-
-
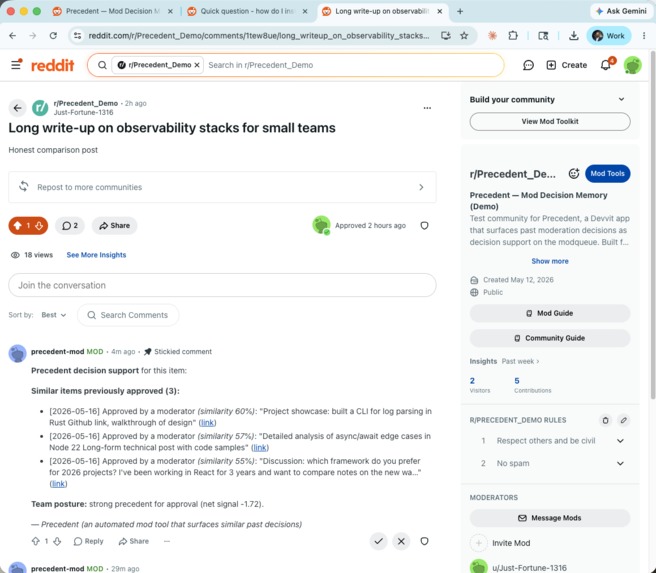
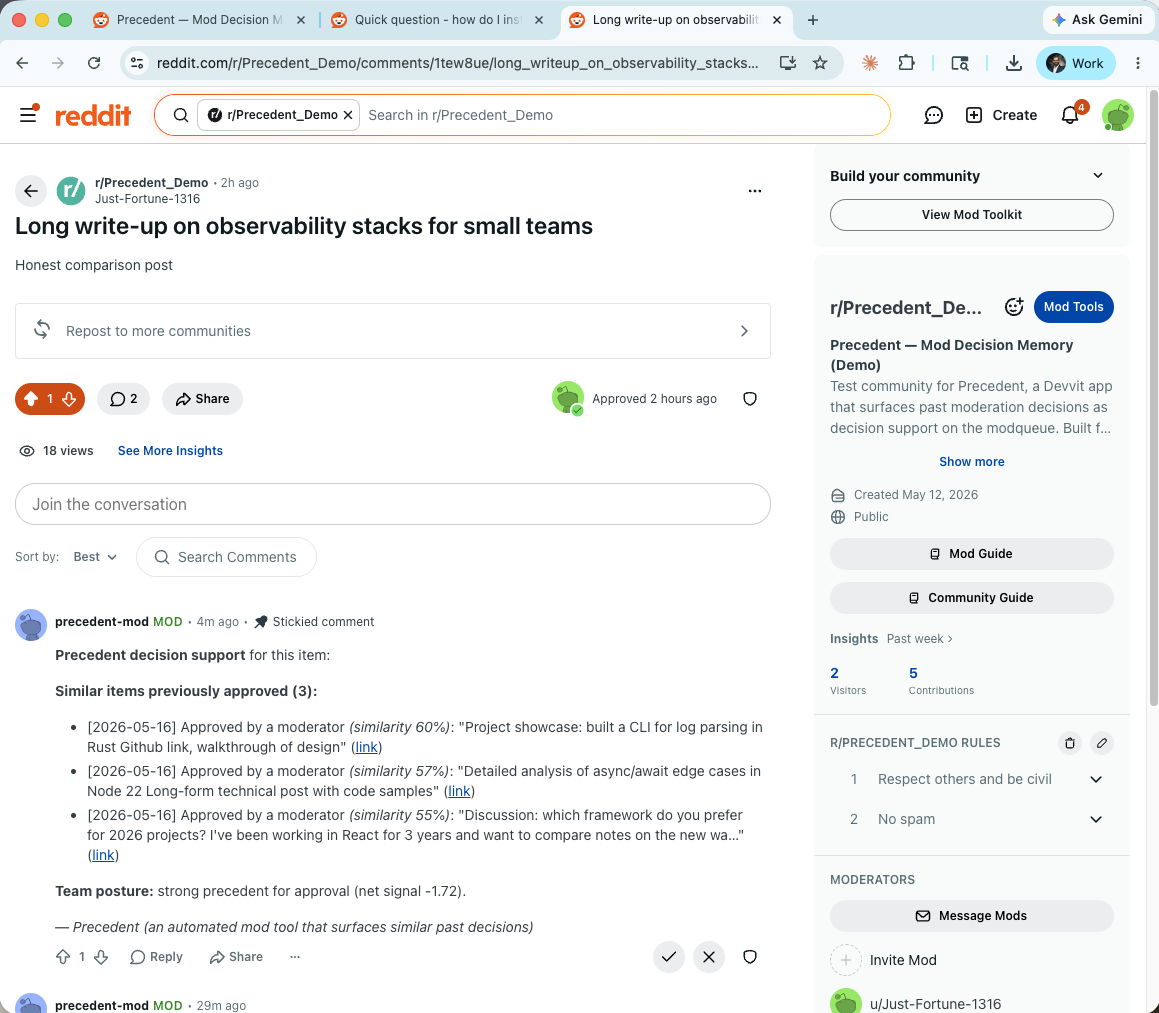
Mod-side decision support: find-similar posted 3 matching team approvals with similarity %, dates, and team-posture net signal.
-
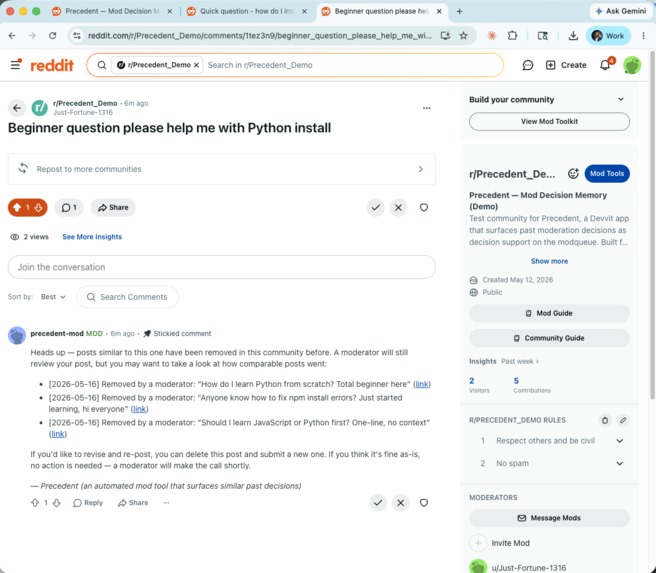
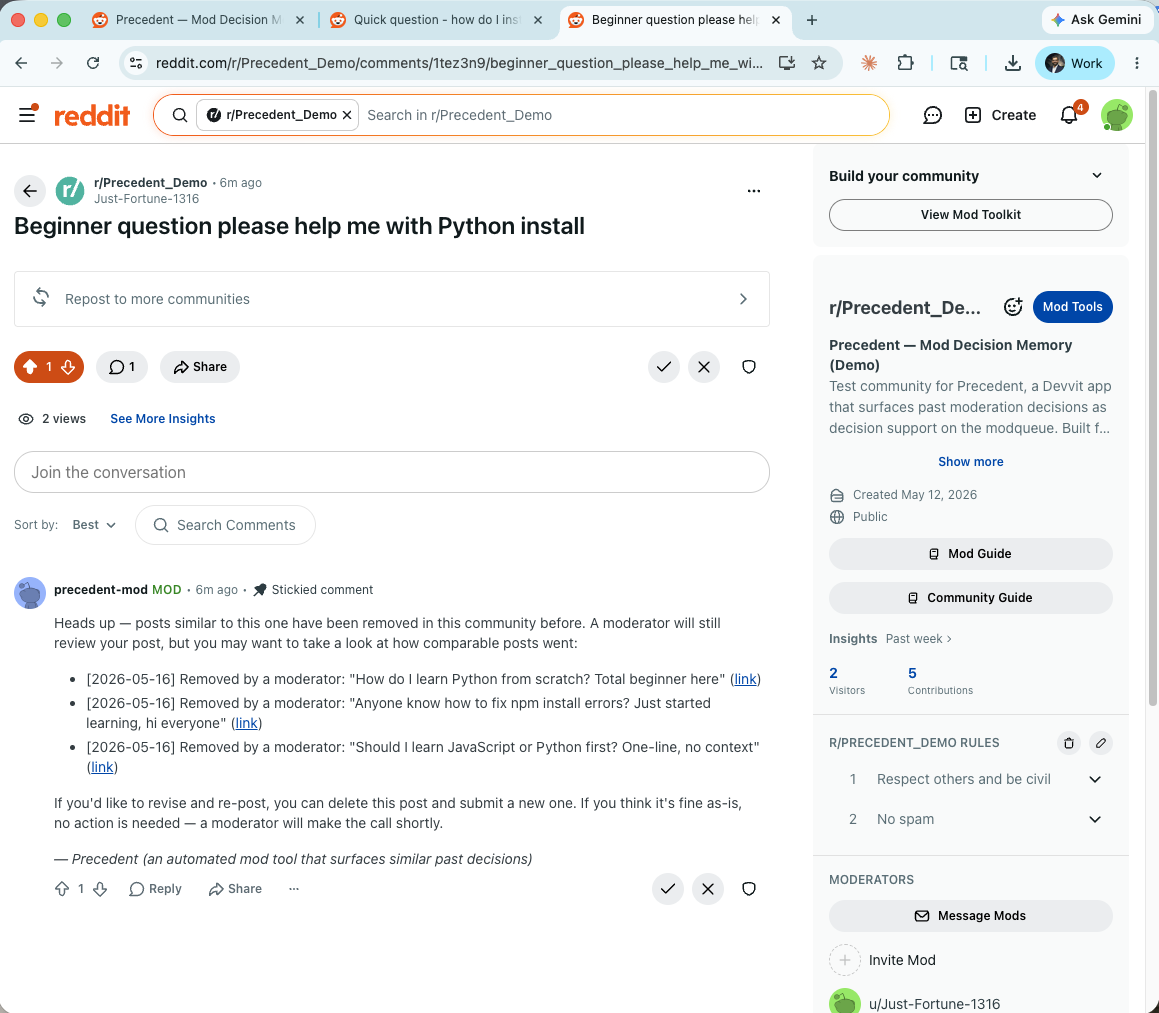
User-side proactive coaching: posted before mod review when a new post matched 3 prior team removals; user offered a revision path.
Inspiration A few weeks ago I was reading r/ModSupport — Reddit's sub for moderators talking shop — and noticed a recurring thread: "I just removed the third near-identical low-effort post this morning, and I know my co-mods would have handled it differently. We're not on the same page and there's no good way to get there."
