-
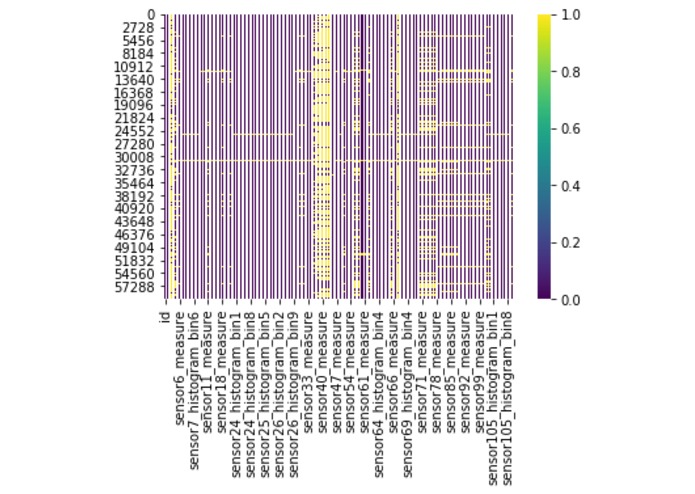
Original missing value pattern of the data
-
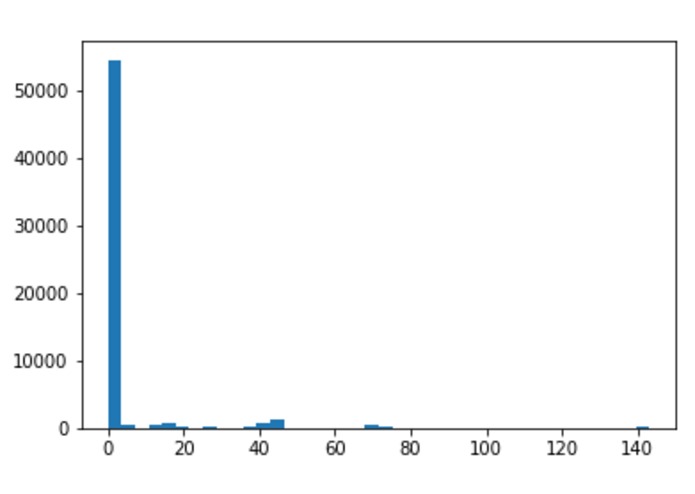
Histogram of number missing values of each feature
-
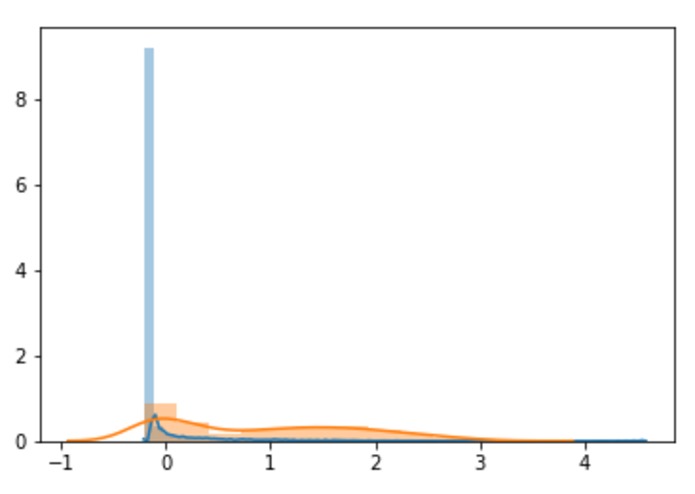
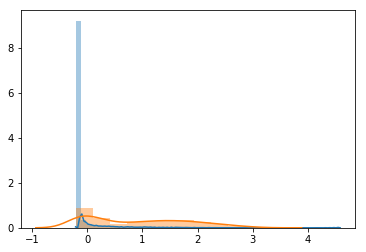
Histogram of feature distribution of positive (orange) and negative (blue) samples
-
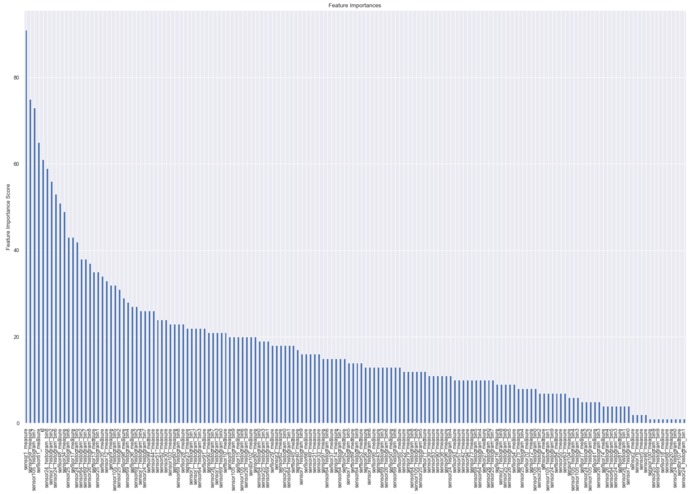
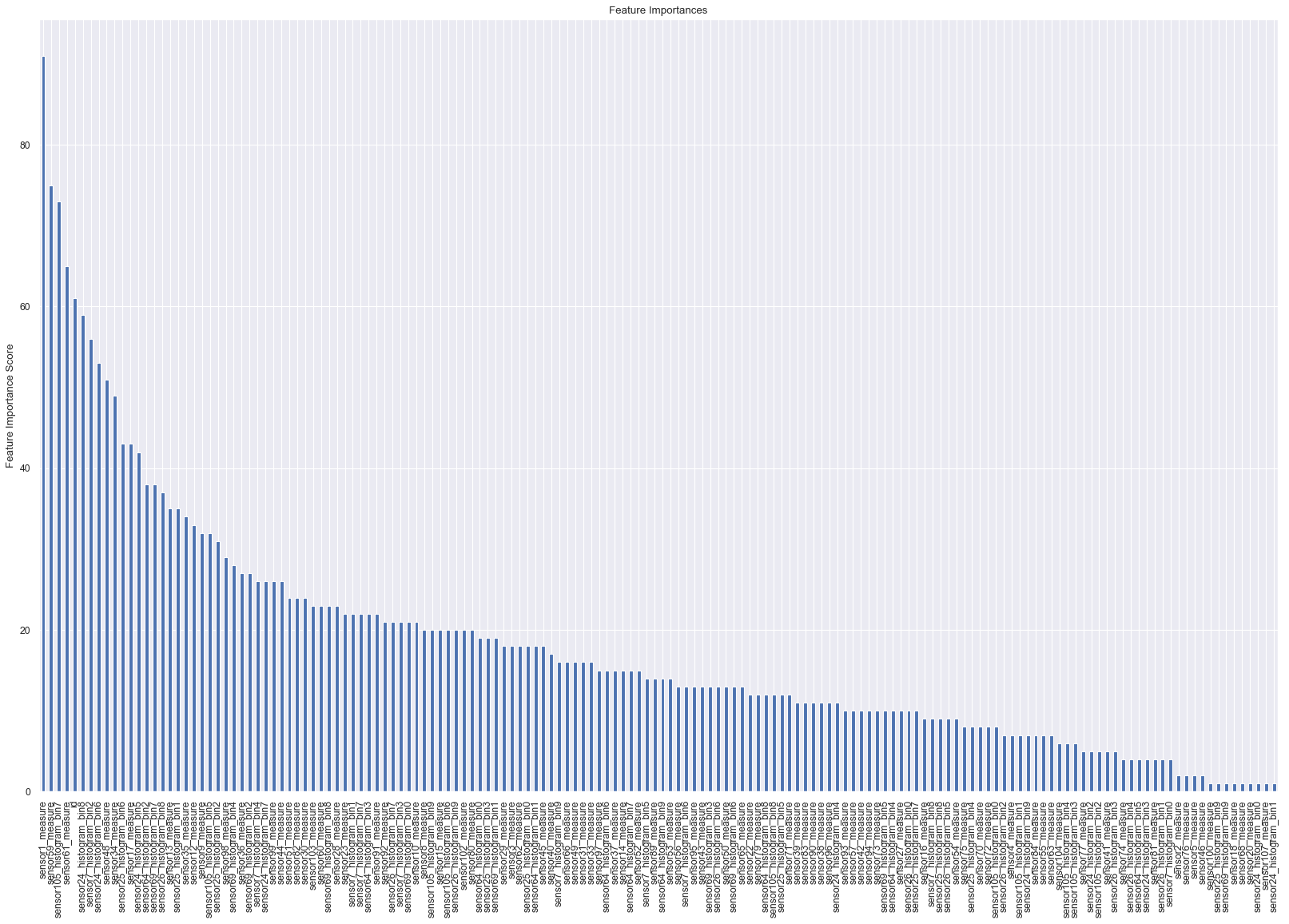
Feature importances derived from our classifier.


Inspiration
80% of producing oil wells in the United States are classified as stripper wells. Stripper wells produce low volumes at the well level, but at an aggregate level these wells are responsible for a significant percentage of domestic oil production. Stripper wells are attractive to a company due to their low operational costs and low capital intensity - ultimately providing a source of steady cash flow to fund operations that require more funds to get off the ground.
Equipment monitoring and predicting failure time is a very important task in the oil and gas industry. Unplanned well downtime results in loss revenue. We build a model to predict equipment failure based on sensor measurements.
What it does
It classifies different samples based on different sensor data collected from a variety of physical information, both on the surface and below the ground. The steps involve include: data preprocessing, normalization, missing value imputation, feature selection, sample removal, model training, and evaluation.
How I built it
We first did a lot exploratory data analysis and data preprocessing. We found that some features are very skewed while others have many missing values. We tested multiple classifiers, including logistic regression, gradient boosted trees, and deep neural networks and found that gradient boosting on trees performed the best.
Challenges we ran into
- The dataset has a major class imbalance: failures are far less frequent than normal operation. We addressed this by upsampling the less frequent class.
- The data had a lot of missing values. We alleviate this by removing features and samples that had severe amount of missing, and imputing the remaining missing data with the mean.
- Some features of the data are heavily skewed. We amend this by performing a log transformation of the heavily skewed data.
- The training and testing sets have different mean and variance, creating a slight distribution shift.
Accomplishments that I'm proud of
- We are able to achieve very good results while maintaining good interpretability, without relying on black-box models such as deep learning.
- Significant F1-score (98.107%) is achieved using only a single feature.
- Feature importances show the usefulness of each feature, maintaining interpretability of our model.

Log in or sign up for Devpost to join the conversation.