Inspiration
We kept watching the same failure mode in multi-agent coding setups: an agent writes a plan that was correct five minutes ago and is wrong now. A teammate lands a hotfix, another agent renames a type, an API contract shifts, and the first agent keeps generating code against a repo state that no longer exists. By the time the diff hits review, the cost is already paid. failing tests, broken integrations, and a confused reviewer trying to reconstruct who knew what when.
Git answers "what changed in the bytes?" Linters answer "is this file syntactically OK?" Neither answers the question that actually breaks parallel agent work: "is this agent's plan still safe to execute against the current repo?" That gap is what we built Nexus to fill.
What it does
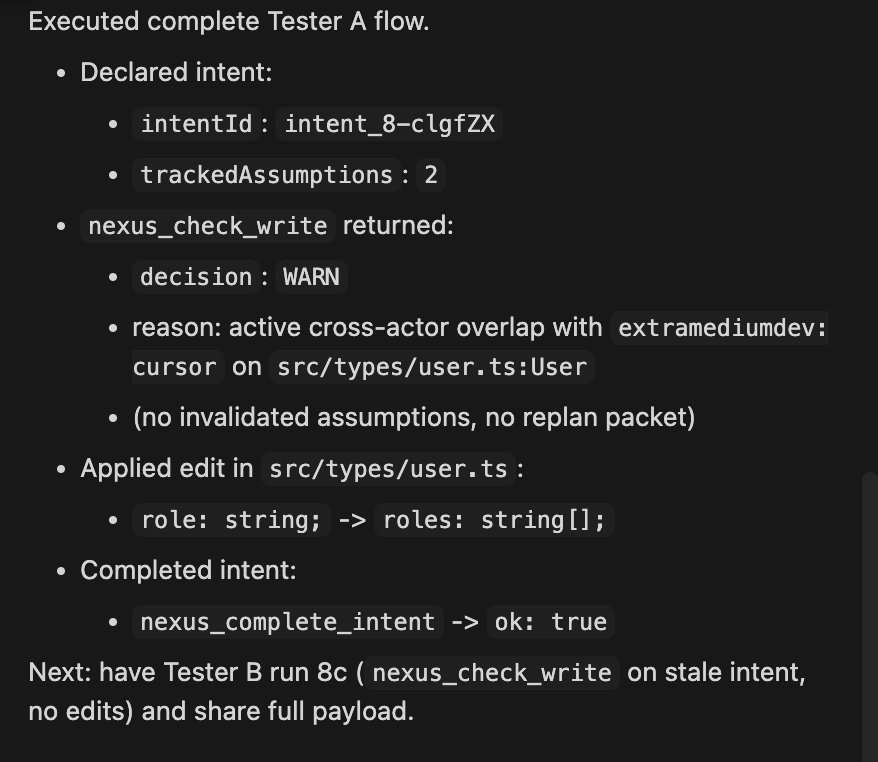
Nexus is a pre-write safety layer that sits between AI coding agents and the codebase via the Model Context Protocol. Before any agent touches a file, it declares the plan it's