-
-
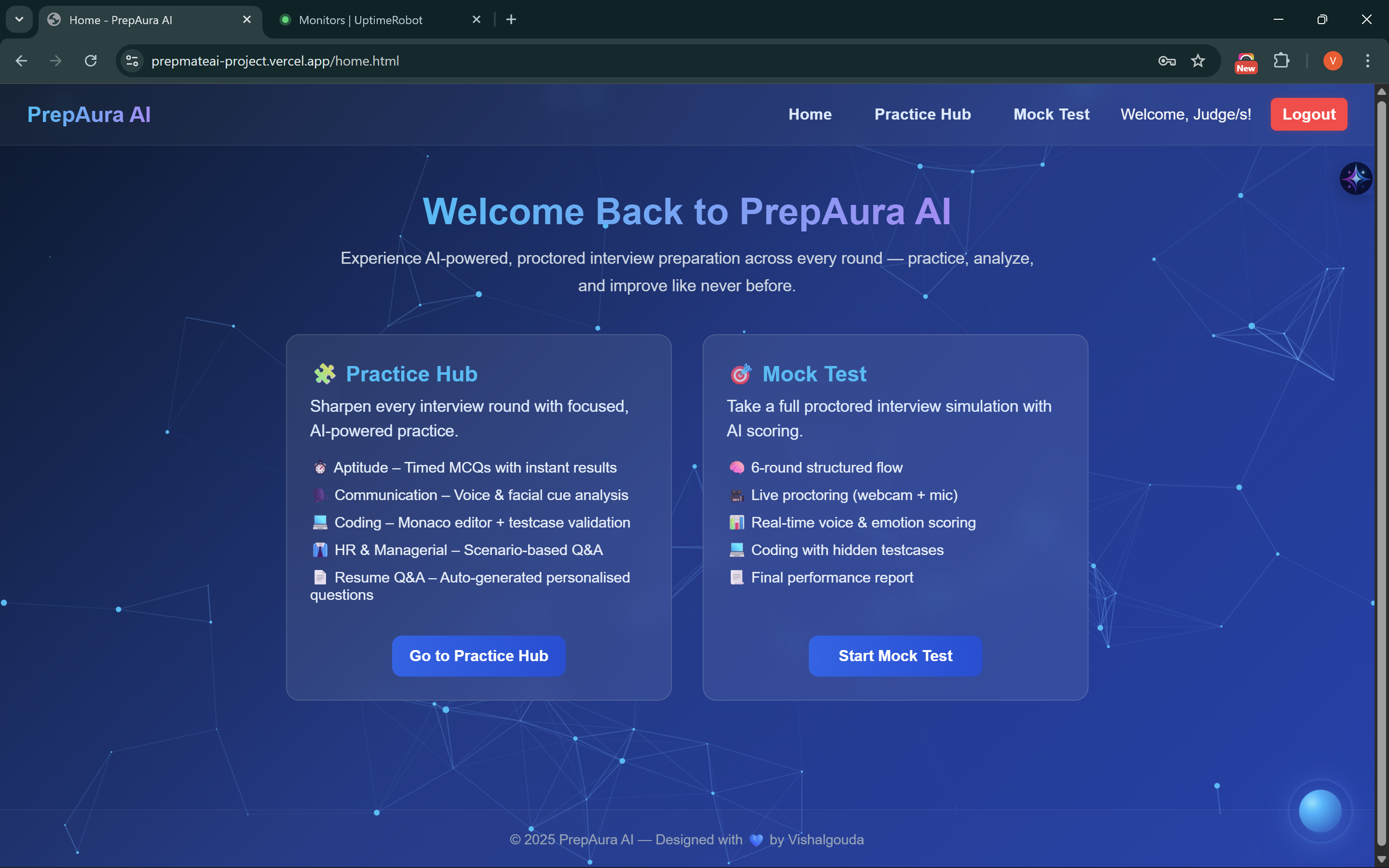
Home page
-
Login page
-
Index Page
-
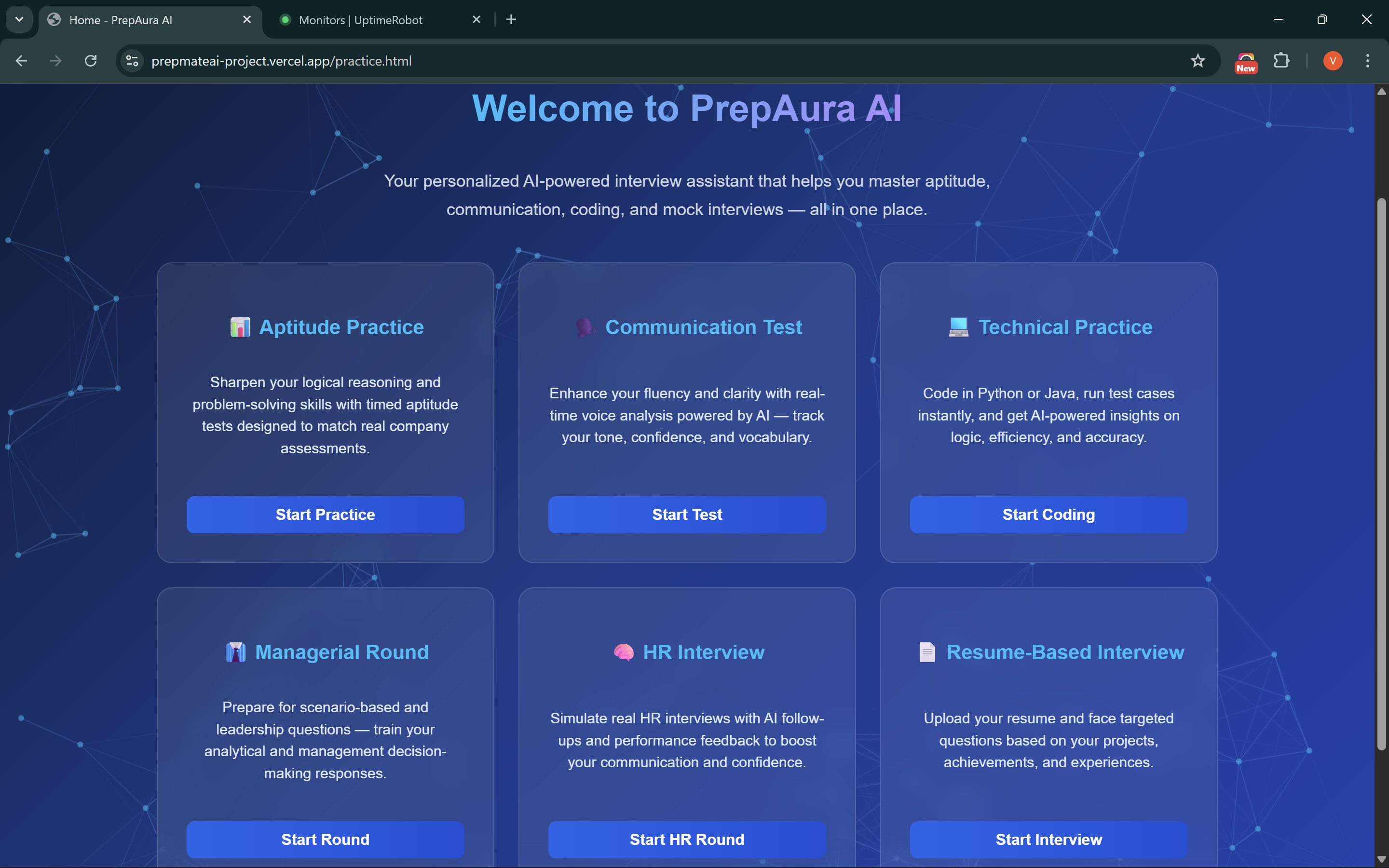
Dashboard will all tools in Practice Hub
-
