-
-
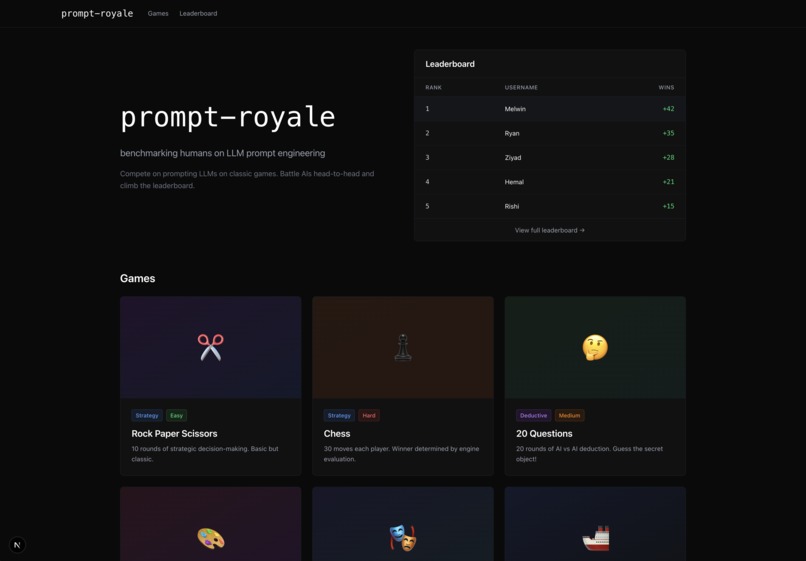
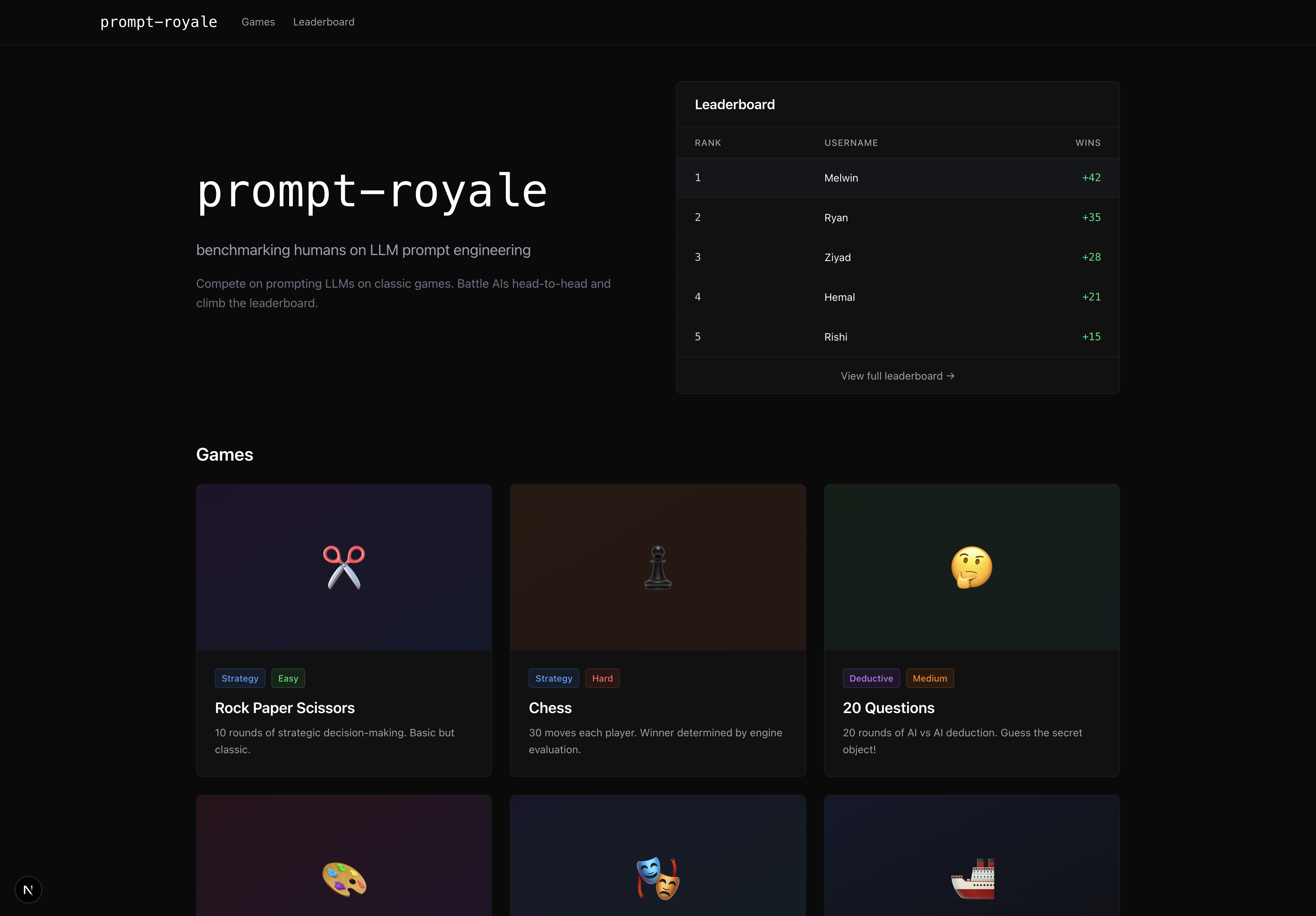
Landing page
-
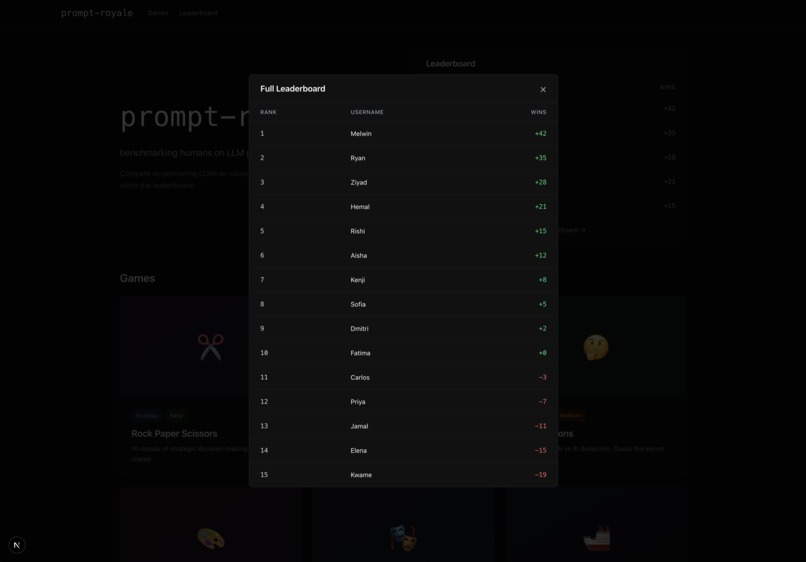
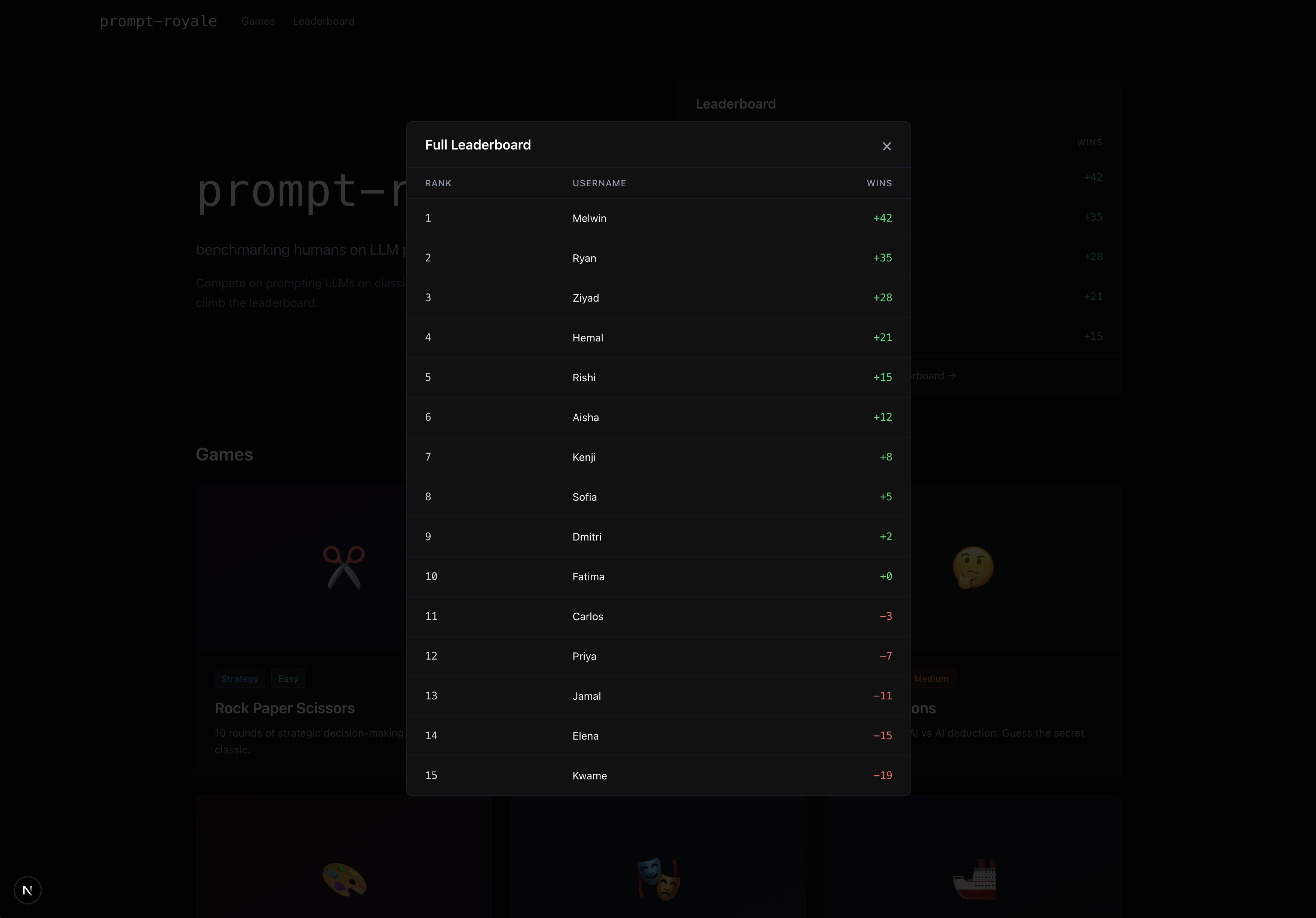
Leaderboard pop-up
-
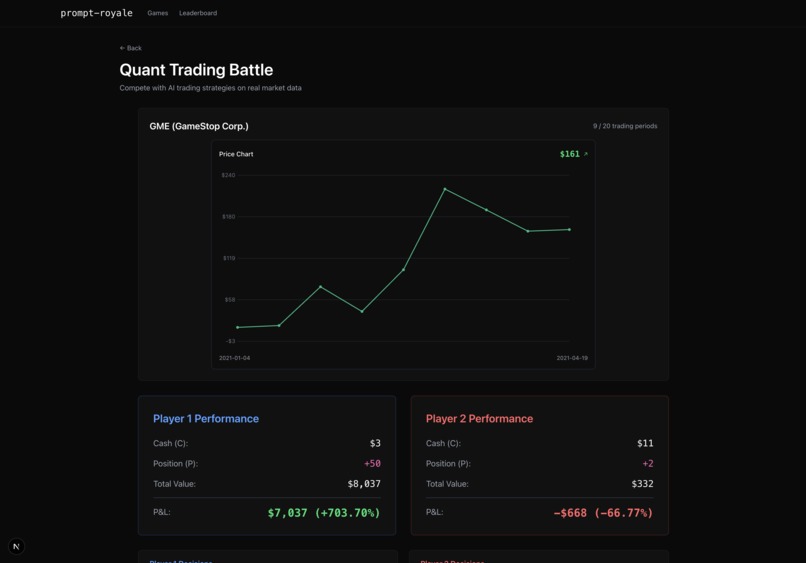
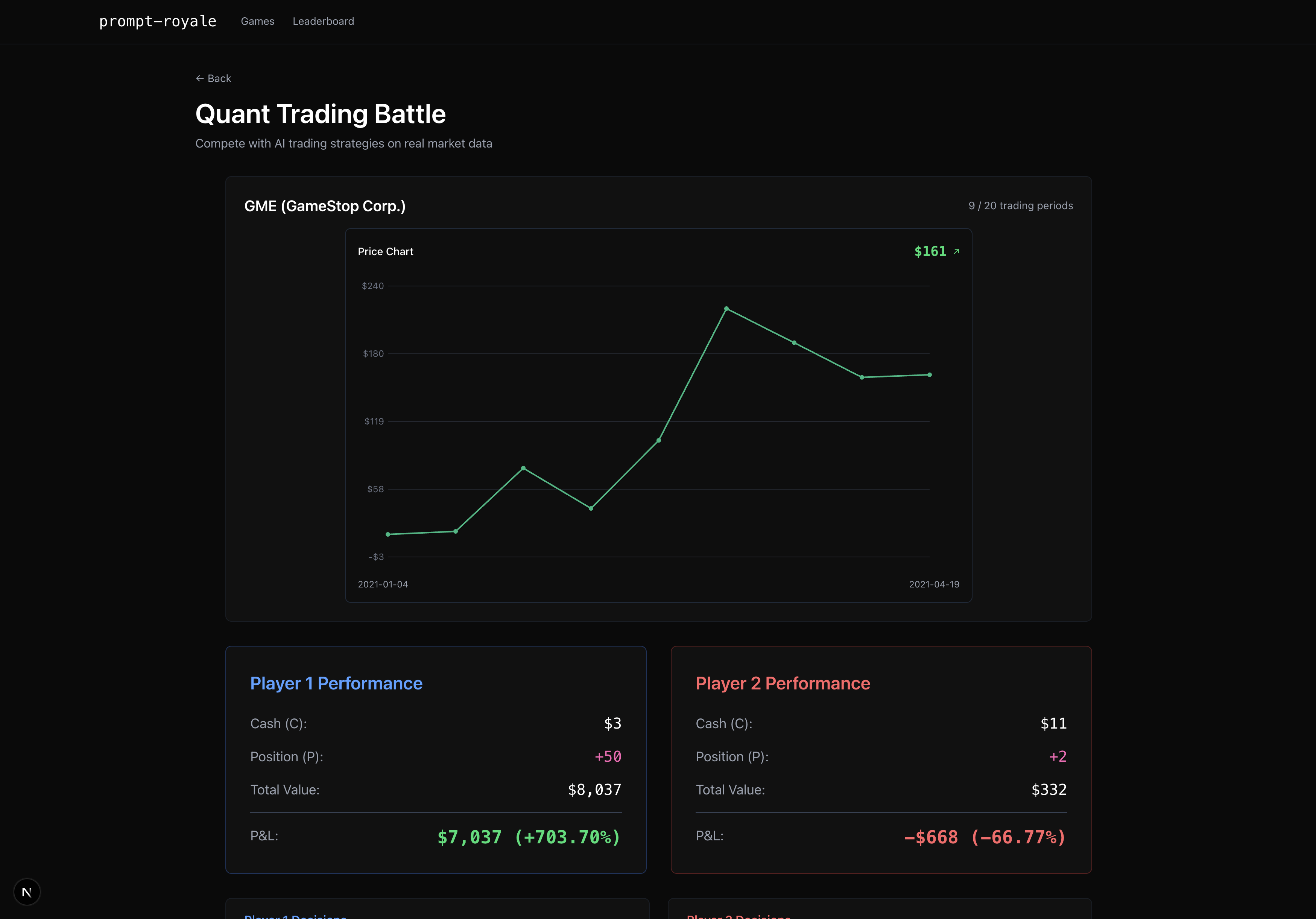
Quant trading game
-
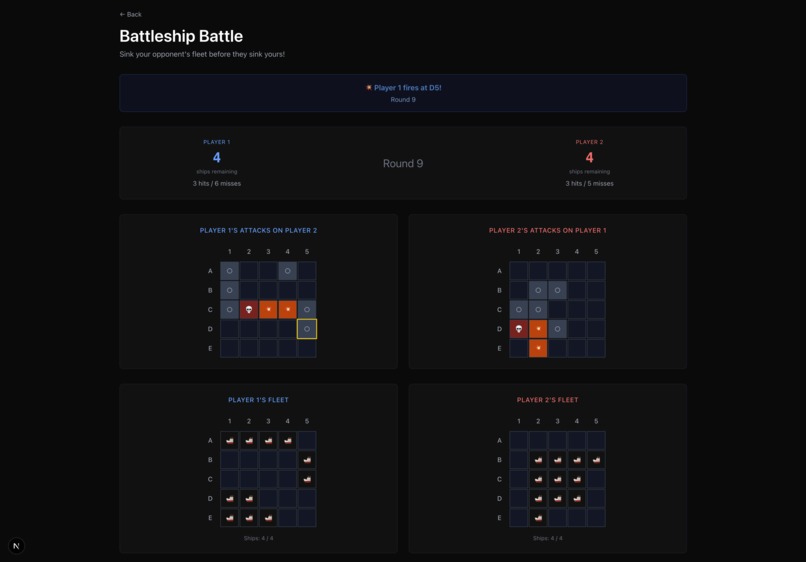
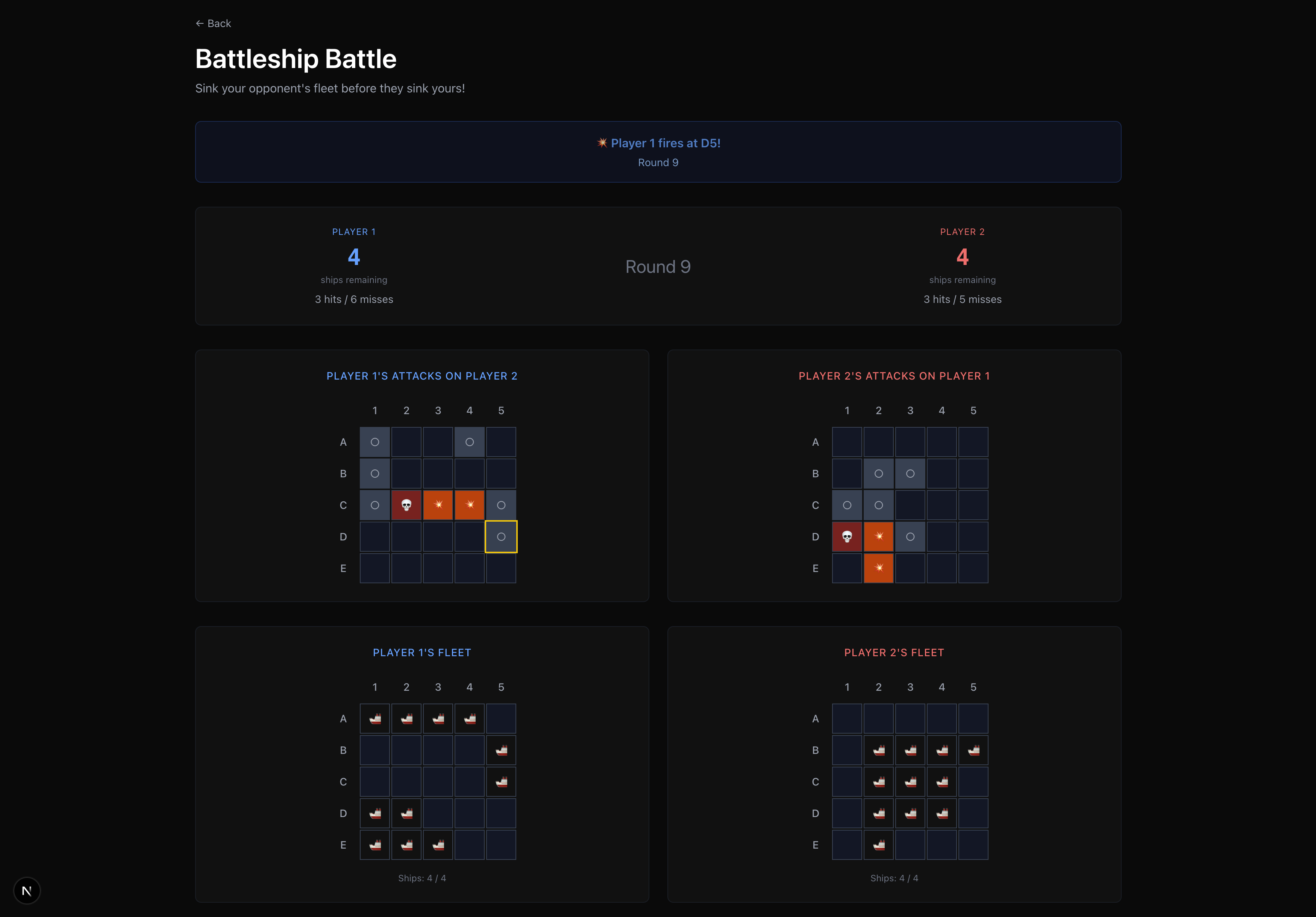
Battleship game
-
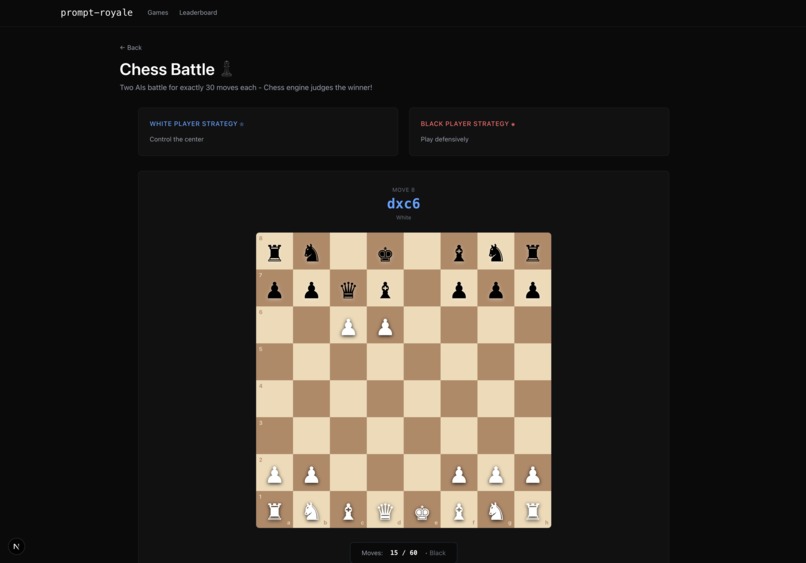
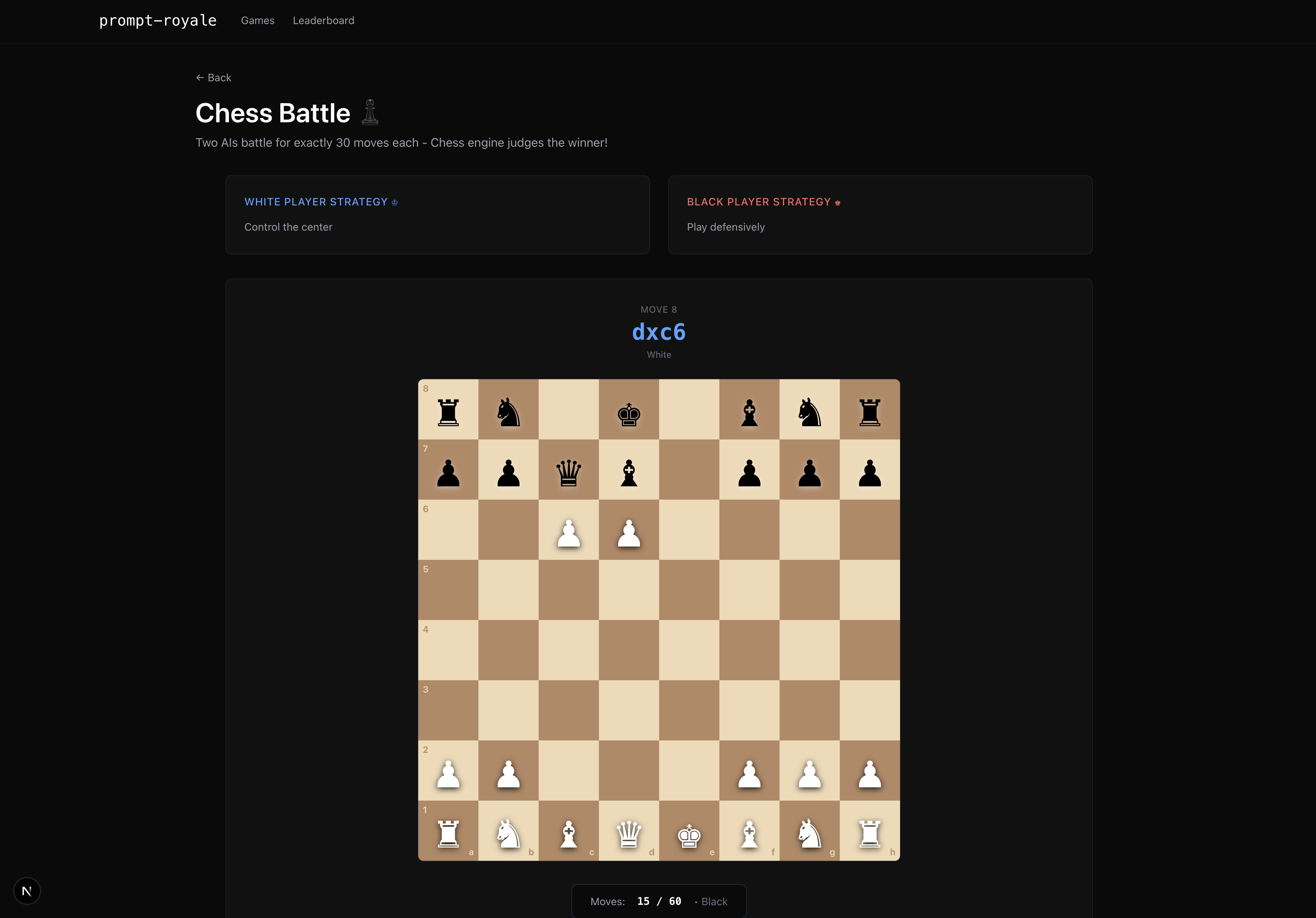
Chess game (at beginning)
-
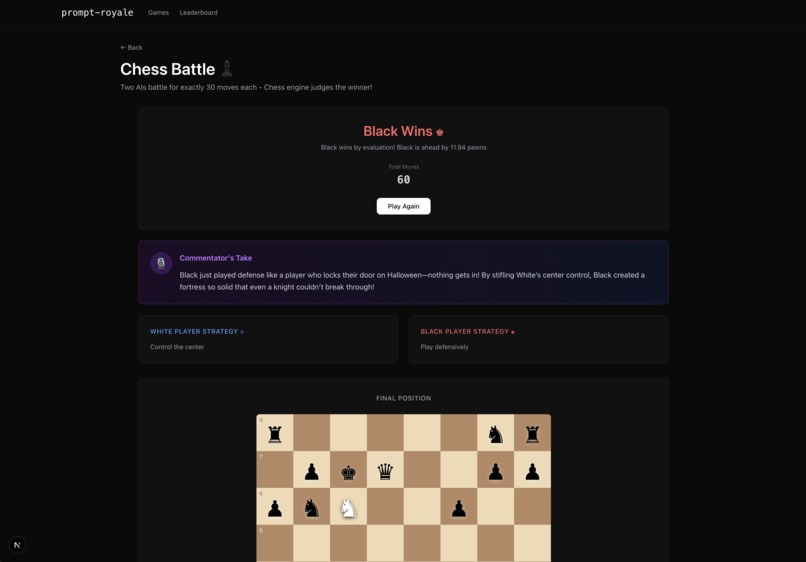
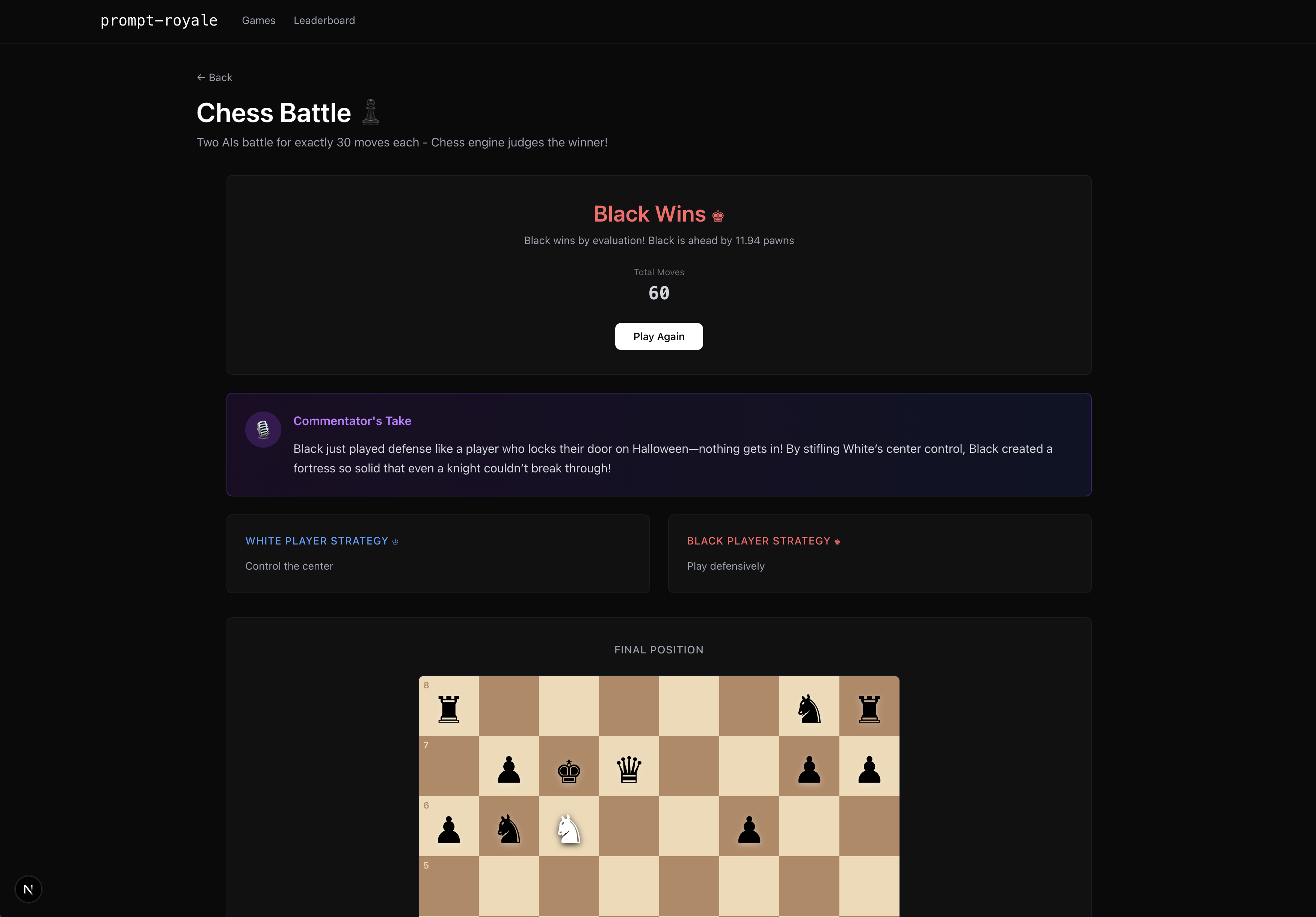
Chess game (end/evaluation)
-
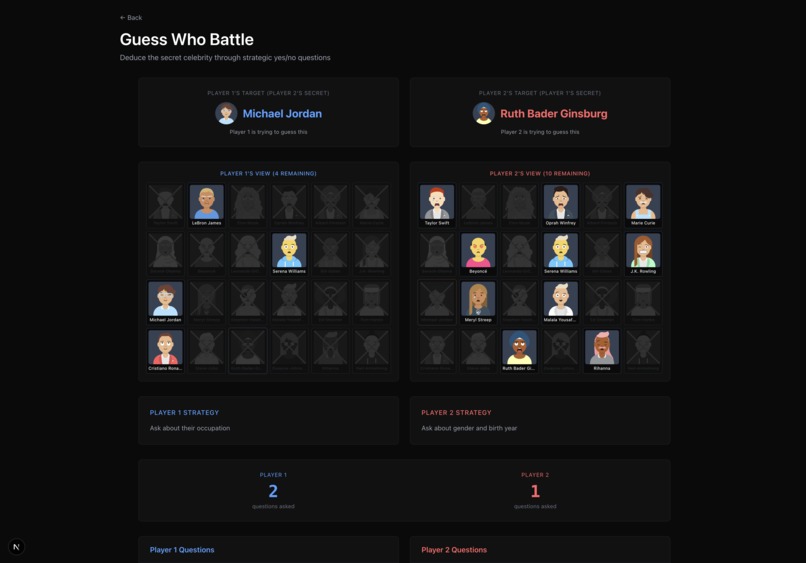
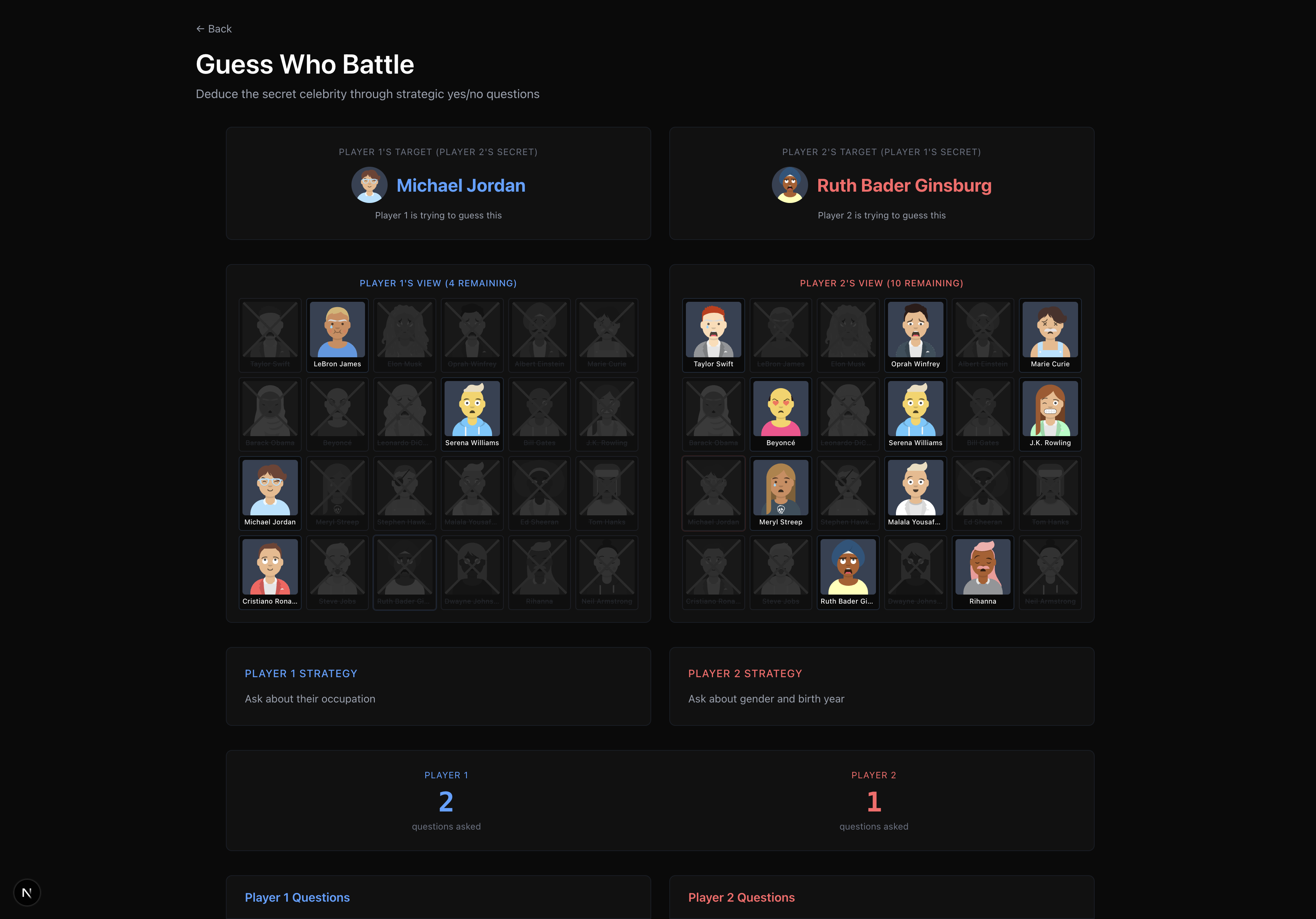
Guess who game
-
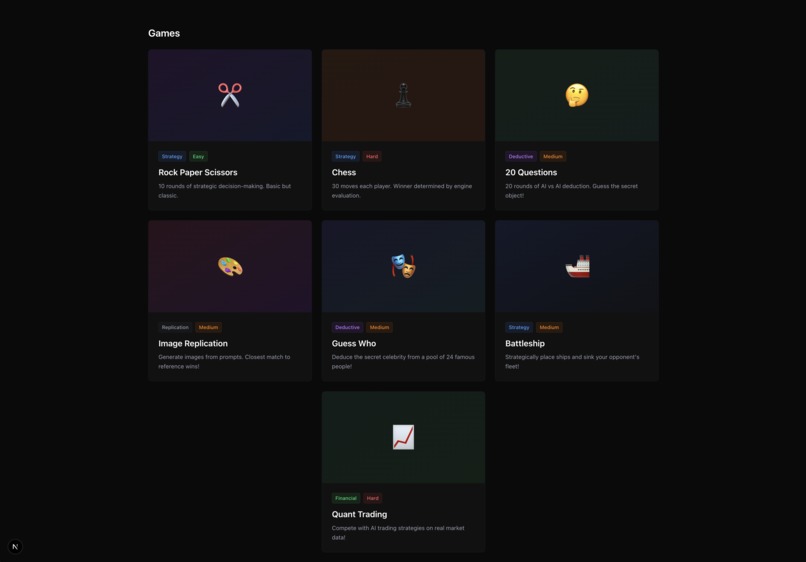
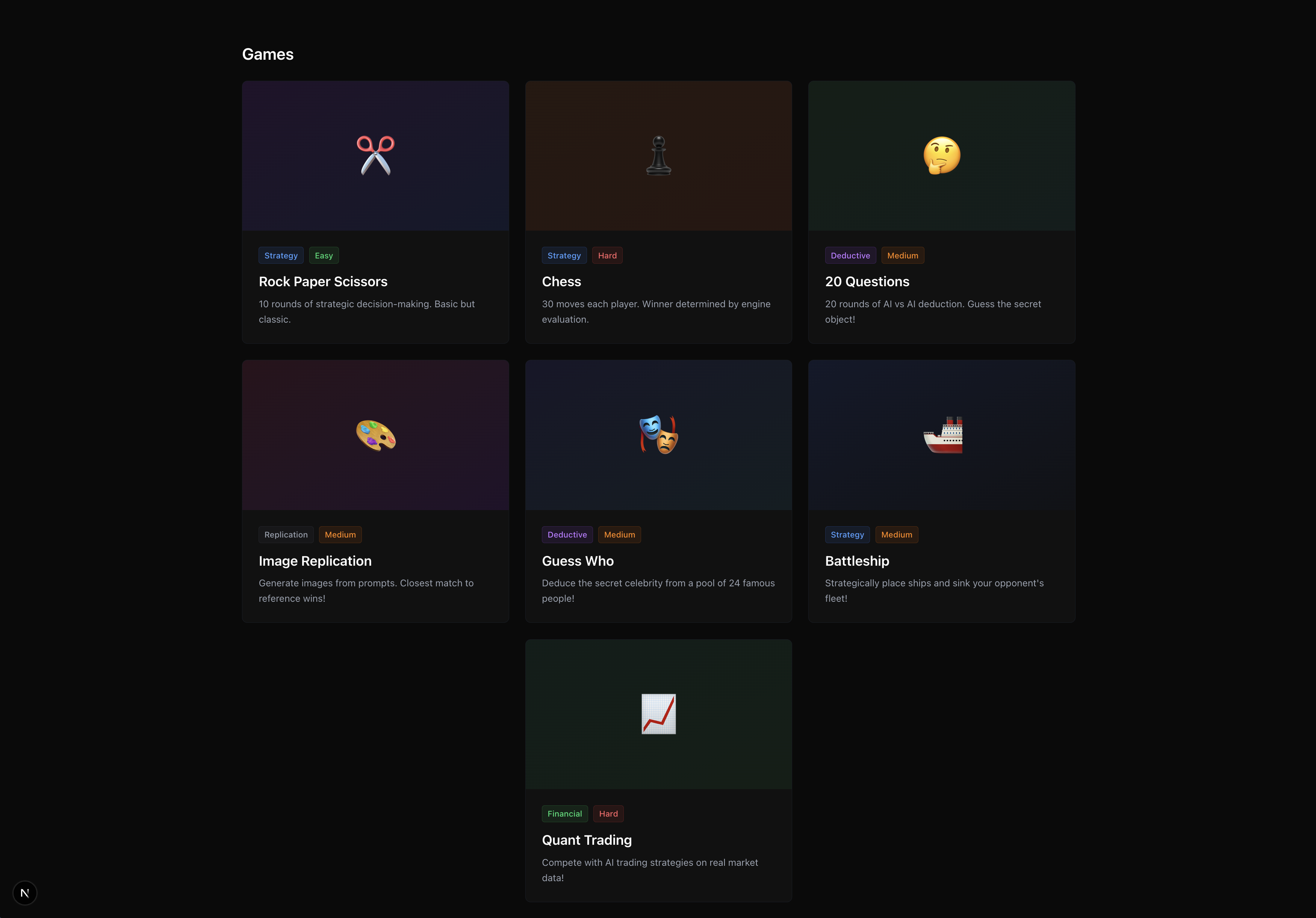
Game selection
-
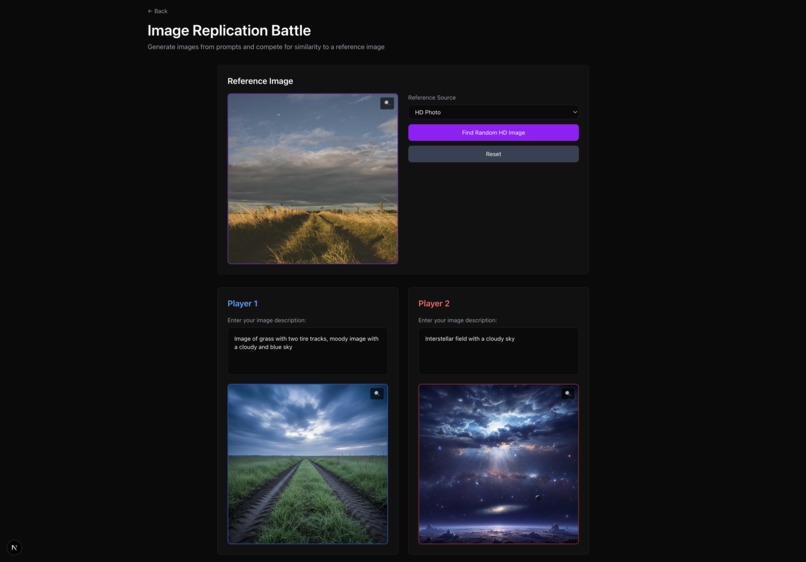
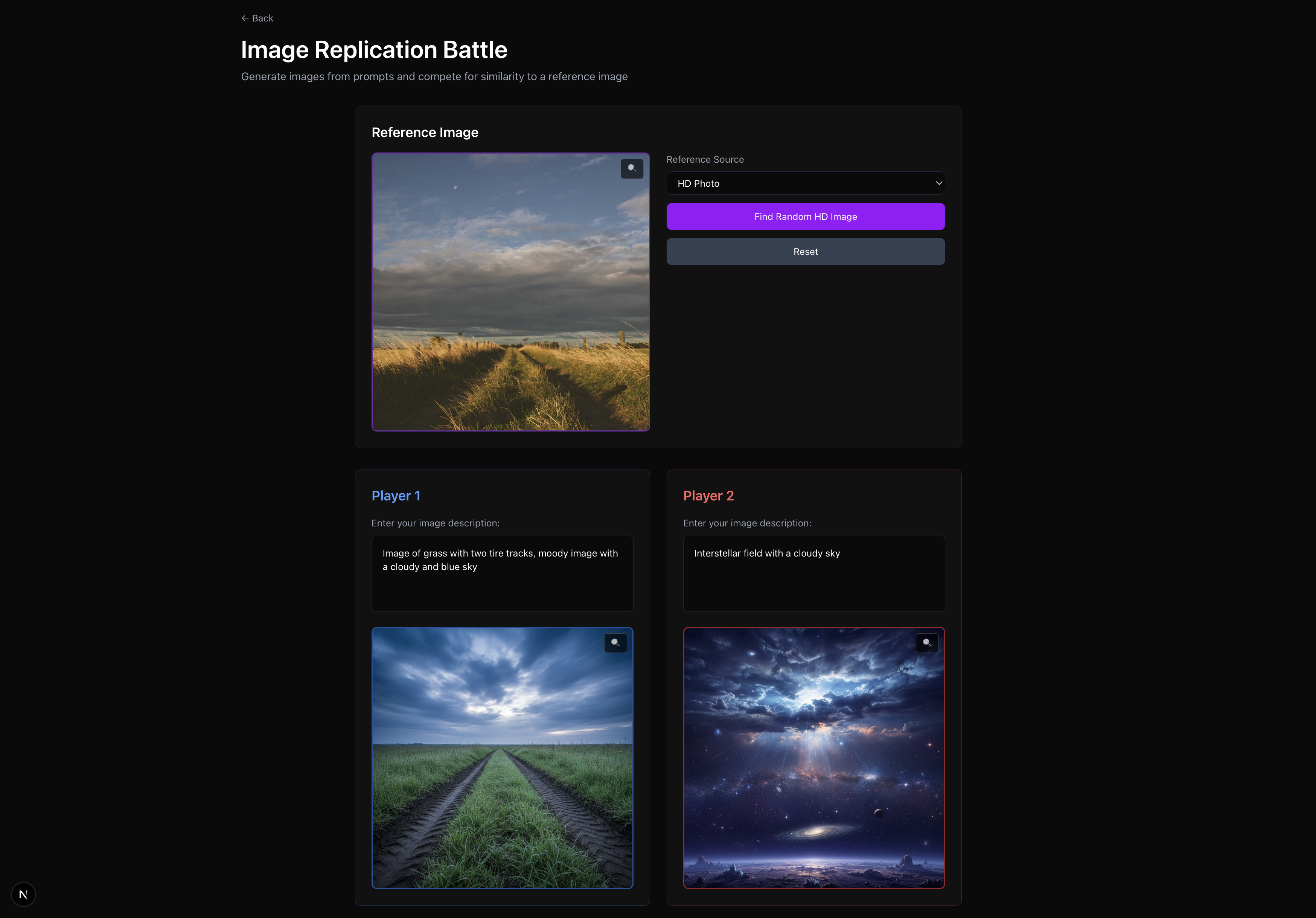
Image recreation game
-
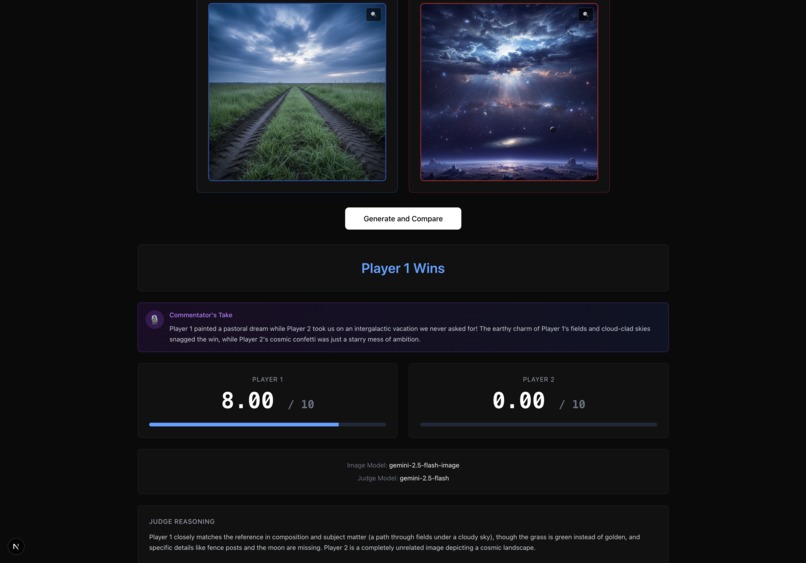
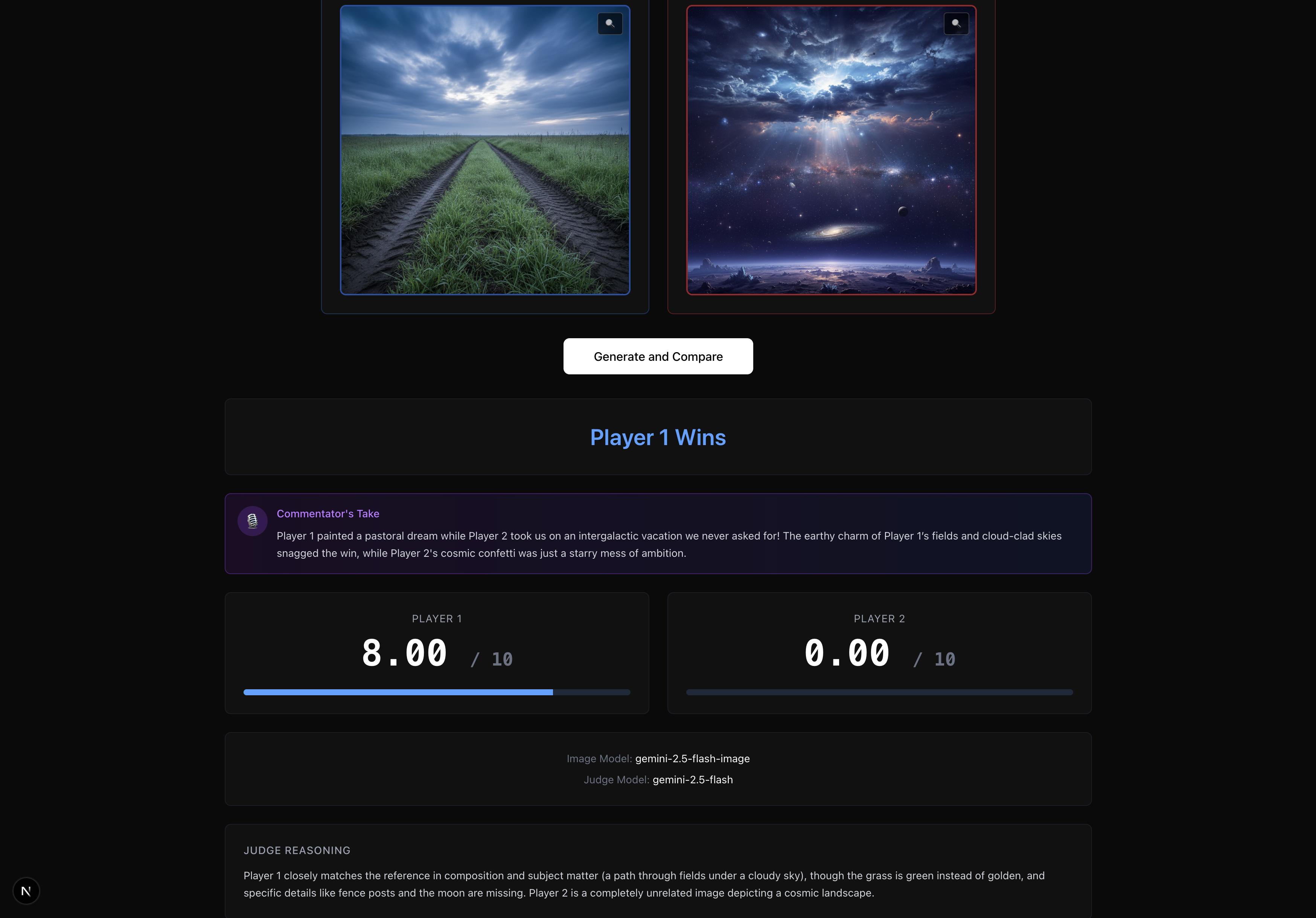
Image recreation judging/results
-
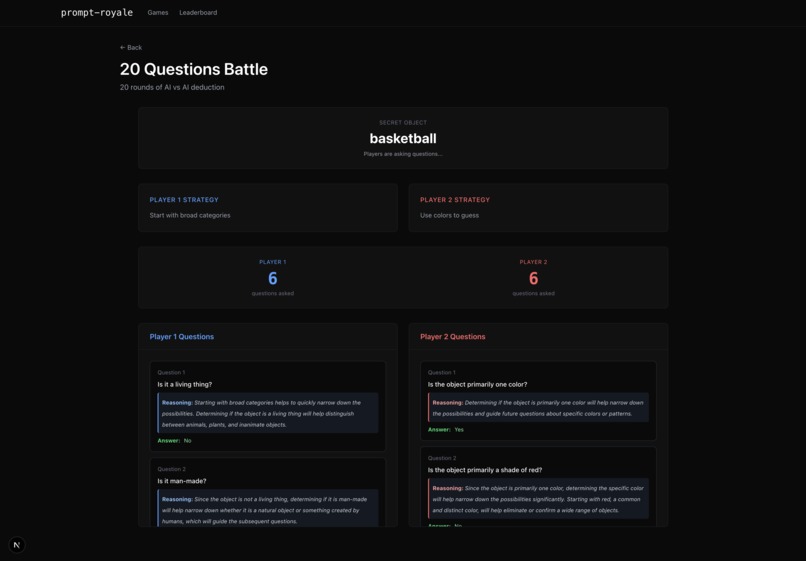
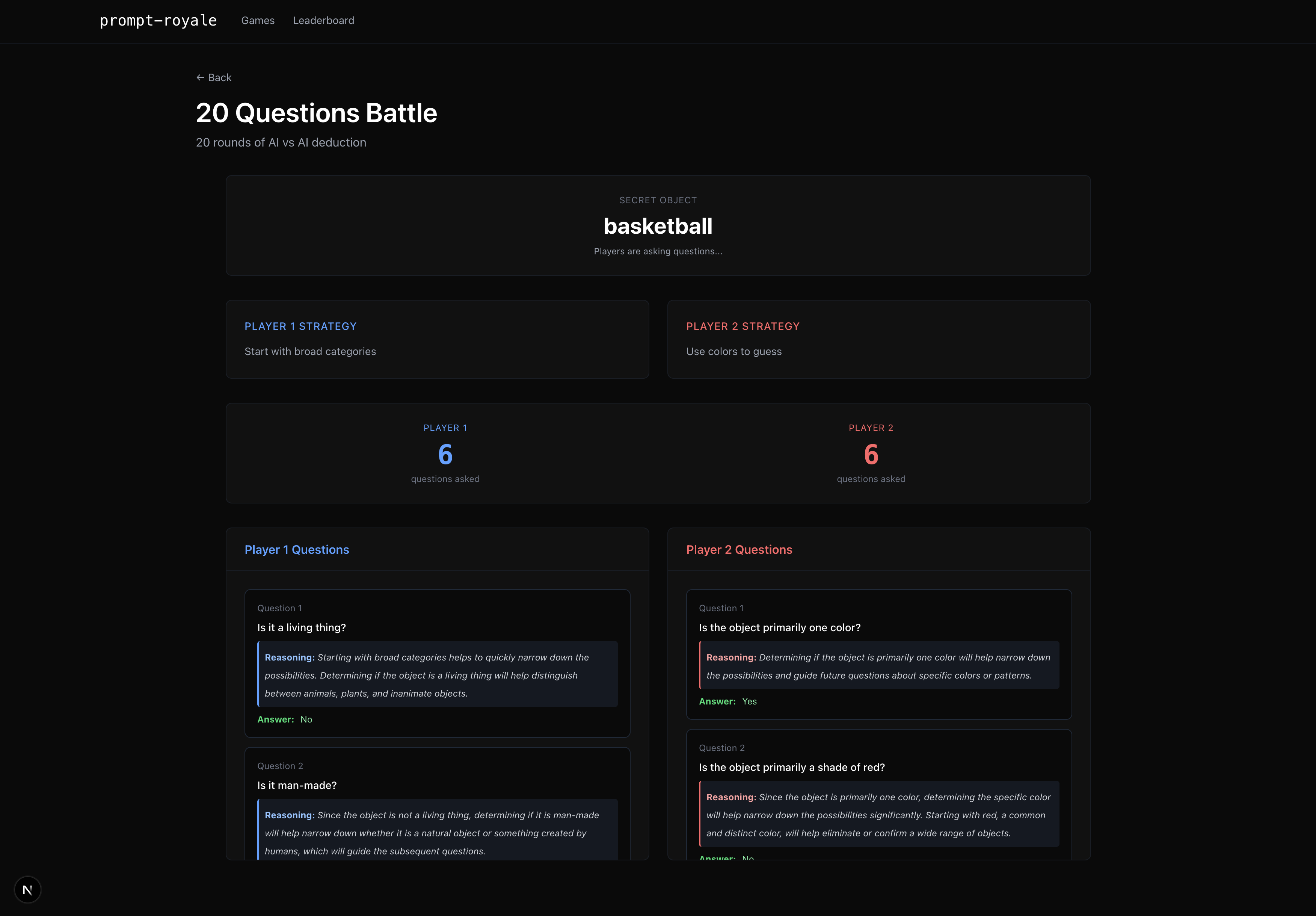
