-
-
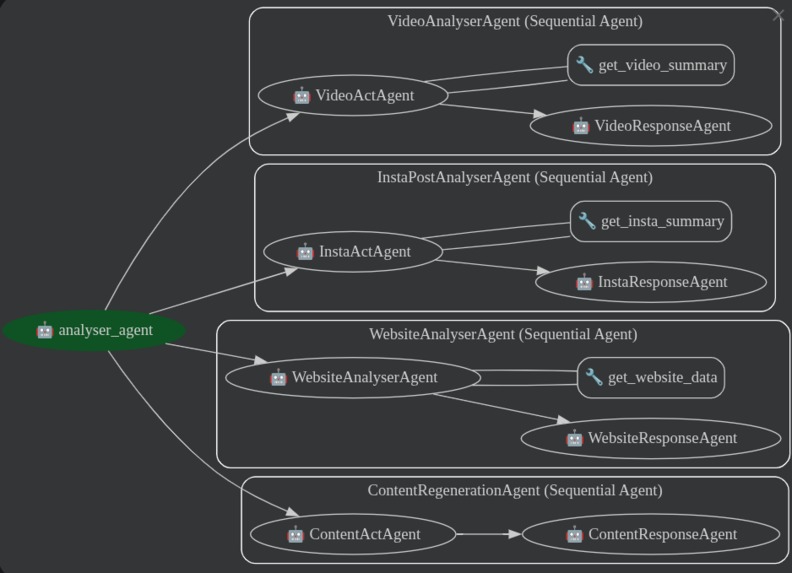
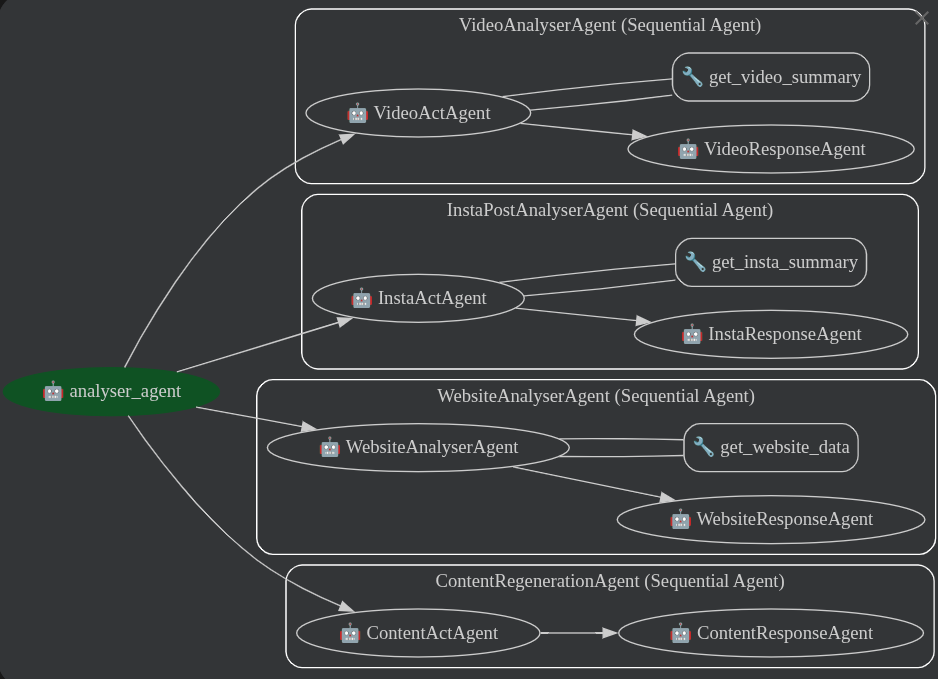
The google adk agentic graph that showcases how the framework works based on the input data.
