
Inspiration
Every product manager knows the feeling: you've spent days on a PRD, you're confident in it, and then the review meeting happens. The engineering lead asks why the edge cases aren't specced. The designer points out there's no empty state. Sales says they can't tell who the product is actually for. Finance wants to know what the success metric is.
None of these are hard questions. They're predictable questions. Every PRD fails in the same four places — and yet we still walk into review meetings unprepared for them.
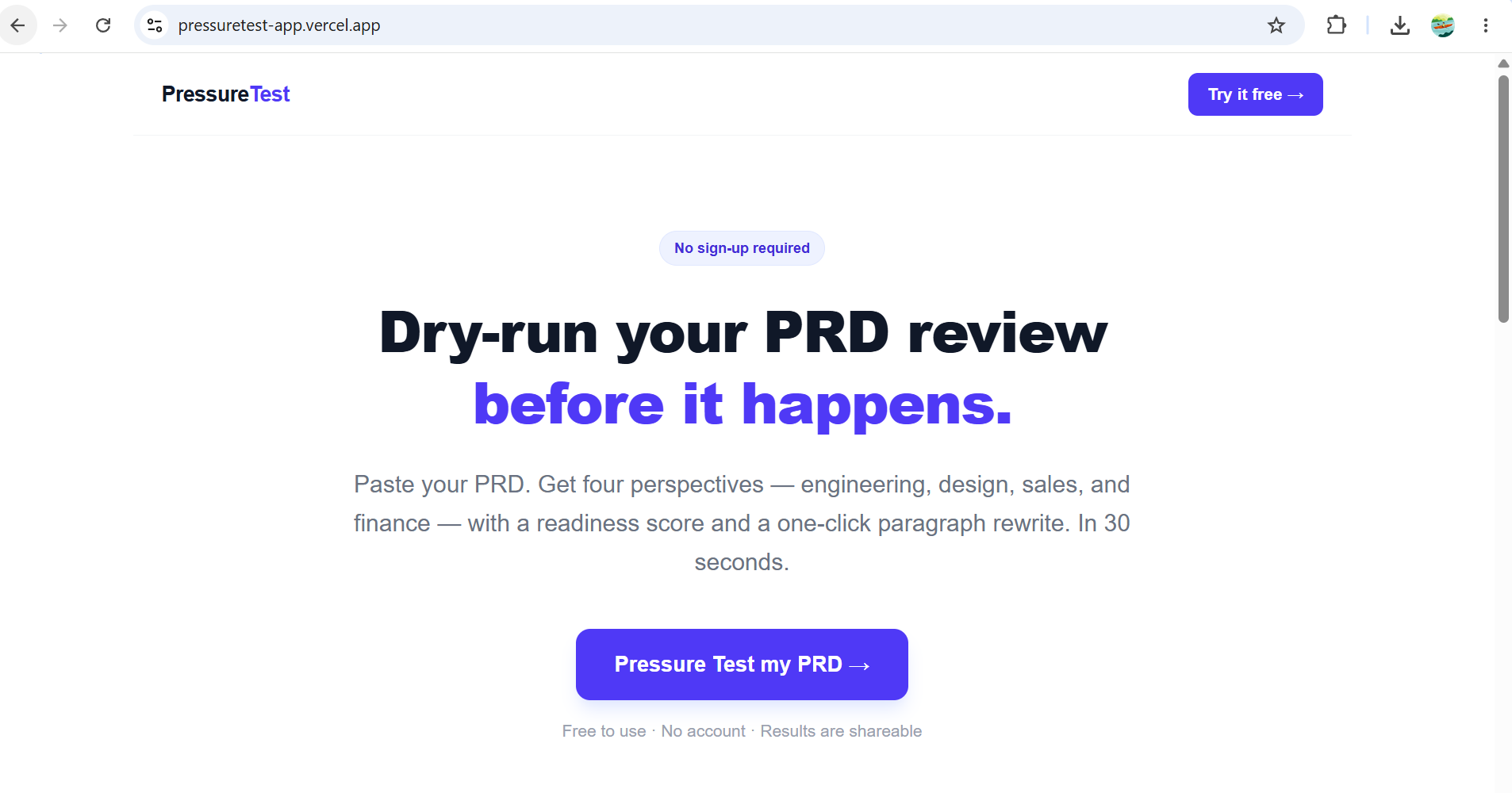
PRD Pressure Test exists to fix that.