The undercurrent in those threads isn't that mods need better removal tools. AutoMod exists. The modqueue exists. What's missing is decision memory. A mod team applies rules consistently in theory, but the rules aren't written for every edge case, and every mod ends up making the same call differently on borderline content. New moderators especially struggle — they spend months guessing the team's actual posture on cases that automated rules can't capture.
Every subreddit already generates the data needed to address this. Every mod action is, in effect, a labelled example of how the team handles a particular kind of content. Existing tooling — AutoMod, the modqueue, third-party classifier bots — doesn't treat that history as memory.
I'd been looking for the right Devvit project to commit serious time to. The combination of mod tooling, novel use of Devvit Redis, and a clear unmet need made this hackathon the right alignment. The Devvit platform's native access to mod actions, Redis storage, and trigger surfaces meant the project could live inside Reddit, not bolted on as a webhook integration. What it does Precedent turns a subreddit's modlog into a vector-indexed decision memory and uses it to support mods at the moment a decision is being made.
It runs through three surfaces.
Autonomous ingestion. Every mod action — every remove, approve, spam, ban, distinguish — fires a Devvit ModAction trigger that embeds the affected content via Google's gemini-embedding-001 model and stores it as a precedent in Devvit Redis. The corpus grows automatically as the team works. There's no setup beyond a one-time API key.
