-
-

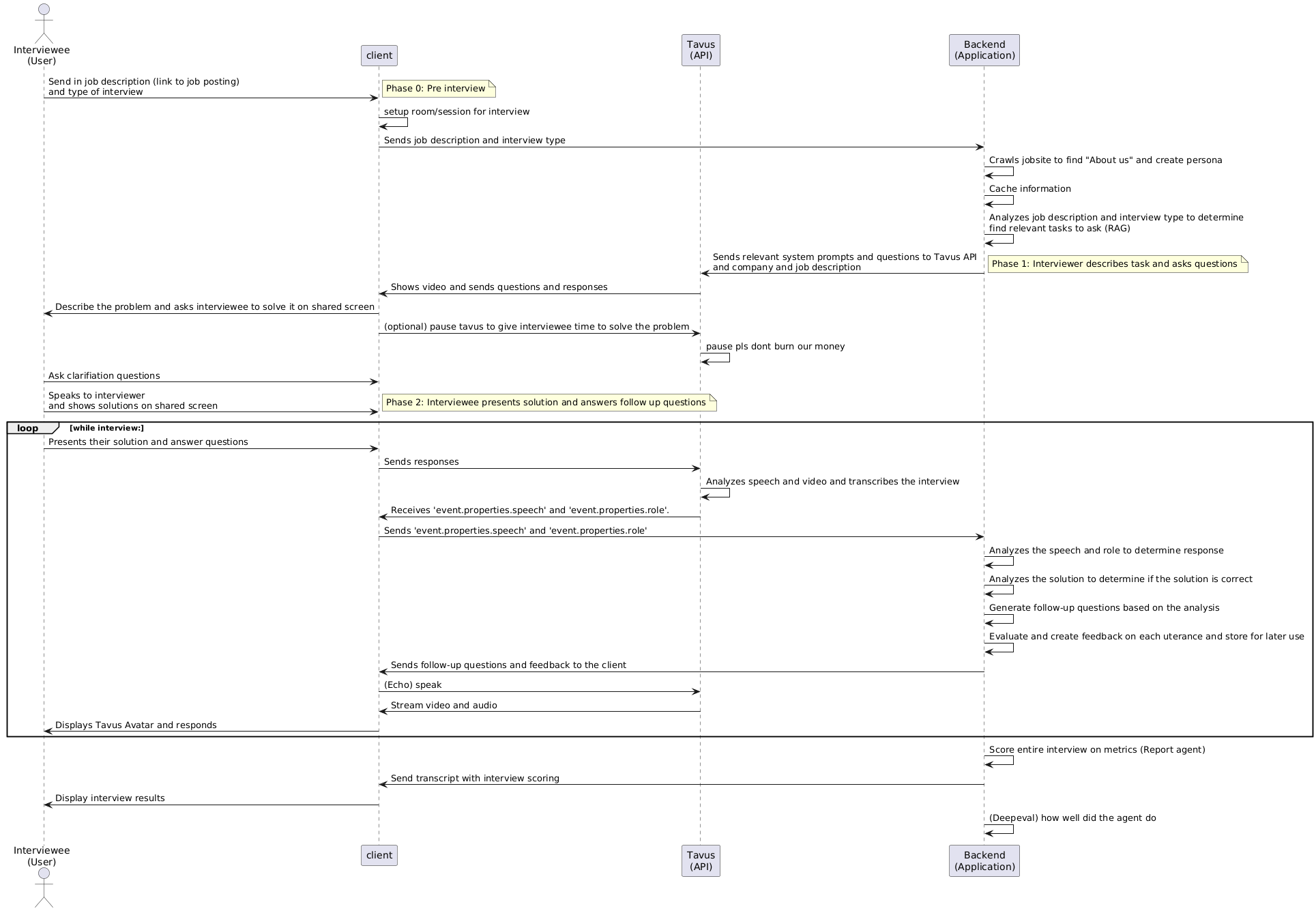
sequence diagram
-
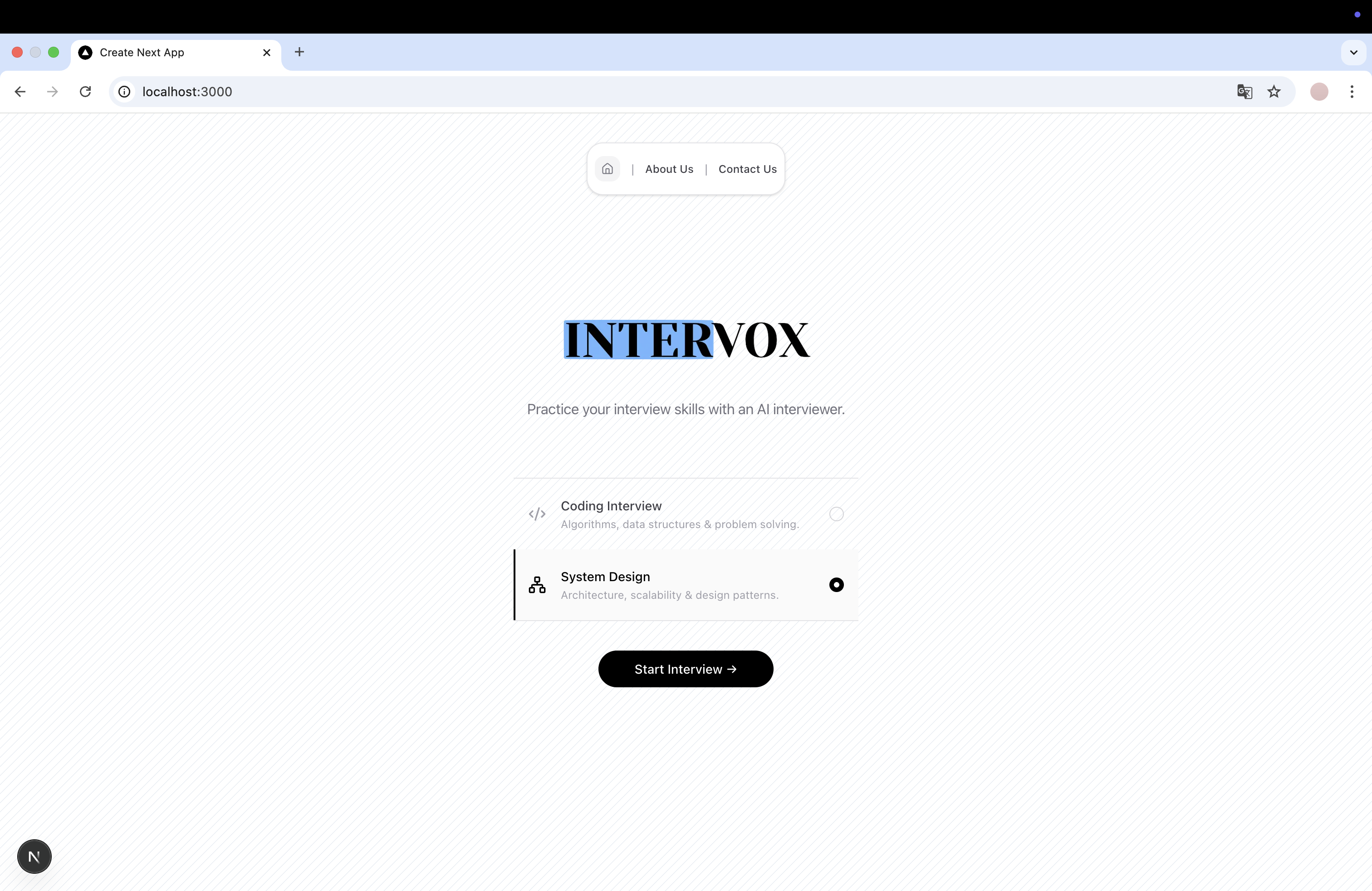
Landing Page
-
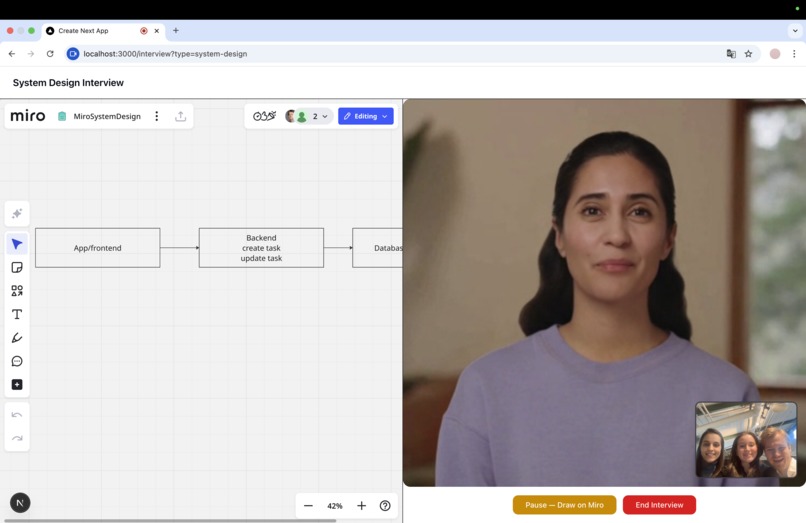
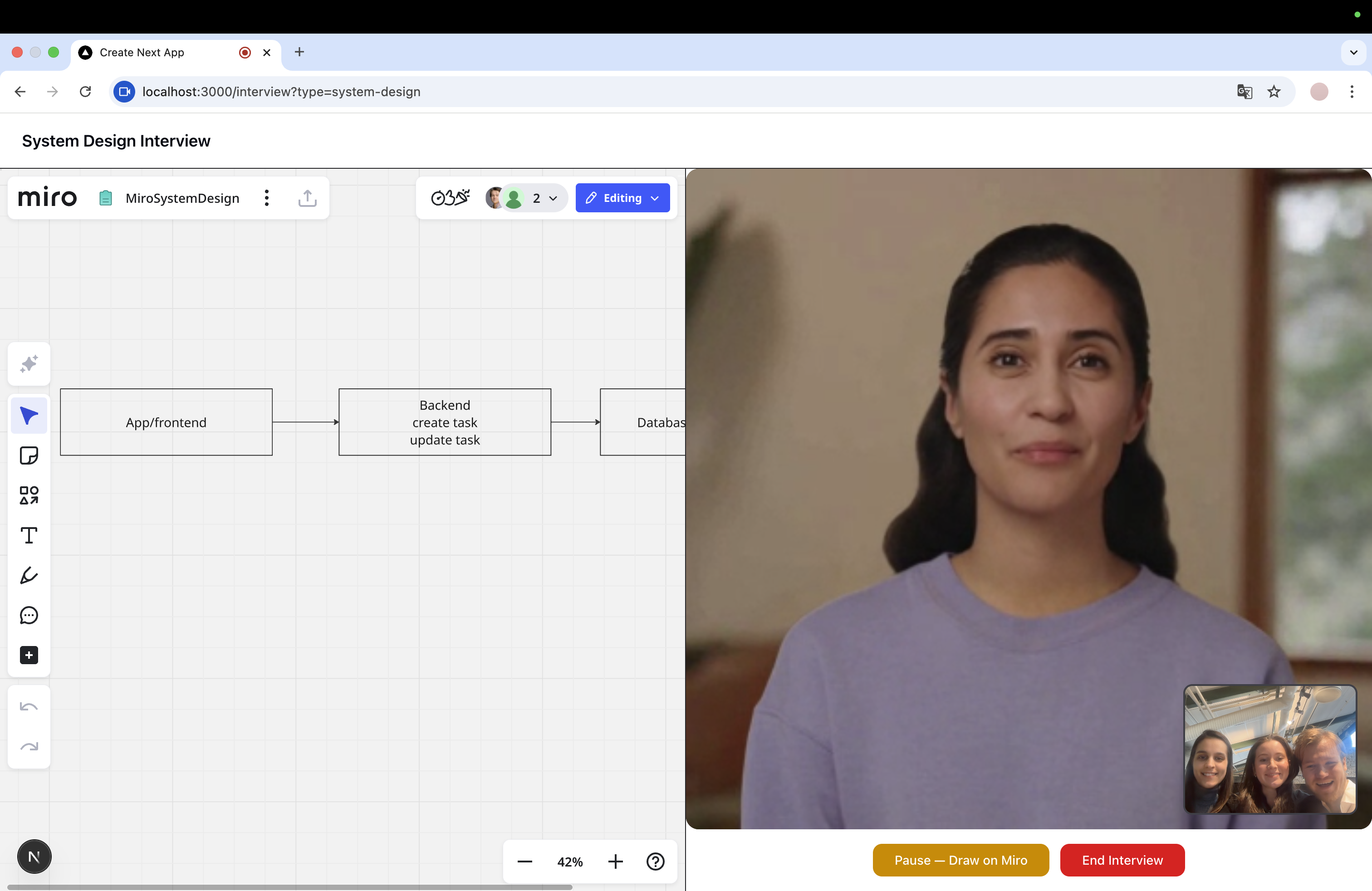
System interview with Tavus Replica
-
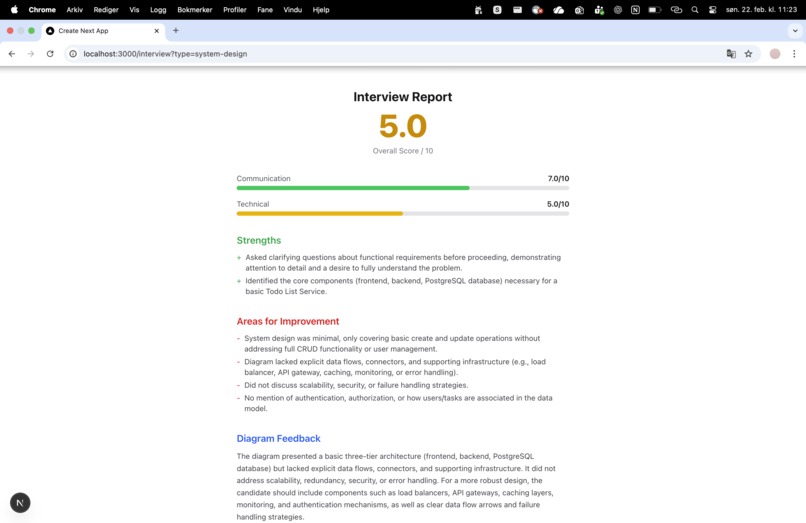
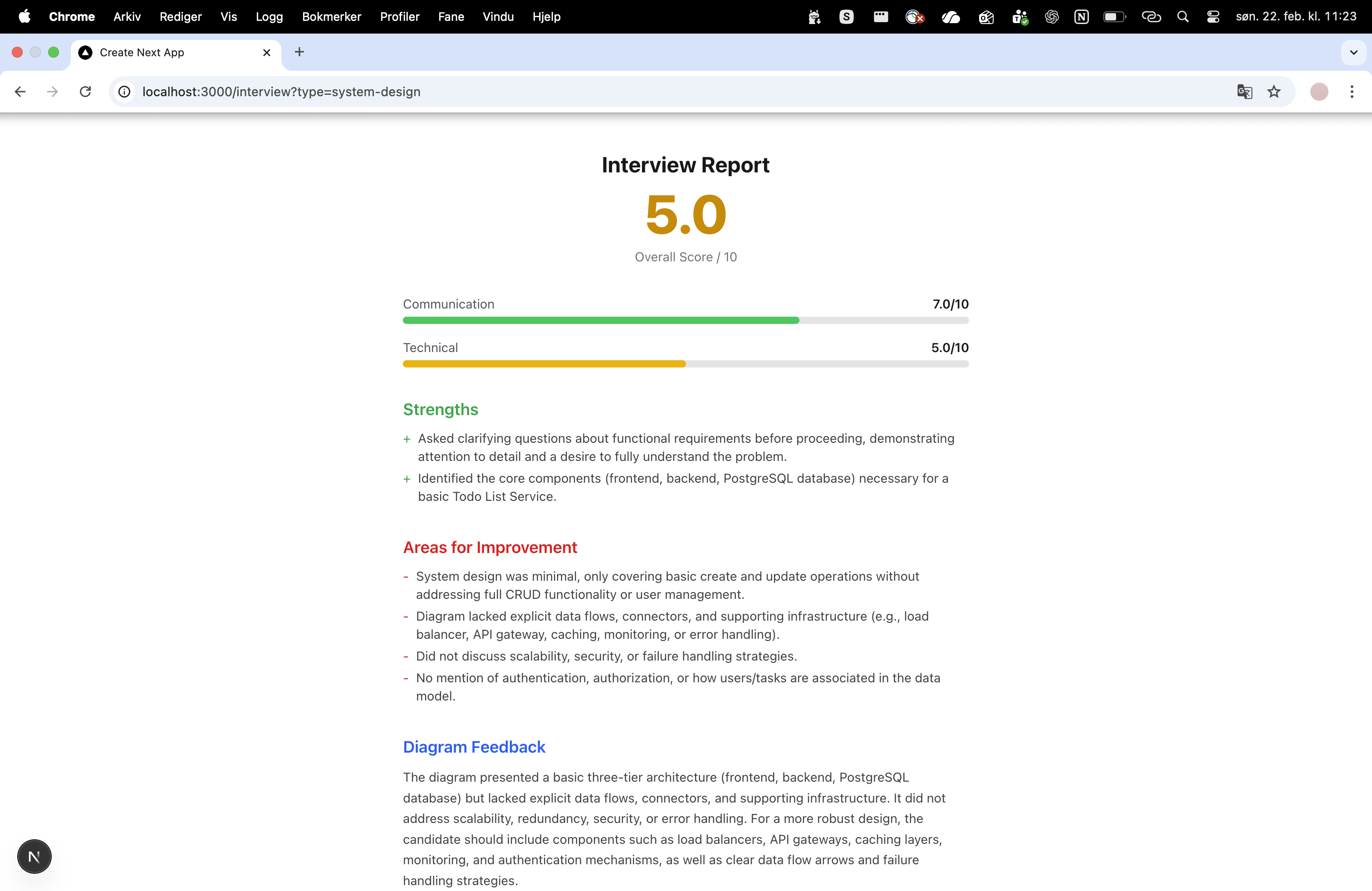
Feedback page
Intervox — DevPost Submission
Elevator Pitch
Intervox is an AI interviewer that feels real. It watches your code, reads your diagrams, challenges your decisions, and scores your performance so you can practice technical interviews under real pressure and walk into FAANG unshakable.
Project Story
Inspiration
Technical interviews are one of the most stressful experiences in a developer's career, and one of the hardest to prepare for. The problem isn't knowledge. Most candidates know the concepts. The problem is the experience itself: thinking out loud under pressure, defending decisions in real time, drawing an architecture while someone watches and questions every choice you make.
There's no way to practice that. You can grind problems on LeetCode. You can read system design blogs. But none of that replicates the dynamic of a real interview: an interviewer watching you work, pushing back on your reasoning, and evaluating not just your answer but your thought process.
We wanted to build what we wished existed: an interviewer you can practice with any time, that feels real, that actually looks at what you produce: your diagrams, your code, and gives you honest, structured feedback.
