-
-
Our Project Poster!
Pretty Please
A tag and generate model to convert non-polite sentences to polite sentences
LINK TO FINAL WRITEUP: https://docs.google.com/document/d/1INEgMHabsU6IN-bGZYQpIHL3FjMGQawjQK531PFbLng/edit?usp=sharing
LINK TO OUR SECOND CHECK IN REFLECTION: https://docs.google.com/document/d/1LytbibEKFFxkp47uvoUitoHLoVidrWShTu6fKH04QeA/edit?usp=sharing
Who
Team Name: MIT
Members: Ishan Hasan (ihasan2), Matteo Lunghi (mlunghi), Tom Liu (tliu46)
Mentor TA: Jason Manuel (jmanuel2)
Introduction
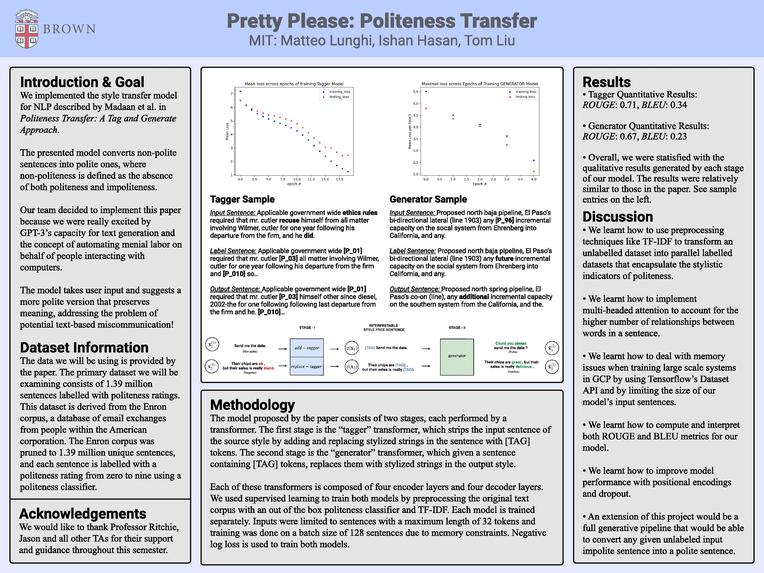
For this project, we will be implementing the style transfer model for natural language processing described by Madaan et al. in Politeness Transfer: A Tag and Generate Approach. The paper introduces the new task of politeness transfer. The paper primarily addresses the issue of converting non-polite sentences into polite sentences, where non-politeness is defined as the absence of both politeness and impoliteness. Beyond this, the model is evaluated on other types of language style transfer as well.
Our team decided to implement this paper because of our interest in NLP. We were really excited by the GPT-3 model’s capacity for text generation and the concept of automating menial labor on behalf of people interacting with computers. For example, letting a NLP model automate away the menial task of manually filling in charts that exhibit clear patterns. This got us thinking about style transfer tasks within NLP and led us to a task that everyone probably spends a bit too much time thinking about: text based communication! It’s far too easy for text communication to be misconstrued because of the lack of tone variations and body language indicators commonly used in speech, so when we communicate over text messages or emails, we spend a lot more time sprinkling our messages with verbal niceties to compensate for this. This brought us to the politeness transfer paper by Madaan et al. The model described takes user input and suggests a more polite version that preserves meaning, addressing the problem of potential text-based miscommunication!
Related Work
Previous work in style transfer for NLP has been focused on the tasks of sentiment modification, caption transfer, persona transfer, gender and political slant transfer, and formality transfer. Politeness transfer on the other hand is a newly defined task. Here, Futurity wrote an article about the paper this project is based on. The article talks about just how nuanced the quality of politeness is. Politeness in human language is filled with subtleties and differs across cultures. For that reason, the scope of the paper this project is based on focuses only on a controlled subset of language.
Resources
Politeness Transfer: A Tag and Generate Approach Arxiv
Politeness Transfer: A Tag and Generate Approach Github (IMPLEMENTED IN PYTORCH)
Data
The data we will be using is provided by the paper by Madaan et al. The primary dataset we will be examining consists of 1.39 million sentences labelled with politeness ratings. This dataset is derived from the Enron corpus, a database of email exchanges from people within the American corporation. The Enron corpus was pruned to 1.39 million unique sentences, and each sentence is labelled with a politeness rating from zero to nine using a politeness classifier.
