-
Main slide

Inspiration
We wanted to do something useful, that could be eventually implemented in real-life situations, and given that most of our team was a data science geek, we wanted to use AI and, what is better than a ML algorithm? Two different ML algorithms that complement each other!
What it does
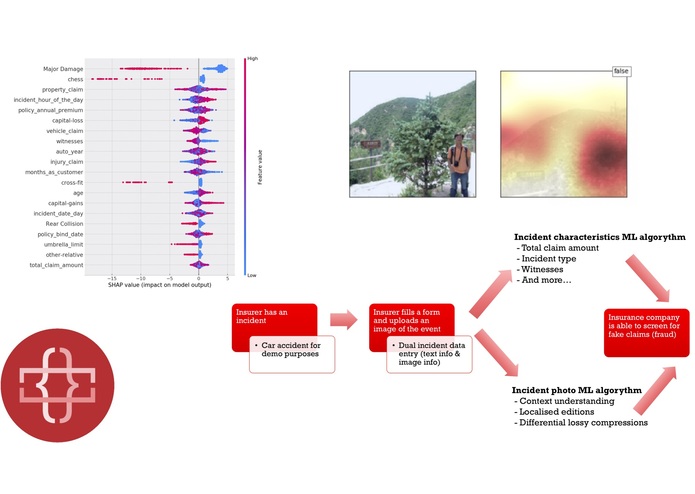
It spots fraud in insurance claims by screening for fake incident reports and for fake images (aka photoshopped). It consists of an integrated tool accessible through a web page, where the insured is able to complete a form about the incident and provide a photo of the situation.
Then, the text information regarding the incident characteristics goes through a ML algorithm to assess if it's fake or not and the photo goes through another algorithm to assess if it's photoshopped or not. Furthermore, both algorithms are able to tell what have they found suspicious to allow further investigations on that specific topic.
How we built it
Incident characteristics algorithm: using a GradientBoosting machine, using one-hot encoding to deal with categorical variables, and using Synthetic Minority Over-sampling Technique (since fraud datasets are usually skewed), we built a complete scikit-learn pipeline.
Photoshopped images algorithm: we used two approaches, we started using Deep Learning with a convolutional neural network (Resnet50) but it was not practical since it only provided classification, so we switched to Error Level Analysis which provides segmentation as well, focusing on the JPG/JPEG lossy compression detection. We believe humans are the ultimate responsables of such a monetary decision, so that's why we provided a screening tool focused on explainability and not a definitive decision without ability to further investigate
Integrated platform: we created an analytics suite powered by a Flask web server with the following workflow:
- The user introduces the data (incident characteristics and image)
- Our models screen for fraud by checking suspicious traits in all data sources
- Our visualizations help the human in the loop make an informed decision, while saving time and effort.
Challenges we ran into
It's only been 24h but we had plenty of time to run into a wide variety of challenges.
Some of them are the inexistence of an easy-to-use library to detect photoshopped images and finding an insurance claim dataset with appropriate labels to train our algorithm.
We also tried to get some explanations for the outputs of the model for the tabular data, however, we could not get any meaningful results after trying all the possible approaches and libraries. After building a complete scikit-learn pipeline to deal with categorical values, missing values imputing and feature scaling (since that's the best practice), we found out the libraries designed to explain those algorithms are no "pipeline friendly".
We also tried to get a heatmap to "explain" the predictions of our convolutional neural network, after learning how to get the weights and gradients of the penultimate layer, we ran into extra difficulties that made it impossible to implement the feature even though the main and most complex part of it was working.
Accomplishments that we're proud of
Getting an acceptable accuracy recognizing photoshopped images, since it's not something that many people have worked on.
Deploying many API endpoints to interact with our models. One thing is training an algorithm and something completely different is being able to serialize it and putting it in a production-like environment (and we're not even talking about explaining the contribution of each feature).
What we learned
Machine learning in production is difficult (reliability, explainability, going beyond tutorials).
The inner workings of state-of-the-art techniques in the field of AI/DL.
Algorithm explainability with shap values.
What's next for Screening fraud
We have really enjoyed the time working together and look forward to expand our knowledge in truly interesting topics such as machine learning explainability, AI projects deployment and image forensics. During the hackathon we have created some worthy code snipeds which are very proud of, such as the graphics explaining feature importance and the Error Level Analysis for photoshopped images. We don't discard them to GitHub as a stand-alone gists or small repos. Count on us for next year edition!


Log in or sign up for Devpost to join the conversation.