-
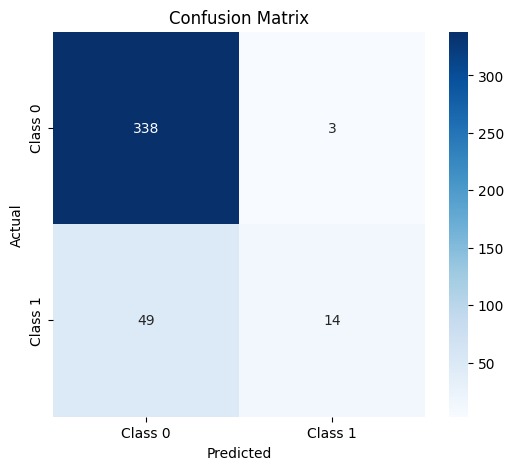
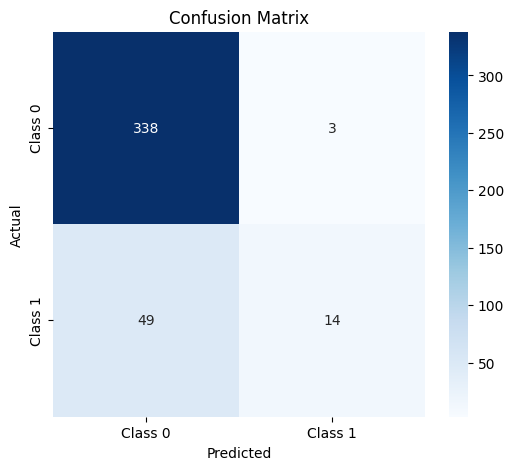
Confusion Matrix
-
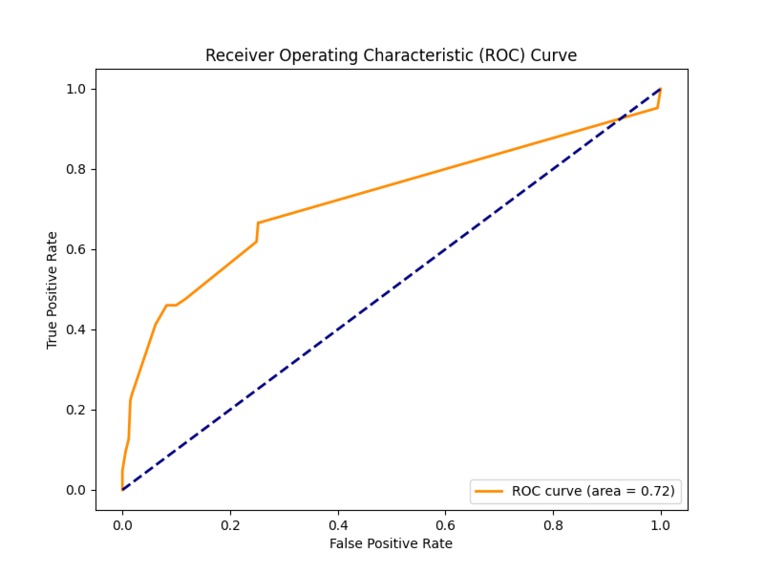
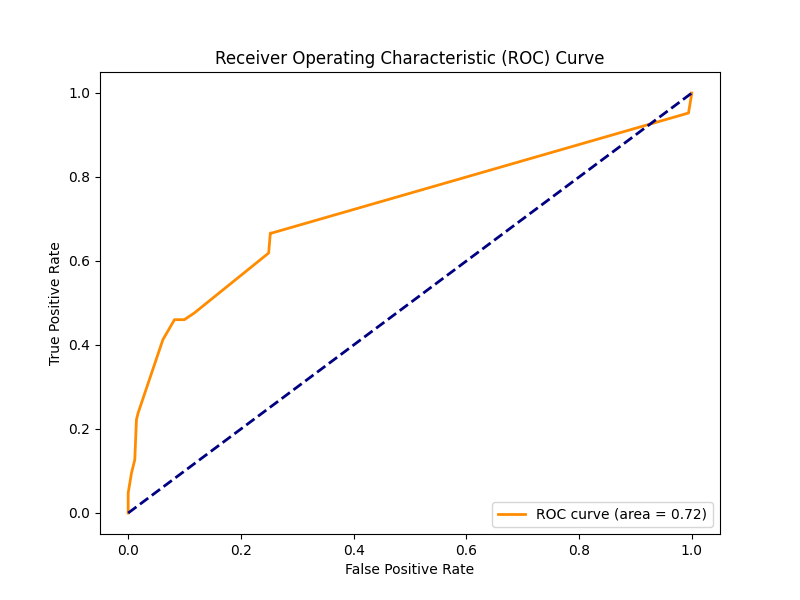
ROC Curve
PredictIt: Transforming Data into Business Insights with Predictive Power
About the Project
PredictIt is a machine learning project focused on developing a predictive model using customer data to forecast their behaviors, specifically targeting customer segmentation and prediction of their future actions. The project leverages classification techniques, primarily using a Random Forest Classifier, to analyze data such as annual income, kids count, and spending habits to predict customer behavior.
