-
-
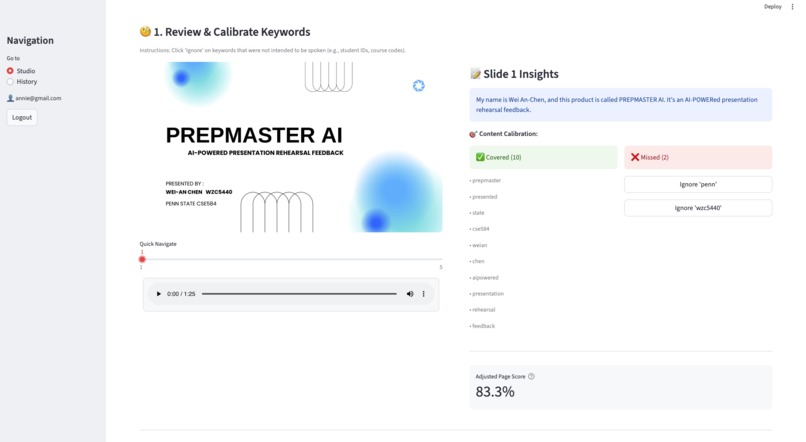
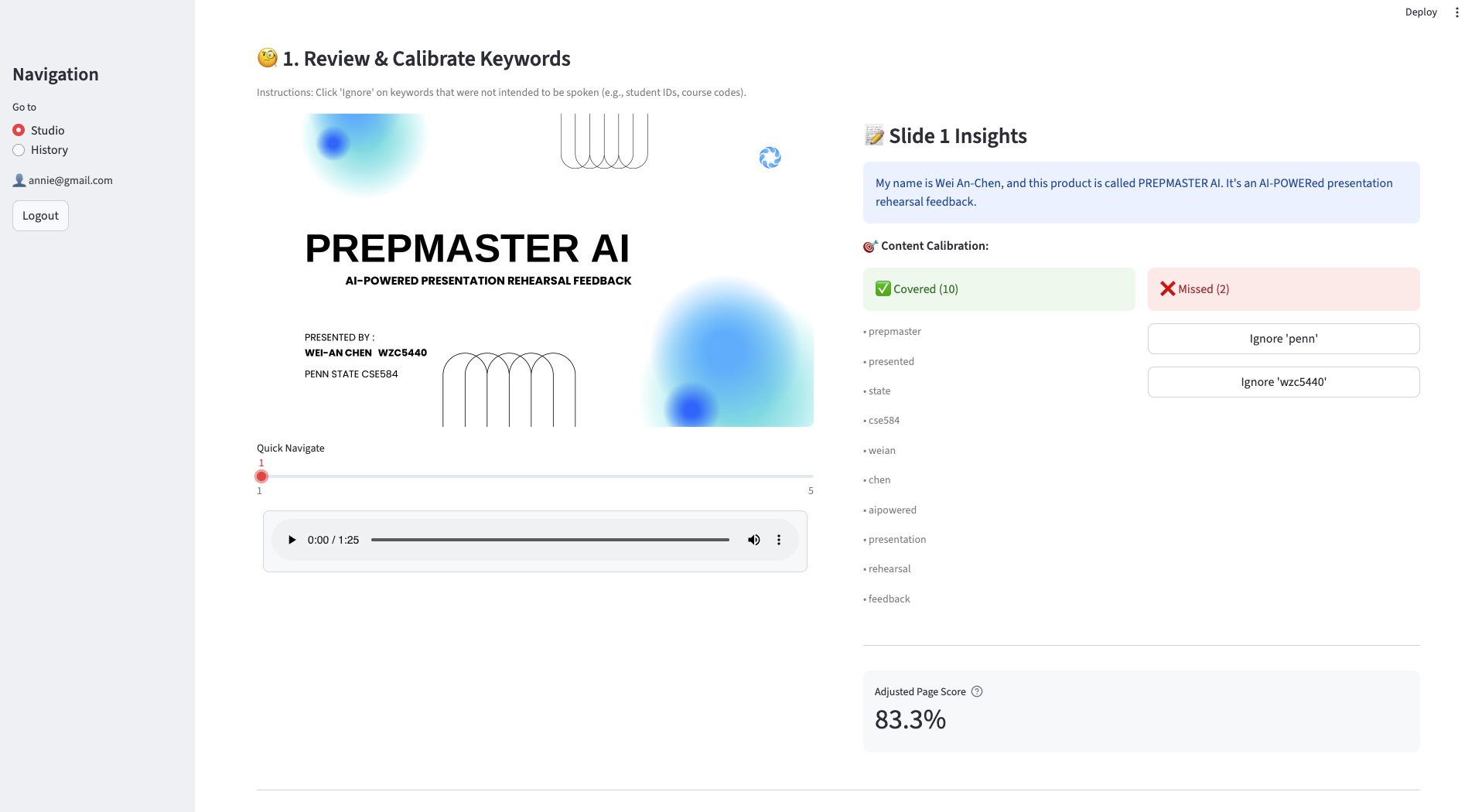
Sync audio with slides and manually "Ignore" non-essential keywords to instantly recalculate an accurate adjusted score.
