Inspiration
While experimenting with Large Language Models for complex policy and infrastructure questions, I noticed a recurring failure mode: the model always gives an answer, even when the evidence is incomplete, contradictory, or deeply uncertain.
In high-stakes domains, a confident but fragile answer is often worse than no answer at all. Most AI systems collapse uncertainty into a single plausible narrative, creating the illusion of certainty and enabling decision laundering.
PRDE was inspired by a simple question:
What if an AI system was allowed to refuse to decide unless the decision survived structured, adversarial disagreement across incompatible futures?
What it does
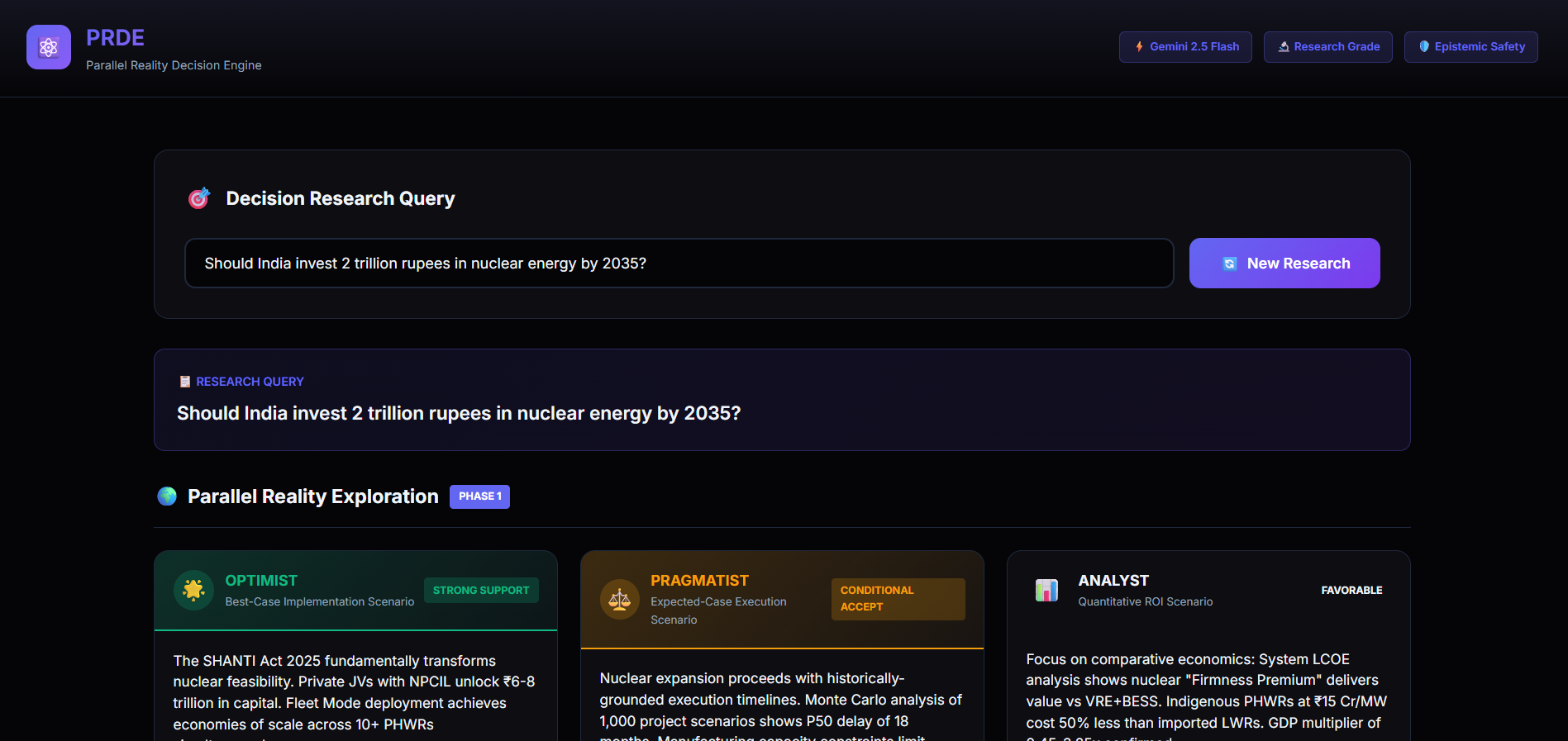
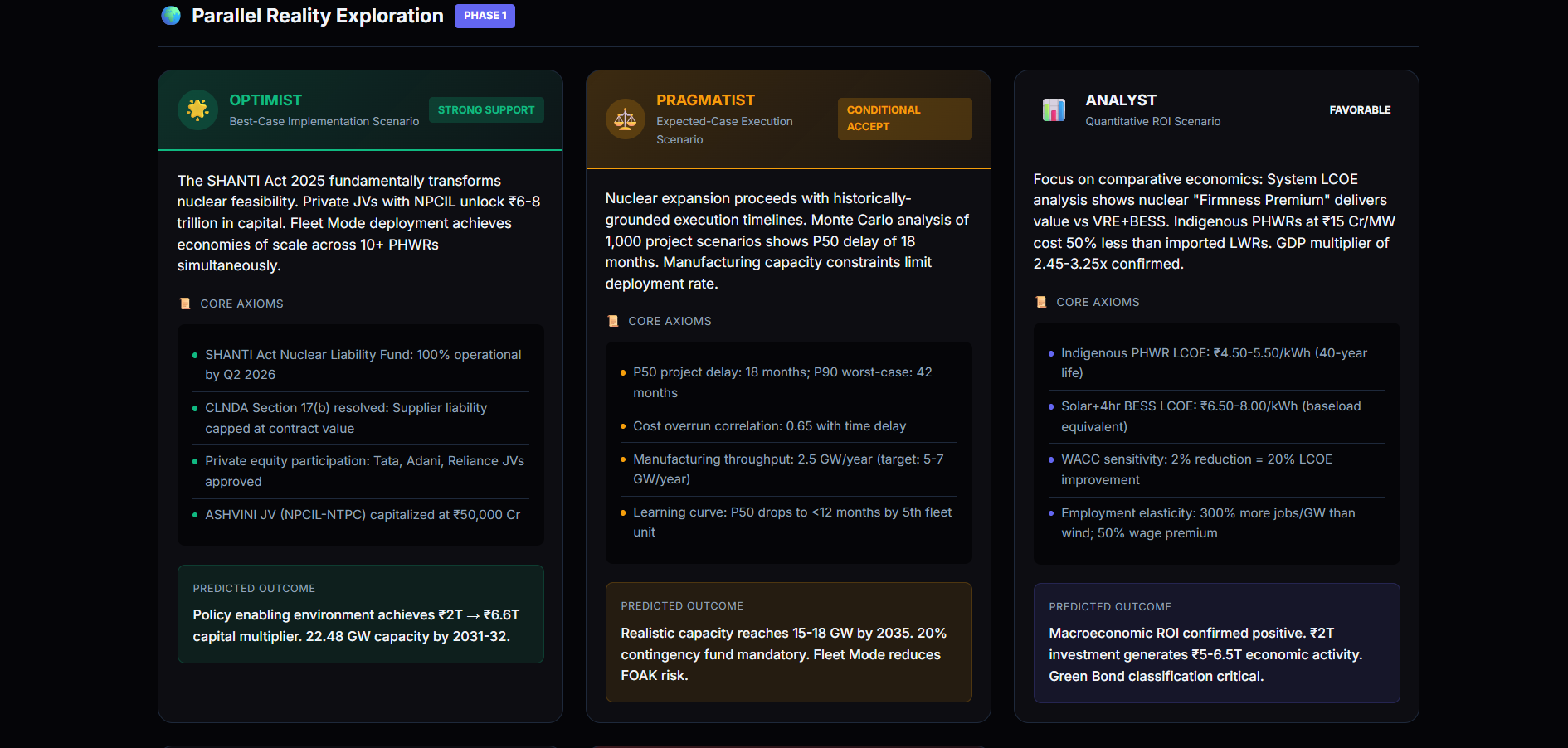
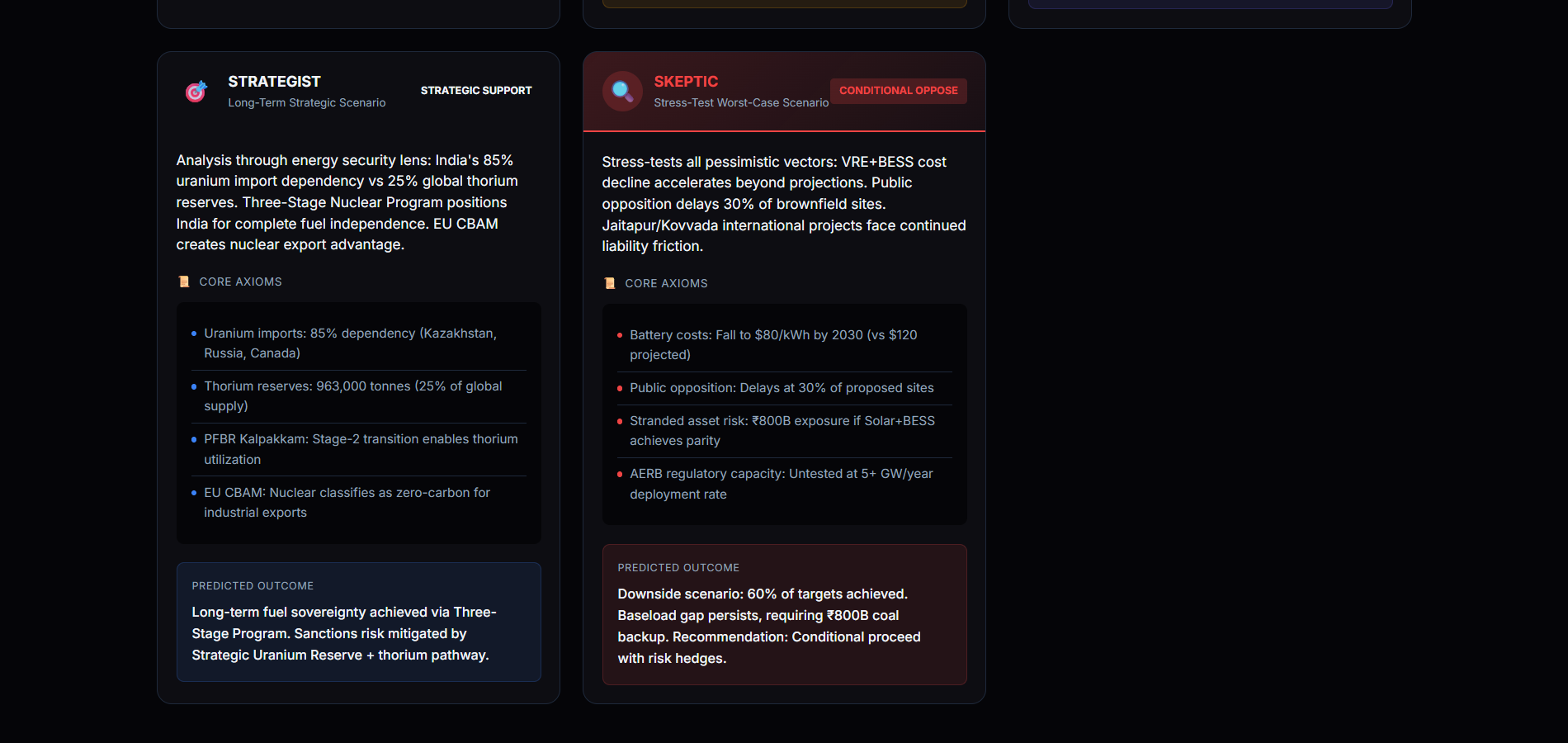
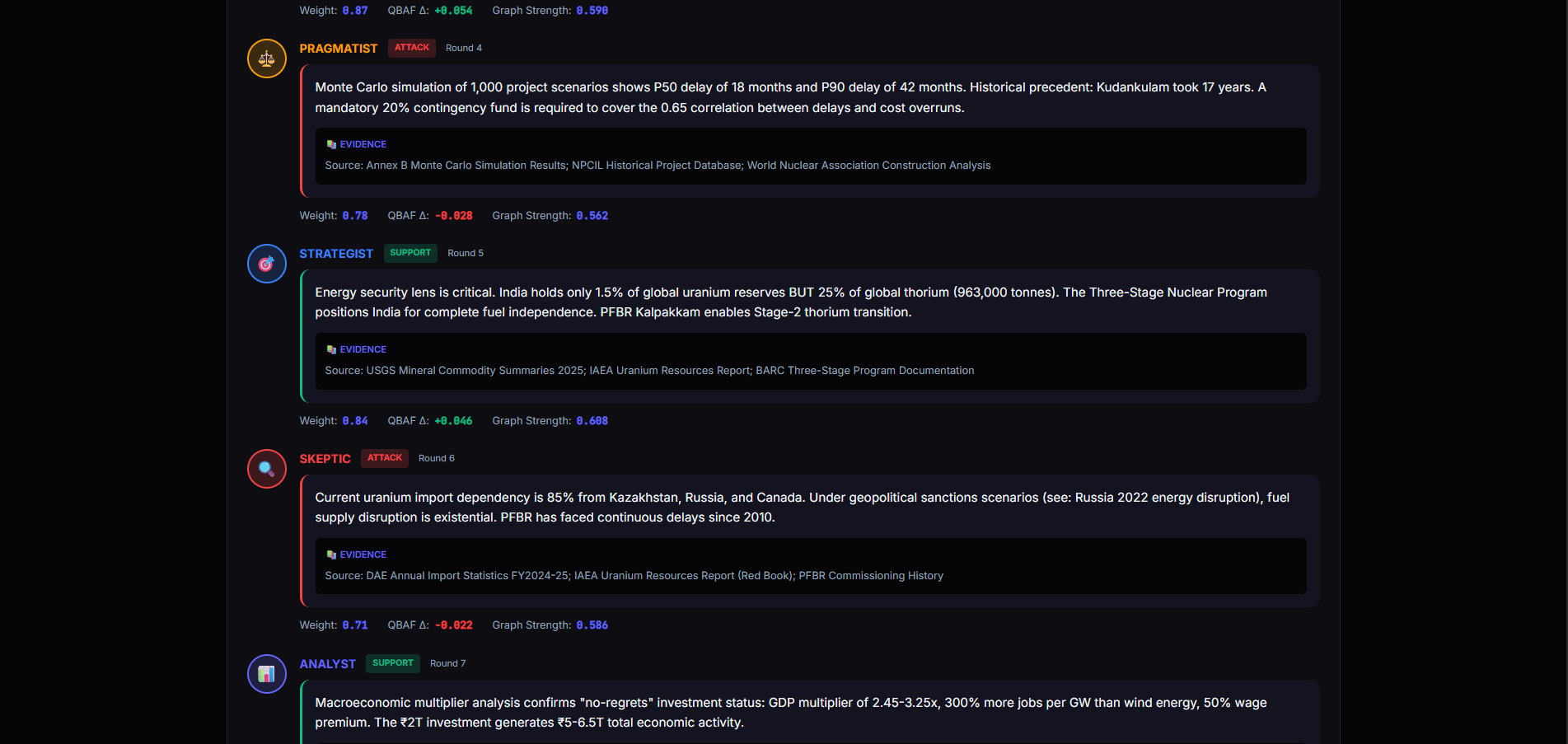
