-
-

Pragma Lens image
-

PragmaLens
-
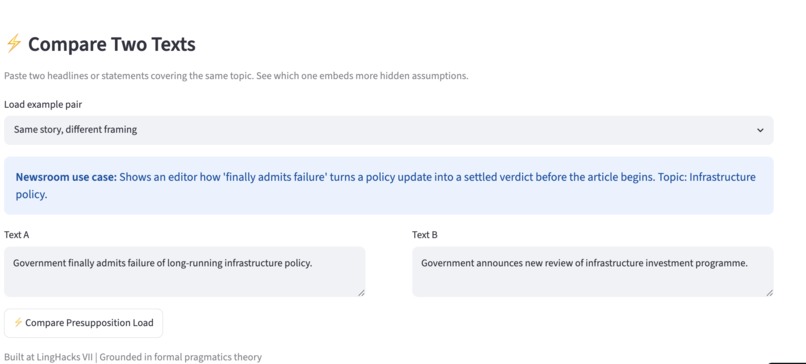
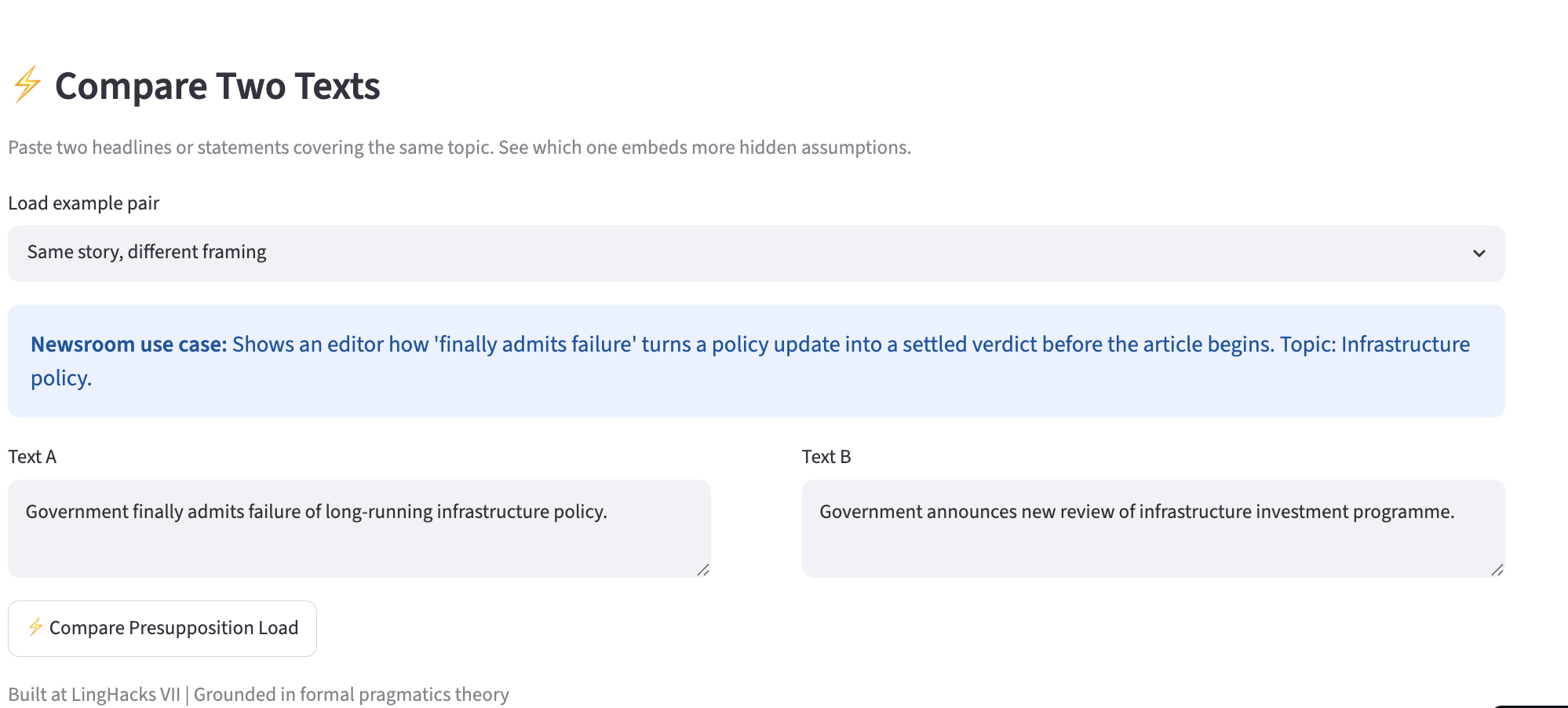
Analysis Tab - Comparing two texts
-
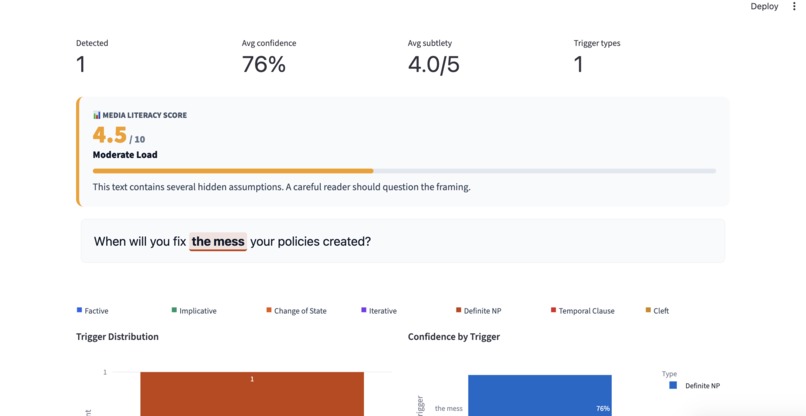
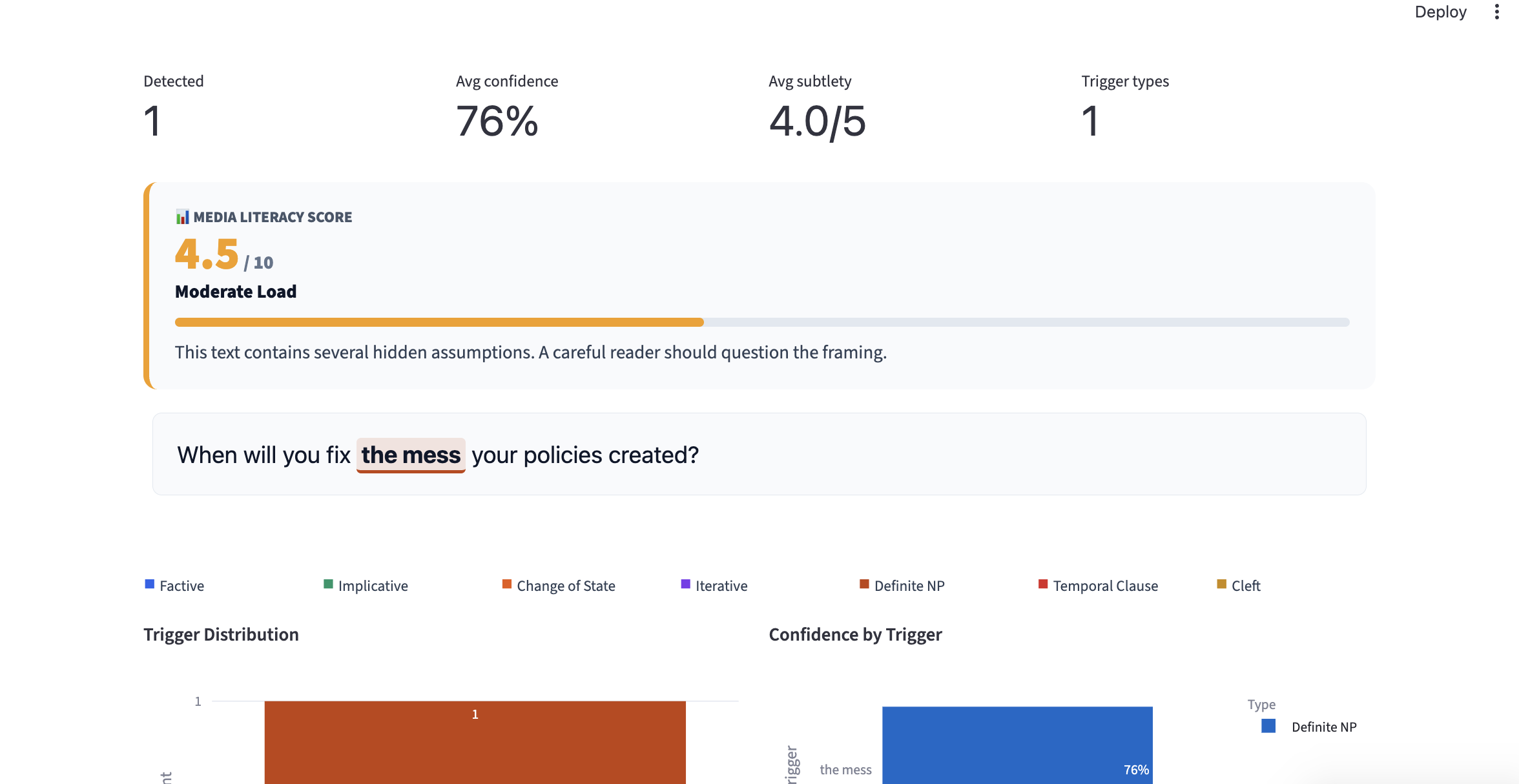
