Inspiration
Is it possible to automatically fill in some of the columns for Monday's items, based on the "name" of each item?
We can be more productive and avoid human errors if we do this automatically.
Can we train a neural network with hundreds of thousands of issues to achieve this?
Using Deep Learning to predict some columns of Monday's items, reading only the name of the item.
At this time, we'll predict the type (bug or improvement) and priority of Monday's items (high, medium, low).
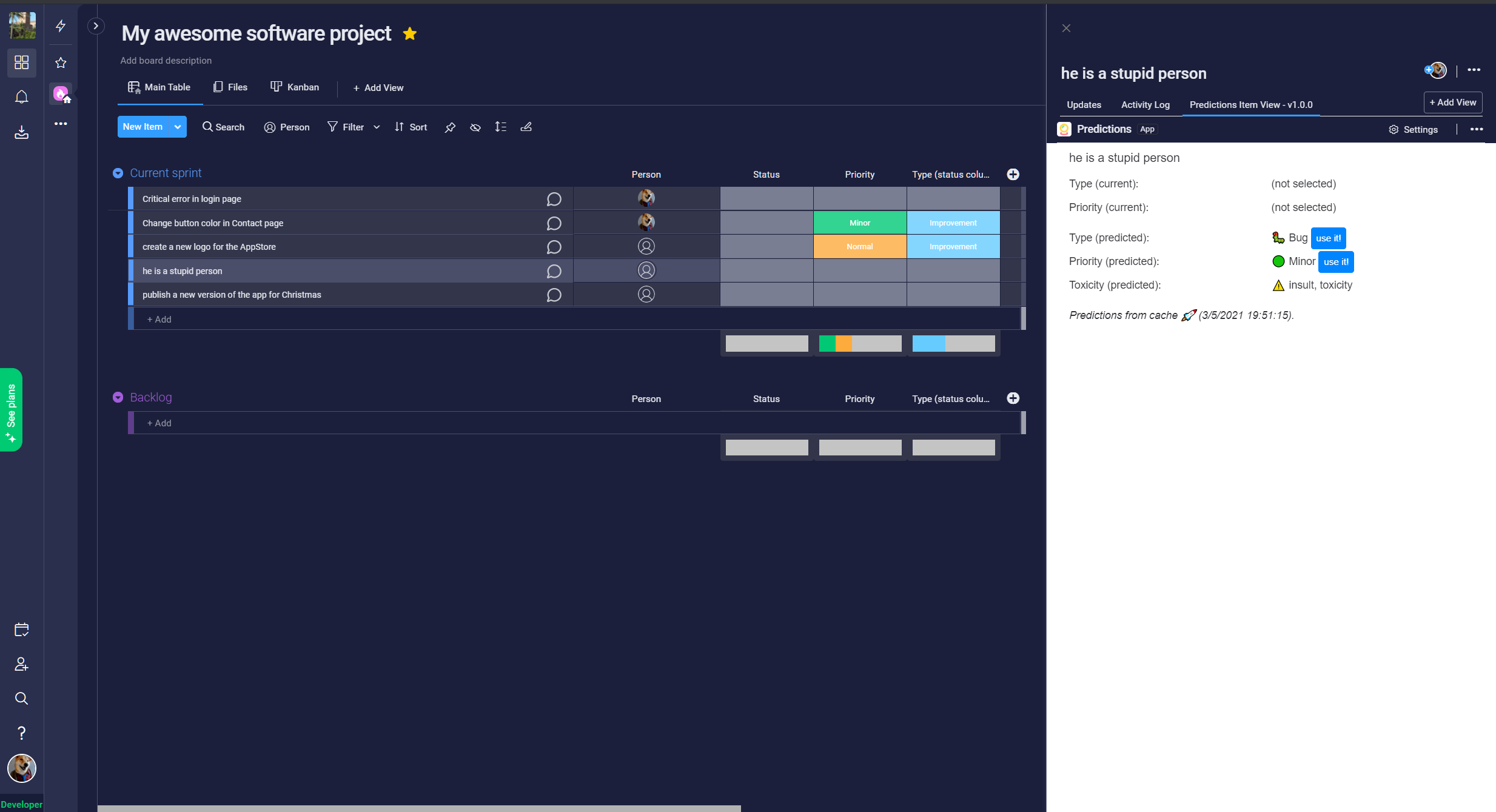
In addition, we'll take advantage of other pre-trained neural networks to detect toxicity in the items. Toxicity means: identity attacks, insults, obscene, severe toxicity, sexual explicit or threats.