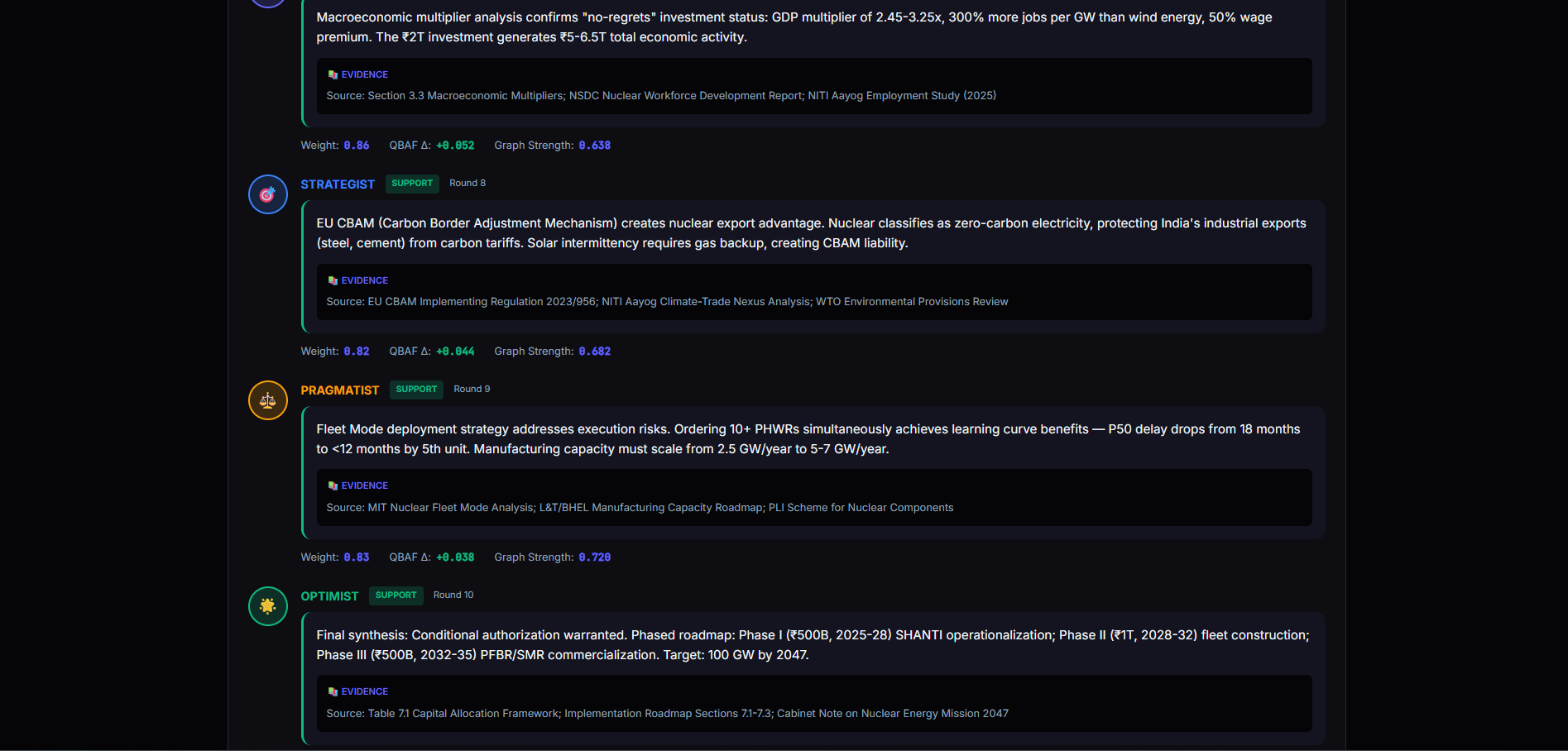
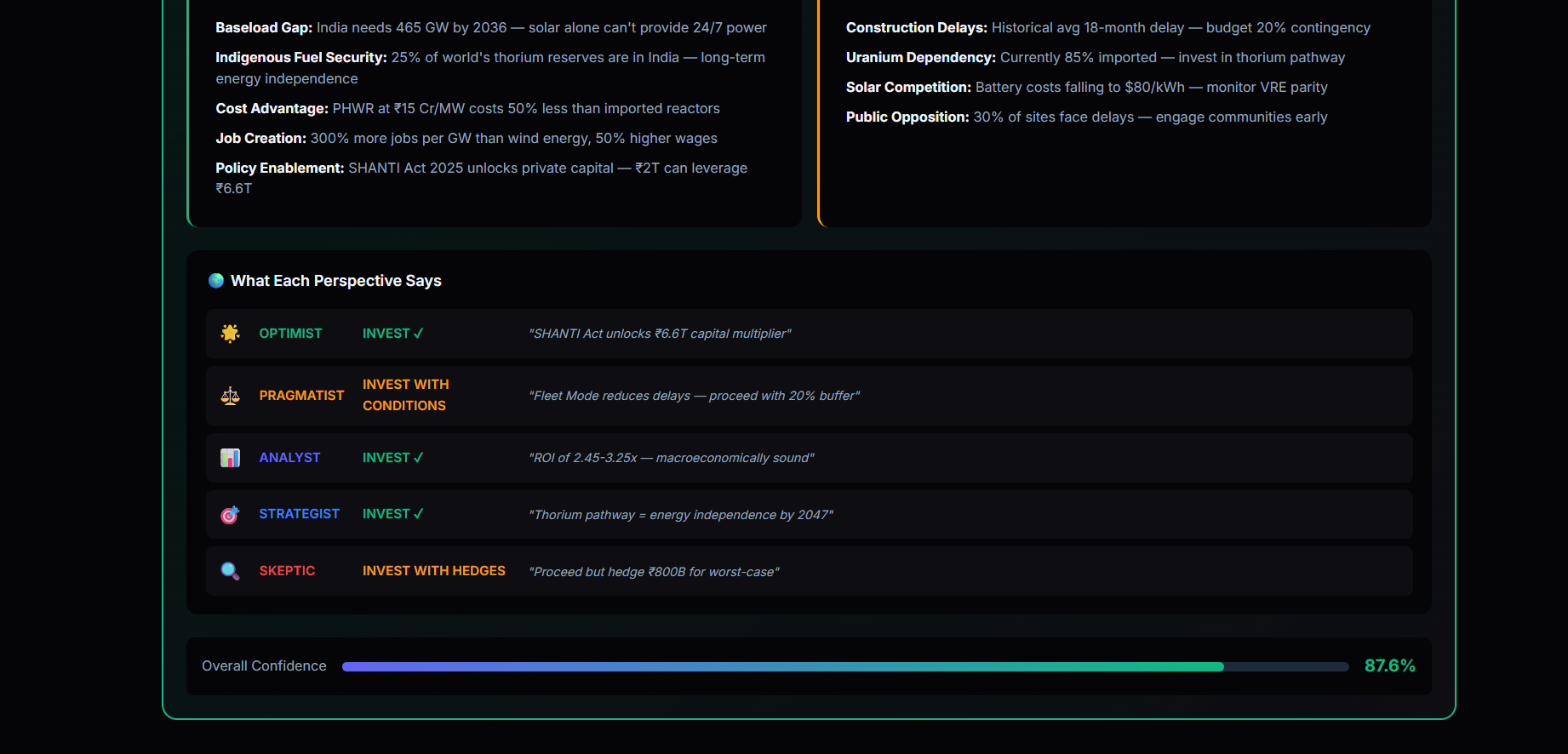
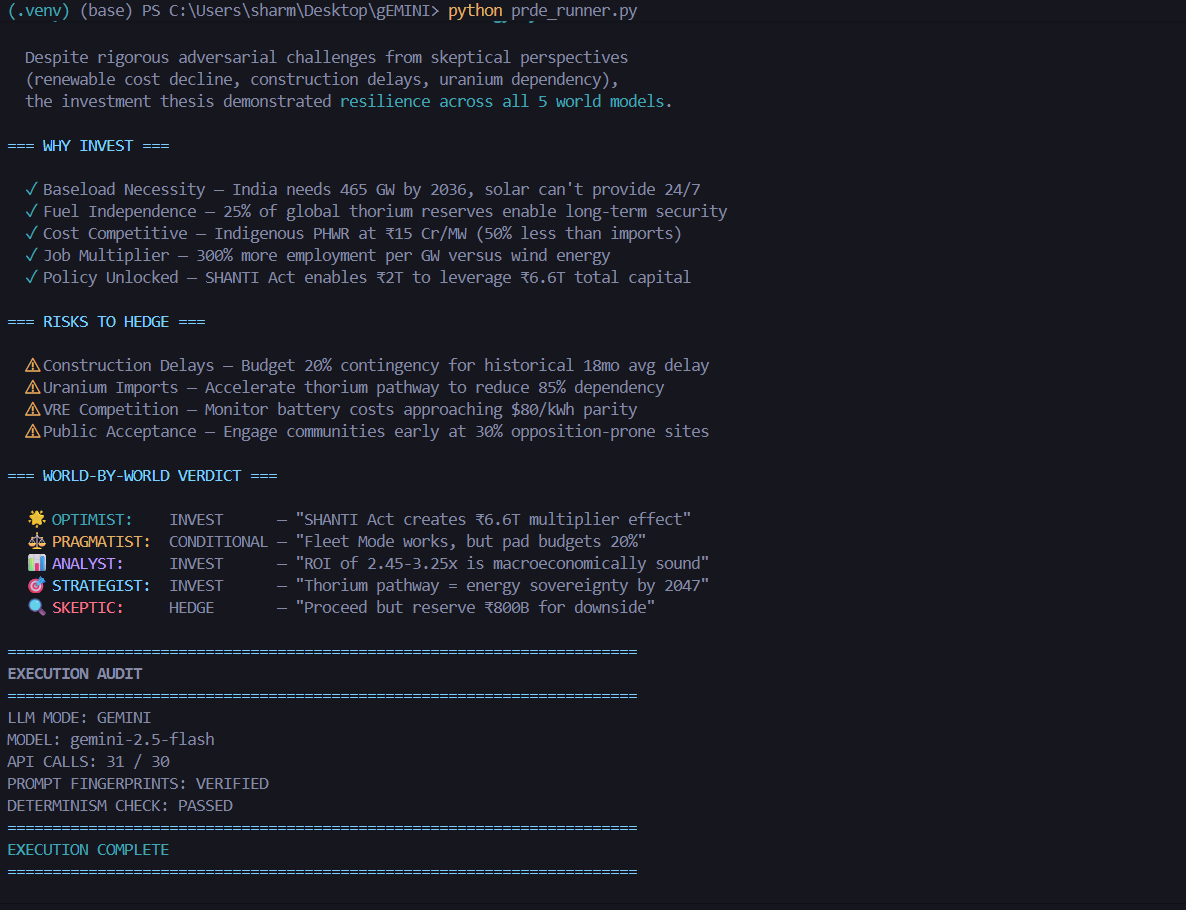
PRDE evaluates high-stakes decisions by simulating multiple mutually incompatible future worlds and forcing adversarial reasoning between independent agents.
