-
-
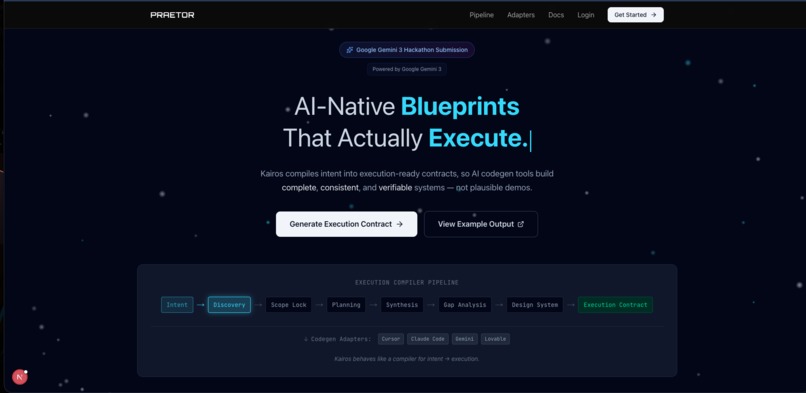
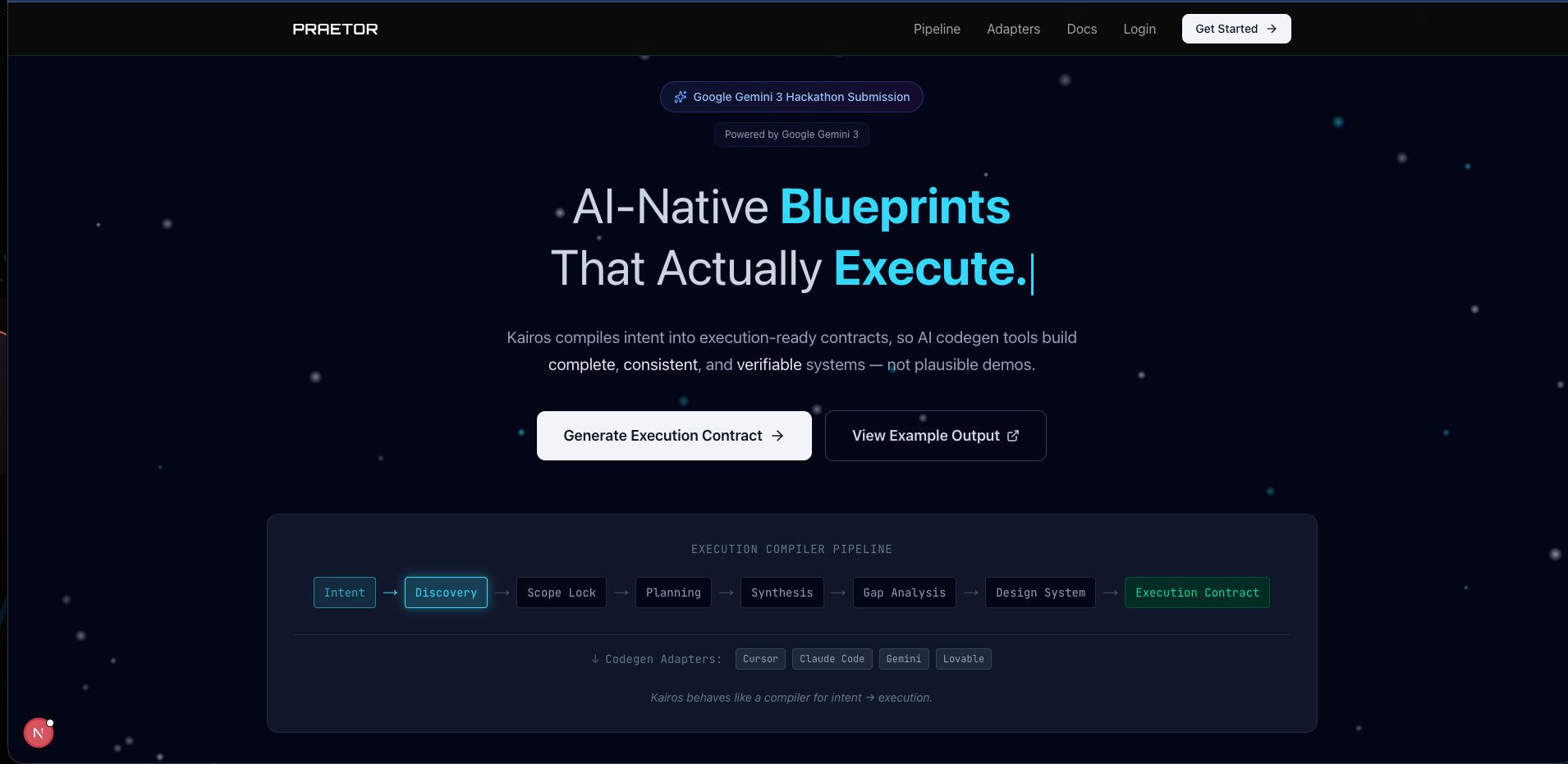
Landing Page
Inspiration
What it does
How we built it
Challenges we ran into
Accomplishments that we're proud of
What we learned
What's next for Praeter
Inspiration
20 years as an engineer. 8 of those freelancing. Most of the startups I worked with failed — and it was almost never the code. It was always the requirements.
