to the user.
Increasing Scalability and Speed
- By optimizing the architecture to handle more URLs from Google, we can improve responses. However, if we did this, we would also need to improve response times.
Built With
- amazon-web-services
- apigateway
- bedrock
- lambda
- s3

Log in or sign up for Devpost to join the conversation.