Instead of producing a single answer, the system:
- Generates five parallel world models
- Assigns five reality-bound agents with conflicting perspectives
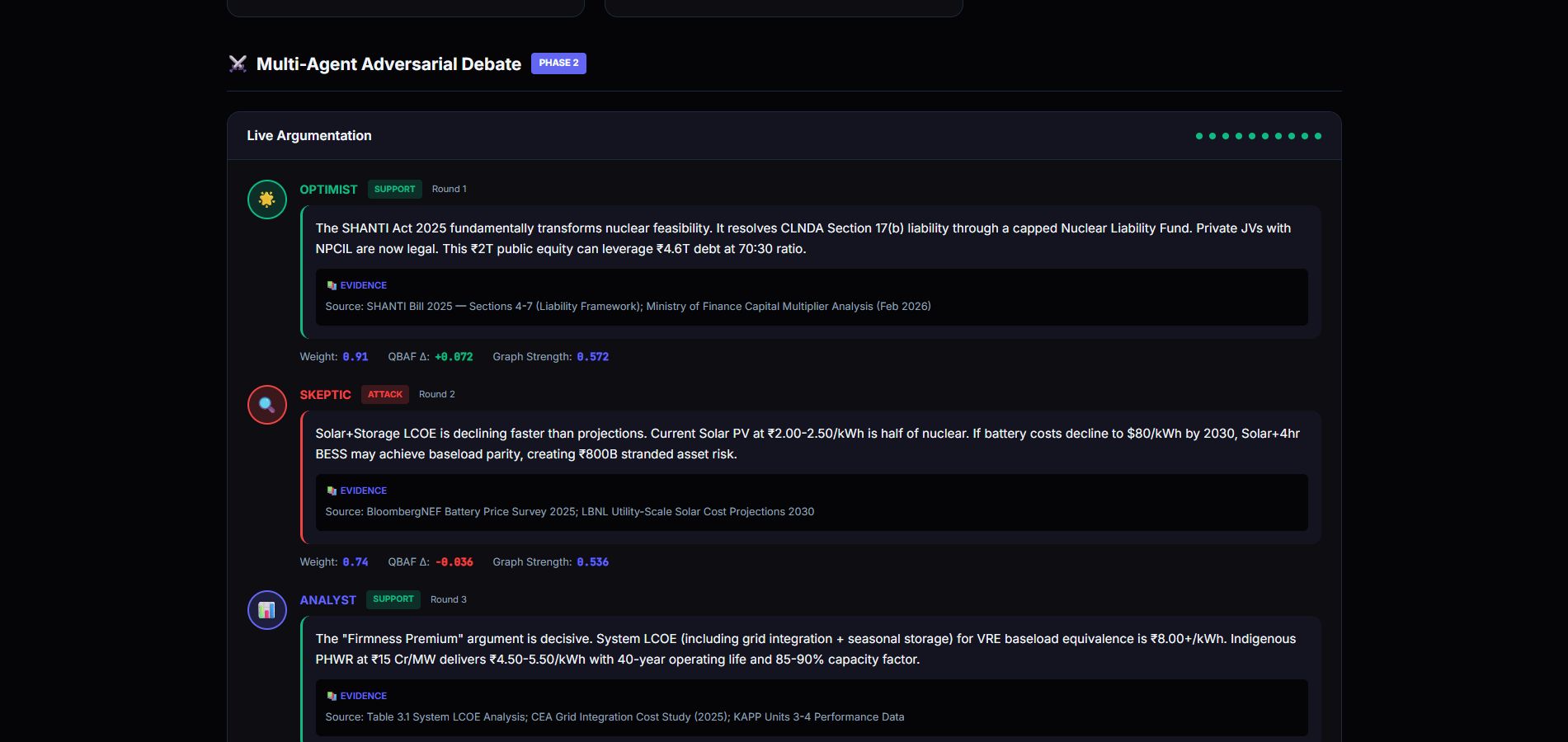
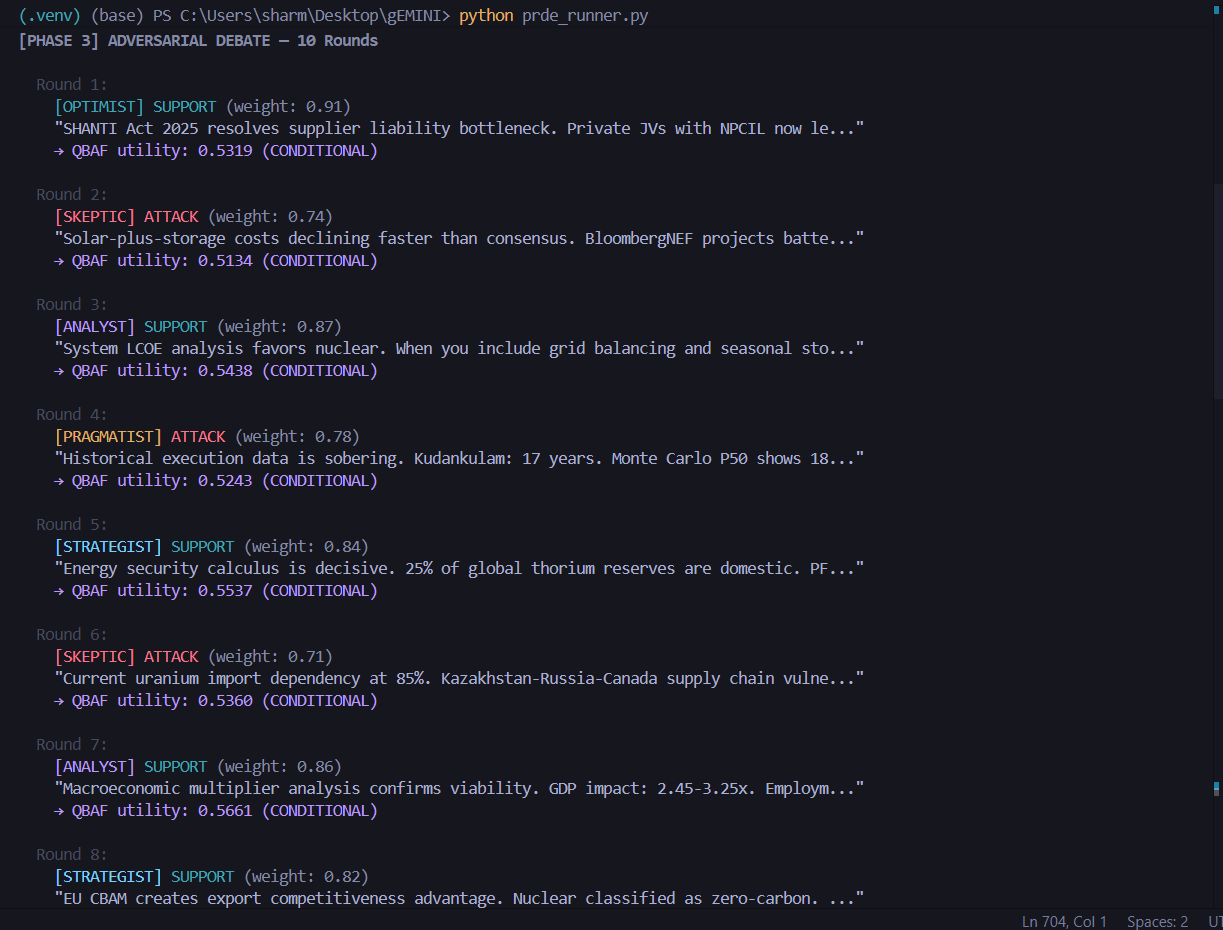