-
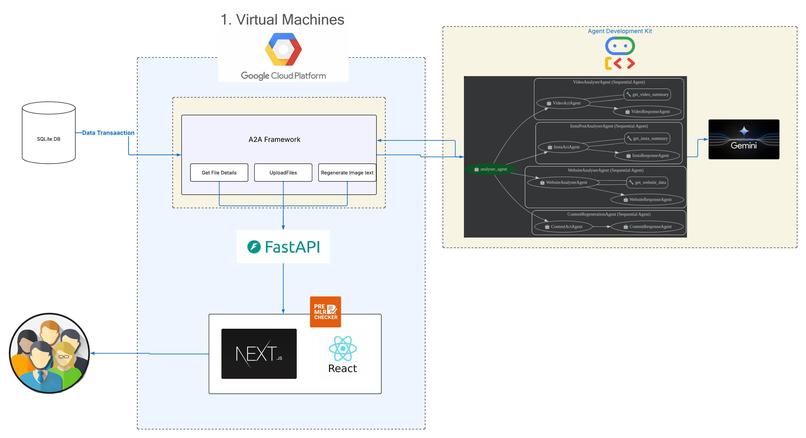
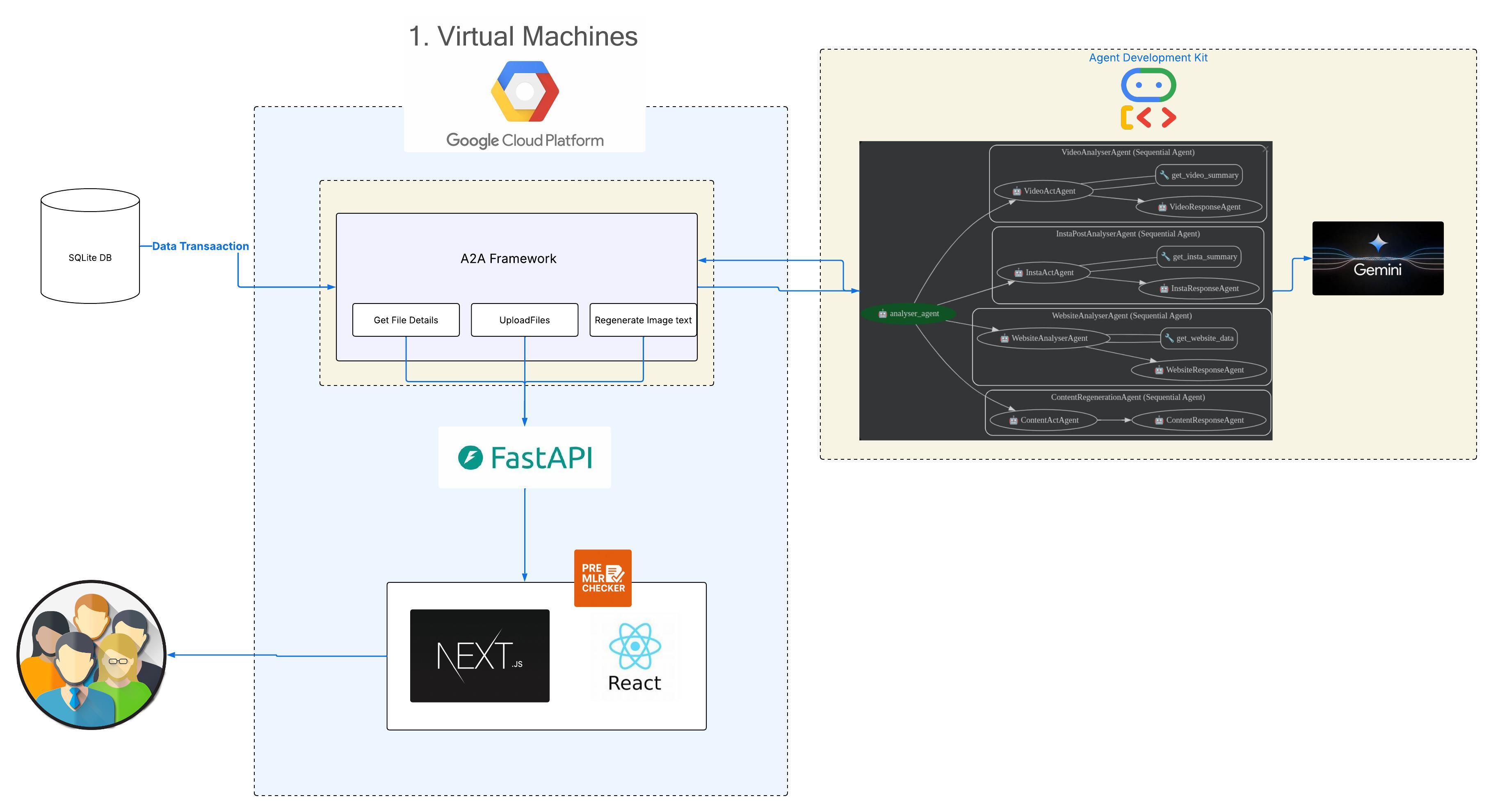
Architecture diagram
-


Pre-MLR Assist: AI-Powered Content Analysis Tool
Inspiration
The inspiration for Pre-MLR Assist came from a real-world challenge in the pharmaceutical and advertising industries. Marketing teams often struggle with ensuring their promotional content complies with strict regulatory guidelines, which can vary across different platforms and media types. Manual review processes are time-consuming, inconsistent, and prone to human error.
We noticed that content creators and marketing teams were spending excessive time on compliance reviews rather than focusing on creative work. This inefficiency sparked the idea for an automated solution that could analyze different types of content against specific guidelines, providing instant feedback and recommendations.
The emergence of powerful AI models like Google's Gemini presented an opportunity to create a tool that could understand and evaluate content across multiple formats - from Instagram posts to video advertisements to websites - with human-like comprehension but machine-like consistency and speed.
What We Learned
Developing Pre-MLR Assist was an incredible learning journey that expanded our knowledge in several areas:
AI Agent Architecture
- Multi-agent systems: We learned how to design and implement a hierarchical agent system with a manager agent coordinating specialized sub-agents.