Then AI coding tools came along. I went all in — 500 million tokens across 15 personal projects. 2 shipped. Same pattern. Clients couldn't tell me what they needed. I couldn't ask the right questions. And AI made it faster to build the wrong thing.
Research confirmed what I'd experienced: AI-generated code has 1.7x more bugs than human code. 63% of developers say the #1 problem is lack of context. The tools aren't broken. They just don't know what to build.
I built the missing layer.
What it does
Praeter transforms a vague project idea into a production-ready technical specification through AI-guided discovery.
You describe what you want to build. 47 specialized agents ask the right questions — not random AI questions, but questions pulled from standardized pools grounded in BPMN, OpenAPI, and ArchiMate. The system prefills 90% of answers from domain templates and industry patterns, so you focus only on what makes your project unique.
5 gap detectors catch missing permissions, incomplete integrations, and schema issues before they become bugs in code. Then platform adapters transform the final spec for Claude Code, Cursor, or Kiro — optimized for how each tool consumes it.
8 phases. 47 agents. From vague idea to implementation-ready spec.
How we built it
- ~305,000 lines of TypeScript — React 19, Next.js 15, PostgreSQL
- 47 specialized AI agents — discovery, research, synthesis, gap detection, compilation
- Mastra framework for agent orchestration with 4 execution strategies (sequential, parallel, hierarchical, debate)
- 117 database migrations — production-grade multi-tenant schema with row-level security
- Standards-based grounding — BPMN 2.0 for workflows, OpenAPI 3.0 for APIs, ArchiMate for architecture
- Gemini integration for fast, cost-effective agent execution across the pipeline
The hardest architectural decision was the question budget system. Early versions generated 900+ questions — unusable. We built a 7-source budget system that caps at 93 questions while maintaining coverage. That's a 90% reduction without losing signal.
Challenges we ran into
The prefill confidence problem. How do you know when an AI-generated answer is good enough to auto-confirm vs. needs human review? We built a 5-source confidence system (discovery output, ontology mappings, component defaults, design intelligence, market research) with weighted scoring. Answers above 0.9 confidence auto-confirm. Below 0.7 requires review.
Question explosion. Naive question generation produces hundreds of questions nobody will answer. We implemented a strict budget system with caps per source category, forcing the system to prioritize high-value questions.
Gap detection without false positives. Early gap detectors flagged everything. We tuned 5 specialized detectors (integration, permission, workflow, template, schema) with severity levels so only true blockers prevent progression.
Accomplishments that we're proud of
- Question budget: 93 questions — down from 901 in early versions. Users can complete discovery in 30-45 minutes.
- 5 gap detectors running in parallel — catching issues that would otherwise become bugs in generated code
- Platform adapters — specs transform for Claude Code, Cursor, Kiro, each optimized for the target tool
- Standards-based, not vibes-based — every workflow maps to BPMN, every API to OpenAPI, every architecture decision to ArchiMate
- Production-ready infrastructure — 117 migrations, multi-tenant, row-level security, ready to ship
What we learned
Specification quality is the bottleneck. The AI coding tools are incredible. The prompts are good enough. What's missing is structured context — and that has to come from somewhere. We learned that "just ask better questions" doesn't scale. You need standardized question pools, domain templates, and confidence-scored prefilling.
Grounding prevents hallucination. When we let agents generate questions freely, they produced plausible but useless questions. When we grounded them in standards (BPMN, OpenAPI, ArchiMate) and constrained outputs to predefined pools, quality jumped dramatically.
The 90/10 rule is real. About 90% of any project is commodity code — auth, CRUD, notifications. The system asks about all of it, but focuses human attention on the 10% that's unique. That's where the value is.
What's next for Praeter
Auditor system — After code is generated, we'll diff it against the spec. Did the implementation match the specification? Where did it drift? This closes the loop.
Reverse ingestion — Feed in an existing codebase, produce a reconciled specification. Surface hidden assumptions and undocumented decisions.
Spec PRs — Treat specification changes like code PRs. Diffable, reviewable, auditable. Changes propagate impact analysis automatically.
The first spec is valuable. The fifth iteration — refined through usage, testing, and drift detection — is transformative. We're building for that.
Built With
- ai
- gemini
- javascript
- mastra
- nextjs
- tailwindcss
- typescript
- vercel

Log in or sign up for Devpost to join the conversation.