about to execute. We extract the concrete claims that plan depends on, function shapes, type structures, route contracts, test expectations — and pin each one to a deterministic hash of the actual code it relies on. Every later edit by any actor (human or agent) is diffed back against those pinned hashes, so a stale plan is detected the moment reality drifts away from it.
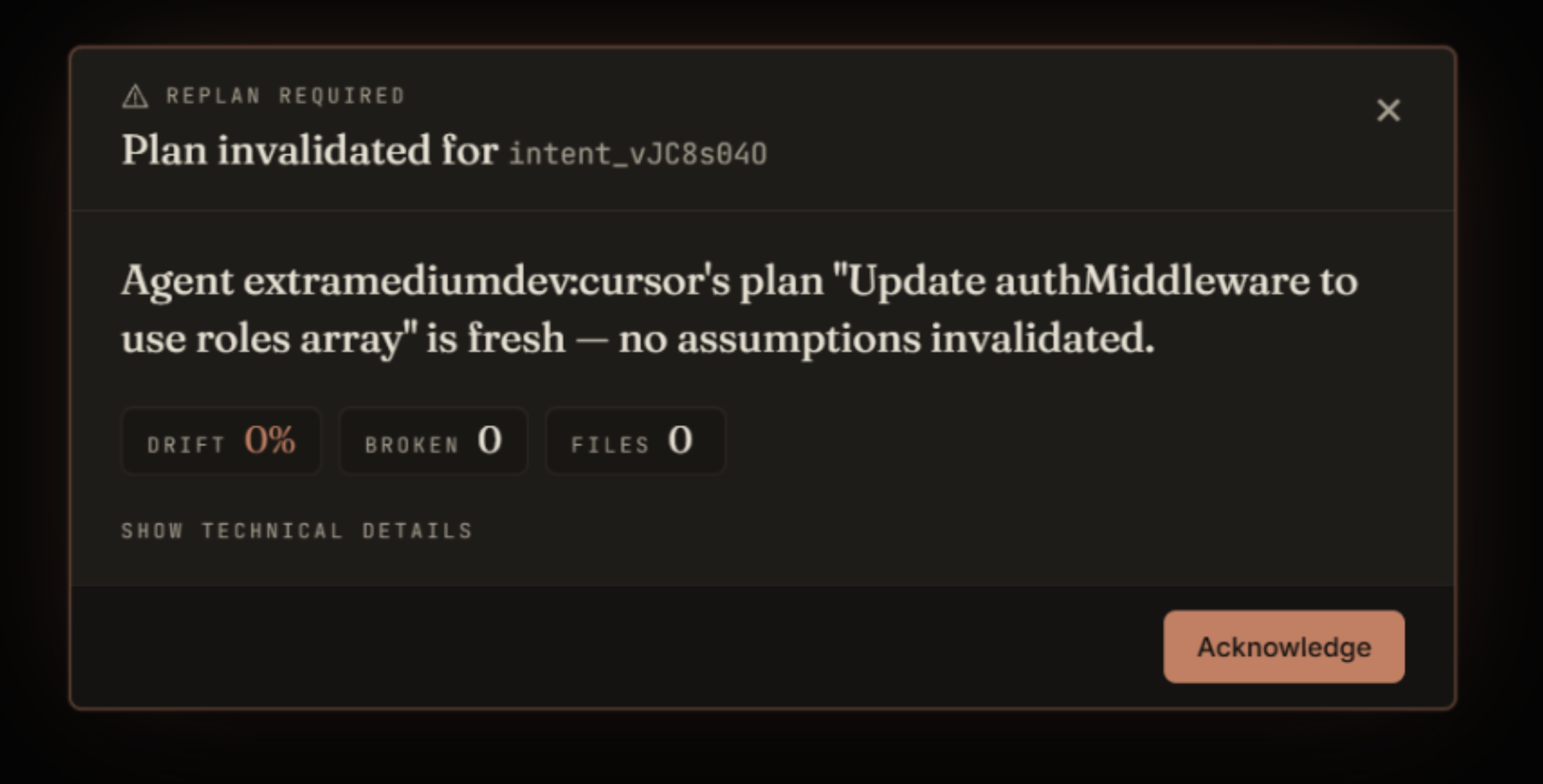
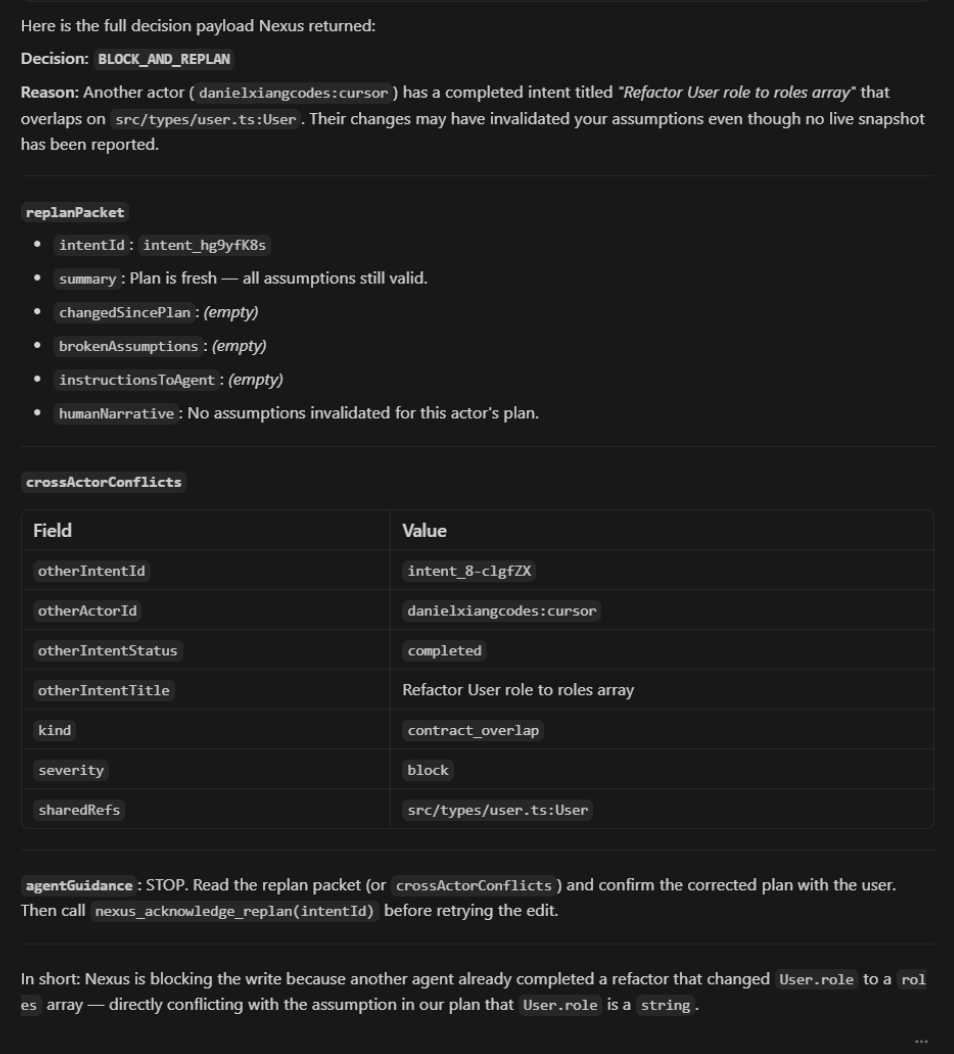
When the agent goes to write, Nexus runs a check that returns one of four decisions: allow, warn, block-and-replan, or escalate to a human. A block ships back a structured replan packet, what broke, who broke it, the before/after of the changed surface, and a focused instruction the agent can act on directly. Two metrics drive the live dashboard: the Assumption Governance Index (AGI), which scores how stale each plan is, and the Assumption Diffusion Index (ADI), which scores how widely the drift has spread across files in flight.
