-
-
Poster
Predicting Political Party Affiliation Using Tweets
Marina Triebenbacher (mtrieben) Rachel Yan (ry22) Zachary Mothner (zmothner)
Find our final writeup here: https://docs.google.com/document/d/1O7AxPipTLktGYl2PvFXN18ok87yBWgHjhyUGj_Jld44/edit?usp=sharing
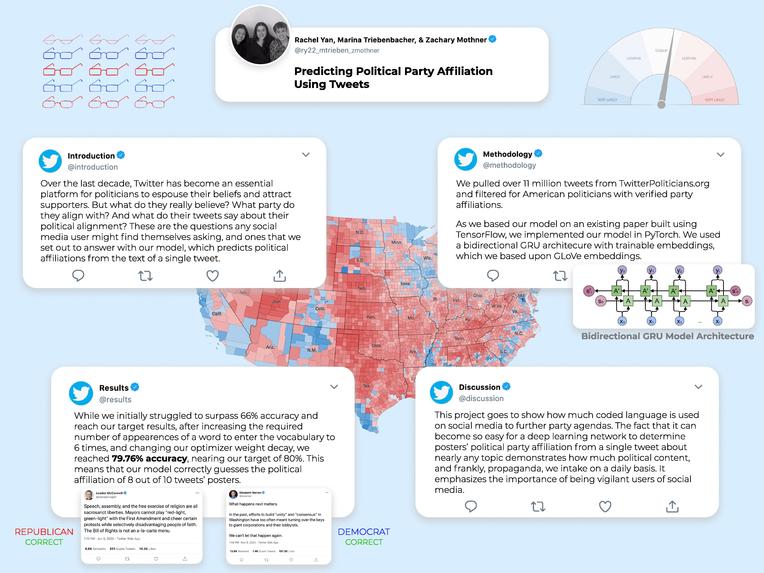
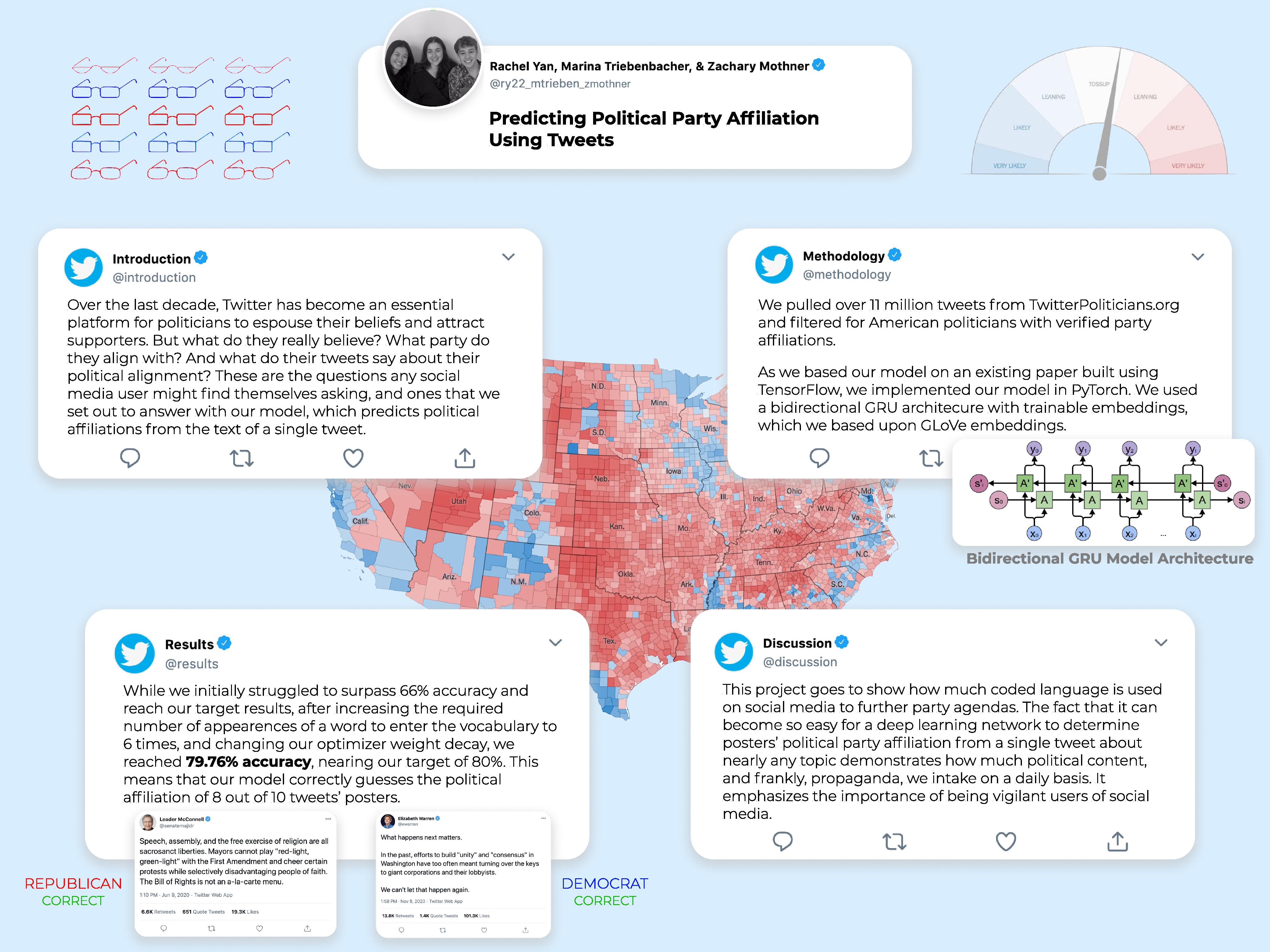
In this project we will be implementing a Deep Learning Neural Network Algorithm to predict Twitter users’ political affiliations using a singular tweet. We will be using a GRU model architecture based off of that which is described in the Stanford University paper Predicting U.S. Political Party Affiliation on Twitter. Given that this paper has included their code repository, which contains a model built on the Tensorflow framework, we will be implementing this model on the Pytorch framework. This paper also used the dataset Tweet Congress for their training and testing data, but we will be using the dataset Twitter Politicians. This dataset also includes politicians from countries outside of the United States, which means if we can build a model successful in classifying U.S. political parties, we can attempt to apply it to other countries’ political systems.