What it does
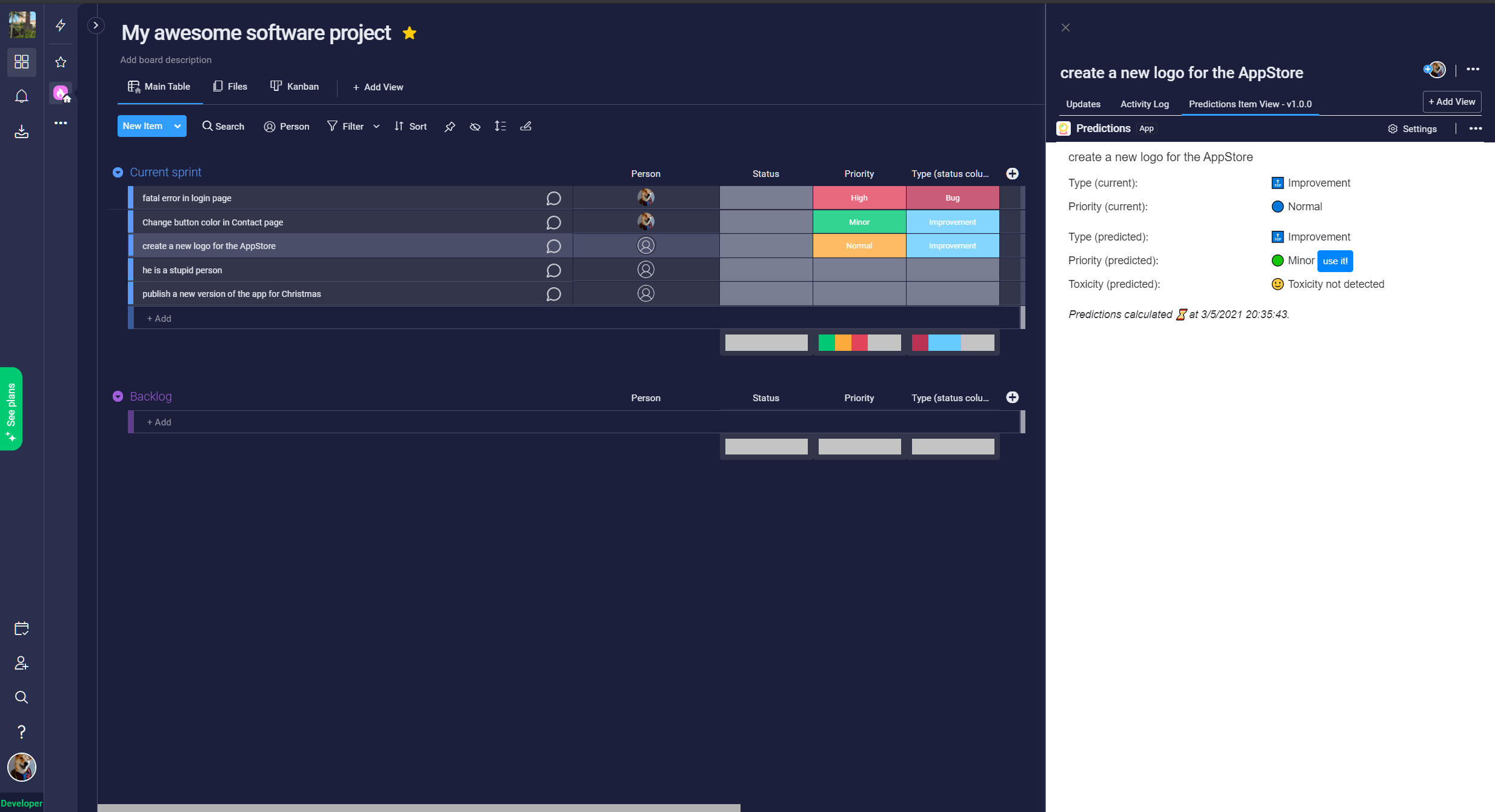
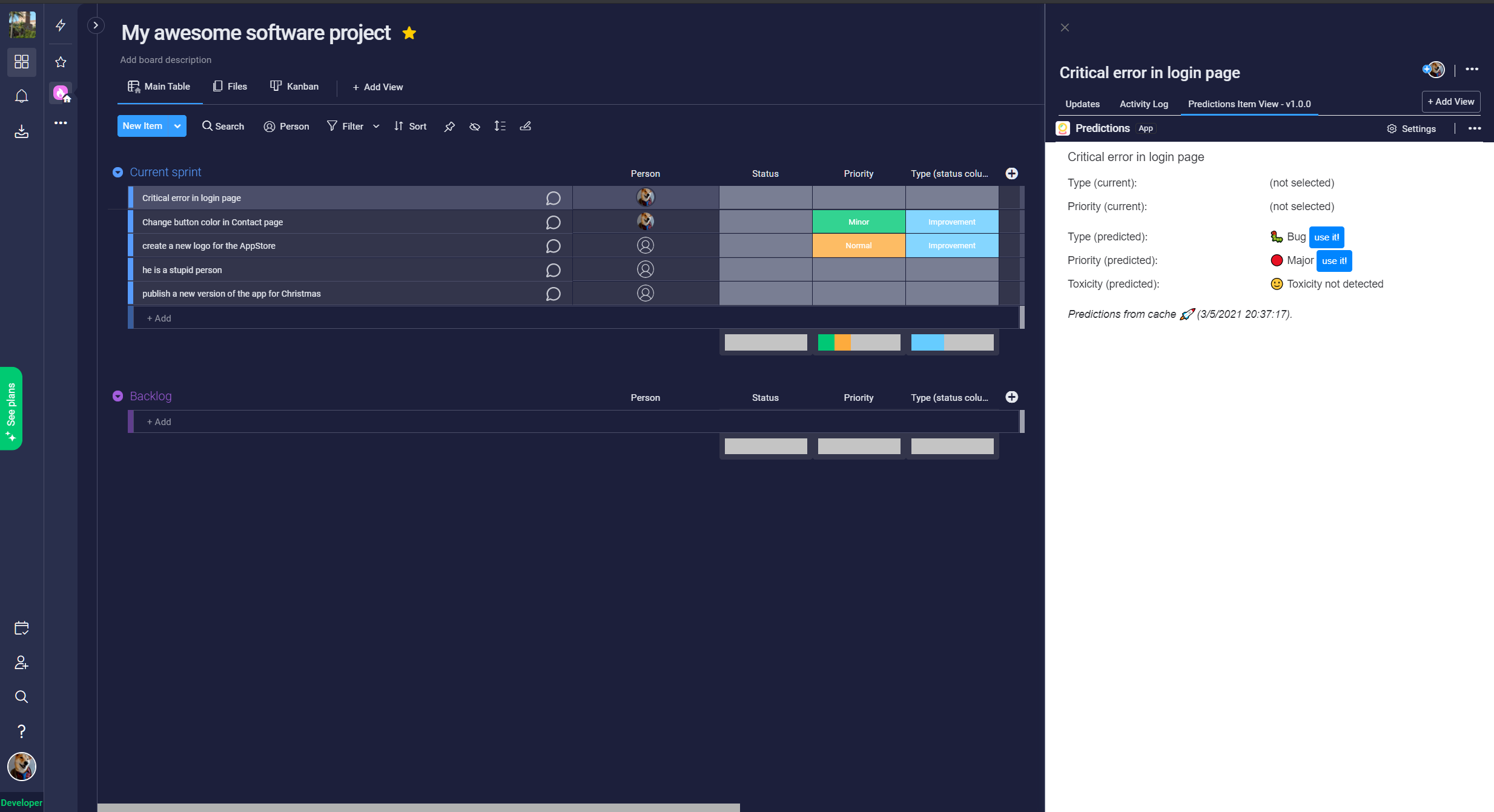