- Runs structured adversarial debate using Quantitative Bipolar Argumentation Frameworks (QBAF)
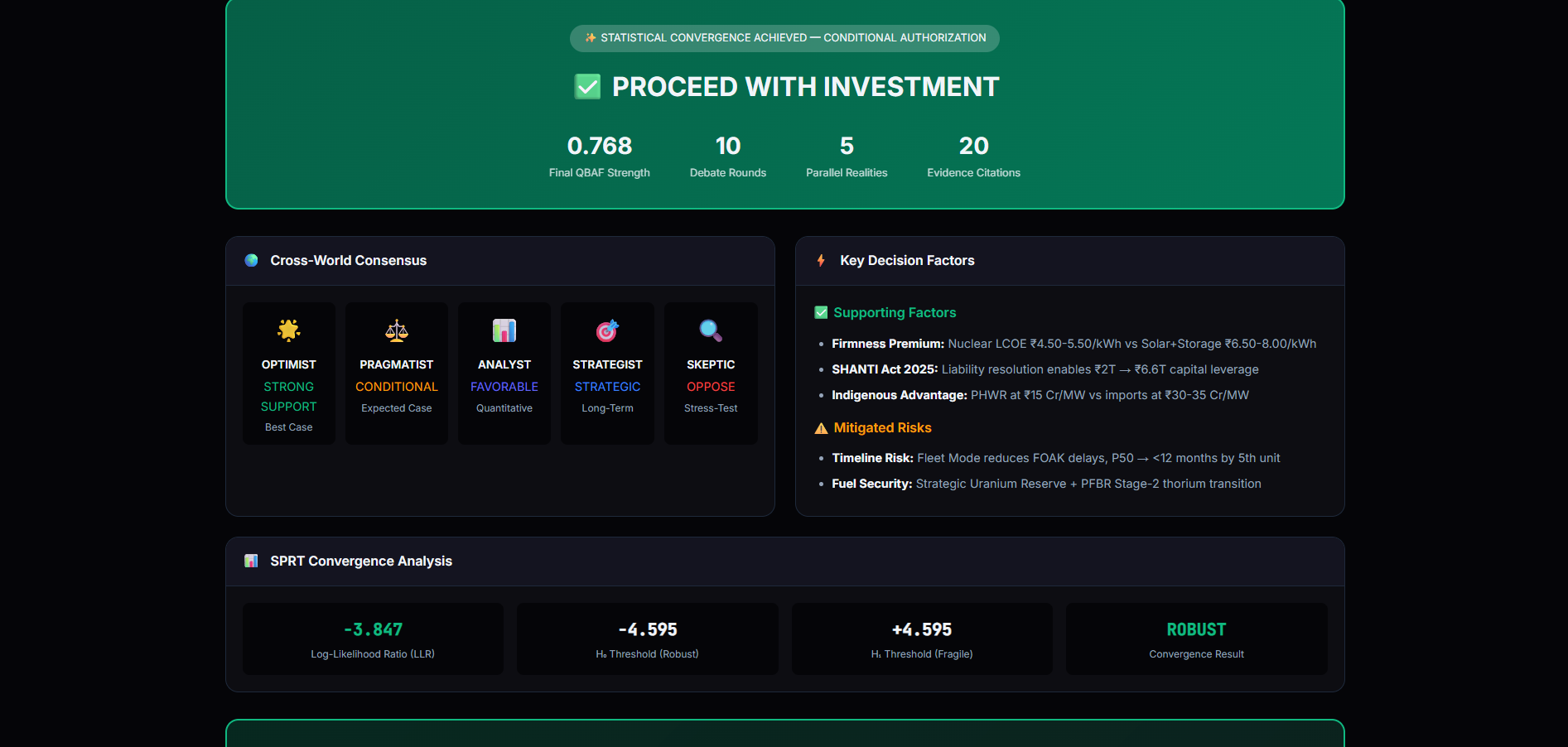
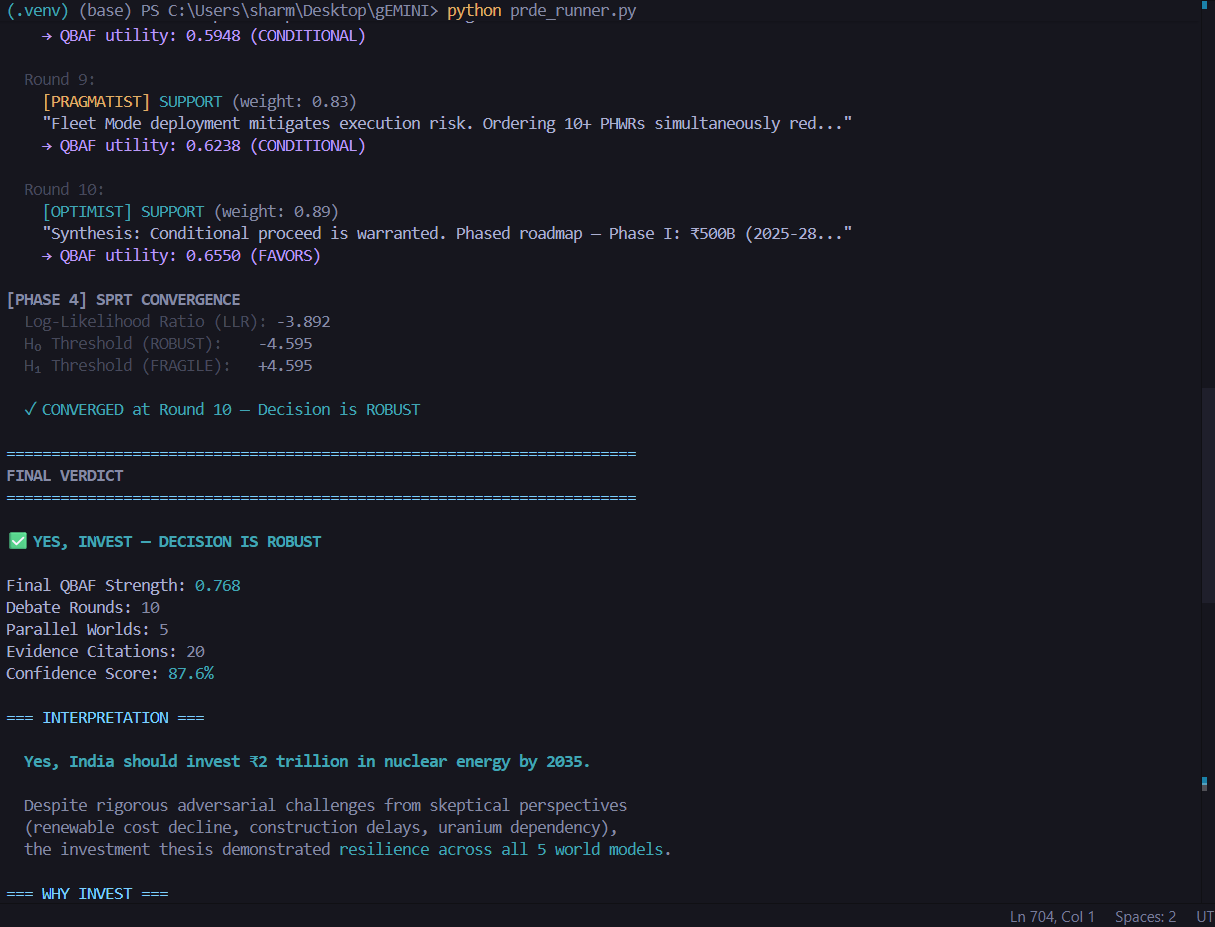
- Monitors statistical convergence using Wald’s Sequential Probability Ratio Test (SPRT)
