-
-
Sprint Health
-
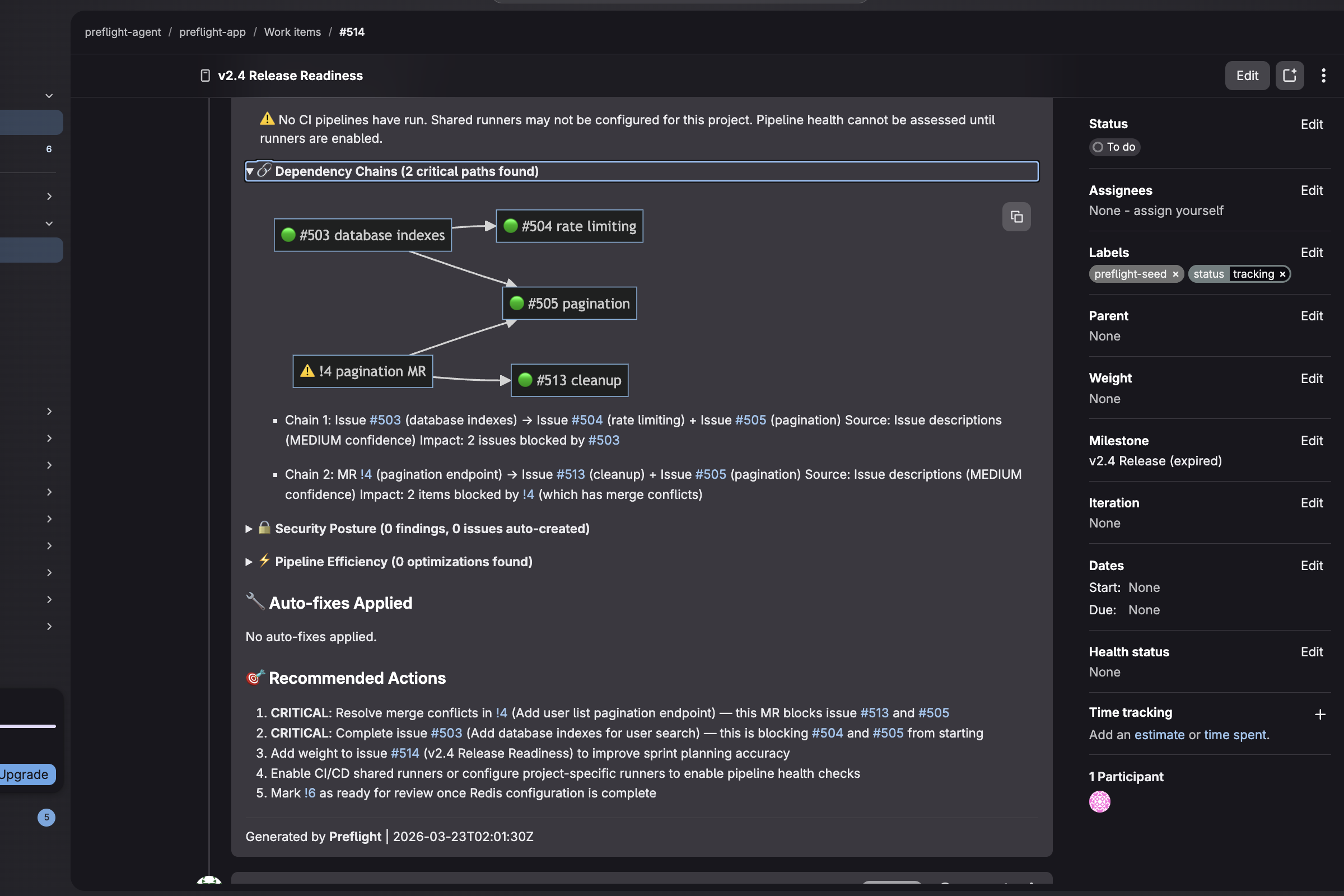
Dependency Mermaid Diagram
-
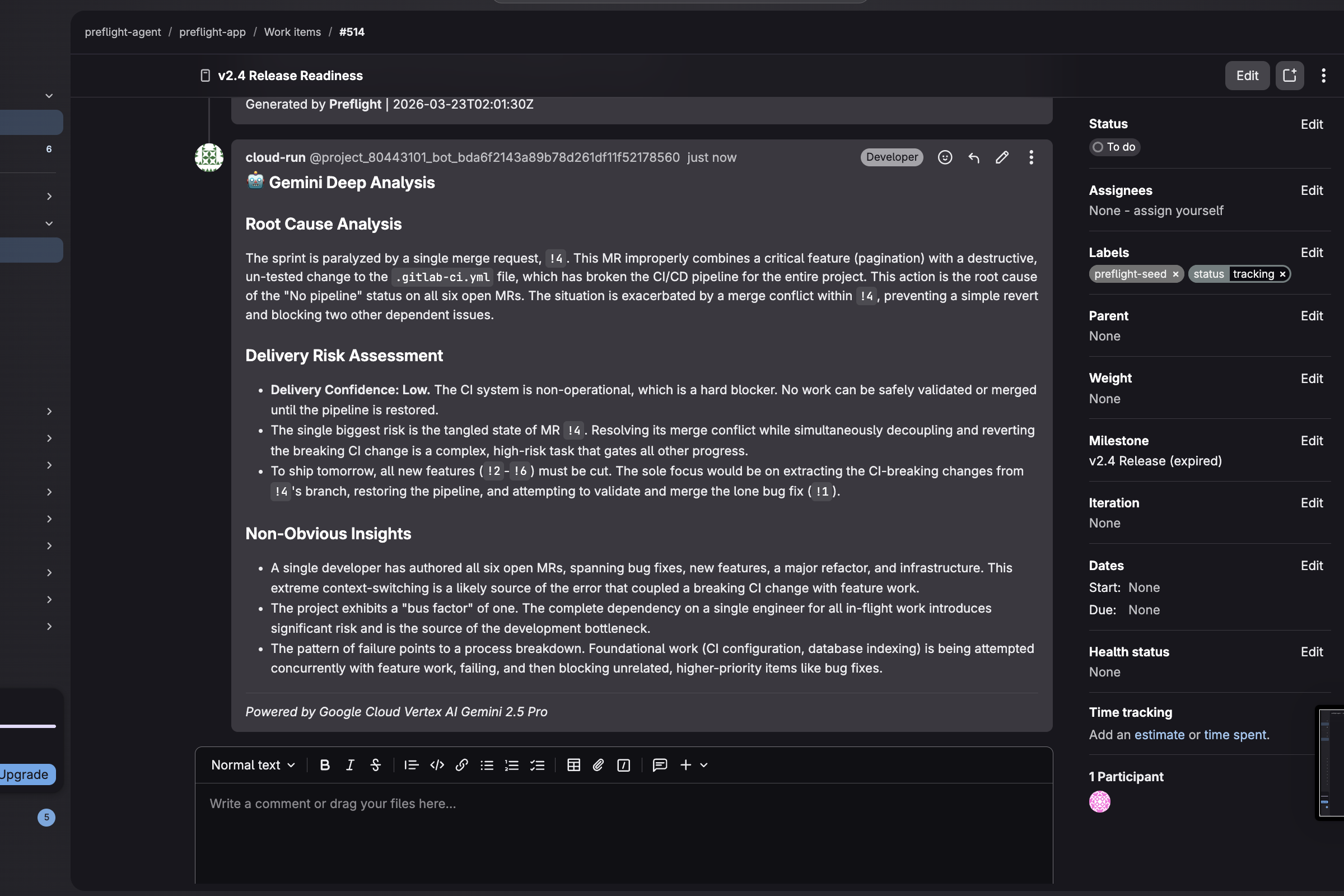
Gemini Deep Analysis
Inspiration
Organizations take 60 days on average to patch critical CVEs. Attackers exploit them in 4.5 days. That 55-day gap is where breaches live — and 60% of security incidents involve a vulnerability where a patch was already available.
Meanwhile, engineering leads spend 1–2 hours every sprint manually checking labels, pipelines, dependency chains, and unlinked vulnerabilities. As AI accelerates code output, the volume of MRs, issues, and scan results grows faster than humans can track.
Chat won't solve this. Teams need agents that react to triggers and take action.
What it does
A single @mention on a GitLab issue triggers a three-agent chain that audits every issue (labels, weight, staleness, assignees), every MR (pipeline status, unresolved threads, draft flags), open vulnerabilities, dependency chains, and .gitlab-ci.yml configuration — then takes corrective action.
The Fix Agent auto-labels issues where keyword-match confidence is HIGH, posting an audit trail comment on every change. At MEDIUM confidence, it recommends only — never auto-applies. It creates remediation tickets for unlinked vulnerabilities with no human sign-off needed.