Analysis and results , Prediction, confidence + stats
-
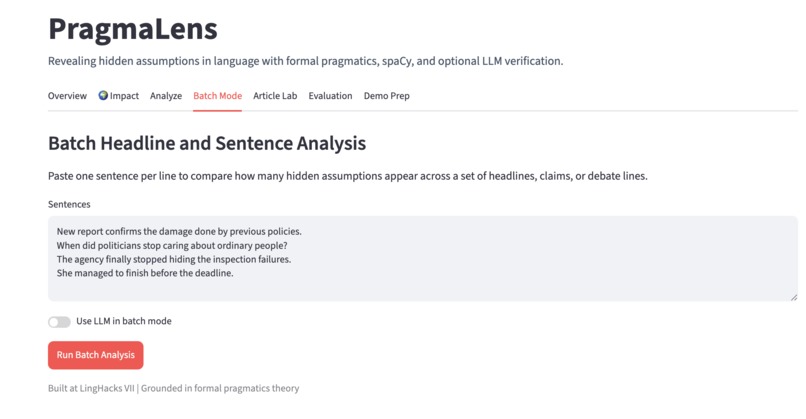
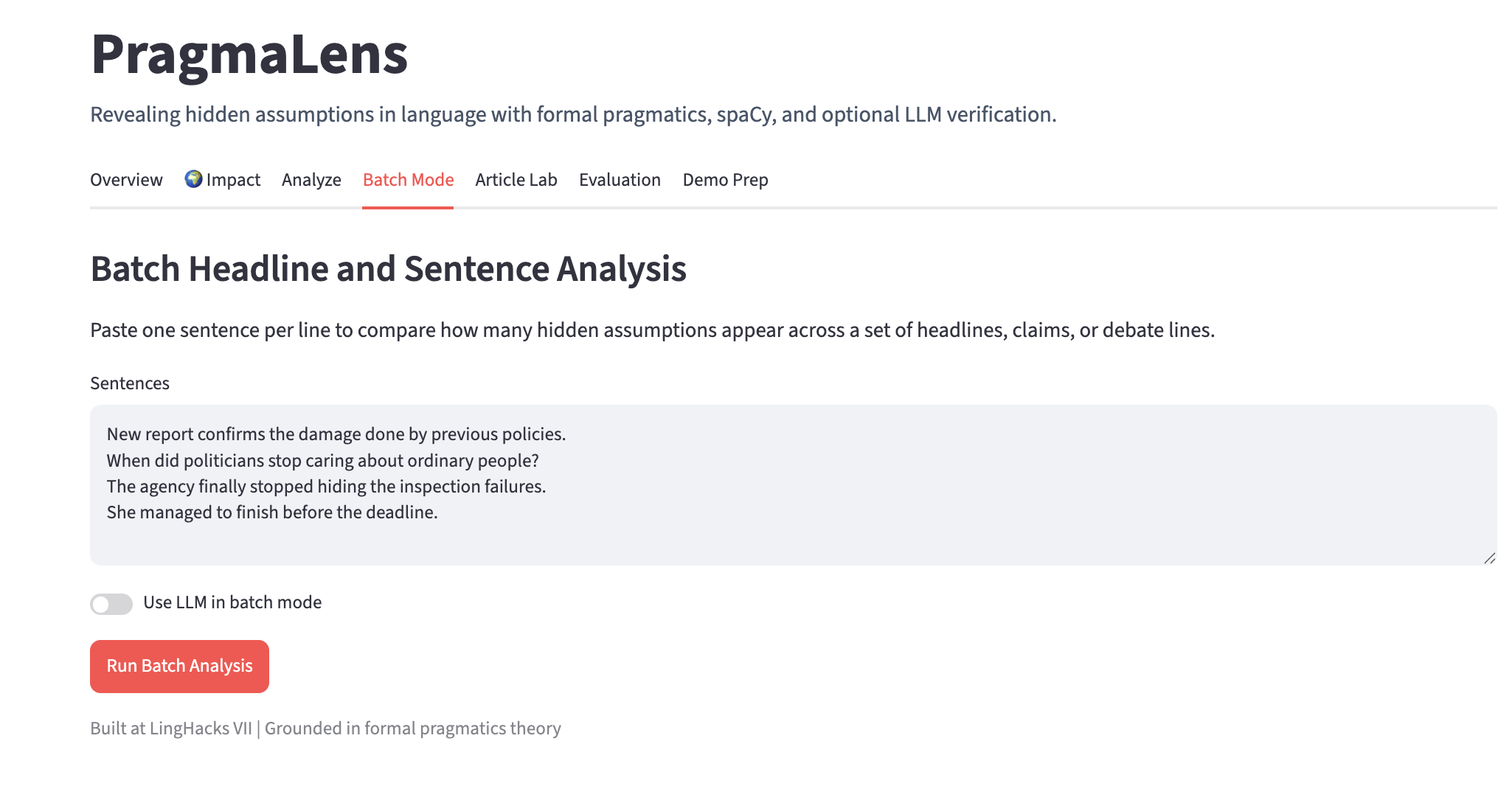
Batch mode- analyses multiples sentences at once
-

Overview page - project summary -method visual
-
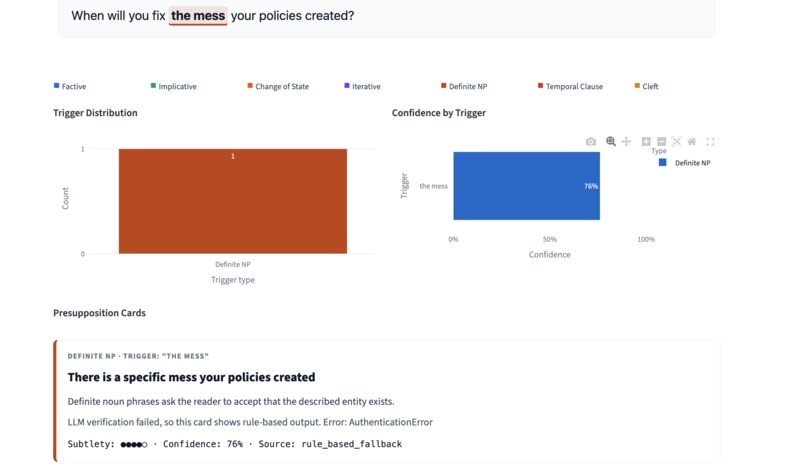
