-
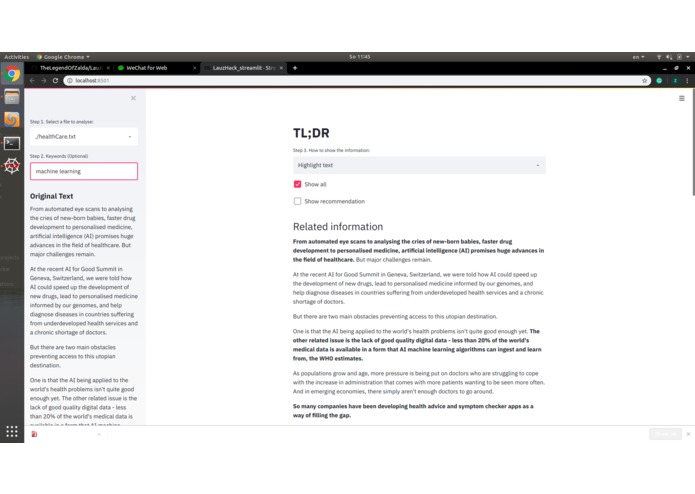
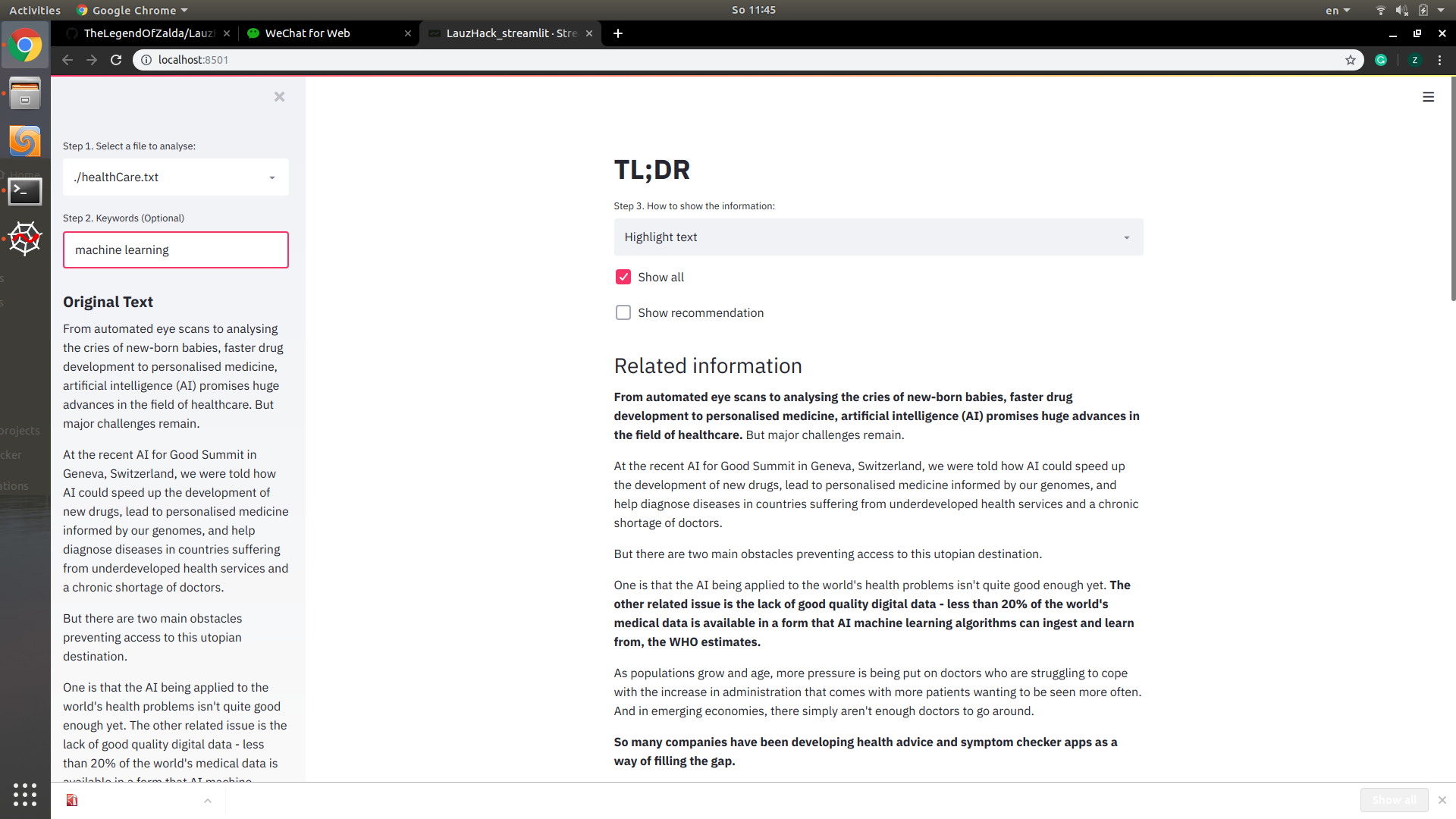
Highlight sentences
-
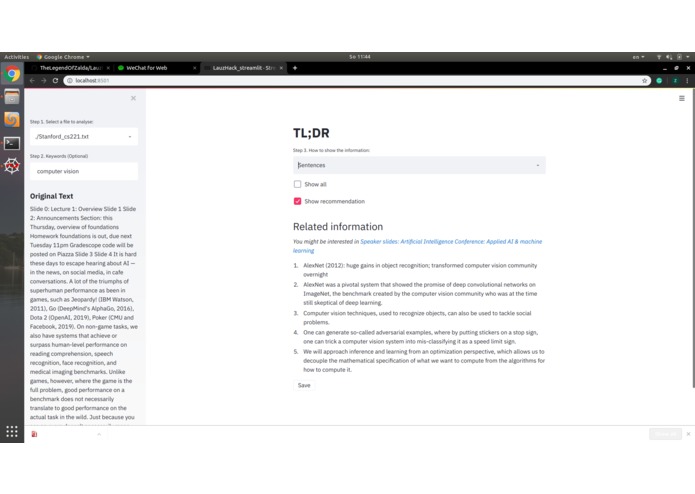
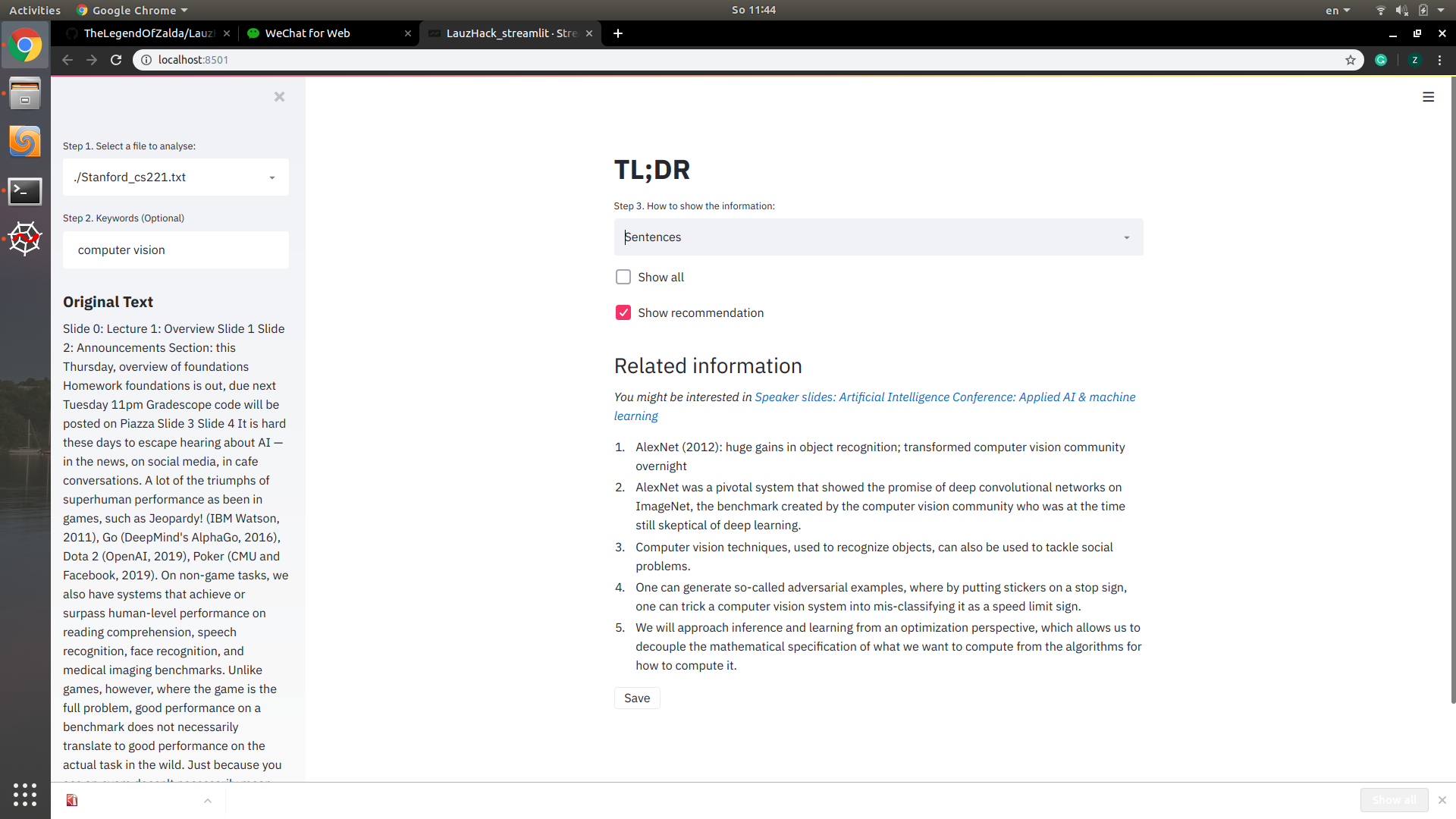
Extract sentences
Inspiration
Information is exploding. Time is money. We love saving money.
We want to summarize long textual information, and often it is not summarizable. Instead, we should extract key phrases only, like what we do for preparing an exam: highlighting what we think are important.
we TL;DR everything.
What it does
Given a txt or pdf file, it reads the content and extracts or highlights sentences related to the given keywords. If no keywords are given, it automatically extracts topics and gives key sentences. The results are shown in the application and can be saved to a txt file with markdown syntax that highlights the extracted information.
