-
-
brev hosting
-
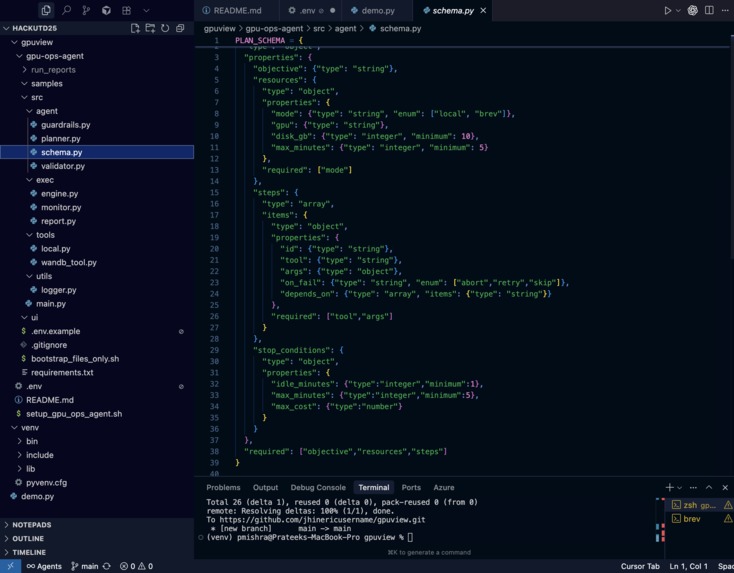
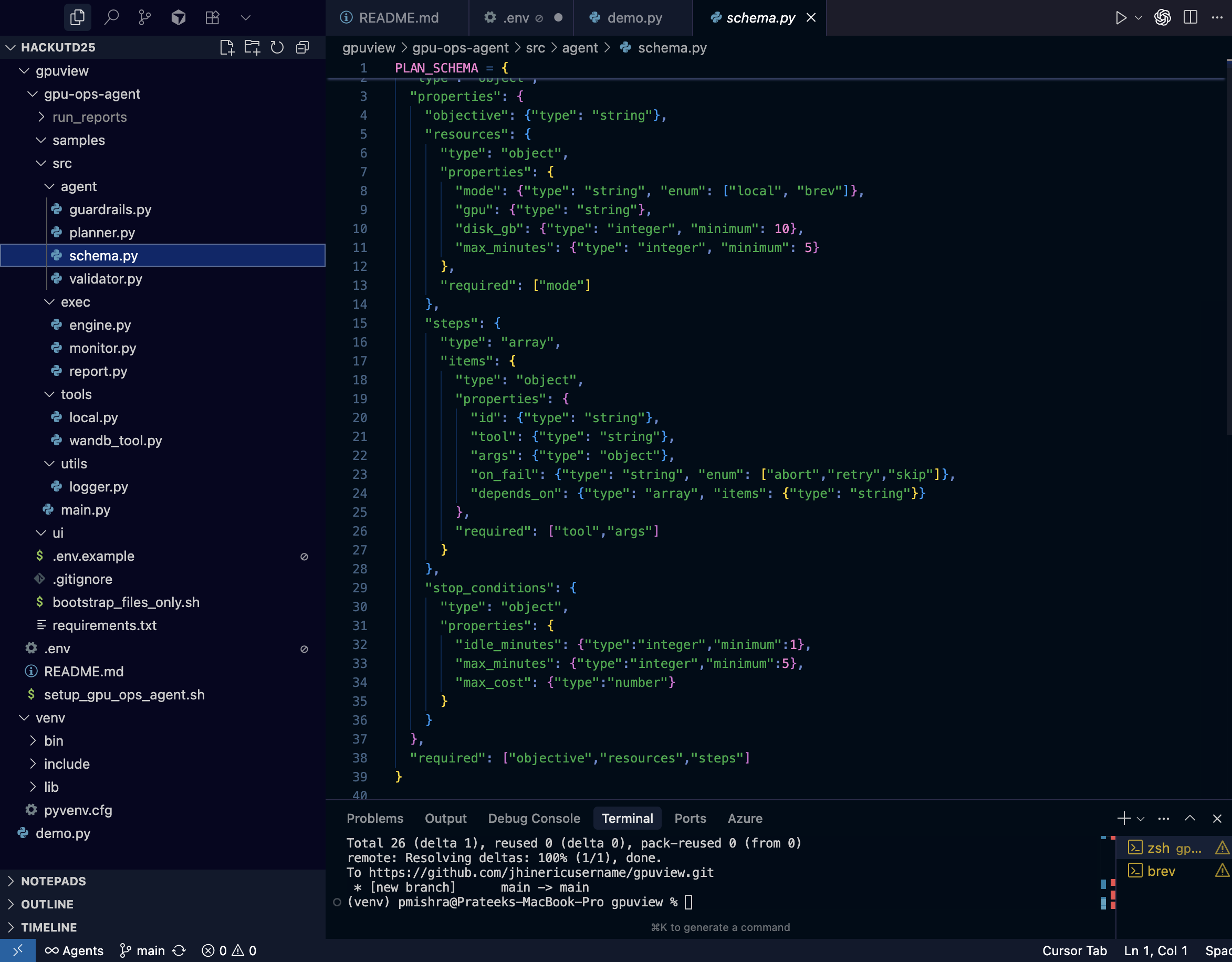
schema
-
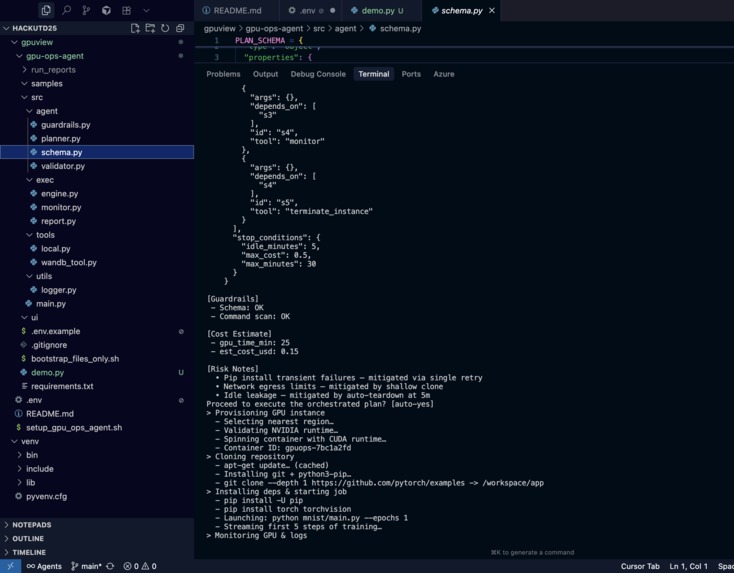
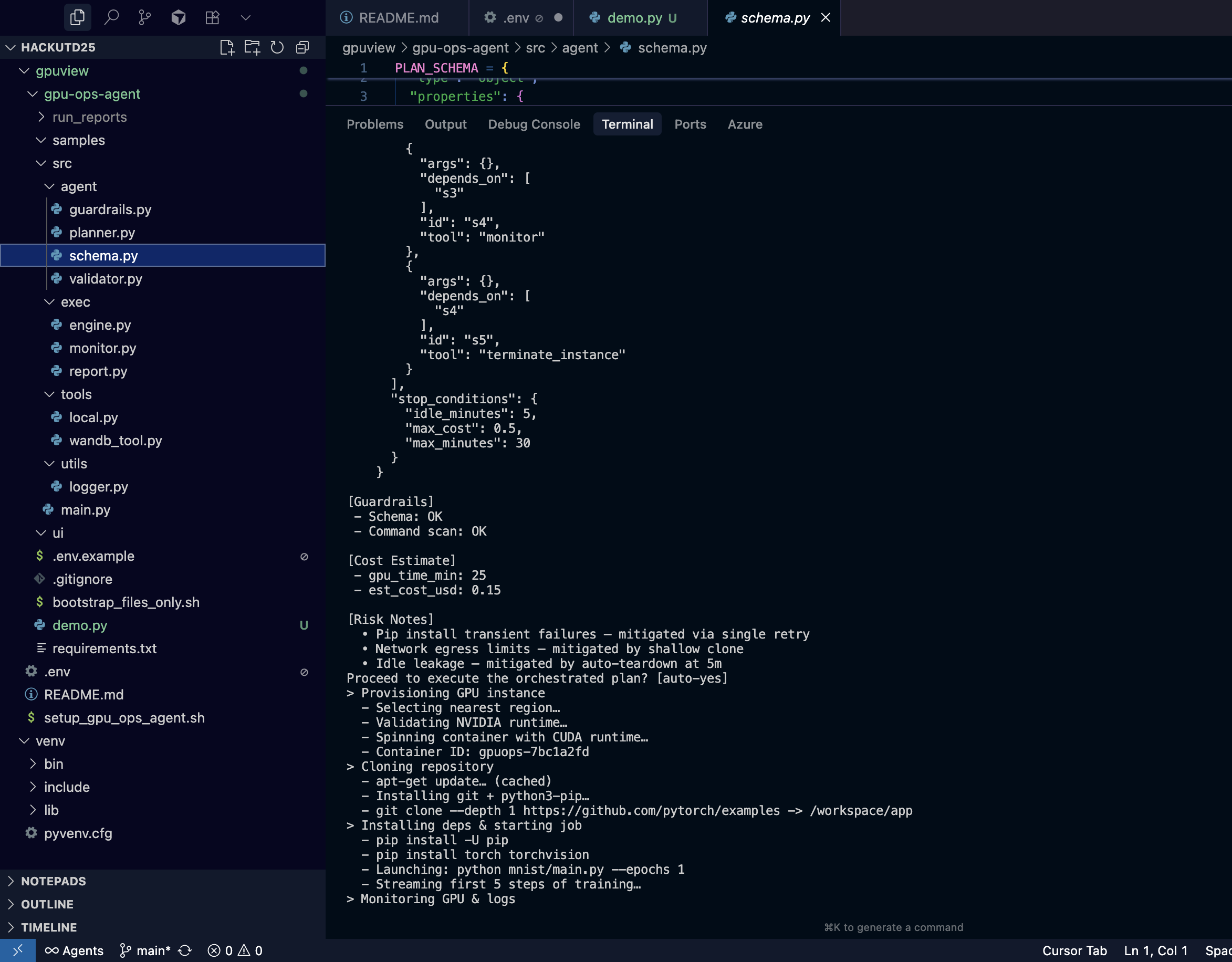
test run
🧠 GPU Ops Agent — Autonomous GPU Workflow Orchestrator
💡 Inspiration
Most “AI agents” today can talk — but can’t act. I wanted to build something that actually does work: a system that can plan, launch, monitor, and tear down GPU workloads autonomously.