Analysis and results
-
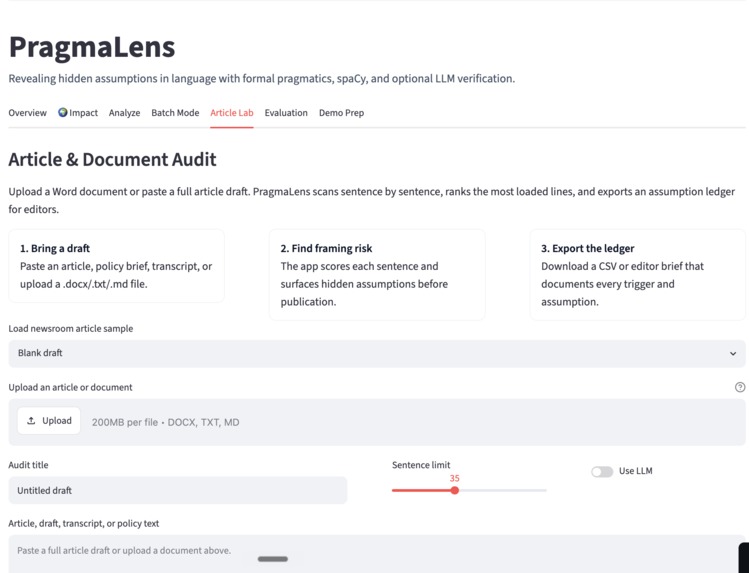
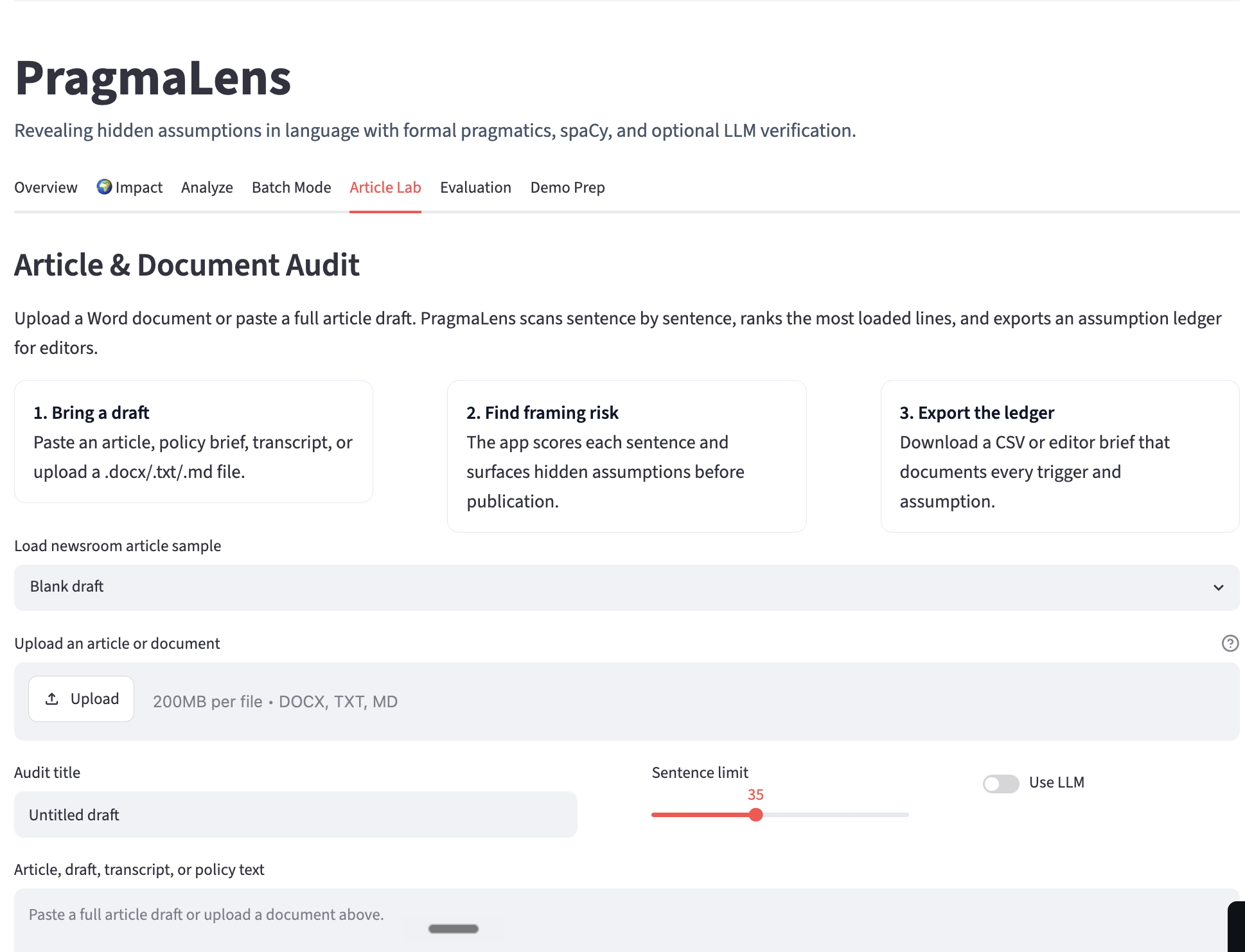
Article and Document Audit, Sumbit entire documents, articles ,etc.
-
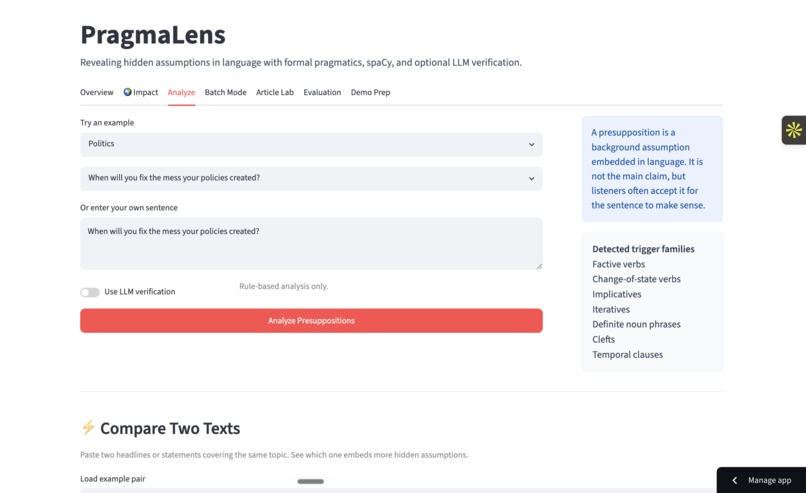
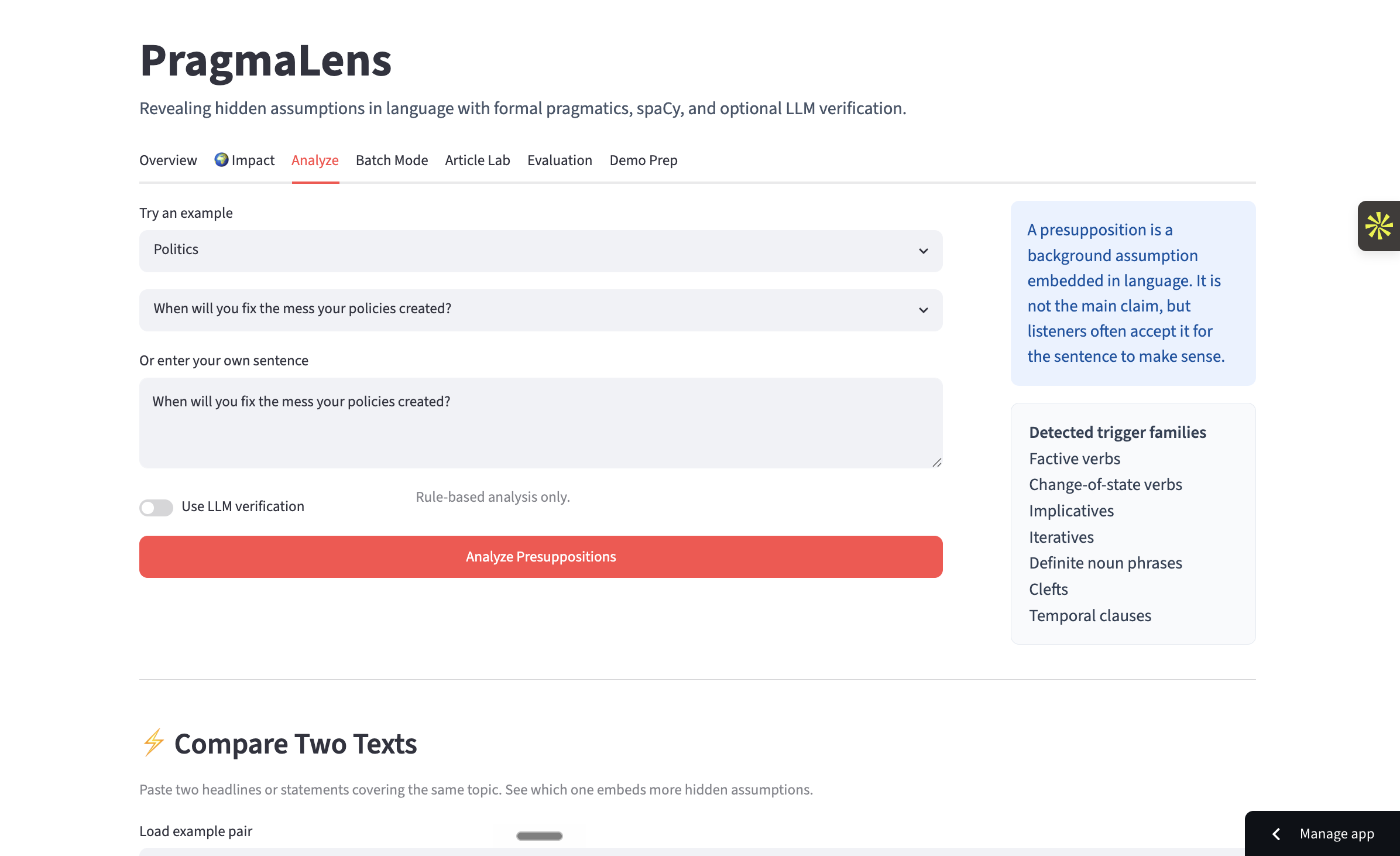