- Agent communication: We gained insights into effective communication patterns between agents, allowing them to collaborate on complex tasks.
Google ADK (Agent Development Kit)
- Agent configuration: We learned how to configure agents with appropriate models, instructions, and tools.
- Session management: We implemented stateful interactions that maintain context across multiple requests.
- Artifact handling: We developed methods to process and analyze different types of media files.
API Development
- FastAPI implementation: We built a robust API with proper error handling, validation, and documentation.
- Unified endpoint design: We created a smart endpoint that automatically detects content type and routes to the appropriate analysis pipeline.
Database Design
- SQLite integration: We implemented a lightweight but effective database solution for storing analysis results.
- JSON serialization: We learned techniques for storing complex data structures in a relational database.
Docker and Deployment
- Containerization: We packaged the application with all dependencies for consistent deployment across environments.
- Environment configuration: We implemented flexible configuration through environment variables.
How We Built It
Architecture
Pre-MLR Assist follows a modular architecture with these key components:
- API Layer: A FastAPI application that handles HTTP requests, file uploads, and database operations.
Agent System: A hierarchical structure of AI agents:
- Manager Agent: Coordinates the analysis process and formats the final output
- Specialized Sub-agents:
- Instagram Post Analyzer
- Video Ad Analyzer
- Website Analyzer
- Content Generator
Database: SQLite database for storing analysis results with a schema designed for flexible content types, including storage of the actual content for reference and regeneration purposes.
File Storage: Local file system storage for uploaded content with proper organization.
Content Regeneration: A specialized agent for regenerating content based on suggestions to improve compliance.
Development Process
Research Phase:
- Studied Google ADK documentation and examples
- Researched common compliance guidelines for different media types
- Explored effective agent architectures for content analysis
Core Development:
- Implemented the base agent system with the manager agent and sub-agents
- Developed specialized tools for each agent to analyze different content types
- Created the database schema and implementation
API Development:
- Built the FastAPI application with proper routing and error handling
- Implemented the unified analysis endpoint with content type detection
- Added endpoints for retrieving and managing analysis results
- Created a content regeneration endpoint that takes original content and suggestions to produce improved content
Integration and Testing:
- Connected all components and tested with various content types
- Refined agent prompts and tools based on analysis results
- Optimized performance and resource usage
Containerization:
- Created Docker configuration for easy deployment
- Implemented environment variable configuration
Technologies Used
- Python 3.11+: Core programming language
- Google ADK: Agent Development Kit for creating and managing AI agents
- FastAPI: Modern, high-performance web framework for building APIs
- SQLite: Lightweight database for storing analysis results
- Docker: Containerization for consistent deployment
- Gemini 2.0 Flash: AI model powering the content analysis
Challenges Faced
Technical Challenges
Multi-modal Content Analysis: One of the biggest challenges was creating a system that could effectively analyze different types of content - text, images, videos, and websites - with a consistent approach. Each media type required specialized processing techniques and evaluation criteria.
Solution: We implemented a modular agent architecture with specialized sub-agents for each content type, coordinated by a manager agent that provides a unified interface.
Context Management:
- Maintaining context across the analysis pipeline was difficult, especially when dealing with large files and complex guidelines.
Solution: We implemented a robust context management system using ADK's session service, ensuring that all relevant information was available throughout the analysis process.
Implementation Challenges
Guideline Interpretation:
- Translating human-readable guidelines into structured criteria that AI agents could evaluate was challenging.
Solution: We developed a guideline parsing system that extracts key requirements and converts them into evaluation criteria for the agents.
Consistent Scoring:
- Ensuring consistent scoring across different content types and guidelines required careful calibration.
Solution: We implemented a standardized scoring system with weighted criteria based on guideline importance and content relevance.
Error Handling:
- Robust error handling was essential for a system processing user-uploaded content of various types and qualities.
Solution: We implemented comprehensive error handling throughout the application, with detailed logging and user-friendly error messages.
Future Improvements
While Pre-MLR Assist is already a powerful tool, there are several areas for future enhancement:
Expanded Content Types: Add support for additional content types like social media stories, podcasts, and interactive content.
Guideline Management: Develop a user interface for creating, editing, and managing guidelines.
Explanation System: Enhance the explanation capabilities to provide more detailed reasoning for compliance decisions.
Real-time Analysis: Implement websocket connections for real-time feedback during content creation.
Version Control for Content: Implement a version control system for tracking changes to content through multiple regeneration cycles.
Conclusion
Building Pre-MLR Assist has been a rewarding journey that combined cutting-edge AI technology with practical business needs. The project demonstrates how AI agents can be leveraged to solve complex problems in content compliance and regulation.
By automating the compliance review process, Pre-MLR Assist not only saves time and reduces errors but also enables marketing teams to focus on what they do best - creating engaging content. We're excited to continue developing this tool and exploring new applications for AI agent systems in the marketing and compliance space.











Log in or sign up for Devpost to join the conversation.