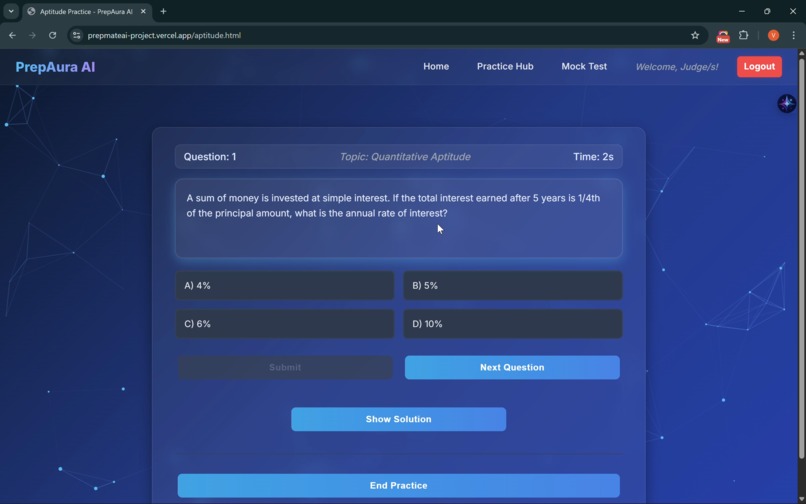
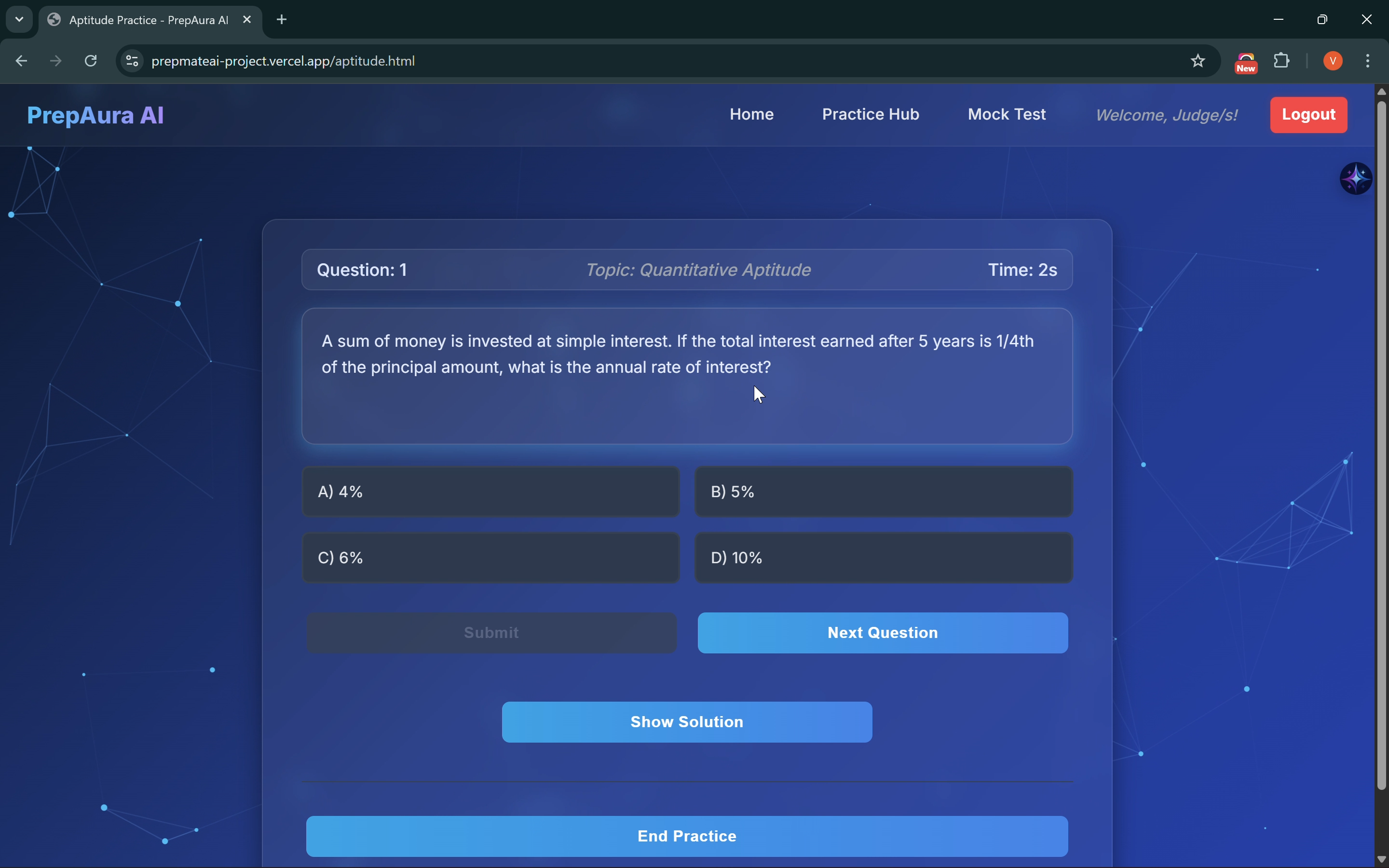
Aptitude Round Interface
-
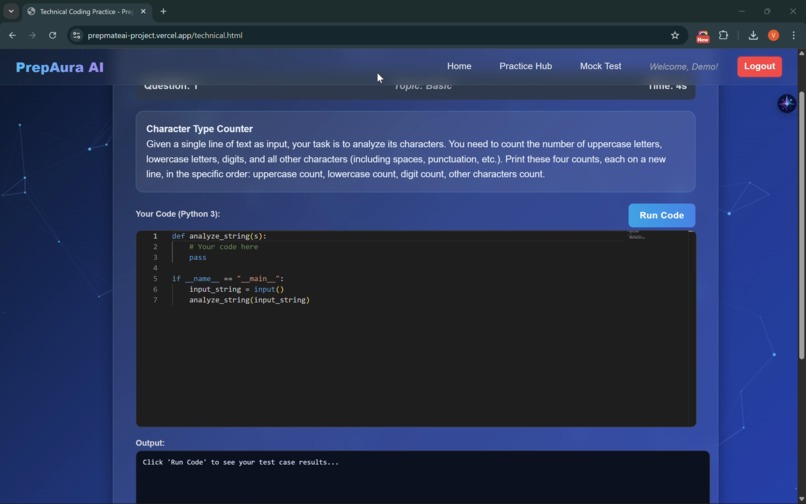
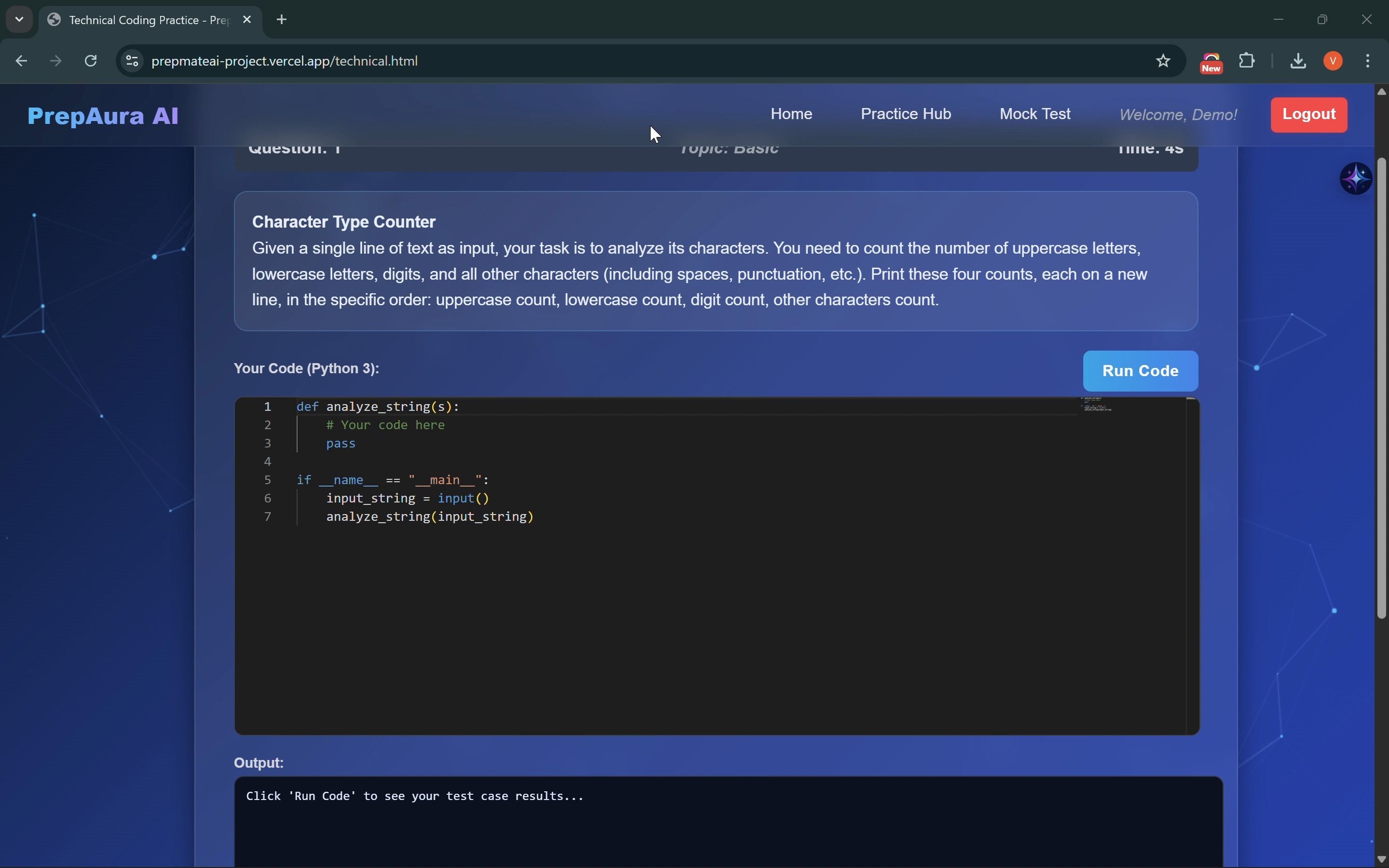