Analysis Tab
-
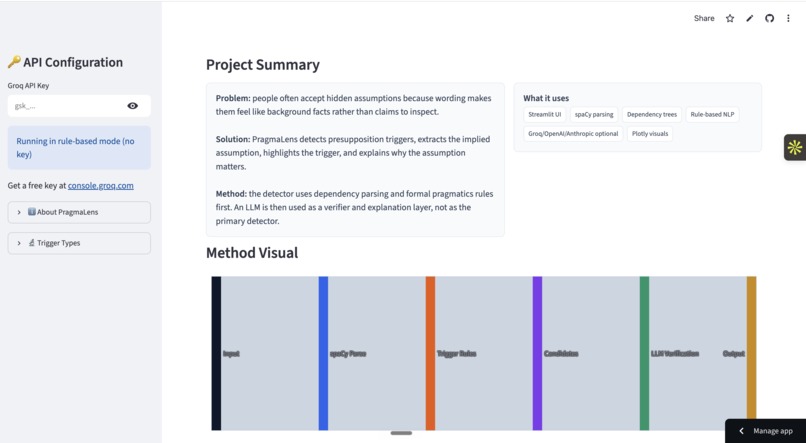
Overview page - project summary
-
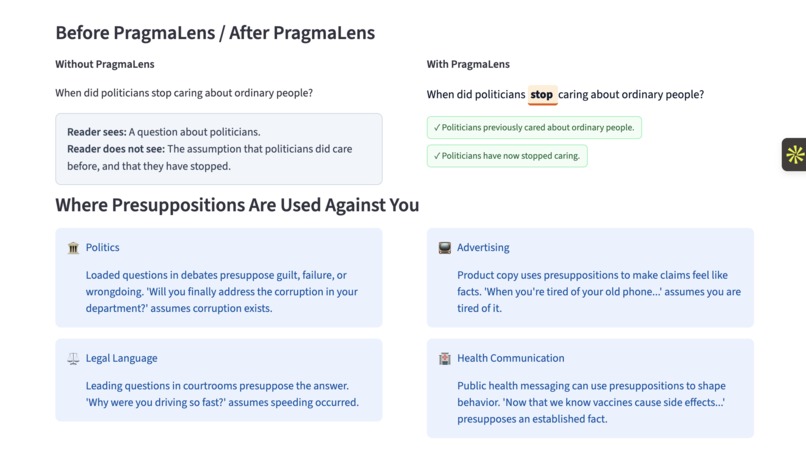
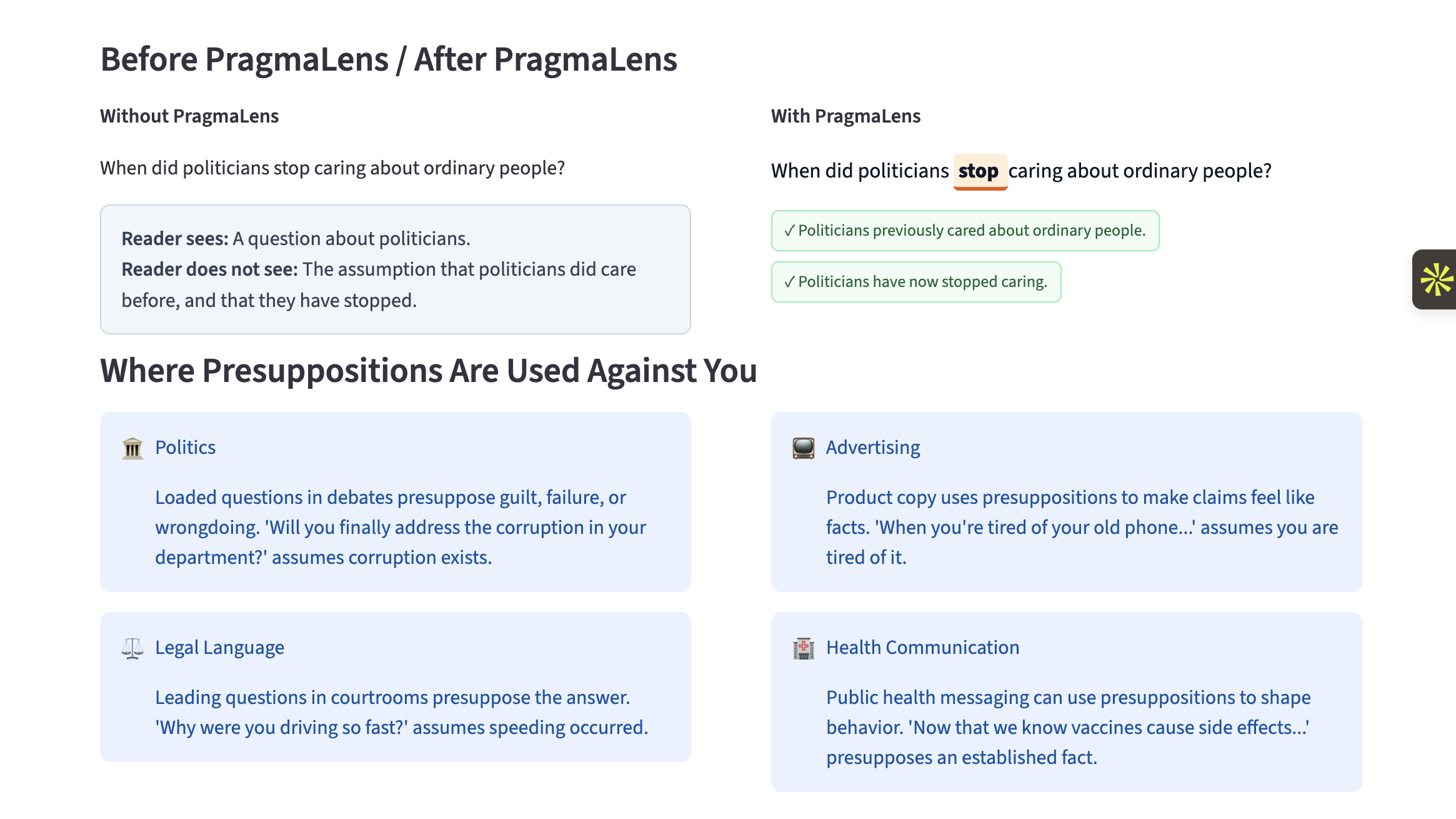
Before v/s After PragmaLens
-
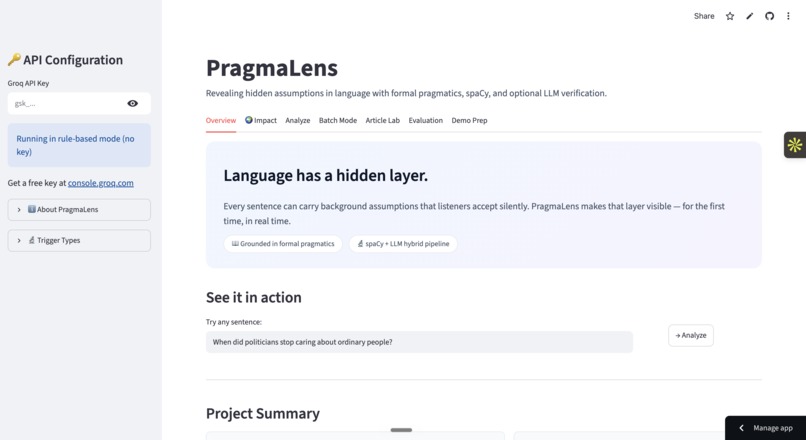