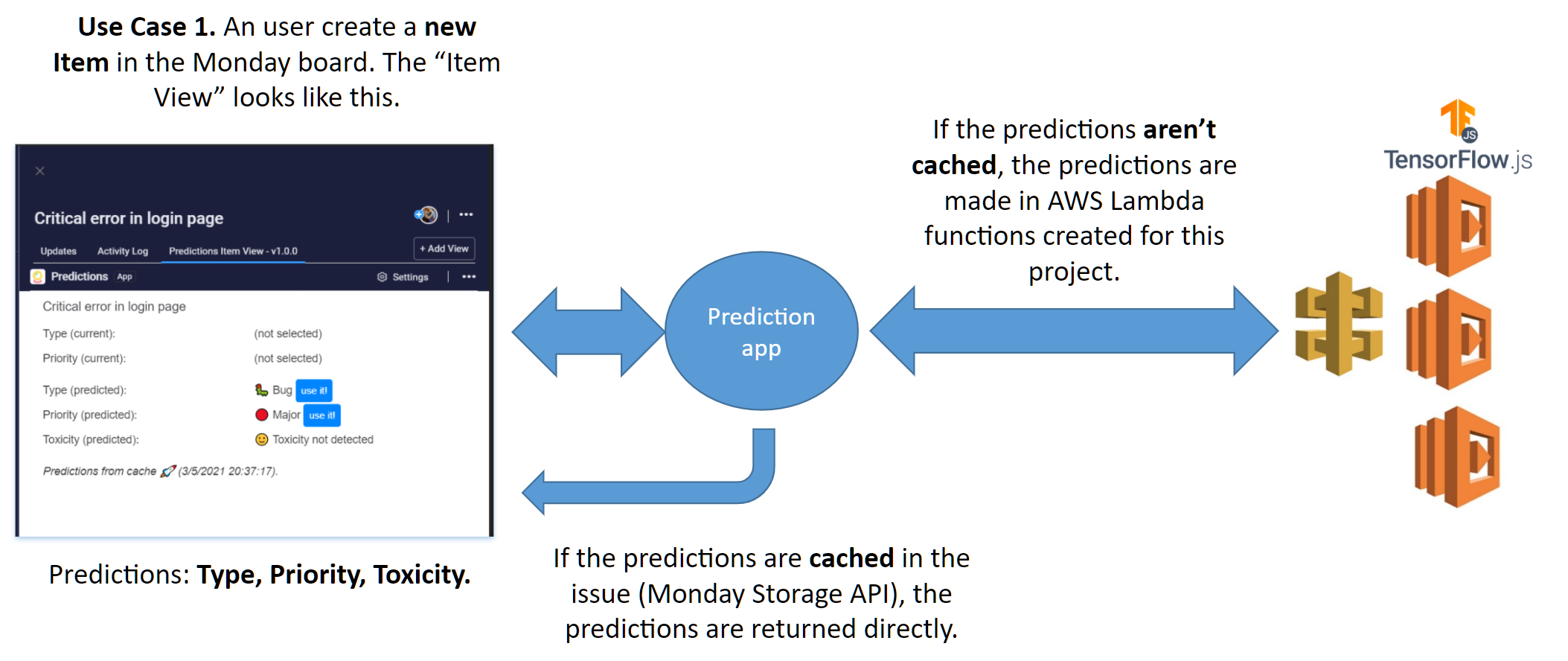
It predicts from the name of a Monday's items, its type and priority. This prediction appears in the Item View of this app. It also detects if there is toxicity in each item.