Technical/Coding Round Interface
-
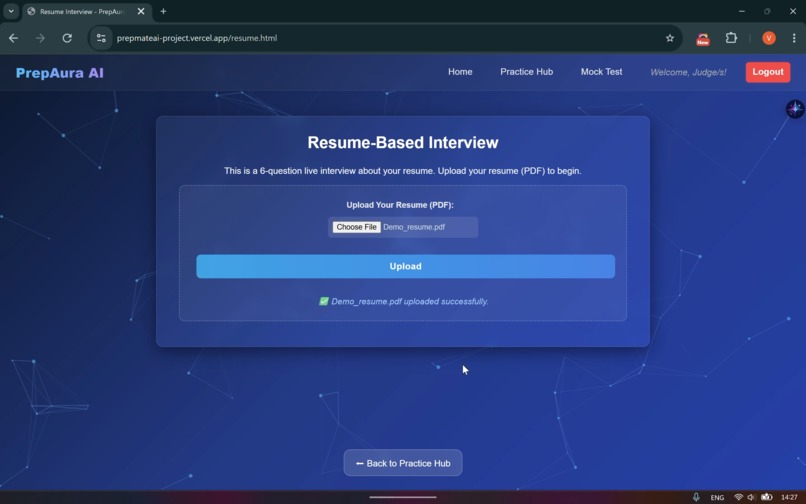
Resume Based Interview Round Interface
-
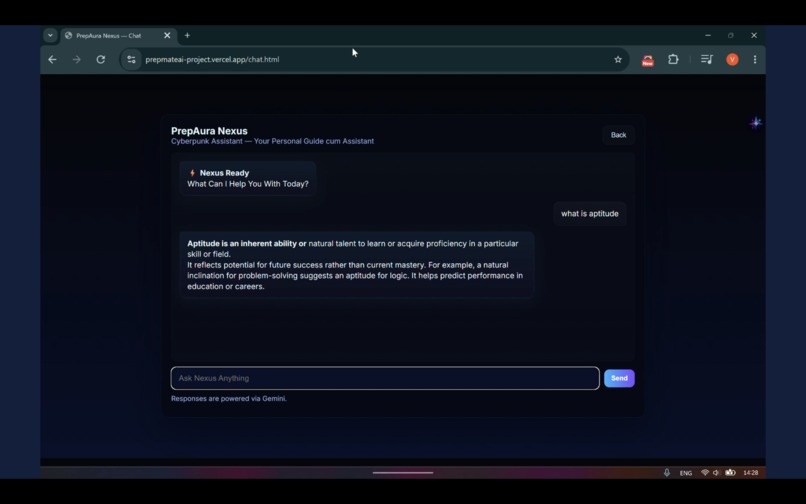
Nexus Chatbot Interface
