-
-
As you are recording your speech, your audio is being analysed and measured for features such as words per minute.
-
As well as filler words.
-
-
-
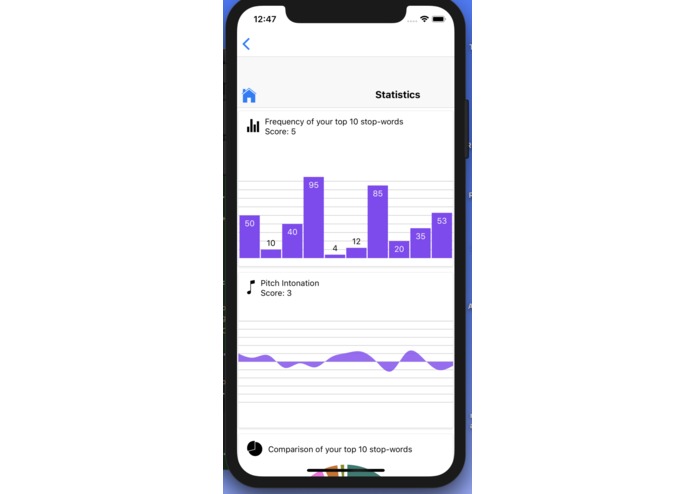
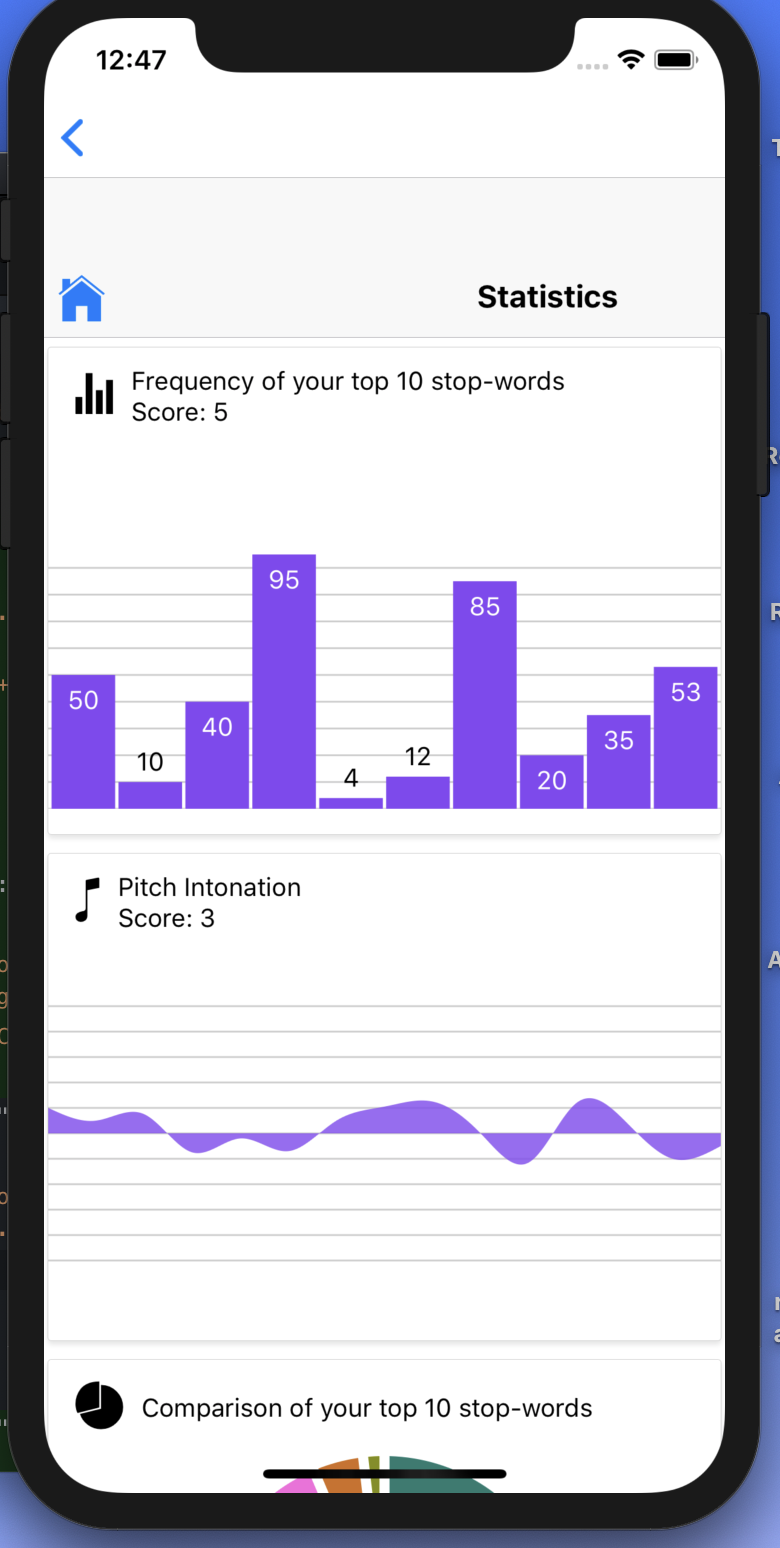
You can also view much more detailed feedback with various statistical data visualizations.