-

report provides deep insights into fluency, energy curves, and semantic flexibility
-
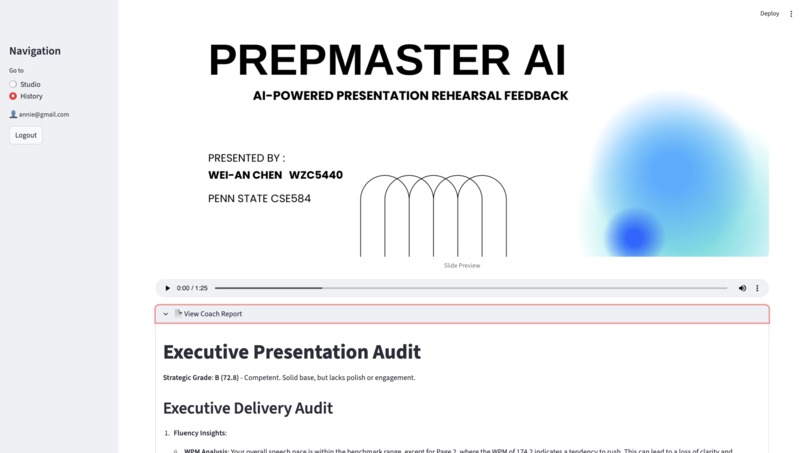
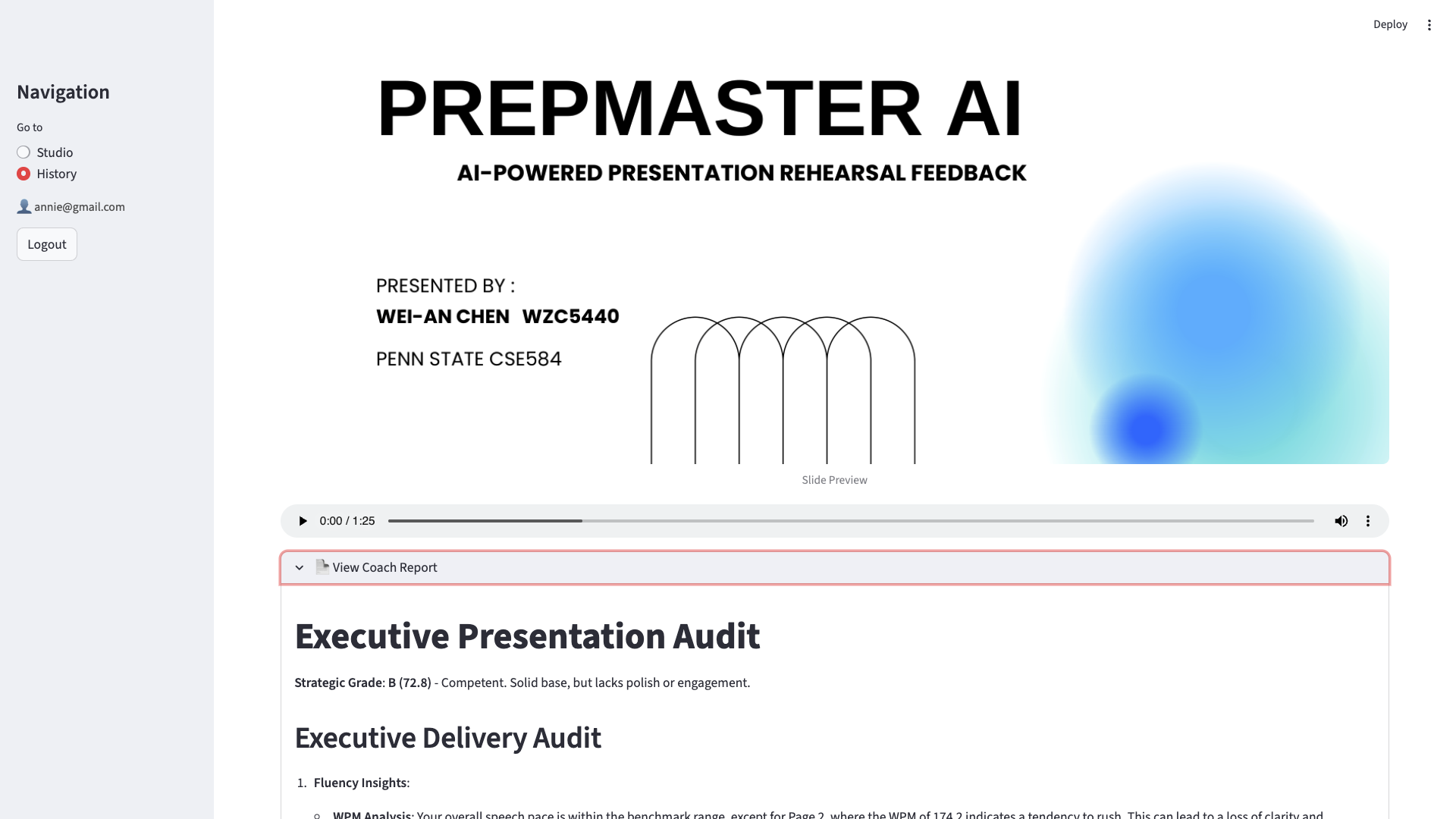
Review previous rehearsal recordings alongside their corresponding AI-generated Executive Audits to track your presentation progress

Inspiration
Cracking the "Black Box" of Public Speaking Presentation mastery isn't just about beautiful slides or perfect grammar; it's about the Multimodal Alignment between visual content and verbal delivery. I realized that most rehearsal tools provide "hollow" feedback—a generic score that doesn't tell you where you failed.
