-
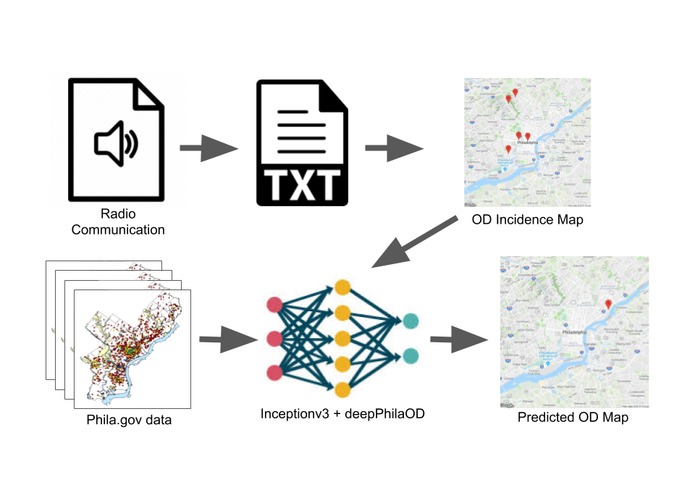
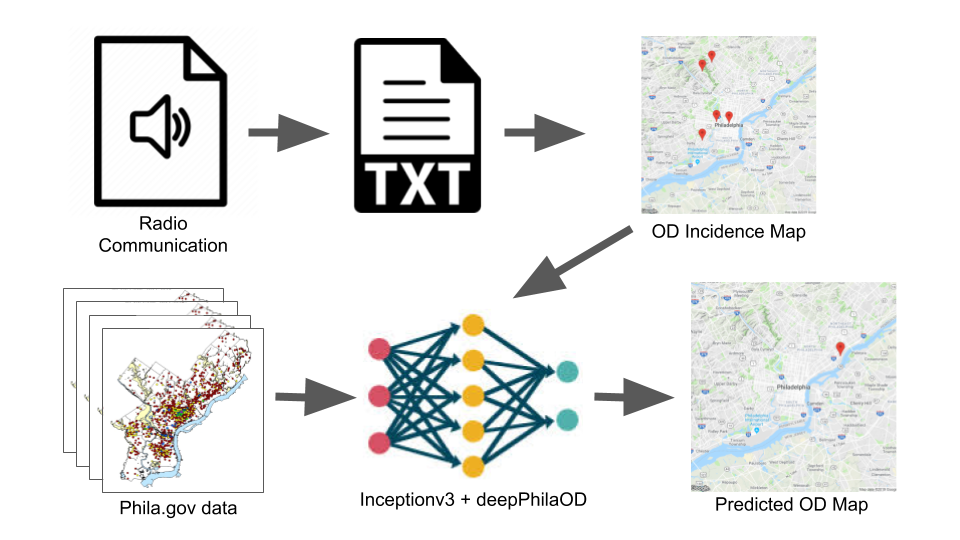
Project Schematic: Audio is processed into OD incidence maps, which predict the epidemic progression. Phila.gov data is ideal training data.
-

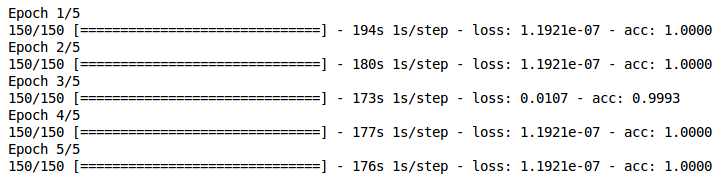
Testing DeepPhilaOD: 5 epochs, 150 steps per epoch (took about 6 minutes per epoch), default parameters yielded roughly 0 accuracy.
-
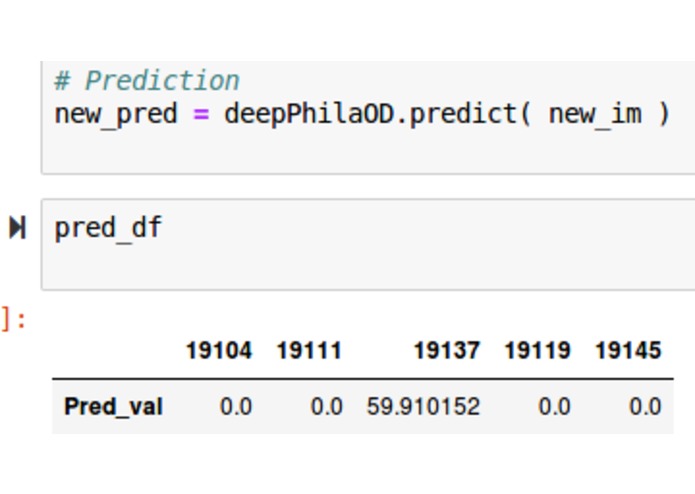
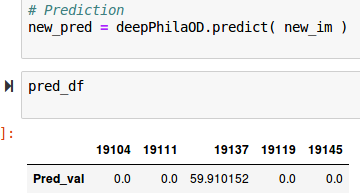
Sample prediction: raw output is an array of predicted overdose values that correlates with zip code regions.