What It Does
Intervox is a full AI-powered interview simulator. Here's how a session works:
You start an interview. A photorealistic AI avatar appears on video. It greets you and presents a real technical problem, sourced from actual FAANG interview repositories.
You talk through your approach. The avatar listens, asks clarifying questions, pushes back on weak points, and probes deeper, behaving like a real senior engineer would in an interview.
You pause and work. When you're ready to draw, you pause the interview and sketch your system architecture on a live Miro whiteboard. The interview is paused: no resources consumed while you draw.
The AI reads your diagram. When you resume, the AI connects to the Miro board, reads every shape, connector, and label you drew, and builds a structured understanding of your architecture. The avatar comes back and references your actual components by name — "I see you have a load balancer routing to three microservices, but there's no caching layer. How would you handle read-heavy traffic?"
You get a scored report. After the interview ends, you receive a detailed report card: overall score (0–10), communication score, technical score, a list of strengths, areas for improvement, and specific feedback on your diagram.
This isn't a chatbot. It's the closest thing to sitting across from a real interviewer, one that can see your whiteboard.
How We Built It
The AI Avatar — Tavus + Daily.co
The interviewer is a photorealistic AI avatar powered by Tavus, streamed over WebRTC via Daily.co. But here's an important architectural decision: the avatar is a rendering layer, not a reasoning layer. It doesn't do its own LLM thinking. Instead, our backend agents do all the reasoning, and we inject the response back into the avatar's mouth using Daily.co's conversation.echo message protocol. This gives us control over what the interviewer says while keeping the video experience seamless and natural.
Each interview actually creates multiple Tavus conversations, one for the presentation of task and initial Q&A phase, and a new one (enriched with diagram context) after the candidate resumes from drawing. The old conversation is gracefully terminated, and the new one picks up with full history intact.
The Multi-Agent Pipeline — LangChain + LangGraph
Every time the candidate speaks, their utterance passes through a pipeline of 5 specialized LangChain agents, all running on GPT-4.1 at temperature 0:
- Clarity Agent — Scores how clearly the candidate communicates (0–10)
- Feedback Agent — Generates specific coaching points
- Follow-ups Agent — Suggests what the interviewer should probe next
- Correctness Agent — Evaluates technical accuracy and relevance
All four evaluations are then merged into a single context and passed to a fifth agent:
- Final Response Agent — Synthesizes everything into one natural, coherent interviewer reply
This fan-out/fan-in pattern means the avatar's response is informed by four independent evaluations, it's accurate, pedagogically appropriate, and asks the right follow-up. A sixth agent, the Report Agent, runs only at the end of the interview and produces the final scored report card, incorporating both conversation history and diagram analysis.
Diagram Analysis — The Official Miro MCP Server
When the candidate resumes from the whiteboard, a LangGraph ReAct agent connects to Miro's official MCP server at mcp.miro.com over HTTP, authenticated with OAuth 2.1 and PKCE.
Using langchain-mcp-adapters, the agent gets access to Miro's MCP tools and calls them autonomously:
context_explore— Discovers the board's structure (frames, layout, item overview)board_list_items— Fetches every shape, sticky note, text element, and connectorcontext_get— Drills into specific items for detailed content
The agent then produces a structured DiagramAnalysis: identified components with their roles, data flows between them, architectural gaps (missing caching? single points of failure? no auth layer?), and targeted probe questions that reference the candidate's actual component names.
This analysis gets injected into the new Tavus conversation's context, so the avatar can say things like "How does your API Gateway handle failures when calling the User Service?", using the exact names from the board. The AI genuinely read the diagram.
We also built a parallel direct REST API integration with Miro (miro_service.py) that extracts a text-based graph representation of the board, resolving connector start/end items to human-readable labels and outputting arrow-diagram syntax like "LoadBalancer" -> "AppServer" label="HTTP". Two different Miro authentication surfaces, both in production, serving different parts of the pipeline.