As a solo builder, I’ve worked on plenty of AI infrastructure setups — Docker configs, GPU jobs, dependency hell, idle-cost leaks — and I realized most of that can be automated. So this project was born: an agent that uses reasoning + tool use to manage GPU workflows like a human DevOps engineer.
The HackUTD NVIDIA challenge — “AI that takes action, not just responds” — was the perfect spark.
⚙️ What It Does
GPU Ops Agent is a Nemotron-powered orchestrator that can:
- Parse a natural language objective (e.g. “Train MNIST for one epoch, teardown after 5 minutes idle”)
- Plan multi-step GPU workflows:
- Provision container / instance
- Clone and install code
- Execute and monitor the job
- Auto-teardown based on idle or time caps
- Provision container / instance
- Apply guardrails for cost, safety, and reproducibility
- Generate structured reports and artifacts at the end of each run
Everything is modular — each “tool” (like create_instance, run_command, or monitor) can be extended for other cloud backends or APIs.
🏗️ How I Built It
This was a solo project built end-to-end in ~24 hours. I wanted to make it easy for anyone to train models and use GPUs by focusing on the task and not specifcs.
Stack & Tools
- NVIDIA Nemotron (Meta Llama 3.1 - 70B Instruct) for planning & self-critique reasoning
- Python 3.10 +
openaicompatible client - Rich for UI + terminal animations
- Docker (simulated locally for demo) for container lifecycle orchestration
- Jinja2 for runtime report generation
- Pydantic / JSONSchema for plan validation
- Colorama + Click for interactive CLI demo
Architecture The system is split into modular layers:
agent/→ planning, validation, and guardrailsexec/→ orchestrator + monitor + reportingtools/→ adapters for Docker, WandB, or APIsdemo.py→ the showcase script for judges, simulating a full run with logs and GPU telemetry
Mathematically, the planner uses a structured loop:
$$ \text{Objective} \rightarrow \text{Plan} \rightarrow \text{Critic}(Plan) \rightarrow \text{Validated Execution} $$
🚧 Challenges I Faced
1. Running GPU orchestration solo:
Without access to multi-GPU or containerized environments locally, I had to simulate orchestration and GPU telemetry while keeping the logic realistic enough to show to judges.
2. Making it visually engaging:
Most backend demos are invisible. I wanted to make the command-line tell a story — a theatrical “thinking + acting” flow that judges could feel.
3. Designing safe autonomy:
I had to think deeply about how an AI agent might go wrong — infinite loops, rm -rf risks, runaway costs. I built JSON guardrails and regex filters to block unsafe commands and limit runtime.
4. Working entirely solo:
Every subsystem — planning, validation, orchestration, visualization — had to be designed, coded, tested, and refined alone. The hardest part wasn’t code — it was context switching between roles (AI engineer, DevOps, designer, storyteller).
📚 What I Learned
- How to structure agentic AI systems around reasoning + action, not just chat.
- How to simulate “LLM planning and execution” safely with structured schemas.
- Practical insight into GPU lifecycle automation — from provisioning to idle teardown.
- That storytelling matters: demos that explain how AI thinks are much more memorable than black-box outputs.
🚀 The Demo
The demo script (demo.py) walks the judges through:
- A full reasoning trace from Nemotron
- JSON plan generation
- Safety critic + patching loop
- Guardrails and cost estimation
- Interactive confirmation
- “Execution timeline” with GPU utilization logs and progress bars
- Artifacts + report summary + judging criteria checklist
Built With
- brev
- nemotron
- python


Log in or sign up for Devpost to join the conversation.