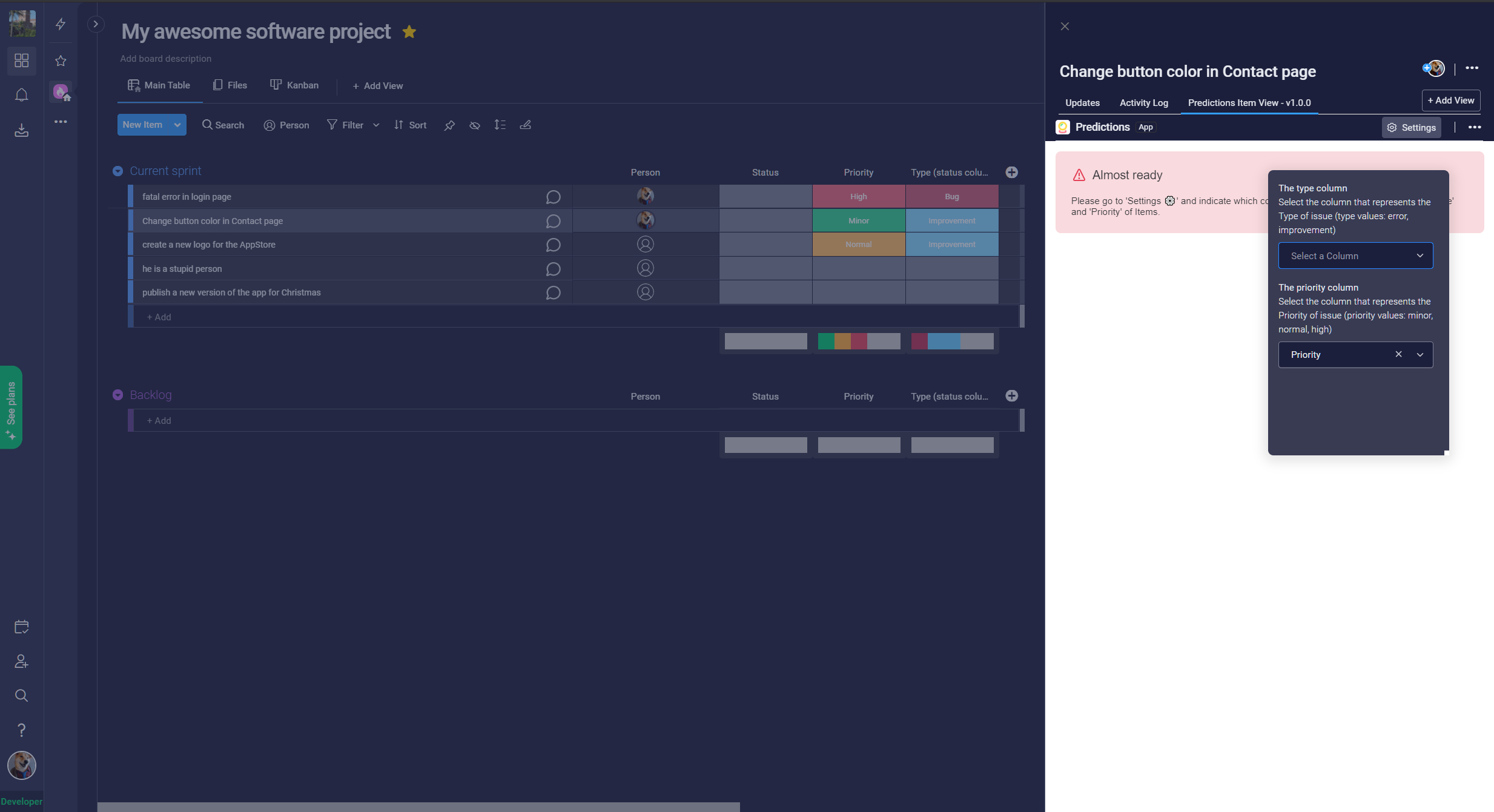
When the "type" or "priority" prediction doesn't match with the value entered by the user, a button will appear in the Item View, to quickly change the user value. With this feature I want to help fix human errors when teams are creating items in Monday.com.