Real Interview Problems — Firecrawl
We use Firecrawl to scrape public FAANG interview repositories on GitHub. Firecrawl's agentic extraction mode autonomously navigates these repos and extracts structured problem sets conforming to our schema: problem title, description, difficulty, topic tags. This turns raw GitHub HTML into a clean question bank that powers every interview session.
The Frontend — Next.js 16 + Daily.co
The frontend is built with Next.js 16 and React 19. The interview screen shows the AI avatar in full-screen video with the candidate's own webcam in a picture-in-picture corner: exactly mimicking a real video interview. When the candidate pauses to draw, the view switches to an embedded Miro board. The report card renders with color-coded score bars (green/yellow/red thresholds) and conditional diagram feedback that only appears when Miro analysis was performed.
Containerization — Docker To ensure reproducibility, scalability, and clean separation between services, we containerized both our backend and frontend using Docker. The backend (LangChain agents, Tavus orchestration, Miro integrations, OAuth flows) runs inside an isolated container with all dependencies pinned, while the Next.js client is separately containerized for consistent builds and deployment.
Challenges We Ran Into
Miro MCP OAuth was the hardest part. The MCP server at mcp.miro.com uses OAuth 2.1 with PKCE and dynamic client registration, not the standard Miro API auth. We had to build the entire flow from scratch: dynamic client registration (POST to /register), S256 PKCE code challenge generation, a local callback server on localhost:9876 to catch the redirect, state parameter validation for CSRF prevention, token caching to disk, and automatic refresh with fallback to re-authentication. About 236 lines of hand-rolled OAuth that we had to partially reverse-engineer because documentation was sparse.
Keeping conversation history across Tavus calls. Because each interview spawns multiple Tavus conversations (one pre-diagram, one post-diagram), we had to maintain a unified conversation history across them. The session state machine tracks the full LangChain message history independently of Tavus, so when the new conversation starts, the avatar has full context of everything discussed before the candidate started drawing.
Making the avatar speak what our agents produce. Tavus normally does its own LLM reasoning, but we needed our multi-agent pipeline to control the responses. The solution was using Daily.co's conversation.echo event, we send our agent's synthesized response as a text message, and the avatar speaks it as if it thought of it itself. Getting this to feel seamless took iteration.
Graceful failure handling on resume. If diagram analysis fails (MCP timeout, OAuth issue, empty board), the interview needs to continue, not crash. We built fallback paths so a failed analysis produces a placeholder message and the Tavus conversation still spins up. The candidate never sees an error; the avatar just asks them to walk through their design verbally instead.
What we learned
**We made a conscious decision not to split work by strengths. Instead, we did the opposite. The teammate who had never used Docker was the one who containerized the backend and frontend. The one who didn’t know LangChain agents was the one who implemented and orchestrated them. The others stepped back and explained, reviewed, and debugged together. That forced real knowledge transfer instead of parallel silos and even the “teachers” ended up learning new things, like better ways to orchestrate agents with sub-agents and structure fan-out/fan-in flows cleanly.
**A lot of this project involved things that were new to all of us. We spent hours reading documentation, testing assumptions, and sharing summaries with each other. We learned how to work with WebRTC sessions and react to live events, how Tavus conversations behave under the hood, how Firecrawl’s agentic extraction actually works in practice, and how to authenticate and operate against Miro’s MCP server with OAuth 2.1 + PKCE. **One surprisingly important lesson: sequence diagrams saved us. Once the system involved multiple agents, external video streams, OAuth flows, and conversation restarts, things became hard to reason about. Drawing the interaction timelines made everything click and helped us align quickly.
Built With
- clsx
- daily.co
- deepagents
- docker
- fastapi
- firecrawl
- framermotion
- httpx&aiohttp
- jotai
- langchain
- langgraph
- langsmith
- lucidereact
- miromcp
- next.js16
- ogl
- postgresql
- pydantic
- python
- radixui
- react19
- shadcnui
- tailwindcssv4
- tavusapi
- typescrip
- uv
- uvicorn

Log in or sign up for Devpost to join the conversation.