-
-

-

logo
-
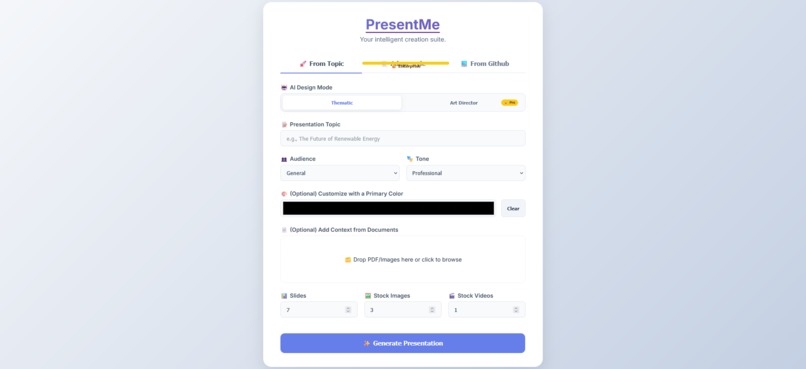
create page
-
presentation views



Inspiration
The genesis of PresentMe lies in a universal inefficiency observed across institutions: the immense waste of expert time on the manual, low-value task of creating presentations. From corporate strategy to academic research, valuable institutional knowledge—often locked in dense documents, reports, and codebases—faced a significant barrier to being communicated effectively.
Our inspiration was not merely to simplify slide design, but to fundamentally re-architect the entire communication workflow. The vision was to build an intelligent agent, not just a tool. The pivotal moment came with the realization that modern AI, combined with powerful, scalable technologies like TiDB Serverless's native vector search, could create more than just slides. It could build a searchable, dynamic "institutional memory," making an organization's own knowledge instantly accessible and ready for high-impact communication.
What It Does
PresentMe is an AI-driven communication platform that automates the creation of professional, on-brand presentations, transforming raw information into polished, actionable insights. It functions as a sophisticated, multi-step AI agent that executes complex, real-world workflows from a single user prompt.
The agent’s workflow is a seamless orchestration of advanced AI capabilities:
- Ingests Institutional Knowledge: The process begins by ingesting knowledge from diverse sources, whether it's a simple topic, a comprehensive multi-page PDF report, or an entire GitHub repository.
- Understands and Indexes with RAG: For complex sources, the agent employs a Retrieval-Augmented Generation (RAG) pipeline. It intelligently chunks the content, generates vector embeddings, and indexes them in a TiDB Serverless vector database. This creates a deep, searchable knowledge base specific to the user's content.
- Generates High-Fidelity Content: The agent autonomously performs vector searches against the indexed data to retrieve hyper-relevant context. It then uses this context to generate accurate, detailed, and insightful content, structuring it logically across multiple slides.
- Automates Brand Compliance: A key innovation is the "Adopt This Style" feature. This multi-modal workflow uses an AI vision call to analyze the design of an existing document (colors, fonts) and then commands the LLM to generate a new presentation that is perfectly brand-compliant.
- Integrates External Tools: The agent seamlessly extends its capabilities by invoking external APIs to find stock media (Pixabay), create collaboration sessions (Google Meet), and process payments (Stripe), delivering a complete, end-to-end user experience.
How We Built It
PresentMe is a production-grade, full-stack SaaS application built on a modern, scalable, and capital-efficient technology stack.
Core Backend: The application is built with Python and the Flask framework. Computationally intensive AI workflows are managed asynchronously using a robust background task queue powered by Celery and Redis, ensuring a fluid and responsive user experience.
Database & RAG Engine (The Core): TiDB Serverless is the heart of our platform. It was chosen for its unique combination of MySQL compatibility (enabling easy integration with SQLAlchemy), native high-performance vector search (which powers our entire RAG pipeline), and a serverless architecture that provides automatic, hands-off scaling.
AI and Vector Stack:
- Large Language Model: We utilize the Azure Open AI (
gpt-4o) for all generative and reasoning tasks. - Embedding Model: The
sentence-transformerslibrary (all-MiniLM-L6-v2) creates the vector embeddings for our RAG pipeline. - Text Processing: LangChain's
RecursiveCharacterTextSplitteris used for intelligent document chunking prior to indexing.
- Large Language Model: We utilize the Azure Open AI (
Frontend & Deployment: The user interface is built with standard HTML, CSS, and vanilla JavaScript. The application is deployed live on PythonAnywhere, with TiDB and Redis running as managed cloud services, demonstrating a professional and realistic production architecture.
Challenges We Overcame
The primary challenge was architecting a scalable RAG pipeline that moved beyond simple "context stuffing." This required designing a robust data ingestion workflow: extracting text from PDFs with PyMuPDF, chunking it effectively with LangChain, generating embeddings, and defining a flexible data model (VectorChunk) with efficient SQL queries to store and retrieve vectors from TiDB.
Ensuring system resilience was another critical challenge. We implemented a pre-deduction token system for AI tasks, coupled with an automatic refund mechanism within our Celery workers. This guarantees that if any step in a complex, multi-stage AI workflow fails, the user is not unfairly charged.
Accomplishments We're Proud Of
First and foremost, we are proud of shipping a production-grade SaaS application, not just a demo. It is a live, deployed platform with user authentication, payment integration, and a sophisticated, asynchronous AI backend.
Technically, our greatest accomplishment is the intelligent, context-aware routing system within our create_presentation_logic function. This system autonomously decides whether to use the high-fidelity RAG pipeline for dense documents or a more creative "Art Director" generative pipeline for open-ended topics.
We are also extremely proud of the "Adopt This Style" feature. It represents a true multi-modal agentic chain—combining a vision model call with a constrained language model call—to deliver a unique and powerful capability that provides immense value to institutional clients.
What We Learned
A key insight from this project was understanding the symbiotic relationship between an AI agent and its data backend. The true power of generative AI in a product is unlocked not by a single LLM call, but by orchestrating a chain of specialized tools and high-quality, contextually relevant data sources.
We learned that the quality of the "Ingest & Index" stage is paramount in any RAG system. Most importantly, we recognized the transformative value of a managed, high-performance vector database like TiDB. The ability to offload complex vector search operations allows a small team to build an incredibly powerful, scalable, and enterprise-ready application from day one.
What's Next for PresentMe
The future of PresentMe is to expand from a powerful application into an indispensable institutional communication platform. Our immediate roadmap is focused on deepening our enterprise feature set:
- Team Workspaces & Centralized Brand Kits: Enabling organizations to manage users and enforce brand consistency at scale.
- Advanced Data Visualization: Allowing users to connect to data sources like Google Sheets to auto-generate on-brand, data-driven charts.
- Cross-Presentation Search: Leveraging our TiDB vector database to create a true "corporate memory," allowing users to find insights across all of their past presentations.
Our long-term vision is to become the go-to AI agent for a full suite of institutional documents—from executive summaries to marketing reports—all powered by the robust RAG and TiDB foundation built during this hackathon.
Built With
- azure-openai
- celery
- css
- flask
- gitpython
- google-gemini-api
- google-oauth
- html
- javascript
- langchain
- pixabay-api
- pymupdf-(fitz)
- python
- redis
- sentencetransformers
- sqlalchemy
- stripe
- tidb-serverless

Log in or sign up for Devpost to join the conversation.