Inspiration
Most people practice presentations in front of a mirror or just wing it. There's no feedback, no data, and no way to know if you're actually improving. Professional speaking coaches exist — but they cost hundreds of dollars an hour and aren't available at 2am before your pitch. We built PresentIQ to be that coach: always available, brutally honest, and specific enough to actually help.
What it does
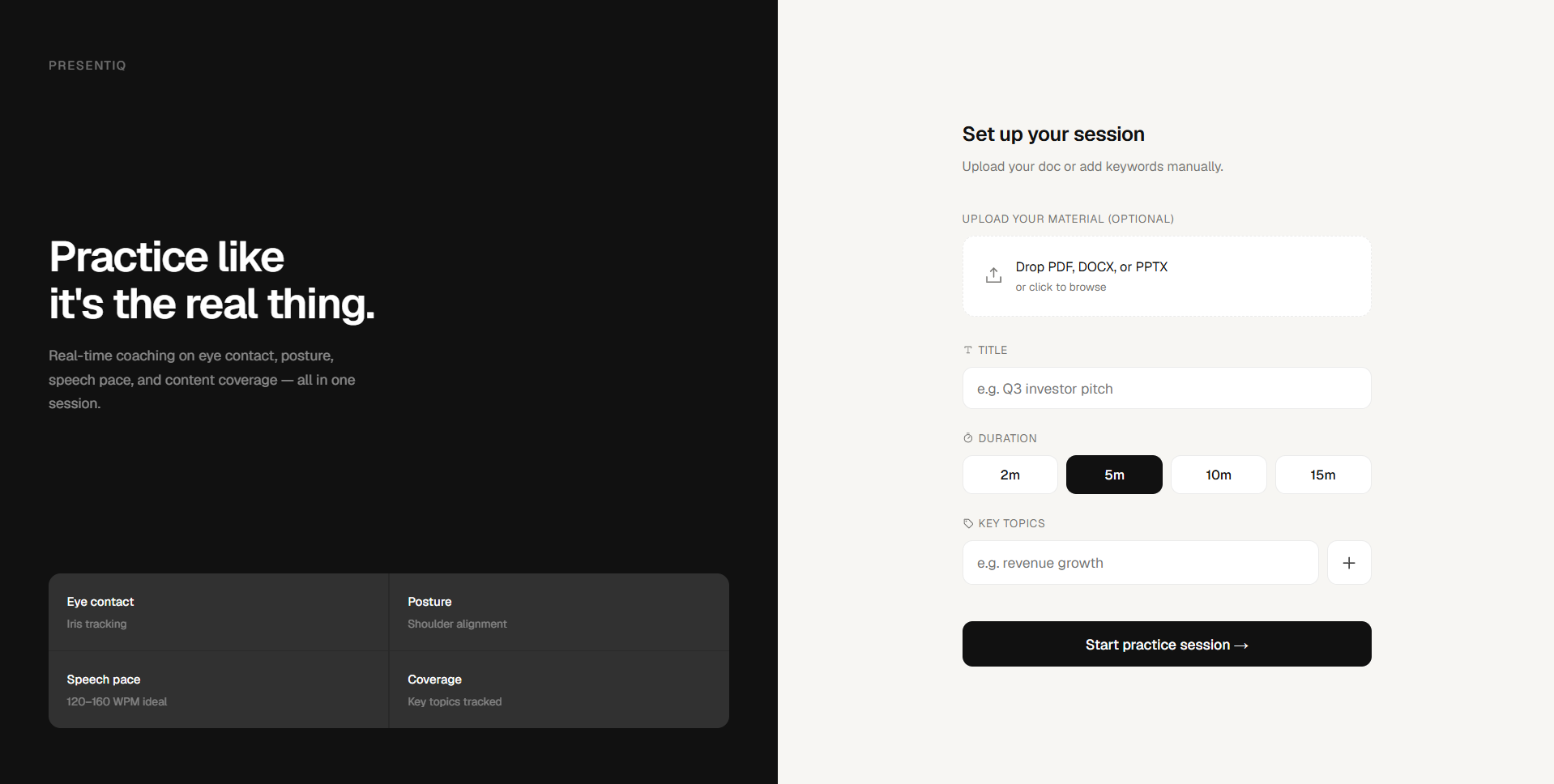
PresentIQ is a real-time AI presentation coach that runs entirely in your browser.
You upload your slides, notes, or PDF before you start. The system reads your material once, extracts your key topics, builds a structured topic map, and generates a readiness quiz — a short chatbot conversation that tests whether you actually know your material before you go live. Weak areas are flagged and watched closely during your session.
During the presentation, PresentIQ tracks:
- Eye contact — via iris tracking and gaze vector estimation (MediaPipe Face Mesh)
- Posture — shoulder alignment, neck angle, spine tracking (MediaPipe Pose)
- Gesture activity — hand landmark motion analysis
- Speech pace — real-time WPM with a hybrid audio pipeline
- Filler words — contextual detection (not naive word matching)
- Content coverage — which topics you've covered vs. which you haven't
Coaching fires on events, not on a timer. When a filler spike is detected, when you hit a key topic, or every 30 words — Groq generates a specific, human-sounding coaching note and pushes it over the WebSocket in under 2 seconds.
At the end, the results page shows your full coaching timeline, a quiz vs. session comparison (did you actually improve on your weak areas?), WPM, filler count, topic coverage, and a full transcript.
How we built it
The architecture is a multi-system pipeline, not a single model:
Audio pipeline (hybrid):
- Web Speech API for instant live captions and fast filler detection
- Groq Whisper (3-second chunks) for accurate transcription and metric recomputation
- Both layers feed transcript chunks to the WebSocket for event detection
Vision pipeline:
- MediaPipe Face Mesh + Iris for gaze estimation
- MediaPipe Pose for skeletal posture tracking
- Temporal smoothing over a 5-frame buffer to reduce jitter
Coaching pipeline:
- SessionMemory object spans the full session — quiz history, rolling summary, confirmed topics, behavioral trends
- Rolling 30-second summaries replace raw transcript before sending to Groq
- Event-driven feedback with per-category cooldowns (no repeated tips)
- Quiz weak areas are passed into live coaching context so the coach watches them
Stack:
- Backend: FastAPI + WebSockets + SQLite
- Frontend: React + Framer Motion + Web Speech API + MediaPipe (browser-side)
- AI: Groq (LLaMA 3.3 70B for coaching, Whisper Large V3 for transcription)
Challenges we ran into
The hardest problem was temporal accuracy. Per-frame scoring is meaningless — a single frame where you glance away is noise, not a signal. We implemented rolling time windows (5s, 15s, session average) and smoothing buffers so every metric reflects behavior over time, not a snapshot.
The second challenge was the audio timing bug: elapsed_seconds is cumulative,
but state.tick() should only receive the duration of the current chunk.
Passing elapsed directly would have doubled the pacing metrics. We separated
chunk_duration and elapsed_seconds into distinct form fields.
Contextual filler detection was also non-trivial. "I like this idea" should not count as a filler. We wrote a context filter that checks surrounding words before flagging hesitation fillers.
What we learned
Coach-level feedback is not one model — it's 6-8 systems that need to agree. Temporal intelligence (judging over time, not per frame) is what separates a real coaching tool from a demo. And the moment feedback arrives in 1-2 seconds instead of 15, the entire product feels different.
What's next
- Word-level timestamps from Whisper for pause detection and filler clustering
- Gesture zone classification (below waist = weak, chest level = ideal)
- Confidence scoring from cross-signal fusion (gaze + pace + gesture combined)
- Session comparison across multiple practice runs to show improvement trajectory