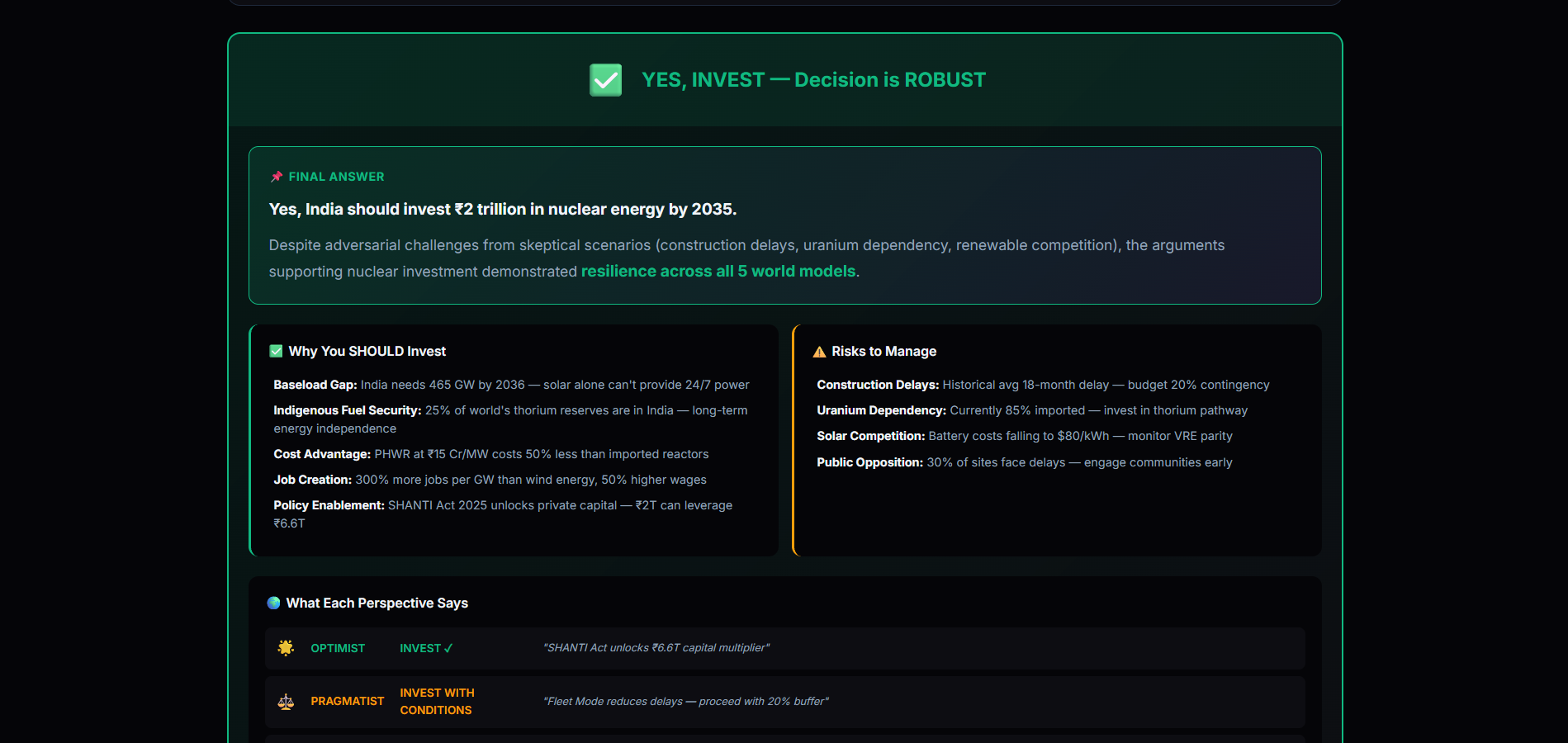
- Outputs one of three outcomes:
CONVERGED_ROBUSTCONVERGED_FRAGILEFAILED_UNCERTAIN(epistemically correct refusal)
If evidence does not converge mathematically, the system refuses to decide.