The 'type' and 'priority' predictions are achieved thanks to a neural network that has been created and trained by me, using Tensorflow.

How we built it
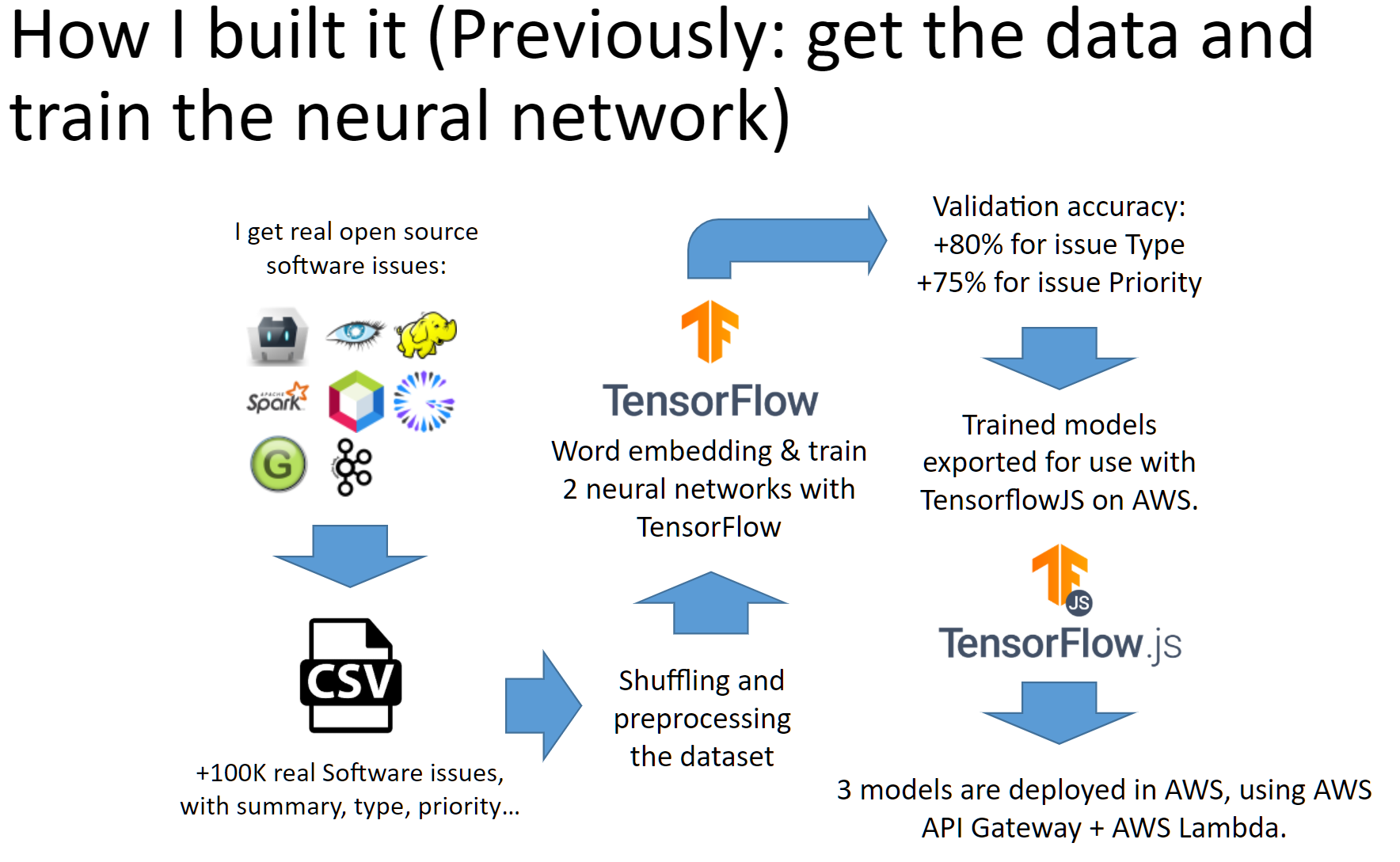
Part 1: Get the data and train the neural network. First of all, I downloaded many real issues from opensource projects. After preprocessing the information, I created a CSV file with more than 100,000 real software issues. For each issue, we have its summary (name), type, priority, etc.