What it does
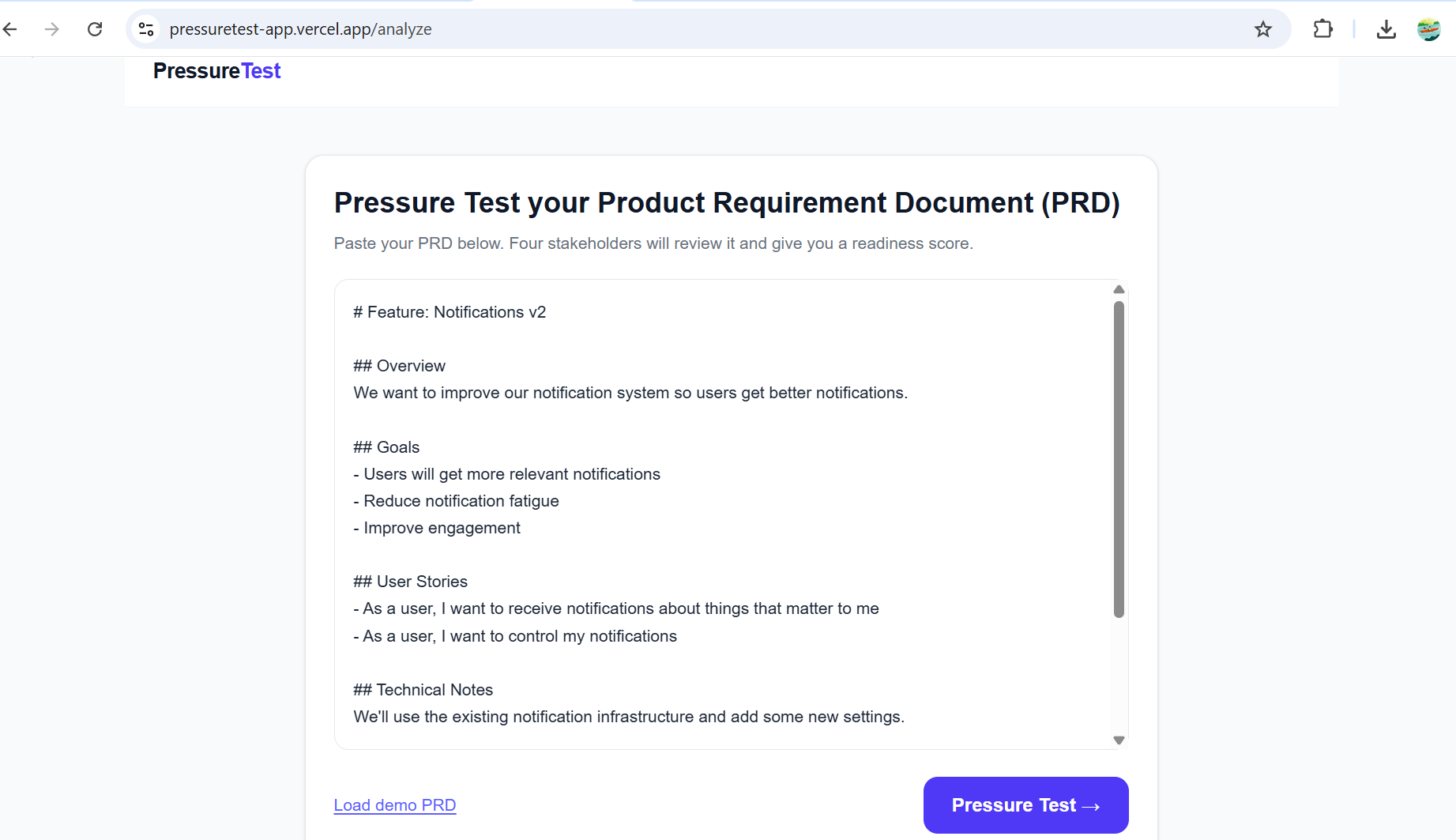
Paste any PRD. In under 30 seconds, four AI stakeholders — an Engineering Lead, a Designer, a Sales Lead, and a CFO — review it in parallel and each return:
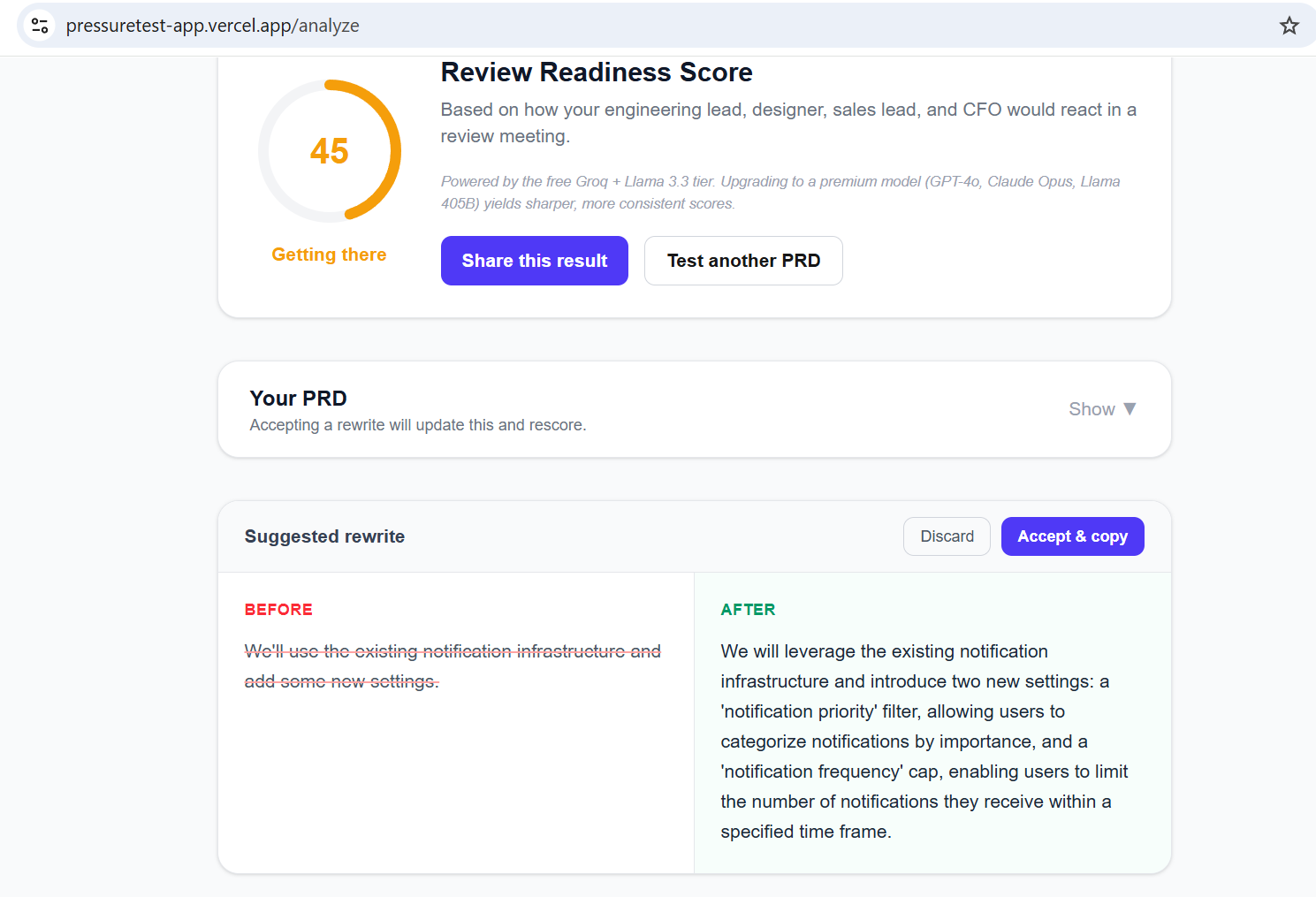
A readiness score (0–100) Three specific bullets (red / yellow / green severity) quoting the exact paragraph that triggered the concern. The verbatim weakest paragraph from your document.
You get an overall Review Readiness Score, a per-persona breakdown, and — if something is flagged red — a one-click rewrite. Accept it, and the PRD is updated and rescored live. When you're happy with the result, a shareable permalink encodes the full analysis in the URL so you can send it to your co-author.
No sign-up. No account. Free to use
How I built it
- Next.js 16 App Router with TypeScript and Tailwind CSS
- Groq + Llama 3.3 70B for parallel persona analysis and paragraph rewrites — chosen because it's free, fast (sub-second), and capable enough to prove the concept end-to-end
- Stateless architecture — no database. Share permalinks base64url-encode the entire analysis result into the URL itself