Inspiration
The inspiration behind this project came from the growing importance of predictive analytics in business decision-making. In industries ranging from retail to e-commerce, understanding customer behavior and predicting future trends are key to staying ahead of the competition. I wanted to apply machine learning techniques to solve a real-world problem, especially focusing on predicting customer actions to guide marketing and business strategies.
What I Learned
- Data Preprocessing: I gained experience in cleaning and preparing data, especially dealing with missing values, encoding categorical variables, and scaling features for model optimization.
- Modeling: I learned how to train and tune Random Forest Classifiers and other machine learning models, using performance metrics like accuracy, confusion matrix, and ROC curve to evaluate models.
- Visualization: I improved my skills in visualizing complex data, such as creating heatmaps for confusion matrices, and learned how to plot feature importances to gain insights into the data.
- Evaluation Metrics: I understood the importance of classification evaluation metrics, such as F1-score, precision, recall, and accuracy.
How I Built the Project
- Data Collection: The dataset was collected from a business's customer data logs, containing information such as age, income, spending behavior, and other demographics.
- Data Preprocessing:
- Handled missing values.
- One-hot encoded categorical features.
- Scaled numerical features for better model performance.
- Model Selection: Initially, I started with a Random Forest Classifier due to its ability to handle complex datasets and its robustness against overfitting.
- Model Training and Tuning:
- Split the dataset into training and testing sets (80/20 split).
- Tuned the model using hyperparameters like the number of trees and maximum depth.
- Used cross-validation to ensure the model's generalizability.
- Prediction and Evaluation: The model was evaluated using various metrics like accuracy, precision, recall, and F1-score.
- Visualization: Used tools like Seaborn and Matplotlib to create insightful visualizations such as:
- Confusion Matrix Heatmaps
- ROC Curve
- Feature Importance Plots
Challenges I Faced
- Data Quality Issues: One of the main challenges was dealing with inconsistent and missing data. I had to carefully handle these issues to ensure that the model could train effectively.
- Class Imbalance: The dataset had an imbalance between the target classes, which affected the model’s performance. I addressed this by adjusting class weights and focusing on metrics like F1-score rather than just accuracy.
- Hyperparameter Tuning: Selecting the best hyperparameters for the model was time-consuming. I had to experiment with different combinations to find the most optimal settings for the Random Forest Classifier.
- Overfitting: Initially, the model tended to overfit, especially with too many trees in the forest. I mitigated this by limiting the depth of the trees and performing cross-validation.
Conclusion
This project allowed me to apply machine learning in a practical setting, turning raw customer data into actionable insights. I also learned how to effectively communicate the results through visualizations and performance metrics. The final model was able to predict customer behavior with high accuracy, making it useful for future business decision-making.
Next Steps
- Model Enhancement: In the future, I plan to experiment with other models such as XGBoost or Logistic Regression and fine-tune them further.
- Deployment: I am considering deploying this model as a web application or integrating it with a business dashboard for real-time predictions.
Thank you for taking the time to explore my project, and I hope it inspires you to experiment with machine learning techniques in your own work!
Built With
- colab.google
- matplotlib
- python
- seaborn
- sklearn

Log in or sign up for Devpost to join the conversation.