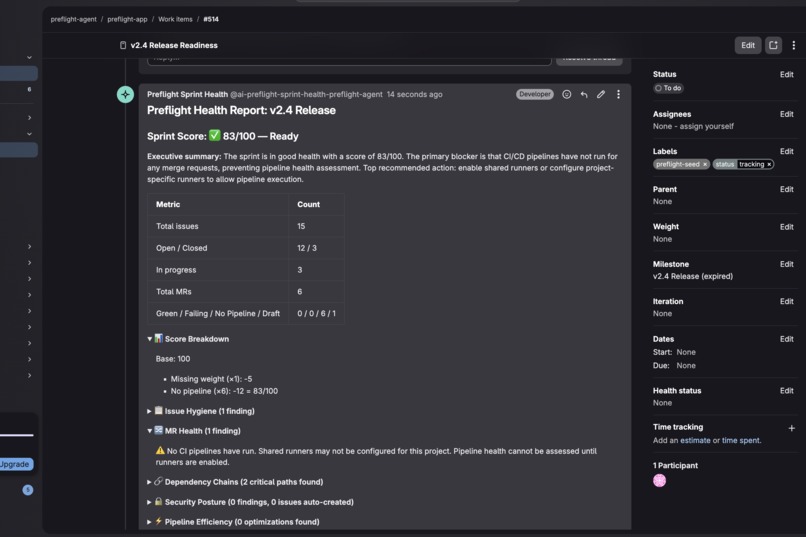
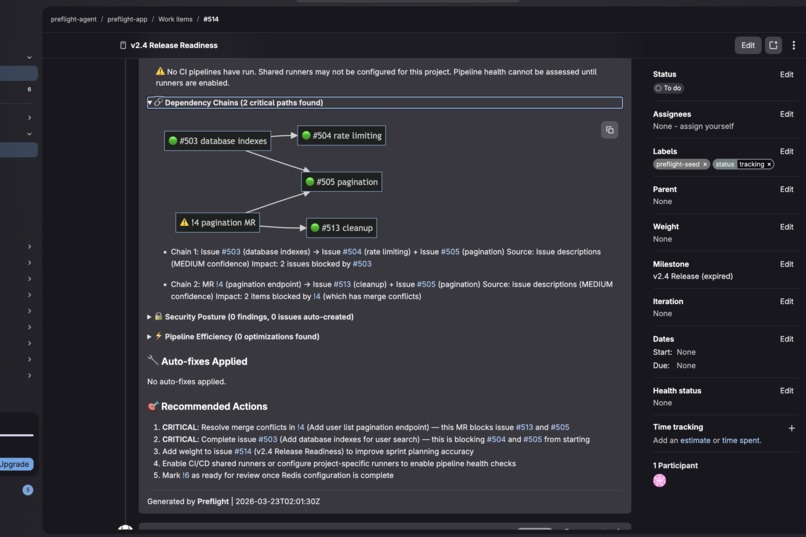
The Report Agent posts a sprint health score on a transparent 0–100 rubric with pre/post comparison — "Pre-Preflight: 74 → Post-Preflight: 89 (+15 recovered)" — and a Mermaid dependency diagram exposing hidden blockers no single issue view would reveal.
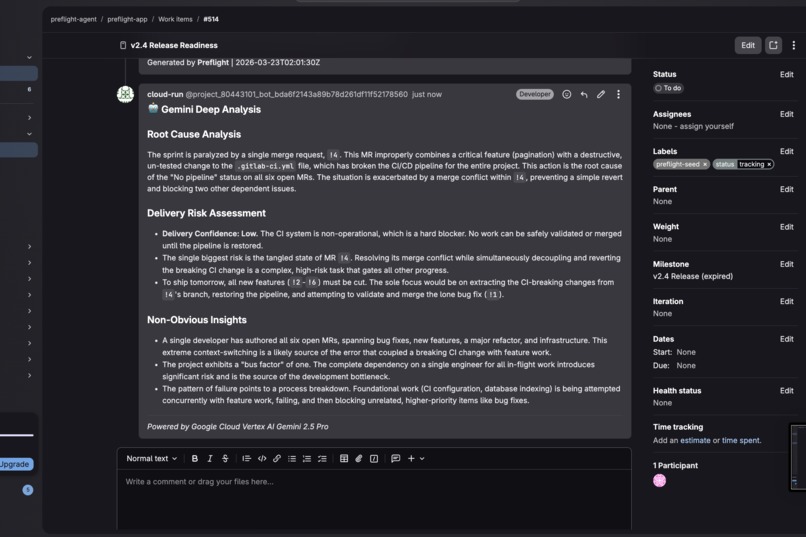
When that report lands, a GitLab webhook fires to Google Cloud Run, which collects raw MR diffs and pipeline logs and sends them to Vertex AI Gemini 2.5 Pro. Gemini finds what per-item analysis misses: shared root causes, delivery risk assessments, and systemic patterns — posted automatically as a follow-up comment. Zero human intervention from trigger to enriched report.