Inspiration
Each and everyone of us has struggled with some fear in our life that held us back from achieving our potential. From students to even great artists alike, most of us have quietly suffered from the fear of the audience, or the fear of public speech. But today, success in life is dependent not only on one's skills but also on the confidence and charm one holds. So our team decided that we wanted to do something about it.
OR{ai}TOR helps you become an even better orator with practice runs, evaluations based on some of the best speakers in the world and keeping track of your personal improvement and growth style. Our app can also be aimed at foreign nationals/elderly who want to practice/learn to speak in English but are often deterred to do so because of embarrassment. Thus, the long term purpose of the app is two-fold: empowering minorities by giving them a tool to express themselves and helping people enhance their professional speech.
What it does
OR{ai}TOR runs on an artificial intelligence model that is trained on data sets to recognize higher quality of speech from some of the most influential speakers of the world like Obama. The model learns from these speeches and compares parameters like pitch variation, intonation (deviations in loudness) & voice modulation, overall speech rhythm and tonality. It also reports the excessive use of filler words and provides a relative result to the user accordingly. The user can record themselves speaking out loud and let the agent analyze their performance. The user can be assured of being in the hands of the best mentors!
How we built it
React-native for frontend app development (iOS, Android) Keras API for AI to create our deep learning model libROSA for music and audio analysis and calculating quality of voice parameters & voice spectrograms Audioset & other online open source .wav speech datasets to train the model Python as our base language for to design the software
Challenges we ran into
Daniel: This is my first time doing mobile app development. Learning new frameworks. Arkar: Spent 3 hours working with errors on timers and learned a lot more about JavaScript. Rajvi: Worked on backend and had to handle an AI model which trained on three different constraints and manage the data structure dimensions to satisfy that requirement. Sean: Worked on backend and guided front-end development. Handled issues with input dimensions for keras data sets.
Accomplishments that we're proud of
Successfully reaching an accuracy rate of about ~0.9 for our model. We were also able to come up with our quality of voice constraints: we defined it to consist of a uniformly varying intensity and tempo. We were able to learn to use libROSA to generate spectrograms to analyze the voice modulation and accurately generate peaks for our calculations.
What we learned
We learned to use a challenging audio library, libROSA, which did not have a lot of documentation available online. We were put in a position where we had to be innovative in coming up with the factors that would decide how to rate quality of speech and we all learned a lot of speech waveforms and transforms in python. Training the AI model on was a great experience as it helped us understand the inner working of every line of code we used from keras.
What's next for OR{ai}TOR
A defined score panel that reviews the user's performance and attaches a score to it along with an achievements bar. This would lead to a more interactive user experience and cause long lasting usability while adding a fun element to an actually tedious process. We would also like to display a history plot that shows the progress of the user according to score and also display what speaker they match closest to. This would add on to the user interaction factor for the app. One practical addition could also be speech training exercises which the user can complete like a game and earn achievements for.
Built With
- android
- audioset
- ios
- json
- keras
- librosa
- python
- react-native
- tensorflow

Log in or sign up for Devpost to join the conversation.