-
-
Agent Desktop App
-
System diagram
Inspiration
Giving a high-stakes presentation is an intense balancing act. When managing multiple teams and presenting complex feature rollouts or performance metrics to stakeholders, the cognitive load is immense. You have to read the room, field sudden questions, and manage your slide deck—all without losing your train of thought. Every time a presenter breaks their flow to find the right slide or recall a specific data point, the audience's engagement drops.
I realized that modern presenters don't just need a clicker; they need an intelligent co-pilot. I wanted to build a system that manages the technology and the trivia, allowing the presenter to focus entirely on the narrative and the audience.
What it does
Presenting Agent is an AI Co-Presenter that lives on your desktop but thinks in the cloud. It perfectly bridges the gap between a Live Agent and a UI Navigator.
During a presentation, the agent continuously listens to the room and observes your active screen. It acts as a real-time conversational partner that can answer audience questions natively with voice, gracefully handling interruptions (barge-ins) just like a human co-presenter would.
Beyond just talking, the agent is your hands on the screen. Because it understands the visual context of your slides, you or your audience can ask it to navigate the presentation. If a stakeholder says, "Can we go back to the architecture slide?", the agent understands the request, confirms verbally, and autonomously executes the system-level keystrokes to change the slide.
How I built it
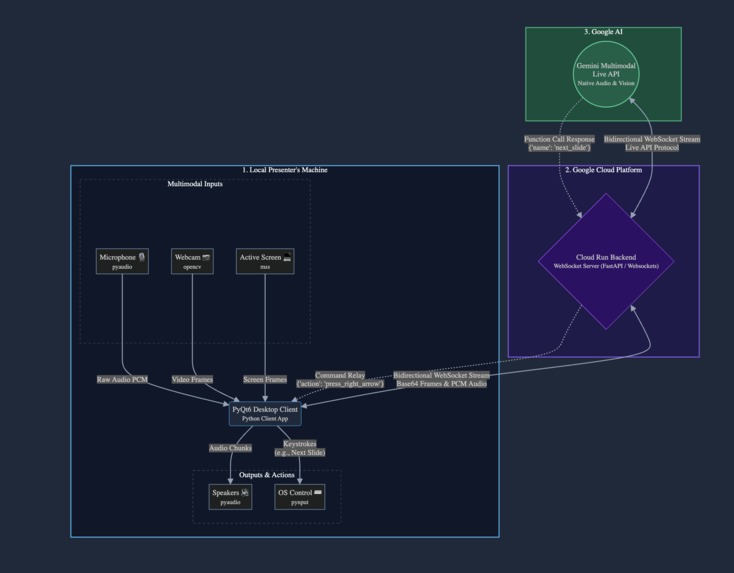
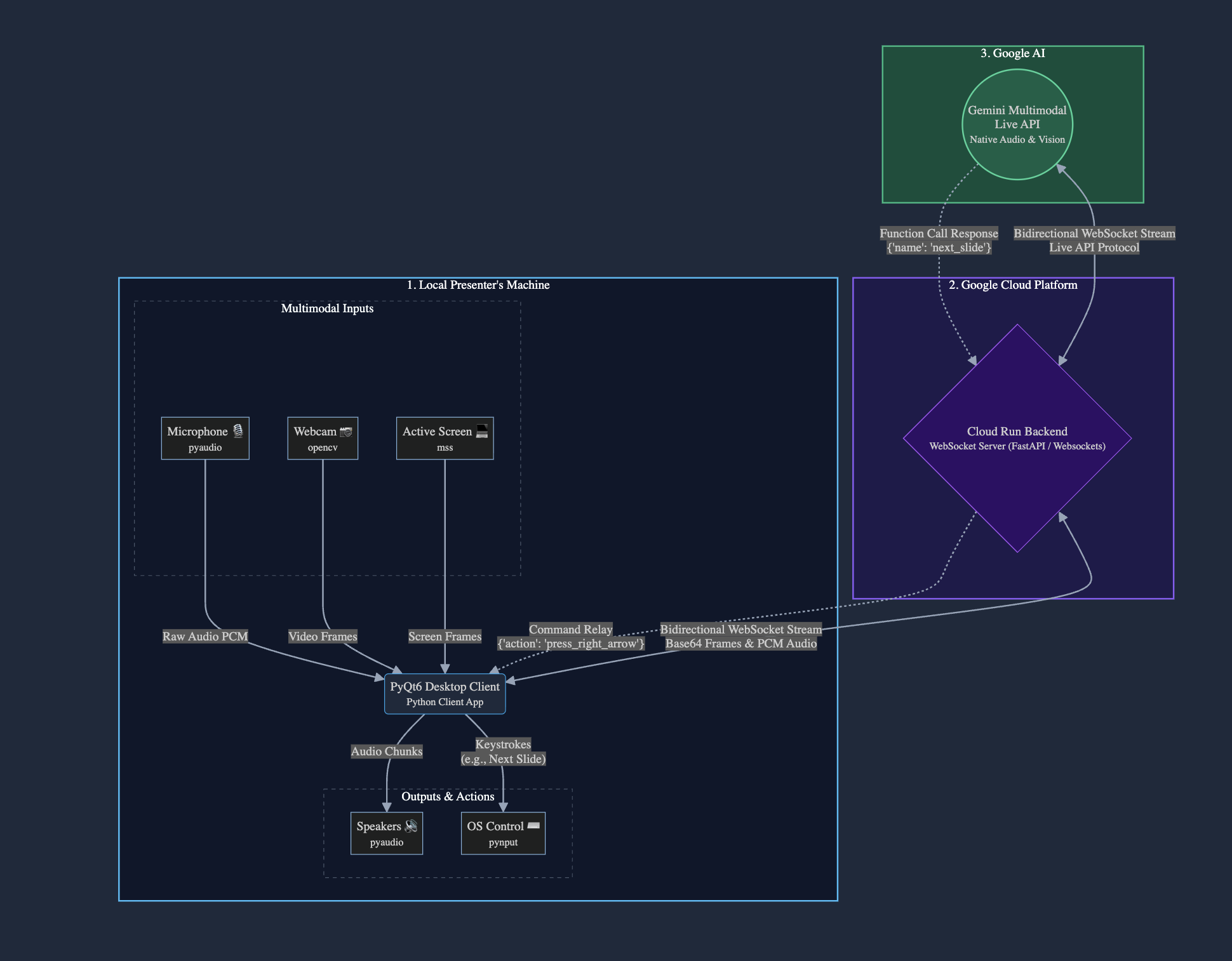
I utilized a secure client-server architecture to ensure local hardware access while hosting the core agent entirely on Google Cloud:
The Cloud Backend (Google Cloud Run): I built and deployed the core agent logic as a containerized Python backend on Google Cloud Run. Cloud Run serves as the "brain" of the operation. It maintains the continuous, bidirectional WebSocket connection to the Gemini Multimodal Live API, processing the multimodal streams. It also registers my system commands (like next_slide or previous_slide) as function-calling tools so the Gemini API knows how to control the screen.
The Desktop Client: I built a lightweight local application using Python and PyQt6 for the interface. It uses mss and opencv to capture screen and webcam frames, and pyaudio to stream microphone input.
The Bridge: The local client opens a secure WebSocket connection directly to my Cloud Run service. Cloud Run routes the live audio/video up to Gemini, and instantly pipes Gemini's native voice responses and UI tool-call commands back down. When the client receives a tool-call command, it uses pynput to safely simulate the necessary keyboard actions to control the presentation.