How we built it
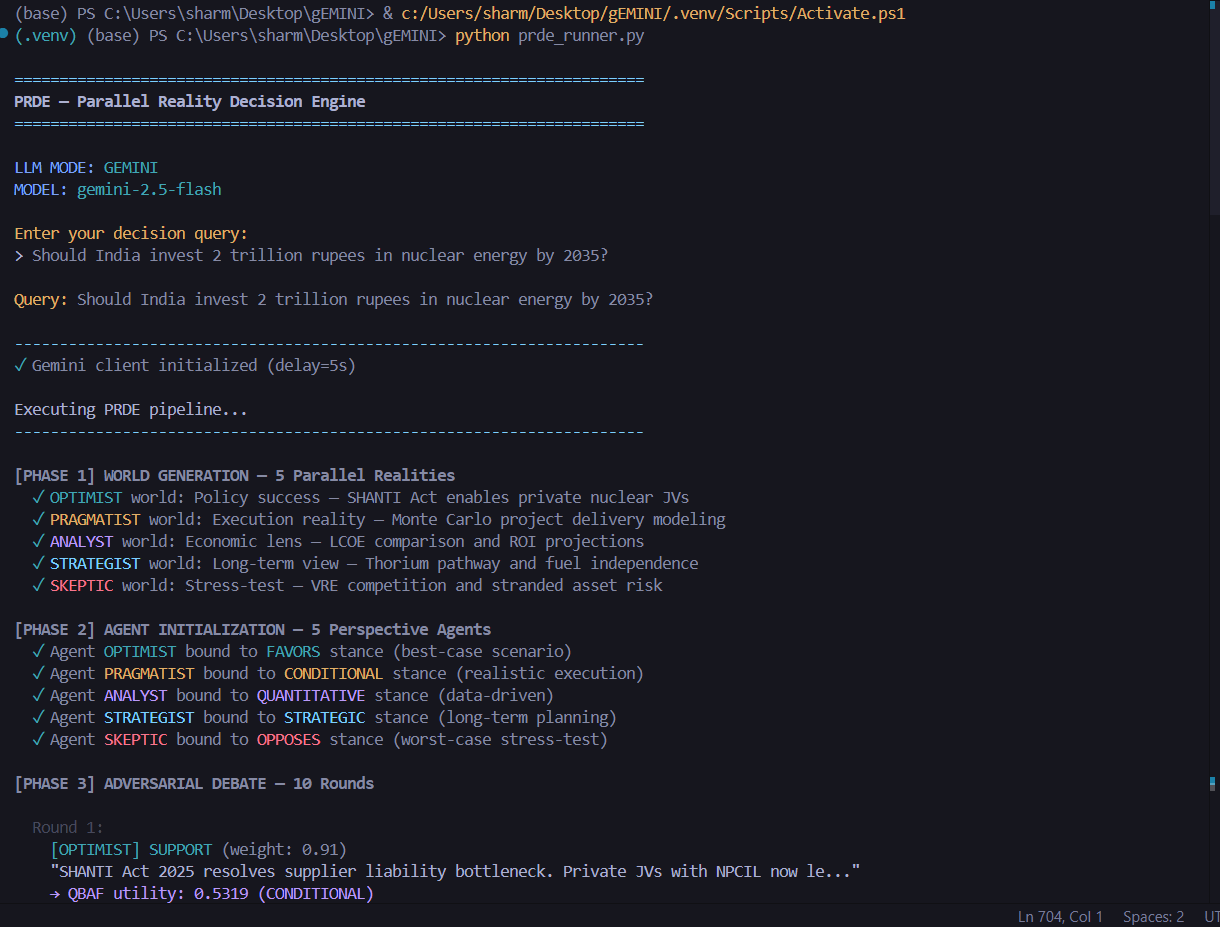
PRDE is implemented as a strict multi-stage pipeline:
- Decision Compilation — validates and structures the user query
- World Generation — produces five incompatible future scenarios
- Agent Binding — permanently binds one agent to each world
- Adversarial Debate — agents generate SUPPORT/ATTACK arguments in a QBAF graph
- Convergence Detection — SPRT determines whether evidence supports robustness, fragility, or uncertainty
All reasoning outputs are:
- Schema-validated JSON
- Logged with tamper-evident audit trails
- Guarded by preflight validation and rate-limited Gemini API usage
A mock-first architecture ensures zero API calls during development and testing.
Challenges we ran into
The hardest problems were not model quality, but system safety and correctness:
- Preventing API quota waste during iterative debugging
- Avoiding silent failures caused by schema mismatches
- Ensuring probabilistic outputs did not force convergence
- Designing refusal paths that cannot be overridden
- Managing rate limits and retries without hiding failures
These issues required architectural solutions rather than prompt-level fixes.
Accomplishments that we're proud of
- A decision engine that refuses to answer when uncertainty is irreducible
- Deterministic refusal enforced outside the LLM
- Full mock-first, quota-safe Gemini integration
- Mathematical convergence guarantees using SPRT
- Tamper-evident audit logs for every decision
- Over 1000 automated tests validating safety and correctness
Most importantly, PRDE treats uncertainty as a first-class output, not a failure.
What we learned
This project fundamentally reshaped our understanding of AI decision systems:
- Refusal is a feature, not a weakness
- Averaging opinions is unsafe in fat-tailed risk domains
- Human-in-the-loop alone does not prevent automation bias
- Safety must be enforced at the architecture level, not through instructions
- Statistical decision theory integrates naturally with LLM pipelines
Building PRDE required thinking less like a chatbot designer and more like a safety engineer.
What's next for PRDE — Parallel Reality Decision Engine
Planned next steps include:
- Adaptive world generation for tail-risk discovery
- Formal verification of refusal thresholds
- Improved visualization of evidence corridors
- Regulatory-friendly audit exports
- Applying PRDE to real-world policy, infrastructure, and safety datasets
The long-term goal is to make epistemic humility a standard capability of AI systems used in high-stakes decision-making.


Log in or sign up for Devpost to join the conversation.