It also gives an interesting link related to the context, for some curious and diligent user, as additional materials.
How I built it
We first process the textual information and extract the main topics of the text using LDA. Then we compute for each sentence its score which indicates how much it is related to the keywords, or the topics if the keywords are not given. In this step, we use the word2vec model GoogleNews-vectors-negative300 in order to compute the similarity. We also google a related article or website that is related to the topics and recommend this as additional reading. Finally, we build a UI for interacting with users, let user to choose text or pdf file to be processed, the way to show the key sentences, keywords etc.
Challenges I ran into
- How to define a proper problem: under what situation we want to use it
- How do we extract key sentences
- Building an UI, none of the team members did this before
- Find a proper model that can run the application in real time
- Network delay
- Websites detecting if we are robots. We are indeed.
Accomplishments that I'm proud of
It works! It works well!
We learned and used many new libraries and techniques during the challenge.
What I learned
- Use a Word2Vec model
- Building an UI
- Extract URL and title with google using python
What's next for Prepare your exam in 2 minutes
- Get over the network delay and robot detection
- Add user features for targeted content extraction
Acknowledgement
This is a challenge given by AXA during Lauzhack 2019. Thank to all organizers of this incredible event and thank to AXA who gave us this opportunity and complete freedom for doing this project.
Built With
- gensim
- natural-language-processing
- nltk
- python
- streamlit

Log in or sign up for Devpost to join the conversation.