Related Work
Predicting U.S. Political Party Affiliation on Twitter, see above.
TIMME: Twitter Ideology-detection via Multi-task Multi-relational Embedding, this paper attempts to perform a similar classification (determining a user’s political party affiliation), but uses far more metrics by analyzing an entire Twitter user as opposed to a single tweet. This model takes into account a user’s following, retweets, likes, etc.; however, we will only be examining one tweet at a time.
Data
We will be using the Twitter Politicians dataset, which was created as a collaboration between Political Sociology at University of Amsterdam and Complex Systems at Chalmers University of Technology in Sweden. The dataset consists of Tweets from nearly 9000 politicians from 26 countries. We plan on filtering out the Tweets from US politicians who are members of the Democratic of Republican parties and using this data to train our model. As this is a NLP-based model, we will be tokenizing the Tweets during preprocessing as well as getting rid of any punctuation. In addition, the paper we are replicating removed all hashtags and mentions from the Tweets, so we plan on experimenting with how that preprocessing step impacts our outcomes.
Methodology
The paper we are replicating implemented a wide variety of models to compare their outcomes, but the most successful model was a bi-directional GRU model with trainable embeddings. The architecture consists of 2 GRU cells, with one unit processing the tokens in the forward direction and the other processing them in the reverse direction. The advantage of this architecture is that it allows each token to influence the tokens that come both before and after it. In addition, in the backpropagation step, the paper uses a trainable embedding matrix to allow the matrix to adapt to the text distribution of the Tweets. The outputs of the two GRU cells in the bidirectional model are concatenated into a 256-dimensional vector which is then passed through a fully connected layer with sigmoid activation to get a (0,1) output to classify a Tweet into one of 2 political parties. Additionally, this model uses Cross-Entropy Loss as the loss function, an Adam Optimizer, and L2 Regularization and Dropout.
Metrics
The paper upon which we are basing our work states in its abstract that they were able to implement a GRU model that can classify political party affiliation with 91.6% accuracy. Our goal will be to implement a model using the Pytorch framework which can approach or achieve this level of accuracy. The authors of the paper use tweets from U.S. politicians with registered political parties so that they can train and test with verified classifications. We will take a similar approach, and use politicians’ official party affiliation as their classification. Our base goal would be to reach the accuracy these researchers reached with their RNN model (~70%). Our target goal would be to increase this accuracy to 80%. Our stretch goal is to achieve 85-90% accuracy as achieved in this paper’s optimal GRU models.
Ethics
What broader societal issues are relevant to your chosen problem space?
It’s become abundantly clear from the 2020 presidential election that disinformation campaigns on social media have become mainstream practice and are here to stay. Given that one political party has denied the results of the election and its politicians are mainly using Twitter as the platform to disseminate their conspiracy theories, the spread of fake news on Twitter is a pressing societal problem that has the potential to seriously undermine our democracy. Predicting political party affiliation is a good start to addressing this problem, because knowing a user’s political leaning illuminates that user’s incentive structure and can link them to similar users.
Why is Deep Learning a good approach to this problem?
Currently, social media companies mainly use human fact-checkers around the world to manually check for hate speech or other illegal posts. This strategy is commonly accepted to be highly ineffective, and because disinformation campaigns are becoming more commonplace and dangerous, it’s essential that technology companies invest in innovative techniques to combat the spread of fake news. We believe that deep learning algorithms have the potential to transform this space, because they can process large amounts of data and classify Tweets relatively accurately. Furthermore, even if as a society we do not yet trust algorithms to conduct all social media fact-checking, or we are afraid of the political backlash it would cause, we can use a political affiliation classification algorithm as a preliminary step to help human fact-checkers. Using deep learning in this situation would help make their work both more efficient and effective.
Division of Labor
We plan to work mostly synchronously, with responsibility for each section divided as follows:
Marina: pre-processing, framework of the model, final writeup/presentation
Rachel: framework of the model, digital poster, reflection #2
Zach: training, testing and tuning hyperparameters, oral presentation




Log in or sign up for Devpost to join the conversation.