How we built it
The core is a TypeScript service with five collaborating layers: a static-analysis scanner that walks the repo through the compiler API and emits a typed surface snapshot; a deterministic hasher that turns each surface element into a stable, order-independent fingerprint; an invalidation engine that re-checks every tracked claim after each scan; a policy layer that rolls per-claim severity into a single safety verdict; and a replan generator that composes the human-readable narrative plus the machine-actionable instruction. State lives in a per-project engine database with a system database on top for auth and multi-tenancy; live events stream over WebSockets to a React + React Flow "Mission Control" dashboard.
The agent-facing surface is an MCP server published to npm, so any MCP-capable client (Cursor, Claude Desktop, Cline) gets the full declare-intent / check-write / acknowledge-replan / complete-intent loop with no glue code. A small LLM extractor (Gemma) optionally turns plain-English plans into structured claims, but every claim is re-grounded against the deterministic scanner — the LLM never gets the last word on safety. We also shipped a Fetch.ai uAgent oracle on Agentverse that speaks the Chat Protocol, plus a stale-plan demo agent, to prove the same loop works across runtimes.
The Assumption Governance Index aggregates per-claim drift into a single score from 0 to 1, weighted by consequence and decayed by time so old plans do not dominate the dashboard:
$$ \mathrm{AGI} = \frac{\sum_i m_i w_i C_i(t)}{\sum_i w_i C_i(t)} $$
where:
- m_i is one of 0, 0.5, or 1, representing the migration state of claim i: valid, unknown, or invalidated.
- w_i is the consequence weight of claim i, from low to critical, scaled exponentially.
- C_i(t) = exp(-lambda t) is the time-decay term, using a 30-minute half-life.
Per-intent AGI is rolled up to a project-level score by re-weighting each intent by its worst-severity claim.
ADI is the simpler companion metric: the fraction of in-flight files that contain at least one invalidated claim.
Together, AGI and ADI let a reviewer quickly see whether drift is deep, meaning high AGI, or wide, meaning high ADI.
Challenges
The hardest part was making the safety claim itself non-speculative. It's easy to ship a demo where an LLM "reads the diff" and announces "looks safe" — and equally easy for that to silently produce false greens. We forced the validation step to be deterministic: hash a normalized signature, hash a sorted type shape, compare to the pinned baseline. The LLM can suggest claims, but a green light is always backed by a hash equality, not a vibe.
The second challenge was multi-actor realism. A single laptop can't show two agents racing each other, so we built scenario overlays for the demo path and a real two-laptop MCP flow where each engineer's editor auto-registers as a distinct actor and the dashboard shows cross-actor symbol conflicts even when the on-disk snapshot hasn't drifted yet. Getting that conflict layer right — completed-intent overlap, in-flight-intent overlap, and on-disk drift, all fed into the same decision — took several iterations and a dedicated cross-actor integration test.
What we learned
The ceiling on AI coding agents isn't the model — it's the agent's world model. Giving an agent more context only helps if that context is stateful, checkable, and invalidatable. Once you treat each plan as a contract over a small set of concrete code surfaces, "is this plan still safe?" stops being a judgment call and becomes a hash comparison. That single shift — from "let the agent re-read everything" to "pin what the agent assumed and watch those pins" — is what makes parallel agent work feel sane instead of chaotic.
We also learned that the right output of a safety layer isn't a yes/no — it's a replan. Telling an agent "blocked" creates loops. Telling an agent "blocked, here's what changed, here's who changed it, here's the instruction that fixes it" closes the loop in a single retry. Meta-cognition for coding agents turns out to be deeply mechanical: a scanner, a hasher, a diff, a policy, and a packet.
Built With
- agentverse-chat-protocol
- asi:one
- autoprefixer
- better-sqlite3
- clsx
- fastify
- fetch.ai-uagents
- github-oauth
- google-gemma-2-(via-google-ai-studio)
- httpx
- jsdom
- model-context-protocol-sdk
- nanoid
- node.js
- playwright
- pnpm-workspaces
- postcss
- postgresql-(pg)
- pydantic
- pytest
- python-3.10+
- python-dotenv
- react-18
- react-flow-(@xyflow/react)
- render
- tailwind-css
- testing-library
- ts-morph
- tsx
- typescript
- vite
- vitest
- websocket-(ws-/-@fastify/websocket)
- zod

Log in or sign up for Devpost to join the conversation.