-
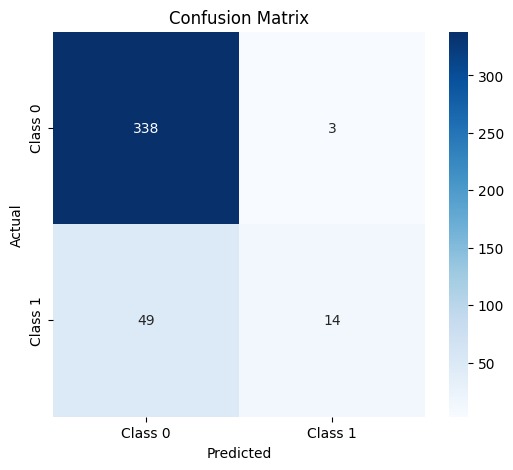
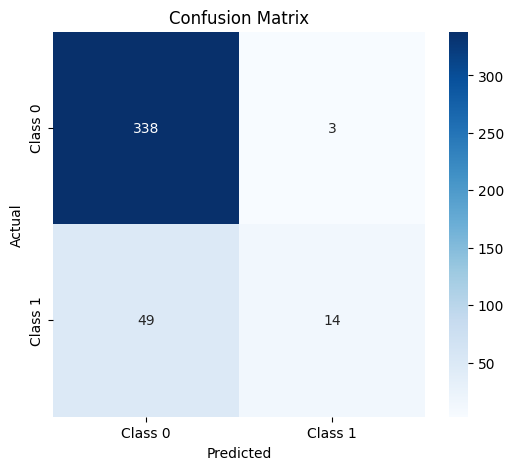
Confusion Matrix
-
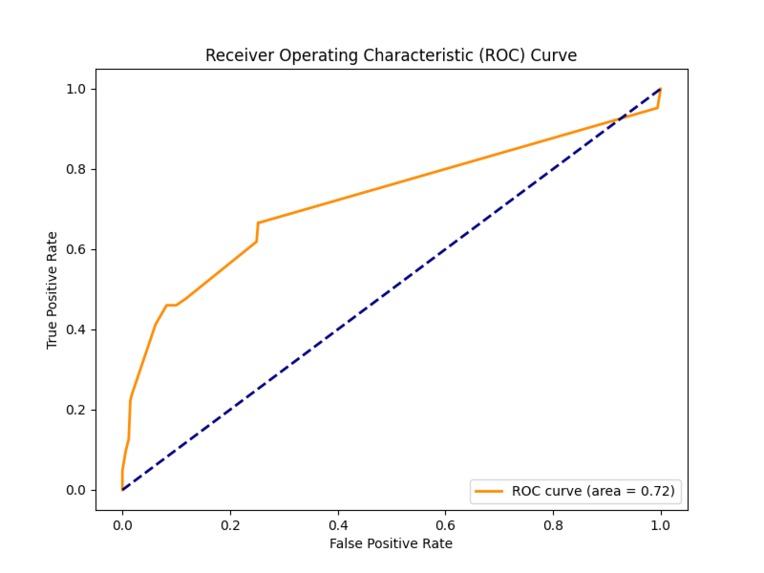
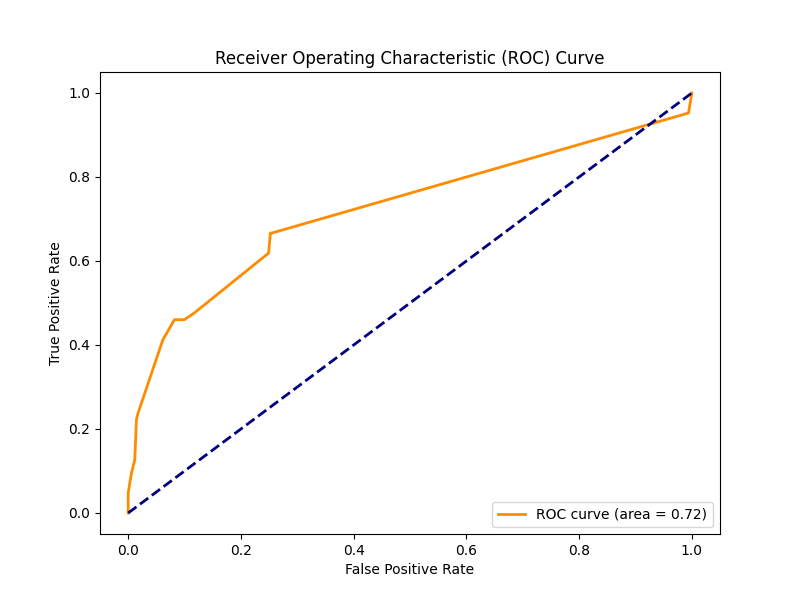
ROC Curve
Inspiration
The inspiration behind this project came from the increasing need to understand customer behavior in real-time. Businesses are constantly looking for ways to optimize marketing strategies, improve customer engagement, and predict potential sales. By analyzing customer data, we can predict behaviors such as purchases, product interests, or even churn, helping businesses make more informed decisions. This project aims to help businesses understand and predict customer actions based on historical data.