I built PrepMaster AI to provide a granular, slide-level diagnostic that answers the "hard" questions: "Did I actually explain the complex chart on Slide 5, or did I just read the title?"
What it does
PrepMaster AI is a high-precision rehearsal engine that deconstructs a presentation session into actionable data.
- Slide-Level Granularity: Instead of one overall score, users receive a diagnostic report for every single slide based on precise entry/exit timestamps.
- Weighted Scoring (3:4:3): A proprietary algorithm that evaluates performance based on Content (30%), Fluency (40%), and Tone (30%).
- Semantic Verification: Uses Sentence Embeddings to determine if the speaker's ideas match the slide content, even if they paraphrase.
- Acoustic Tone Audit: Detects if the delivery is "Monotone" or "Dynamic" by analyzing pitch variability in the audio signal.
How I built it
The system follows a Three-Pillar Architecture designed to balance deterministic reliability with semantic flexibility.
1. The Deterministic Core (Python & Librosa)
To maintain user trust, core metrics are calculated using hard-coded mathematical logic:
- Acoustics: I used
librosaand thepyinalgorithm to extract the Fundamental Frequency () and calculated the Standard Deviation (SD) to measure pitch variability. - Fluency: Algorithms calculate WPM (Words Per Minute) and detect filler words (uh, um, like) and mumbles using confidence scores from the STT engine.
2. The Semantic Logic (Sentence-Transformers)
To allow for natural speaking, I integrated the all-MiniLM-L6-v2 model.
- Vector Embeddings: Slide text and spoken transcripts are converted into 384-dimensional vectors.
- Cosine Similarity: The system measures the "distance" between ideas. If the slide says "revenue" and you say "income," the AI recognizes the successful coverage through semantic similarity.
3. The Synthesis Layer (GPT-4o)
Finally, all "Hard Metrics" are fed into GPT-4o. By providing the LLM with structured data context (scores, filler rates, missing concepts), it generates a professional Executive Coaching Report that is actionable and objective.
Challenges I ran into
- Multimodal Synchronization: The biggest hurdle was aligning
faster-whispersegments with manual slide transition timestamps. I built a custom overlap-calculation logic (using a 0.15s threshold) to ensure speech was mapped to the correct slide even if the user switched slides mid-sentence. - Tone Thresholding: Finding the right mathematical value for "boredom." After testing various voice samples, I determined that a Pitch SD < 12.0 Hz is the reliable threshold for flagging monotone delivery.
Accomplishments that I'm proud of
- Human-in-the-Loop Calibration: I implemented a feature where users can "Ignore" specific keywords. The system then instantly recalculates the score, giving users control over the AI's judgment.
- Full-Stack Integration: Successfully connecting a Streamlit frontend with a Firebase backend (Firestore & Cloud Storage) and a heavy local AI processing pipeline.
- Data Transparency: Every piece of feedback is traceable back to a specific metric, moving beyond "black-box" AI evaluations.
What I learned
- AI Orchestration: I learned that effective AI systems are about placing AI in the right role. I used code for math/determinism and AI for meaning/synthesis.
- Privacy & Security: Managing audio files in Firebase using Signed URLs taught me how to handle sensitive user recordings securely with time-limited access.
What's next for PrepMaster AI
- Vision-AI Integration: Using GPT-4o-vision to analyze the visual elements (charts/diagrams) of a slide to see if the speaker is explaining the data visuals correctly.
- Real-time Haptic Feedback: A visual alert during the rehearsal if the speaker's pacing deviates significantly from the target.
Tech Stack
- Language: Python 3.10+
- Frontend: Streamlit
- Speech Intelligence: faster-whisper (int8 quantization)
- Audio Engineering: Librosa, Pydub, Soundfile
- NLP & Embeddings: Sentence-Transformers (all-MiniLM-L6-v2), NLTK
- Cloud & DB: Firebase (Firestore & Cloud Storage)
- PDF Engine: PyMuPDF (fitz)
- AI Logic: OpenAI GPT-4o



Log in or sign up for Devpost to join the conversation.