Next, I designed 2 neural networks with Tensorflow 2 and trained them to predict the type of an issue and its priority. I've done several experiments with different hyperparameters, up to over 75% accuracy with test issues.
Afterwards, I exported the trained models so I can use them with TensorflowJS. Then, I published these 2 neural networks using AWS Lambda functions.
The third neural network is the pretrained Toxicity classifier from tensorflowjs, which I've also deployed on AWS Lambda.

For the frontend I've used the Monday SDK and React. Some highlights:
- To achieve the greatest impact, all Monday users can use this app in existing boards. I've used Monday Settings so users can indicate in a simple way what column of their board corresponds to the type of item (bug or improvement) and which column corresponds with priority (low, medium, high).

- I followed the style guidelines of Monday.com, to respect sizes, colors, etc. I also take advantage of its "loaders", to improve the UX and that the user knows when the prediction is being made.
- I use Storage API from Monday, to further improve speed. That is, the predictions are cached and reused if the "name" of the item is not modified. This improves the scalability of the project.
- When the prediction doesn't match the data filled in by the user, buttons called "use it" appear to let quickly change the user's data to the predicted data.
Challenges we ran into
The biggest challenges have been working with React (I'm still a beginner in this framework) and the NLP part: creating the dataset and training the models to make predictions.
Also, during development I've thought of some suggestions for the Monday SDK:
- There is no method to remove info from Storage API.
- In my case, I tried to share data between different Views of the same application, but it is not possible using Storage API.
- I think it would be interesting to implement on Monday an easy way to fill some columns, from other columns, using a synchronous external API. This API would receive the information of the item and respond with the values for the new columns. You wouldn't need a Monday token in these external APIs. I didn't find the easy way to do it synchronously.
Accomplishments that we're proud of
- I'm really proud of the functionality, which will help many users to detect errors in their existing boards. In addition, it will help to get the job done faster, filling in the "type" and "prediction" columns almost automatically. It has a real impact on the daily work of Monday.com users.
- I'm happy with the graphical interface, it is fluid.
- I'm happy with the accuracy of the prediction models.
- Of course I'm proud to help avoid toxicity language in collaborative tools like Monday.com.

What we learned
- I have learned how to use the Monday.com SDK.
- I have learned to use Graphql for the first time, using queries and mutations (to update items).
- I have learned new things from React.
- I have learned more about Natural Language Processing (NLP). I'm aware that Artificial Intelligence can help us a lot in daily tasks, such as tagging items in project management (good datasets and good training are important here).
- I have learned to publish machine learning models in a more efficient way, using AWS Lambda and AWS API Gateway.
What's next for Predictions
- I would like to expand the number of predicted fields.
- I would like to create a Board view.
- I want to create a Widget to show usage statistics. I've not been able to include it in this version because the Widget and the Item View don't share the API Storage data. But I would like to create a widget in the future to show this information:
- 100% toxicity free project,
- number of predictions made,
- number of errors detected with the predictions.
- I want to show "related items" information in Board view and Item view. I think it is possible to extract the topic of each item (using NLP) and show the related items together. I think this information is very useful for users, to avoid duplicate errors and to have the most similar information physically close.
Built With
- amazon-web-services
- aws-lambda
- graphql
- javascript
- monday
- natural-language-processing
- react
- tensorflow
- tensorflowjs



Log in or sign up for Devpost to join the conversation.