-

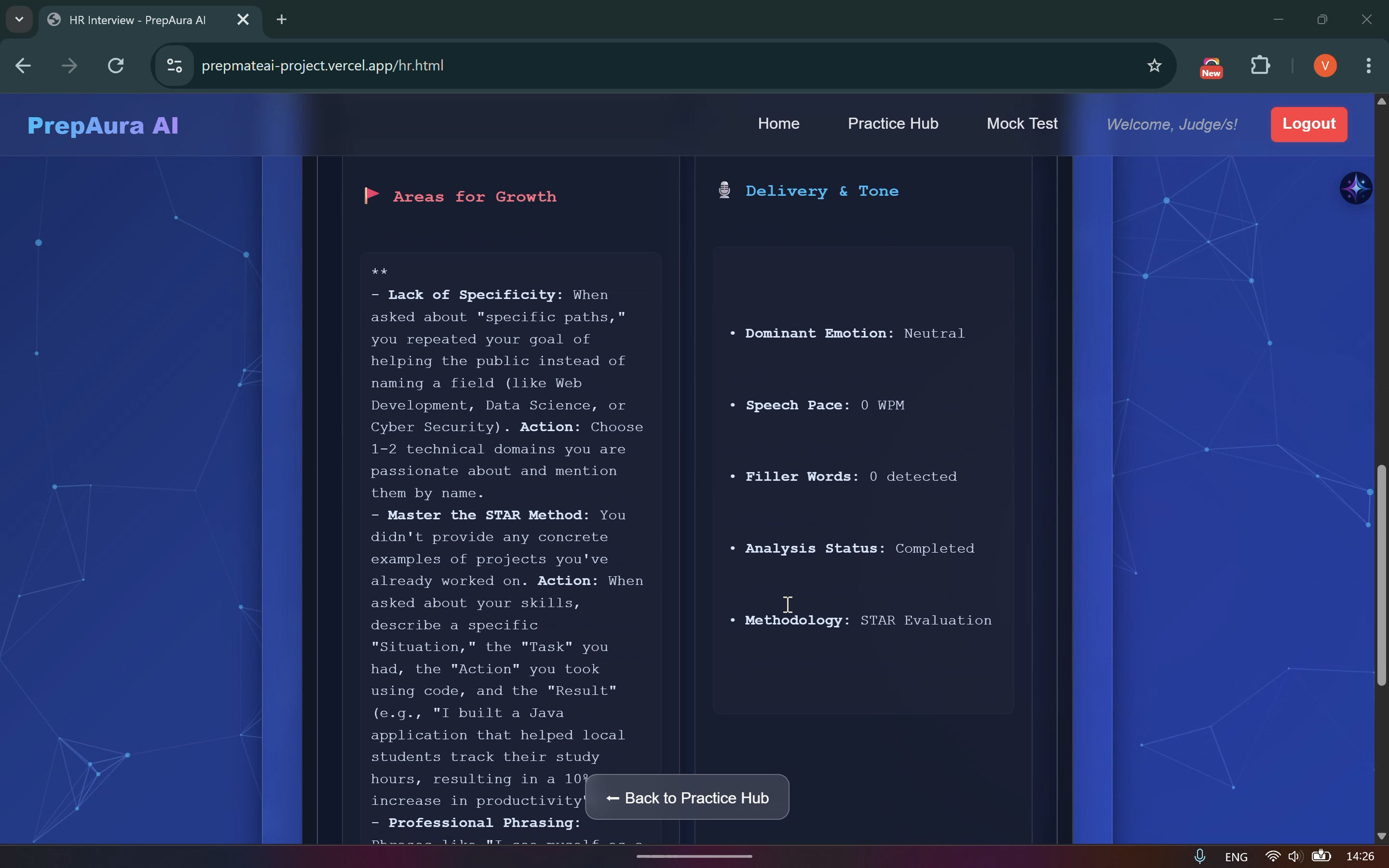
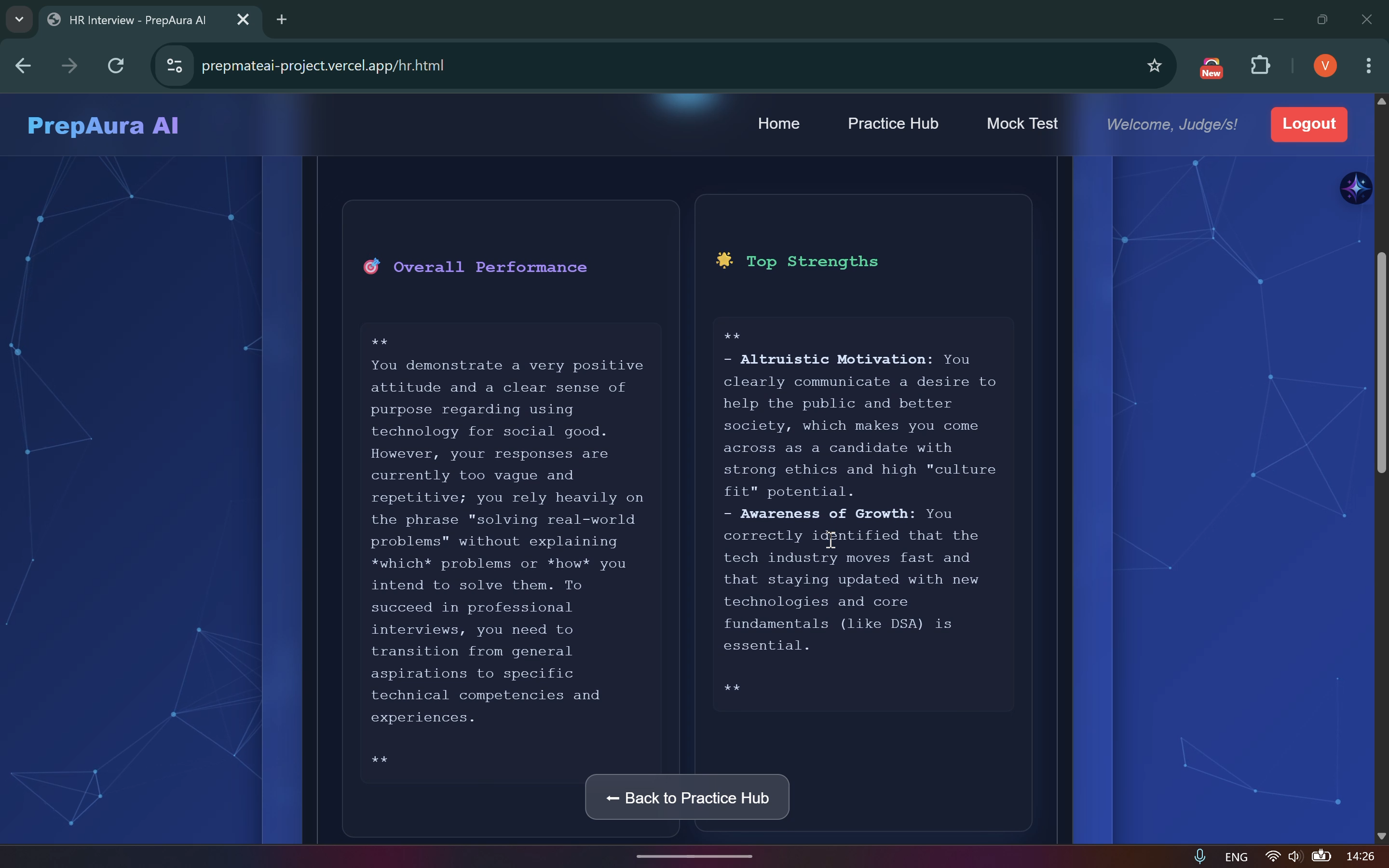
Feedback Report downloaded directly from PrepAura Download Report function
-