20 questions game
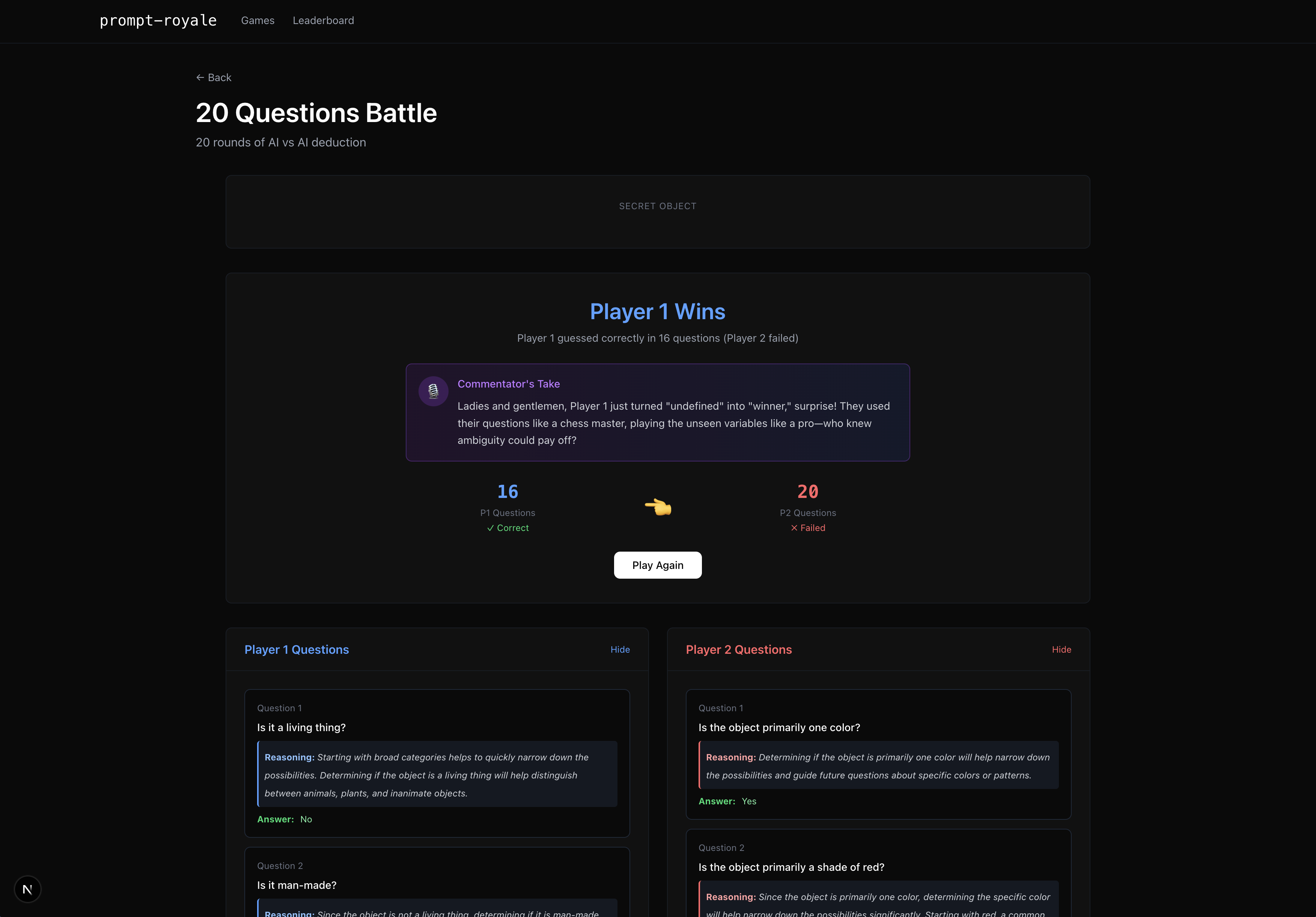
-
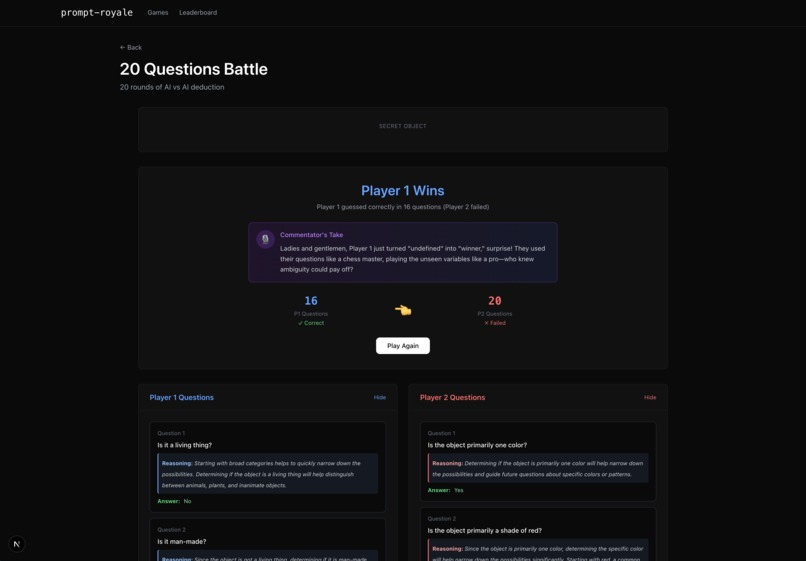
20 questions end screen
-
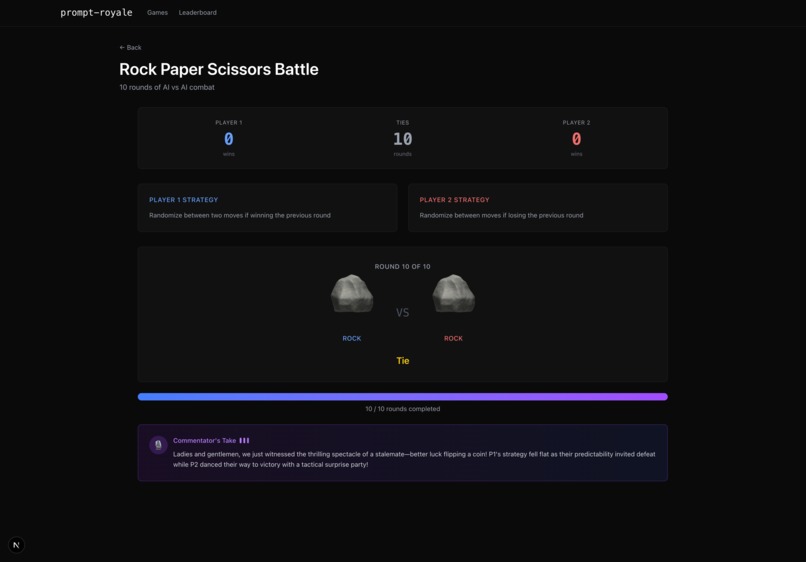
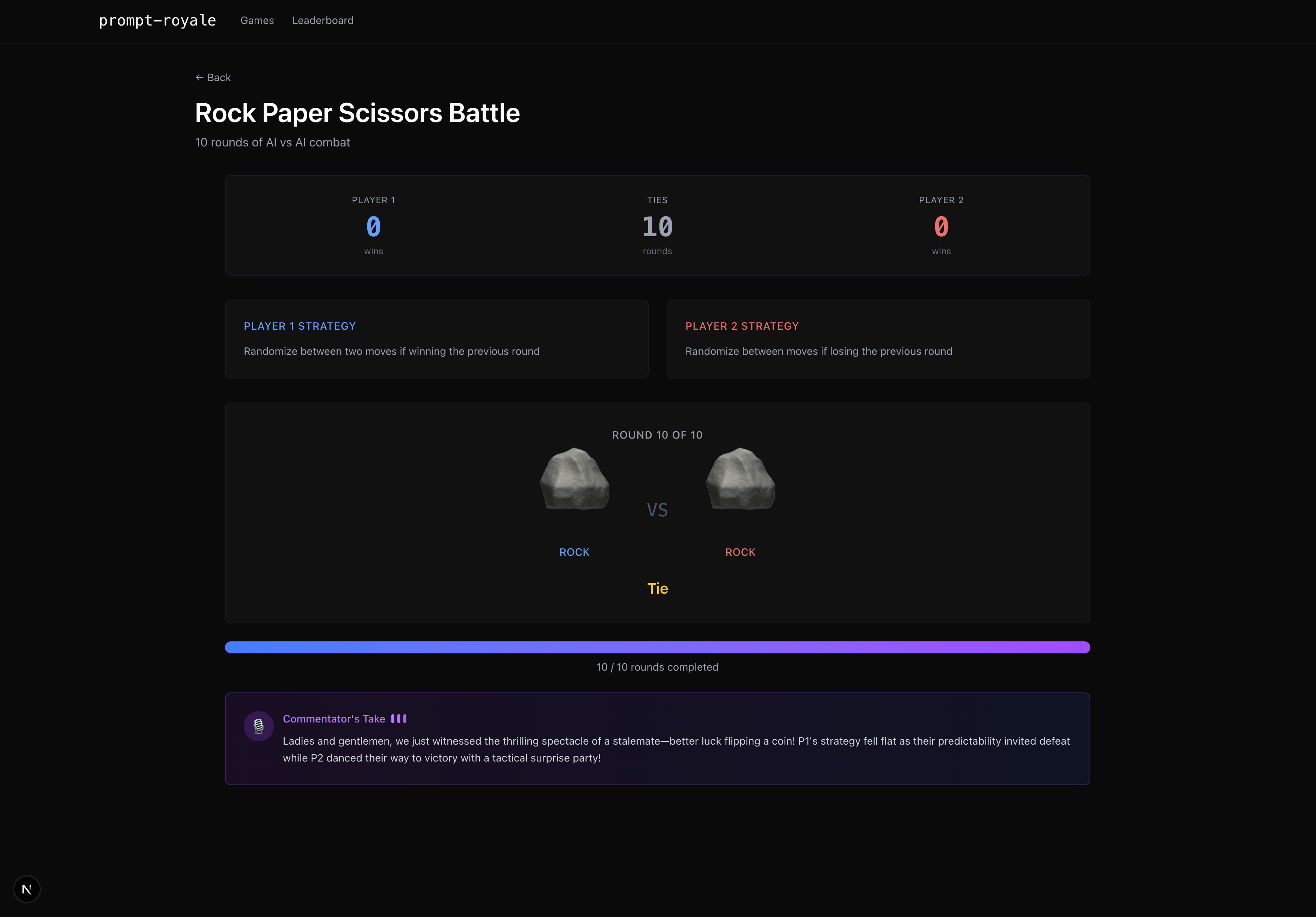
Rock paper scissors game
Inspiration 💡
Everybody’s busy benchmarking LLMs, but we decided to flip the script and instead benchmark humans on how well they can use LLMs. Since our team is composed of previous national chess champions, competitive Esports and online poker grinders, as well as past interns at poker AI companies like GTO Wizard, we decided it would be fun to test humans’ prompt engineering skills in classic game environments. To that end, we decided to build out the environments of our favorite games like “Guess Who?”, “Battleship”, and even Chess, and let any user compete with one another on who can one-shot prompt their LLM to perform best in these zero sum games!
What it does 🔮
Prompt Royale is a collection of LLM-supported game environments that lets any 2 players craft a strategy prompt, and see the whole simulation of the game unfold, where the LLMs make moves