Overview page
-

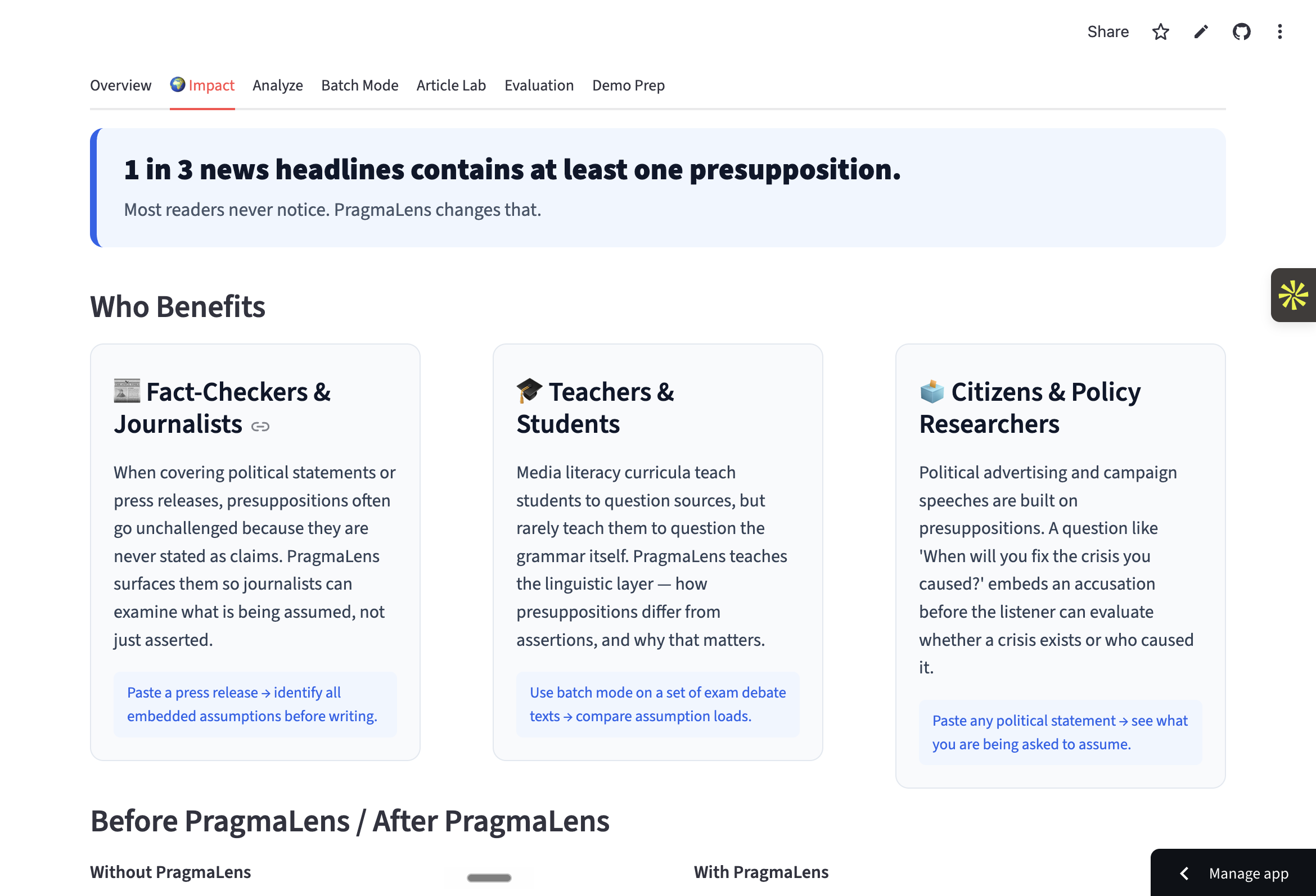
Before v/s After PragmaLens + Scale of the problem
-
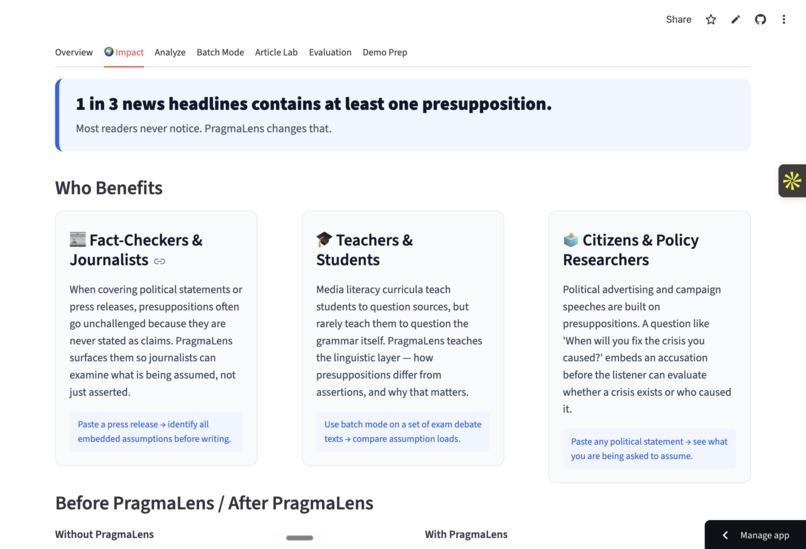
Impact and problem






Inspiration
While watching a political debate, I heard the question: "When will you fix the broken promises you made?" — and realised the question had already assumed the promises were broken, before anyone agreed to that. I discovered that linguists have studied this exact phenomenon since 1892, calling them presuppositions — hidden assumptions embedded in language that listeners accept without noticing. Fact-checkers verify explicit claims. Sentiment analyzers measure tone. But nobody had built a tool to detect the hidden assumption layer. That gap is what PragmaLens fills.