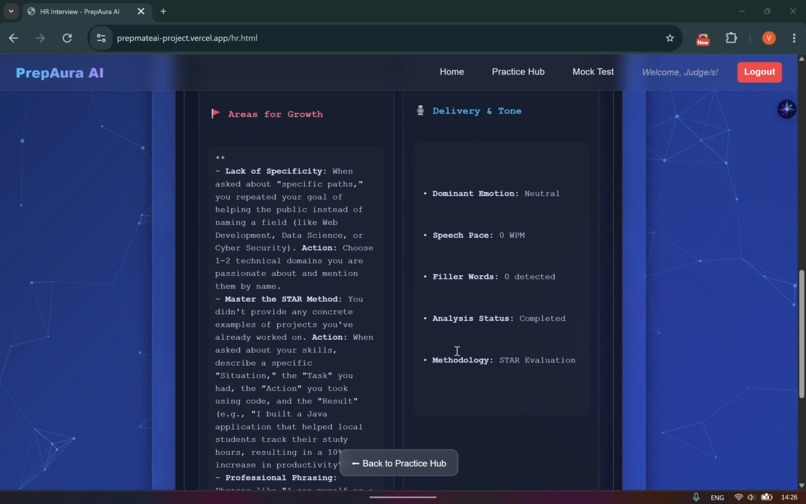
Aptitude Feedback Report-2
-
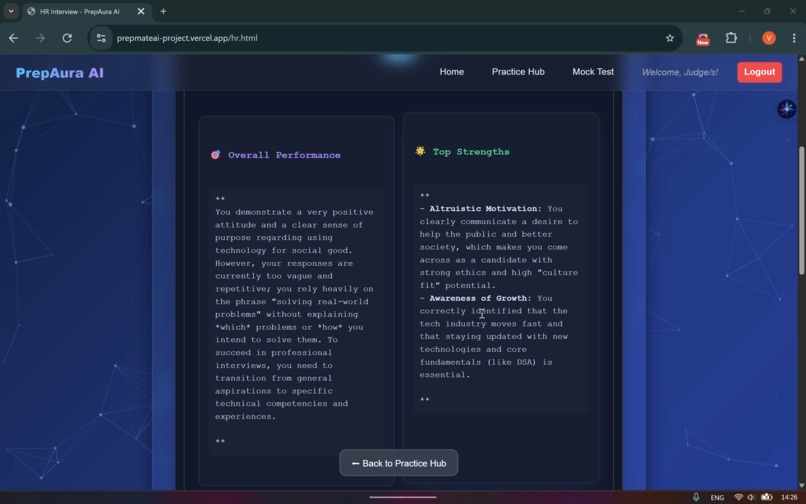
Aptitude Feedback Report

Inspiration
The journey from a student to a professional is rarely a straight line; it is a high-stakes obstacle course. For many Computer Science and BCA students, the dream of a top-tier tech job often stalls at the very first gate: the Aptitude and Coding rounds. These initial technical screenings are designed to filter out thousands, and without the right practice, they can be a source of immense anxiety.