based on your guidance. Concretely, we built 7 games— the classic strategy ones like Rock Paper Scissors, Chess and Battleship, as well as more nuanced, deductive games like “Guess Who?” and “20 Questions”, financial ones like a quantitative trading simulation, and even a creative image reproducibility game where you test if you’re really Bob Ross!
Throughout the game simulation, you get a log of the LLMs’ reasoning for each decision point, as well as an audio recap of the game by our very own voice AI commentator Mark (in the case of the chess environment, he comments live on how well or poorly your LLM plays)! Also, for certain games where there is more subjectivity to which player one, like chess if the game does not end or image reproducibility, we resort in the former case to the Stockfish chess engine evaluation and in the latter case to a LLM-as-a-judge to determine who recreated the original image better. Oh, and we have a live leaderboard ranking who is the best human prompter according to our benchmark!
How we built it 🧱
For the frontend, we relied on Next.js, TypeScript and Tailwindcss for the main app, with streaming APIs so you can watch games unfold move-by-move. We hooked up OpenAI's API for the LLMs and built custom logic for every single game—trust us, implementing Battleship rules at 3am is certainly an experience. The Image Similarity game needed something extra, so we spun up a Flask backend in Python with OpenCV and scikit-image to actually score how similar the generated images are, leveraging Gemini too. We also used the JS Chess library to construct that environment, and some financial APIs to gather real market data for our LLM quant trading game too! To add on, we leveraged a bunch of goated code productivity to be more efficient, like Claude Code, CodeRabbit, and SnapDev, Finally, some particularly exciting libraries we were grateful to have worked with include Lava Gateway to greatly facilitate all our multi-LLM orchestration, as well as Fish.Audio for our in-house AI game commentator.
Challenges we ran into 🚧