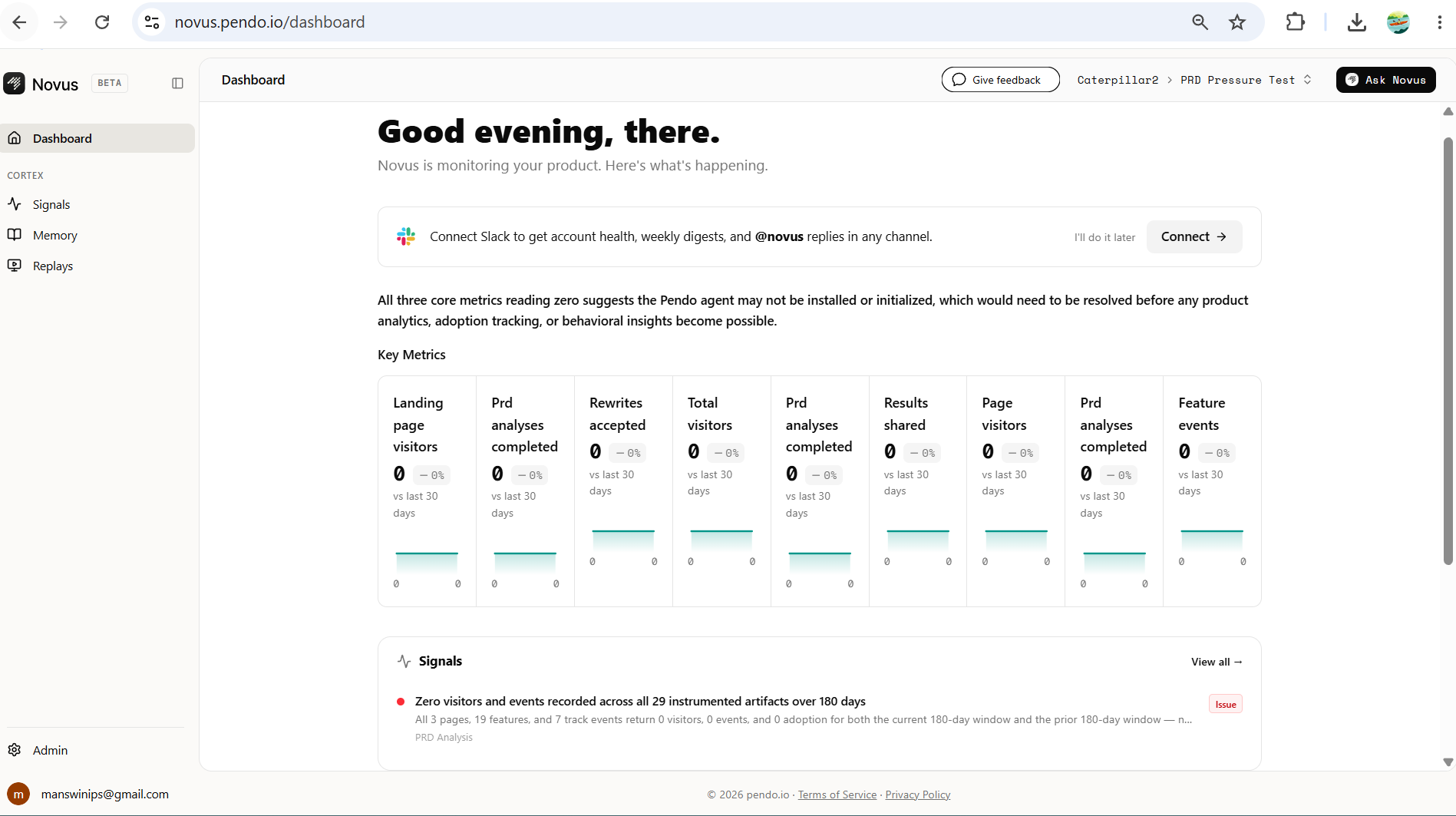
- Novus (Pendo) for product analytics and session tracking
- Deployed on Vercel with auto-deploy on push
Challenges I ran into
Getting four LLM personas to each return a consistent, structured JSON score — without hallucinating field names or collapsing into prose — required careful prompt engineering and strict json_object response format enforcement. Scoring variance across identical inputs (even at temperature 0) meant we had to guard against spurious re-scores when a paragraph replacement silently failed.
The stateless share URL was also non-trivial: Vercel serverless functions don't share a filesystem, so a file-based result store simply didn't work in production. Moving the entire result into the URL as a base64url payload solved it cleanly.
Accomplishments that I'm proud of
- The rewrite flow — paste PRD → see score → click a red bullet → get a side-by-side diff → accept → watch score update — works end-to-end in well under a minute
- Stateless shareable permalinks: the URL is the result, no backend storage required
The "Why not ChatGPT?" answer is actually demonstrable: four named roles, a quantified score, verbatim quotes from your doc, and a persistent shareable link are all things ChatGPT chat doesn't give you
What I learned
Prompt structure matters more than model size for structured output. A smaller, faster model with tight output schema constraints beats a larger model with loose prompting every time for this kind of task. I also learned that the UX of "accept a suggestion" is deceptively hard — knowing whether the replacement actually succeeded, and not re-scoring when it didn't, required more defensive logic than expected.
What's next for PRD Pressure Test
- Upgrade to a premium model endpoint (GPT-4o or Claude Opus) for sharper, more consistent scores — the current free Groq tier is a proof-of-concept
- Customizable personas: add Security, Legal, or Customer Support stakeholders based on your product type
- Team mode: invite your actual stakeholders to annotate the shared result before the meeting
- Inline editing: accept rewrites directly into the PRD panel without copy-pasting
Built With
- css
- groq
- llama-3.3-70b
- next.js
- novus
- react
- tailwind
- typescript
- vercel

Log in or sign up for Devpost to join the conversation.