Challenges I ran into
Managing Multimodal Latency: Synchronizing screen captures and real-time audio streams without causing a bottleneck was incredibly difficult. I had to optimize my local frame-capture rates and rely strictly on WebSockets through my Cloud Run server to keep the conversation feeling natural and instantaneous.
Asynchronous Python Constraints: Running a PyQt GUI event loop, hardware I/O (camera/mic/screen), and an asynchronous WebSocket connection simultaneously led to frozen interfaces early on. I had to carefully architect my asyncio tasks to ensure non-blocking streams.
OS-Level Security: macOS and Windows strictly guard accessibility and screen-recording permissions. I had to build robust error-handling into my client app to gracefully prompt the user to grant the necessary system permissions before the agent could safely execute keystrokes.
Accomplishments that I'm proud of
Successfully merging two distinct hackathon categories (Live Agents and UI Navigator) into one cohesive, high-utility product as a solo developer.
Achieving a truly conversational flow. Building an agent that can actually be interrupted mid-sentence by an audience member and adjust its response on the fly feels like magic.
Engineering a secure, bidirectional cloud-to-local pipeline where an agent hosted on Google Cloud Run can safely and accurately dictate physical system commands to a local machine with near-zero latency.
What I learned
I gained a deep understanding of the Gemini Multimodal Live API and how native audio models drastically outperform traditional pipeline models (Speech-to-Text -> LLM -> Text-to-Speech) in real-time scenarios.
I learned how to effectively deploy persistent, WebSocket-driven containerized applications on Google Cloud Run, taking advantage of its ability to scale while handling continuous, stateful streams.
I mastered the intricacies of Python's asyncio when combined with hardware-level libraries and GUI frameworks.
What's next for Presenting Agent
Expanded Application Context: Moving beyond slide decks to dynamic software demos. I want the agent to be able to navigate a live IDE, highlight specific lines of code, or pull up live performance dashboards during technical presentations.
Session Memory Integration: Implementing Firestore to give the agent long-term memory during a session, allowing it to accurately recall and reference questions asked by the audience earlier in the presentation.
Packaging and Distribution: Compiling the complex Python client into a simple, one-click executable (using PyInstaller) to make it frictionless for non-technical users to install and run their own Co-Presenter.

Log in or sign up for Devpost to join the conversation.