Balancing the trade-off of LLM non-determinism with the precise and careful nature of a lot of our games was a very unique challenge! Namely, we had to be smart prompt engineers ourselves to ensure the LLMs under-the-hood were conscious of legal moves and states, previous move histories, sequential player-v-player dynamics and what the win conditions are. It turns out LLMs really like to cheat at chess by spawning non-existent pieces…
In parallel, the Image Recreation game — where a reference image is randomly sampled and the two players need to prompt their respective LLM in as much detail as possible to try to recreate the image as best as they can — is pretty tough to judge! We tried re-implementing some state-of-the-art deterministic image-similarly algorithms like the image whose pixel RGB values minimize the MSE with respect to the reference image, or even more applied-ML approaches. But ultimately Gemini and Lava Gateway came in clutch and we few-shot trained it to consistently be a fair LLM-as-a-judge, assigning each competitor’s image on a scale of 1-10 for image similarity.
Accomplishments that we're proud of 🏆
We actually shipped 7 working games in one weekend, which was insane. Each game is fully playable, with very diverse and different strategies that are supported by our careful organization of LLM memory and context. For instance, in rock paper scissors you can instruct the LLM to do insane strategies like “If the round number is prime play rock, otherwise copy your opponent’s previous move if it’s sunny in Berkeley, otherwise randomize”. (P.S. that strategy does not win very often)
Similarly, the LLM reasoning streaming and pipeline of going from prompt to action within seconds was not easy to implement, and in turn really satisfying to get right. There’s no janky updates or lag. And to accompany that, we actually focused A LOT on getting the UI of the games really sleek and simplistic (check out our images), which is something we normally don’t focus too much about.
Above all though, this was a super fun project to build out due to the very fact that we got to play our games and compete amongst each other along the way! Steve and Max competed on who could make their LLM beat the other more consistently in Chess, while Abraham and Rudy were battling it out with LLM prompts on the Image Reproducibility and Quant Trading games — in the latter, there were a lot of strategies tested out with the LLMs, as advanced as “market make with a $1 bid-ask spread and delta neutral position” all the way to as simple as “buy low, sell high”.
What we learned 📚
We think the coolest thing we learned is that, just as much as the new technologies of tomorrow like LLMs and Voice Agents certainly need to get benchmarked in software-critical environments, humans need to be benchmarked on their ability to efficiently work with this awesome tech too. Also, this is the first-of-its-kind one-shot LLM game competition, but actually a twist on an existing game we sort of forgot about; if you’ve played on Chess dot com before, you might realize this is kind of like their deprecated “Automate” game mode that was loved a by a ton of people. When we made this project, half-way through we actually realized we practically remade that game mode with LLMs.
What's next for Prompt Royale 🚀
There are a few axes we can think along. For one, we can evidently introduce more game modes that might be more indicative of prompt engineering skill, say heads-up poker or less logical and more reasoning-based games like debate. On another note, we can fortify the whole benchmarking idea by introducing a rigorous ELO ranking to be confident that higher rating means that person is objectively (over a large sample size) a better LLM prompter. Lastly, we think this data could be super useful for a lot of HCI-related studies, and so we would love to support any research initiatives there with our gamified platform. And one last avenue: there’s tons of cool community-related stuff we can do here, like sharing community member’s coolest prompts to play chess like a GrandMaster, or give advice on how to effectively teach your LLM to trade markets in the quant game profitably. There’s probably a lot for people who use LLMs regularly to take away from such a platform, and we’ d totally want to support that dissemination of knowledge! :)
Built With
- chess.js
- claude
- claude-code
- coderabbit
- fish.audio
- gemini
- lava
- lava-gateway
- nextjs
- openai
- python
- react
- snapdev
- supabase
- tailwindcss
- typescript




Log in or sign up for Devpost to join the conversation.