Mod-side decision support. From any post or comment, a moderator clicks Precedent: find similar past decisions. The current item is embedded, compared against the corpus via cosine similarity with recency-weighting, and the top matches are partitioned into removal-evidence and approval-evidence. The app posts a distinguished comment from u/precedent-mod showing both sides — dates, similarity percentages, snippets, links — and a net signal interpreting the team's posture on this kind of content.
User-side proactive coaching. When a user submits a new post that pattern-matches strongly removed content, the app posts a polite stickied comment to the post — before any mod has seen it — showing the user up to three similar prior removals and offering a path to revise. Users who want to fix the issue can delete and re-post. Users who think they're fine can wait for human review. The comment makes the implicit explicit, before the post hits a mod's queue.
Modlog backfill. A subreddit-scoped menu action seeds the corpus from up to 90 days of pre-existing modlog history, so a new install doesn't have to wait for fresh actions to be useful.
A redact menu action also lets mods exclude individual precedents from user-facing surfacing while keeping them in mod-side analysis — for cases where a past decision shouldn't be re-surfaced (a post later contested, a one-off call the team wouldn't want amplified). How we built it Stack: TypeScript on Node 22 LTS, Devvit @devvit/public-api, Devvit Redis as the durable K-V store, Google Gemini API with gemini-embedding-001 (768 dimensions, output-dimensionality controlled), Devvit ModAction and PostSubmit triggers for ingestion and surface activation, Devvit menu actions for moderator-initiated surfaces.
The architecture is deliberately simple. Every external surface — Devvit Redis, Reddit API, settings, modlog iterator — is bridged through a small adapter file (~300 lines). The retrieval, ingestion, ranking, sticky composition, and embedding modules are platform-agnostic: they take typed interfaces, not Devvit-specific objects. The same code is exercised by an in-memory test harness with 60 synthetic mod actions across five archetypal buckets, which lets ranking-logic iterations happen without burning a single API call.
Ranking is a composite of three signals: cosine similarity (the dominant term), a 120-day recency half-life decay so the team's recent posture outweighs older calls, and a curation boost for precedents explicitly marked as canonical. A 0.55 similarity floor filters noise before scoring. Top-K is configurable and defaults to 5.
The partition-by-action step is the most consequential piece of the design. After ranking, results split into removal-evidence (any action that took content down) and approval-evidence (any action that kept it up), with a net signal computed as the score-weighted difference. The user-side coaching surface only fires when the net signal exceeds a configurable threshold; in mod-side analysis, both buckets are always shown.
Privacy: moderator names are anonymised by default in user-facing comments — surfaced as "by a moderator" rather than by username. The redact flag is enforced at the storage layer, not in prompts, so the retrieval code structurally cannot return redacted precedents.
Corpus storage is hex-packed Float32 (8 chars per float, ~6 KB per 768-dim vector). Devvit Redis doesn't expose RediSearch or vector-index support, so cosine ranking happens in-app over a linear scan; this is viable up to roughly 5,000 precedents per sub before a different approach would be needed. Challenges we ran into Devvit Redis zRange semantics. The bug that cost the most time to track down. Devvit's zRange supports a by: 'score' | 'lex' | 'rank' option that controls how the start and stop arguments are interpreted. The original storage code used by: 'score', which treats start/stop as score thresholds, not array indices. Our scores are decidedAt timestamps in milliseconds (around 10^12), so asking for "scores 0 to 499" returned nothing. Every read against the corpus came back silently empty after every successful write. Switching to by: 'rank' was the fix once I read Devvit's type definitions carefully enough to spot the semantic difference.
Playtest log buffering. For about an hour I was convinced PostSubmit triggers weren't firing. The devvit playtest watcher terminal was surfacing some events (AppUpgrade, ModAction-on-app-changes) but not user-submitted PostSubmit events. Switching to the dedicated devvit logs tail revealed every trigger had been firing correctly — the playtest watcher just doesn't surface all events.