What it does
The "Predictive Insights for Customer Behavior" project uses machine learning techniques to analyze customer data and predict their future behavior. We employed a Random Forest classifier to predict customer responses and potential sales. The project processes historical data, including demographics, purchase patterns, and engagement with marketing campaigns, and uses this data to forecast future customer behavior. Additionally, it provides visualizations to showcase the important factors that influence predictions, such as feature importance and confusion matrix.
How we built it
Data Collection and Preprocessing:
- We began with a dataset containing information about customer demographics, activity, and engagement with marketing campaigns.
- We handled missing values, encoded categorical features, and normalized numerical data to make it ready for modeling.
- We began with a dataset containing information about customer demographics, activity, and engagement with marketing campaigns.
Modeling:
- We implemented the Random Forest classifier, which is well-suited for handling complex relationships in data. It provided insights into feature importance, which helped us understand which variables were most influential in predicting customer behavior.
- We split the data into training and testing sets, trained the model, and evaluated its performance based on accuracy, F1-score, and confusion matrix.
Visualizations:
- Several visualizations were created, including a confusion matrix to evaluate the model's predictions, and bar plots to show feature importance.
Deployment:
- We exported the trained model and the test data predictions to CSV files for easy integration with business applications.
Challenges we ran into
Data Quality:
One of the biggest challenges was dealing with missing values and encoding categorical features. Some categories had a large number of unique values, which made the preprocessing complex.Model Overfitting:
Initially, the model was overfitting to the training data, leading to poor generalization on the test set. We addressed this by tuning hyperparameters and using cross-validation techniques.Balancing the Data:
The dataset was imbalanced, with one class being more frequent than the other. We used techniques like class weighting and resampling to address this imbalance and improve model performance.
Accomplishments that we're proud of
Accurate Predictions:
The Random Forest model achieved an accuracy of 87%, providing reliable predictions of customer behavior. The model was able to identify important features, like income and activity level, which helped explain the predictions.Visual Insights:
We were able to generate meaningful visualizations, such as the feature importance graph and confusion matrix, that provide both a quantitative and visual understanding of model performance.End-to-End Solution:
From data preprocessing to model training, evaluation, and deployment, we successfully built an end-to-end predictive analytics solution. This solution can be directly integrated into business applications.
What we learned
Feature Importance:
The Random Forest model helped us understand which factors were most important in predicting customer behavior. This was an important takeaway for improving business strategies.Model Evaluation:
We learned how to evaluate model performance using metrics like accuracy, precision, recall, F1-score, and the confusion matrix. These metrics are essential for understanding model effectiveness, especially in business-critical applications.Data Preprocessing and Cleaning:
The project gave us a deeper understanding of data preprocessing, particularly dealing with missing data, encoding categorical features, and normalizing numerical features. This is crucial for any machine learning project.
What's next for Predictive Insights for Customer Behavior
Model Improvement:
We plan to experiment with other advanced models such as Gradient Boosting Machines (GBM) or Neural Networks to further improve prediction accuracy.Real-Time Data Integration:
We aim to integrate the model with real-time customer data to provide on-the-fly predictions for businesses.Expanding Feature Set:
The current model uses basic demographic and transactional data, but we plan to include more sophisticated features such as customer sentiment analysis (from reviews or social media data).Deployment as a Service:
In the future, we envision deploying the model as an API service so businesses can easily integrate it into their systems and make predictions on new customer data instantly.
Built With
- google.colab
- matplotlib
- python
- sklearn

Log in or sign up for Devpost to join the conversation.