What It Does
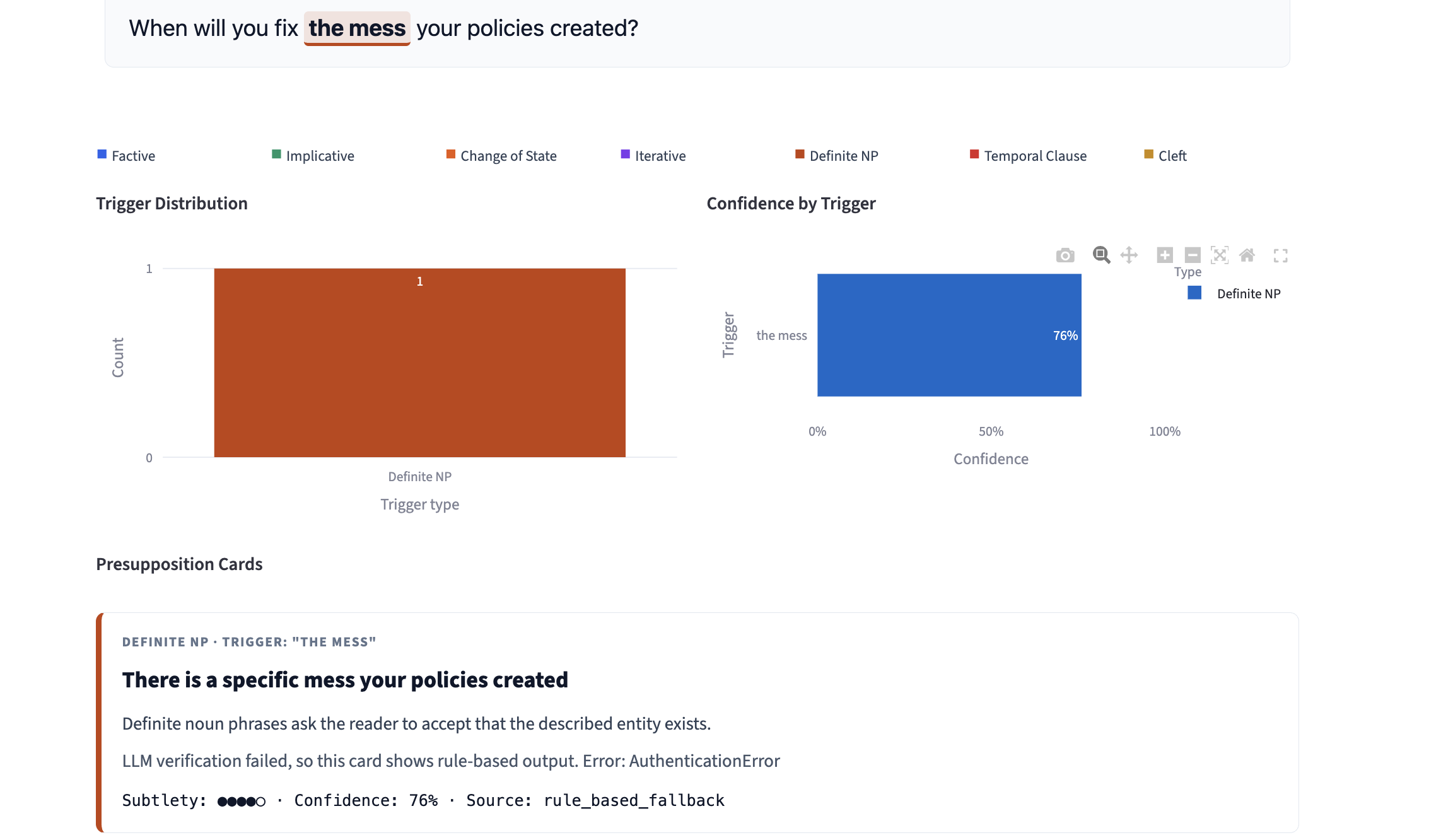
PragmaLens analyzes any sentence and surfaces the presuppositions hidden inside it — the background assumptions a speaker embeds that listeners silently accept. Paste "When did politicians stop caring about ordinary people?" and the app shows you: (1) politicians previously cared, (2) they have now stopped — neither was stated, both were assumed. It highlights the trigger word, explains each presupposition in plain English, and scores the sentence on a 0–10 Media Literacy Score measuring how presupposition-heavy the language is. A Compare Headlines feature lets you paste two texts about the same topic and see which one embeds more hidden assumptions side by side. Batch mode lets you analyze an entire speech or article at once with a CSV export.
How We Built It
PragmaLens uses a two-stage NLP pipeline. First, spaCy's dependency parser walks the grammatical tree of a sentence looking for seven types of presupposition triggers — factive verbs (know, realize), change-of-state verbs (stop, start), iteratives (again, still), temporal clauses (before, after), and more — each grounded in Karttunen's (1973) formal taxonomy. Each detected candidate is then sent to Groq's LLaMA 3.1 model with a system prompt grounded in formal pragmatics theory, which verifies it's a genuine presupposition and generates a plain-English explanation. The frontend is built in Streamlit with custom CSS, Plotly charts, and deployed to Streamlit Community Cloud.
Challenges We Ran Into
The hardest technical challenge was spaCy's dependency tree traversal — getting the right subtree out of complex nested sentences required careful handling of dozens of edge cases. Deploying spaCy on Streamlit Cloud was unexpectedly difficult since the platform can't run terminal commands at runtime to download the model, requiring us to install it as a pip wheel URL during the build phase. Getting the LLM to return technically accurate presupposition analysis — not hallucinating or confusing presuppositions with implications — required many iterations of the system prompt grounded in formal linguistic definitions.
Accomplishments That We're Proud Of
We built the first practical tool to detect presuppositions automatically — a gap that existed despite 70 years of linguistic research. The two-stage pipeline (spaCy rules + LLM verification) is genuinely novel engineering: rules detect the candidates, the LLM verifies and explains them, neither stage works as well alone. The Compare Headlines feature was our proudest moment — seeing two headlines about the same political event with a presupposition count of 3 vs. 0 made the project's purpose immediately clear. We also shipped a complete evaluation benchmark with 20 test cases, so judges can see exactly how accurate the system is — not just a demo, but a measured result.
What We Learned
We learned that formal pragmatics is almost entirely absent from applied NLP despite being one of the most important layers of language — there are thousands of sentiment analysis papers and almost none on presupposition detection in a practical form. Dependency parsing is far more powerful than we expected: knowing that "stopped" governs "polluting" as a grammatical child lets you extract meaning automatically from structure, not just vocabulary. We also learned that LLMs work best as a verification and explanation layer on top of rule-based detection, not as a replacement for it — the rules give structure, the LLM gives clarity.
What's Next for PragmaLens
The most immediate next step is a browser extension (Chrome/Firefox) that lets users highlight any sentence on any news article and see its presuppositions instantly — that is the version that reaches millions of readers, not thousands. We want to expand to additional languages, since presuppositions exist in every human language and the mechanisms are well-documented. Longer term, we plan to build a labeled dataset of presuppositions in political speech — something that currently doesn't exist publicly — and use it to fine-tune a dedicated model, eventually publishing our findings as a research paper on presupposition density as a measurable indicator of rhetorical manipulation.
Check pragma lens out at - https://pragmalens.streamlit.app/ or Check out the GitHub repo - https://github.com/ashishm9864/pragmalens
Built With
- dependency
- groq/openai/anthropic
- natural-language-processing
- optional
- parsing
- plotly
- rule-based
- spacy
- streamlit
- trees
- ui


Log in or sign up for Devpost to join the conversation.