-

Sample Output 1
-
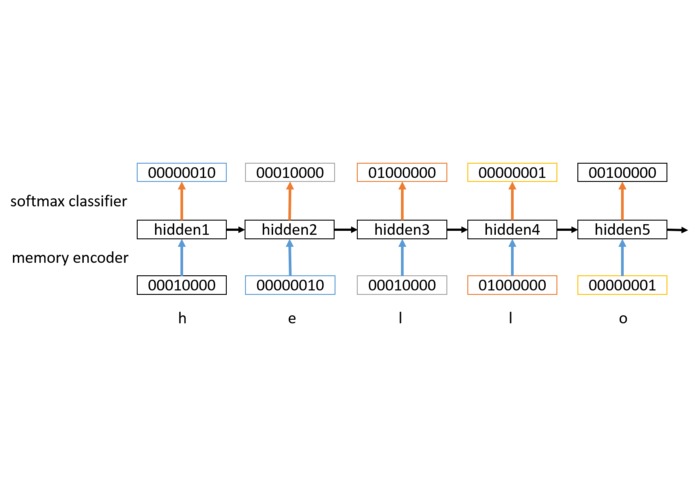
RNN Architecture
-

Sample Output 2

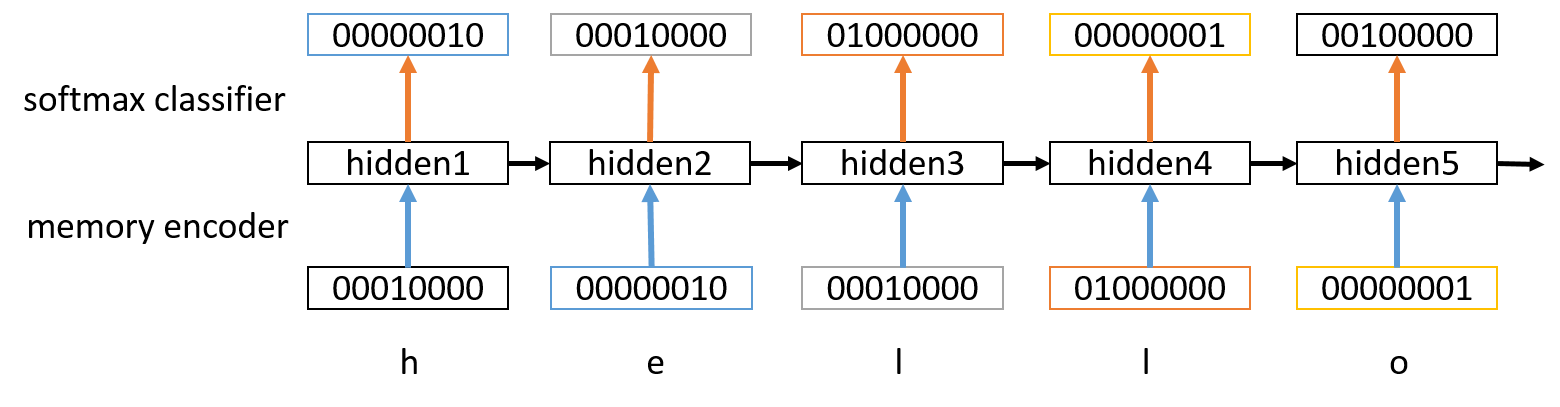

The Force Ghost Writer
Inspiration
Our project stems from a simple question: can you model text well enough to generate original content? We’d recently seen the new Star Wars movie, and were immediately hungry for more. Unable to bear the wait until the next movie comes out, we decided to see if we could write a program to automatically generate a screenplay for a new Star Wars movie. We were also very excited by the recent release of Google’s TensorFlow API. We’re strong believers in deep learning and saw this as a perfect fit for our task.
What it does
The specific language model we’re using is an LSTM, a specific type of recurrent neural network. The LSTM reads the scripts for Star Wars films one character at a time, and tries to predict the next character. After a few hours, it becomes very good at doing this. We can then give it a starting seed, and then have it predict the next page of text. By doing this, it is effectively generating new content inspired by the patterns it finds in the training data.
How we built it
We used Google’s TensorFlow API to build our LSTM. TensorFlow allows us to have a strong amount of control over our network’s architecture, and it has good support for GPU computation. This meant that we were able to train efficiently on an AWS GPU instance. The network itself uses one-hot encodings for every character in the training text, and then feeds this into two stacked hidden layers per LSTM cell, and then uses a softmax classifier to predict the one-hot vector of the next character. Using the Adam optimization algorithm, we can minimize the resulting perplexity with respect to the network weights.
After training, we can generate text by feeding in a short seed word, and then incrementally computing the hidden states and then the predictions for the next character. We adjust the predictions using a temperature which can control how original vs. faithful the new text is compared to the training data, and then sample the character from the adjusted distribution.
For the front-end, we developed a web application in Ruby on Rails, incorporating HTML, CSS, and Bootstrap. The website provides a clean and approachable interface into the neural network parameters.
Challenges we ran into
We’ve done some work in TensorFlow previously on convolutional neural networks, which was relatively easy, but the framework for recurrent neural networks was more difficult to work with than we were expecting. It took us quite a while to understand how to generate data once we had trained the LSTM, but by reading up on the theory behind the networks we were able to figure it out. Andrej Karpathy has a blog post on RNNs that was particularly helpful in this regard.
We also had some difficulty setting up the web server. It was an interesting (and painful) process of setting up the proper build environment for Ruby on Rails on our Amazon ec2 Instance and getting it to serve up our website to a public DNS.
Accomplishments that we’re proud of
The model does a very good job of learning the subtleties of the way that text in a screenplay is formatted. It quickly learns that the text is broken up into paragraphs, separated by character names in all caps, often centered on the page. It also learns how to construct vaguely meaningful sentences, which is very impressive considering that it is trained on a character by character basis, and has no understanding of words beforehand.
What we learned
We learned a lot about how RNNs work through this project. Although we have some experience in other techniques, this was our first project on modeling text data, which came with its own unique challenges. It’s interesting to think that our model knew absolutely nothing about the structure of our data, or even the way that characters are grouped together to form words. This makes our model highly generalizable, to the point that we could apply the same network architecture to learn how to model almost any other text or even arbitrary time-series data.
What’s next for The Force Ghost Writer
There’s still a lot of parameter tuning that can be done to improve performance. We weren’t able to conduct an exhaustive search over all hyperparameter values, but doing so could probably make our generated text a fair bit more realistic. We’re also severely limited by the size of our dataset; all in all we have only half a megabyte of data in total, which is much less than is normally needed by deep learning models. Expanding on our dataset could give us much better results.
Built With
- amazon-web-services
- css3
- deep-learning
- google-tensorflow
- html
- neural-networks
- python
- ruby
- ruby-on-rails
- star-wars
- tensorflow




Log in or sign up for Devpost to join the conversation.