Devvit public-api version drift. Context shapes (context.redis, context.reddit, context.settings) and event payload types have moved across minor versions of @devvit/public-api. Instead of pinning hard to a specific shape, the adapters use loose indexed-access types with defensive runtime coercion. A Devvit point release shouldn't break the build.
Cold-start corpus. On a brand-new install, no precedents exist, so both surfaces are silent until the first few mod actions land. Modlog backfill solves this for established subs; a freshly-created sub still has nothing. I considered seeding from a community-baseline corpus and decided against it — Precedent's whole value proposition is that it reflects this team's posture. Surfacing decisions made by someone else's team would break the trust model. Silence for the first dozen actions is the correct trade.
Trigger fire latency. Devvit triggers occasionally take 2-5 seconds to fire on the playtest install. The user-coaching surface tolerates this — it's still well before mod review. The mod-side surface is moderator-initiated, so latency isn't visible there. Accomplishments that we're proud of The architectural pattern. Every Devvit-specific bridge lives in one file (src/devvit/adapters.ts). Every behavioural module is platform-agnostic. The same handleModAction function that runs in production is exercised by the offline test harness with deterministic embeddings and an in-memory Redis. If the underlying embedding model is swapped, or if Reddit ships a different storage primitive, only the adapter file changes.
The honesty feature working as designed in tests as well as in production. The offline test suite includes a controversial-on-topic bucket: posts that pattern-match removed content where the team has also been approving similar items. The retrieval correctly computes a net signal of around -1.0 on these, which means the user-coaching surface declines to post a warning even though there's strong removal-evidence — because there's also strong approval-evidence on the same content type. That behaviour isn't a special case in the code; it falls out of the partition-by-action design.
Real, durable production state. The app is installed and running in r/Precedent_Demo with a working corpus of real precedents and both surfaces firing autonomously. The ingestion pipeline has been running since the build phase; every mod action grows the corpus; every new submission gets checked against it; the find-similar surface produces clean analysis comments on demand.
What we learned Architectural safety beats prompt safety. The early design had user-coaching gated by prompt instructions to the LLM. The reworked version makes the threshold check deterministic code and enforces the redaction filter as a Redis-level exclude in the retrieval path. Same principle as not placing access controls in LLM prompts: enforce one layer below the AI, where bypass isn't possible.
Devvit's hot-reload loop is excellent once the development tax is paid. The first deploy is fiddly — registering the app, configuring secrets, understanding playtest semantics — but once the watcher is running, code changes land in production within seconds. The development-to-test cycle on the last third of the build was tight enough that ranking-algorithm variations could be tried and observed live in r/Precedent_Demo.
The collaborative tone of the resulting comments came from code shape, not from prompt engineering. The data model partitions retrievals into removal-evidence and approval-evidence; the retrieval code mandates showing both; the composition function includes a disclosure line and a revision path; moderator names are anonymised by default. Each of those is a code-shape choice, not a UX afterthought, and together they produced something that reads as collaborative rather than judgmental.
What's next for Precedent — Mod Decision Memory Short-term: a custom-post analytics dashboard for moderators — corpus growth over time, team decision consistency on similar items, top-pattern clusters per sub. The natural Devvit-native surface and the highest-value addition for mods who want a longer view of how the team is moderating.
Beyond that: a mark-canonical menu action so mods can elevate especially clear examples as anchors for future retrievals. A decision-rationale capture prompt — "why are you removing this?" — saved alongside the precedent, giving future similarity matches semantic signal beyond just the content. Drift detection that flags when newer precedents start contradicting older ones on similar content types, for team review. Opt-in cross-sub precedent sharing for subreddit networks where mod teams want to align (e.g., the family of technical-help subs, or the science Q&A subs).
Longer term, the goal is for Precedent to become a quiet utility layer beneath mod work — something that doesn't draw attention to itself but is reliably there when a borderline decision is being made, drawing on a corpus that grows more useful the longer the team uses it.
Built With
- agentic-ai
- cosine-similarity
- devvit
- embeddings
- gemini-api
- google-gemini
- node.js
- redis
- typescript
- vector-search

Log in or sign up for Devpost to join the conversation.