How we built it
Three Claude Sonnet 4 agents on GitLab Duo's Custom Flow platform, each scoped by least-privilege at the tool-registration level:
- Audit Agent — Read-only, 19 tools, 30+ API calls per run
- Fix Agent — Write-capable, 10 tools, HIGH confidence actions only
- Report Agent — Comment-only, 5 tools
Each agent is self-sufficient — it queries GitLab independently rather than consuming the previous agent's output. Inter-agent context passing proved unreliable under real conditions. Self-sufficiency costs extra API calls but eliminates the most common multi-agent failure mode: one agent's bad output corrupting the next.
The Gemini layer is event-driven: a GitLab Note webhook hits a Cloud Run FastAPI service, which collects full MR diffs and pipeline logs and sends the combined context to Gemini 2.5 Pro's 1M-token window. Claude handles structured per-item tool calling and audit trails. Gemini handles cross-cutting pattern recognition across the full project context. Each model doing what it's actually best at — not one model forced to do both.
270+ automated tests validate the entire pipeline with zero real API calls.
Challenges we ran into
Our first live run was humbling. Agents hallucinated issue numbers with complete confidence — we learned that "be accurate" does nothing but "NEVER fabricate data" works. Anti-hallucination rules at the top of every prompt became non-negotiable.
The 64KB Flow YAML size limit forced aggressive prompt compression, which actually improved agent behavior: shorter instructions, fewer decision trees, better compliance. LLMs don't reliably follow multi-step fallback sequences, so we replaced branching logic with flat, direct commands.
Inter-agent context passing was unreliable enough that we redesigned each agent to fetch its own data independently. Shared runners were disabled in the hackathon namespace, which broke our pipeline scoring until we redesigned the rubric to handle the "never ran" case.
And Gemini was almost too good: it identified our demo seed data as synthetic and critiqued it in its analysis. We tuned the prompt to focus on actionable engineering insights regardless of data source.
Accomplishments that we're proud of
The security boundary model is load-bearing architecture, not decoration. Read-only, write-capable, and comment-only scoping at the tool level prevents cascading failures and gives enterprise teams a trust model they can audit.
The full pipeline — @mention → audit → fix → report → Gemini enrichment — runs with zero human intervention. Pre/post scoring makes the agent's impact quantifiable: not "we found some issues" but "74 → 89, +15 recovered."
CI/CD anti-pattern detection qualifies as a Green Agent: flags missing interruptible: true (~1 min savings), missing rules:changes on test/lint jobs (~3 min savings), and missing cache configs (~2 min savings) — each with a specific YAML fix and estimated compute savings.
The webhook-driven Gemini integration is genuine event-driven architecture — no polling, no cron, no manual triggers. And 270+ tests validate the entire system in seconds with zero real API calls.
What we learned
Multi-agent prompt engineering requires treating each agent as a fault-prone microservice. Security boundaries contain blast radius. Self-sufficiency eliminates coupling. Fallbacks handle the reality that "works on the third try" is the current state of LLM agents.
Short, absolute instructions outperform nuanced decision trees every time. Agents need guardrails, not suggestions.
The dual-model architecture validated our core hypothesis: forcing a single model to handle both per-item tool calling and holistic synthesis produces worse results at both tasks. Route to the model built for the job.
Demo data needs the same engineering rigor as agent logic. The best orchestration in the world looks broken when the seed data doesn't hold up. And shipping beats perfecting — every hour spent on a prompt tweak is an hour not spent proving the system works end-to-end.
What's next for Preflight
Full vulnerability auto-remediation that closes the loop: detect CVE → create ticket → assign owner → link patch → track resolution.
Automatic release gates that block deploys when the health score drops below a configurable threshold — moving Preflight from advisory to enforceable.
Historical trend analysis with sprint-over-sprint health tracking, so teams catch regressions before they compound. Percentage-based scoring that stays meaningful from 10 to 1,000+ issues.
Zero-config milestone detection that triggers audits automatically as deadlines approach — no @mention required.
The long-term vision: enterprise multi-project dashboards with cross-project Gemini analysis, Slack and email alerting, and organization-wide pattern recognition powered by two AI models working in concert.
Built With
- claude-sonnet-4-(anthropic-via-gitlab-duo)
- fastapi
- gemini-2.5-pro
- gitlab-custom-agents
- gitlab-custom-flows
- gitlab-duo-agent-platform
- gitlab-graphql-api
- gitlab-rest-api
- gitlab-webhooks
- google-cloud-run
- google-cloud-vertex-ai
- mermaid.js-(diagram-rendering)
- pydantic
- pytest
- python
- pyyaml


Log in or sign up for Devpost to join the conversation.