Resources
Politeness Transfer: A Tag and Generate Approach Full Dataset
Original Enron Dataset
Methodology
The model proposed by the paper is a transformer model consisting of two stages. The first stage is the transformer which strips the input sentence of the source style by adding and replacing stylized strings in the sentence with tokens. The second stage is another transformer which replaces [TAG] tokens with stylized strings in the output style. The model requires an estimation of polite phrases and impolite phrases from the dataset in order to conduct supervised learning for each stage separately. Negative log loss is used to train both transformers.
Metrics
The two primary dimensions along which we plan on measuring our model’s success are (1) style transfer accuracy and (2) content preservation. The metric used to measure transfer accuracy is the percentage of generated sentences classified to be in the target domain by a pre-trained classifier based on the AWD-LSTM architecture and a softmax layer trained via cross-entropy loss. On the other hand, there are two metrics we will be measuring for content preservation: BLEU-self and ROUGE. The paper also measures a third metric, METEOR, which we will consider to be one of our reach goals. The authors in the paper compared their own results to a baseline model, which simply appends the phrase “but overall it sucked” at the end of an input sentence to transfer it into a negative sentiment and appends the phrase “but overall it was perfect” to transfer it into a positive sentiment. We will be using a similar framework to have a baseline against which we can measure our models performance. Our base goal will be to implement the tagger module, which tags phrases in the input sentence that associate the input to the source style (non-politeness). Our target goal includes also building the generator module, which replaces the tagged phrases with phrases associated with the target style. We aim to measure our model’s performance using the BLEU and ROUGE metrics. Our reach goal is to measure our model’s performance using the METEOR metric and also use one of the other datasets mentioned in the paper to train our model for other types of language style transfer.
Ethics
One ethical aspect to this project concerns the major “stakeholders” in solving this problem. As an independent team developing this idea for a class project, our team has a relatively accuracy metric based goal in developing the model, it is important to note that if such a model were to be implemented in an industrial consumer electronics context, many complex motivating factors might dictate the optimization of the end model, for example, the importance of not miscommunicating a key idea that could end up in a lawsuit. On the other side of the coin in this consumer electronics standpoint, we note that other stakeholders include all English speakers (writers) who might use such a technology. We also note here that such a technology for increasing the “politeness” of text communication is not a single paintbrush with which to cover the entire population of English speakers. This comes down to the fact that not all users might agree on what types of messages might be considered polite or impolite, including based on individual preferences and regional customs. Additionally, those with ASD and other communication disorders might be disproportionately likely to appreciate a tool that suggests a more socially acceptable (i.e. polite) way to phrase a given communication. Given this awareness of the different stakeholders, we must also recognize the varying impacts on these stakeholders that mistakes in this model might produce. As a politeness transfer that applies a generation function, we often see even in the examples of training and testing in the paper that the meaning of the politeness generated sentence of a given impolite sentence often fails to communicate the intended message that a human’s understanding of natural language would have understood. Worse than failing to communicate, though, can be failing to communicate, and instead, communicating the opposite idea. Applied in certain contexts, the cost of such a mistake could be very high. Not so much with regard to the type of person, but to the situation, communication is universally important and everyone needs their message to be heard as is in certain situations, for example, the stakes are much higher when making a business decision than when scheduling an online Zoom meeting. Another area of ethics that we’ve kept in mind while formulating this project were about the broader societal issues that are relevant to a discussion of politeness. The questions about what is considered polite popped up even between our group members when observing the classifications of the paper’s examples, leading us to believe that what is considered polite is a subjective matter that does not necessarily have hard and fast rules, which we recognized would be a challenge in interpreting the results of our model. For example, the paper tagged and replaced a critical review of the food of a restaurant with a positive one, completely negating the point of the communication and prompting us to wonder whether criticism, which we all agreed is oftentimes necessary, is deemed impolite. This in turn challenged our perspective on “politeness” as being some kind of moral high ground to aspire to during communication, making us wonder about the role of politeness in human communication and if the need to be polite is really something that should be a guiding factor in communication at all. In all likelihood, these questions will remain somewhat unanswered through the course of our implementation, although we as a team must be aware of our implicit judgements and values regarding the necessity of politeness in communication when working with the training data, as we recognize that our biased opinions as the model makers propagate through to the results of any user interaction with our model.
Division of Labor (Roughly)
Ishan will implement preprocessing, training, and evaluation functions.
Matteo will implement the encoder layers for both the tagger and generator.
Tom will implement the decoder layers for both the tagger and generator.
Built With
- python
- tensorflow





Log in or sign up for Devpost to join the conversation.