DeepPhilaOD - 9B
Predicting Opioid epidemic progression from EMS radio audio
Inspiration
Philadelphia is one of many locations in the US that is affected by economic inequity. By July 2018, nearly 3 million low-income Pennsylvania residents were enrolled in Medicaid/ CHIP[1]. Community poverty has been shown to be a risk factor of drug addiction to which the opioid epidemic is linked [2]. A lot of publicly available data on opioid abuse is not updated on a live basis - usually, it’s quarterly at best. We were hoping that by scanning unconventional channels of information, we could help to identify areas that currently are, and may be hotspot areas for opioid abuse in the future, which helps professionals work proactively in combating the environmental risk factors that contribute to opioid abuse.
What it does
This project models the opioid epidemic progression and predicts its progression through analysis of EMS radio audio, such as on police channels using Broadcastify, to identify incidents of opioid-related calls along with other attributes like location and time. The proposed predictive model DeepPhilaOD is a deep convolutional neural network that generates predictions of overdoses for certain zip codes. Prelimary training and testing has resulted in 99.99% accuracy, but only 5 zip code areas were analyzed.
How we built it
We stuck with python as our language of choice for this project, and relied heavily on having broadcastify.com as a source of live police & EMS radio, and wrote scripts for Google Cloud’s various tools and services. The short version is: we record the jabber on Philadelphia’s publicly available police & EMS radios and turn it into text. Then, we parsed that text and visualized it on a map.
The deep learning portion of this is based on the pre-trained model called Inceptionv3 by Google. This pre-trained model has network weights from training on about 1.2 million images, validation on 50,000 images and testing on 100,000 images. Because this base network is very deep, a considerable number of layers (dense, dropout, convolution, maxpooling,etc) were added for the implementation of transfer learning in Keras. Preprocessing of the image data is necessary to convert it to channels-last input tensor. Although the initial testing results yielded consistent 0% accuracy, with parameter tuning, the results indicate a very high accuracy above 99%.
Challenges we ran into
First, data. It was difficult to get examples of police and EMS raw audio files. We found a site called broadcastify.com that hosted streams of police and emergency response scanners, but had to figure out how to capture the audio from the site into a format that we could feed to Google’s Speech API. We were all relatively inexperienced, and none of us had worked with an API prior to this event, so there was a lot of documentation to read, errors to troubleshoot, and dependencies to install. After finally configuring our systems, we spent a lot of time slowly building up pieces of our project and were constantly wondering whether our idea was too ambitious for our skill level. Later in the workflow, ideally, the transfer learning model would be trained on data that was used to generate the annual summary figures on Philadelphia's Department of Health, Health Information Portal.
Another significant issue is that there were only 5 zip code regions considered in the training, testing, and evaluation. It is fairly common to see 47 zip code regions on zip code maps, but there is a total of 87 total zip codes in Philadelphia. The small number of regions targeted for generating predictions may have been a factor contributing to an artificial inflation of the testing result (nearly all at 100%).
Accomplishments that we're proud of
We're all first time hackers and first time using API and image-related deep learning! Making something that actually functioned fairly close to our original vision was very exciting, and we were all proud of what we had created together.
What we learned
Lots! A lot about API’s, how challenging it was to produce something that would actually help others combat poverty and better utilize their resources, figuring out how to use brand-new tools in a relatively short amount of time.
What's next for DeepPhilaOD?
Although the skeleton of DeepPhilaOD has taken shape, the workflow has yet to be automated. Future works include filtering the audio transcripts with an embedding network, such as the pre-trained word2vec, to determine whether the incidence is opioid overdose-related, whether each new dialogue is a new incident, and so on. Another augmention could be developed for scraping additional attributes from other EMS data that would ideally improve the model's reliability and prediction.
References
[1] https://www.healthinsurance.org/pennsylvania-medicaid/
[2] https://www.drugabuse.gov/publications/drugs-brains-behavior-science-addiction/drug-misuse-addiction
Built With
- audio-streaming
- deep-learning
- ffmpeg
- google-cloud
- google-compute-engine
- google-maps
- google-speech-to-text-api
- google-storage
- google-vm-instances
- python
- transfer-learning


Log in or sign up for Devpost to join the conversation.