I was inspired to build PrepAura AI to democratize elite-level interview coaching. I wanted to create a platform that doesn't just test knowledge, but masters the entire pipeline—from the logic of a quantitative problem to the syntax of a complex algorithm, and finally, the confidence of a face-to-face HR round. By providing a 360-degree "multimodal mirror," PrepAura AI helps students fail safely in a simulated environment so they can succeed decisively in the real world.
How I Built It
PrepAura AI is built on a robust, multimodal stack designed to handle text, audio, and visual data simultaneously:
The Brain (Gemini 3) : I utilized Gemini 2.5 Flash for rapid question generation and Gemini 3 Flash for the "Final Report" for its deep thinking. The report uses Long-form Thinking configurations to cross-analyze performance data from multiple rounds to provide deep, actionable insights.
The Voice Pipeline: Audio is captured as .webm, converted to .wav via FFmpeg, and transcribed using AssemblyAI. I implemented custom logic to calculate Words Per Minute (WPM) and detect filler words like "um," "like," and "so".
The Visual Hub: Using the user’s webcam, the system performs Facial Expression Analysis, tracking emotional percentages (Neutral, Happy, Surprised) to assess rapport and confidence during live interview simulations.
The Coding & Aptitude Engine: A live IDE integrated with the Judge0 API allows for real-time execution of code against dynamic test cases. Gemini 3 ensures that aptitude questions are mathematically rigorous and formatted for clarity.
The Backend: A Flask server managed by SQLAlchemy and PostgreSQL handles user sessions, interview history, and proctoring logs.
The Hybrid Architecture & Resource Management
To ensure a high-uptime, production-ready experience within the constraints of the Gemini free tier, I architected a Hybrid Intelligence Model:
Why AssemblyAI over Gemini Live : While Gemini Live offers impressive multimodal capabilities, the Requests Per Day (RPD) limits in the free tier posed a significant bottleneck for a high-traffic interview simulation.
The Solution: I offloaded the heavy lifting of speech-to-text to AssemblyAI. This hybrid approach allowed me to reserve Gemini’s precious RPD for high-value reasoning tasks—like behavioral analysis and the final debrief—while maintaining lightning-fast transcription and speech metric calculations without hitting rate limits.
In the same way I used Gemini 2.5 Flash for question generation and solution generation to save precious RPD limits in free tier and used Gemini 3 Flash for report generation which needs deep thinking, thanks to Gemini 3.
What I Learned
Building this project taught me the complexity of Multimodal Fusion. I learned how to synchronize disparate data streams—transcription text, facial emotion arrays, and audio duration—into a single, coherent feedback loop. I also gained deep experience in prompt engineering, specifically ensuring Gemini returns strictly formatted JSON objects for seamless frontend integration.
Challenges I Faced
Minimizing LLM Latency with Pre-fetching : One of the biggest hurdles was the 2–3 second "generation gap" when fetching AI-generated questions. To prevent the user from staring at a loading spinner between every question, I implemented a Background Pre-fetching System. In the Aptitude round, while the user is solving the current question (Q1), the system immediately initiates an asynchronous promise to fetch the next question (Q2) in the background. This "Fast Path" logic ensures that when the user clicks 'Next,' the content is often already waiting in the local state, providing a seamless, buffer-free experience.
State Management in Interviews: Keeping track of the conversation history for Managerial and HR rounds was difficult. I solved this by implementing a structured conversation_history JSON object that passes between the Flask backend and Gemini’s chat session.
Real-time Transcription Polling: Ensuring the UI didn't hang while waiting for AssemblyAI to finish transcribing was a hurdle. I implemented a robust polling mechanism with a 60-second timeout to handle varying audio lengths.
Cross-Domain Security: Configuring CORS and SameSite cookie attributes for the production environment on Render/Vercel was essential to allow secure user login across different domains.
Built With
- assemblyai
- flask
- flaskbcrypt
- flasklogin
- gemini
- judge0api
- pdfplumber
- postgresql
- python
- render
- vercel


Log in or sign up for Devpost to join the conversation.