Inspiration
Numbers about AI training energy consumption kept being alarming yet vague. Then came grokking: tiny models first memorize, then much later "suddenly" generalize. The thing is nobody knows when it happens, so we have long and fixed schedules of training "to be safe". This means the computer keeps sucking power long after the model has stopped learning anything. So there was clearly some measurable, preventable waste and we decided to quantify it and prevent it.
What it does
PowerDown makes wasted energy obvious and easy to fix in an intuitive macOS xcode application since we:
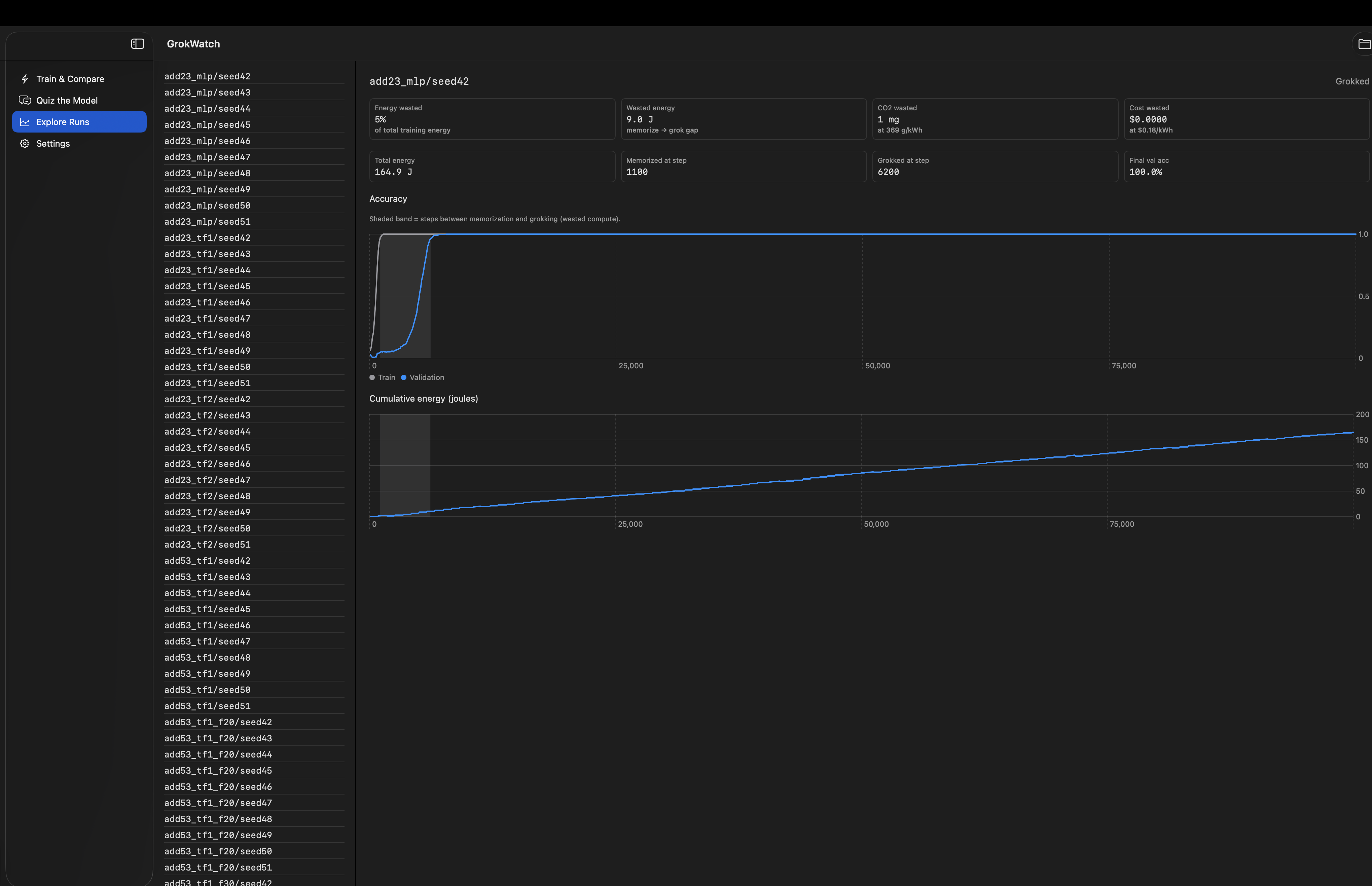
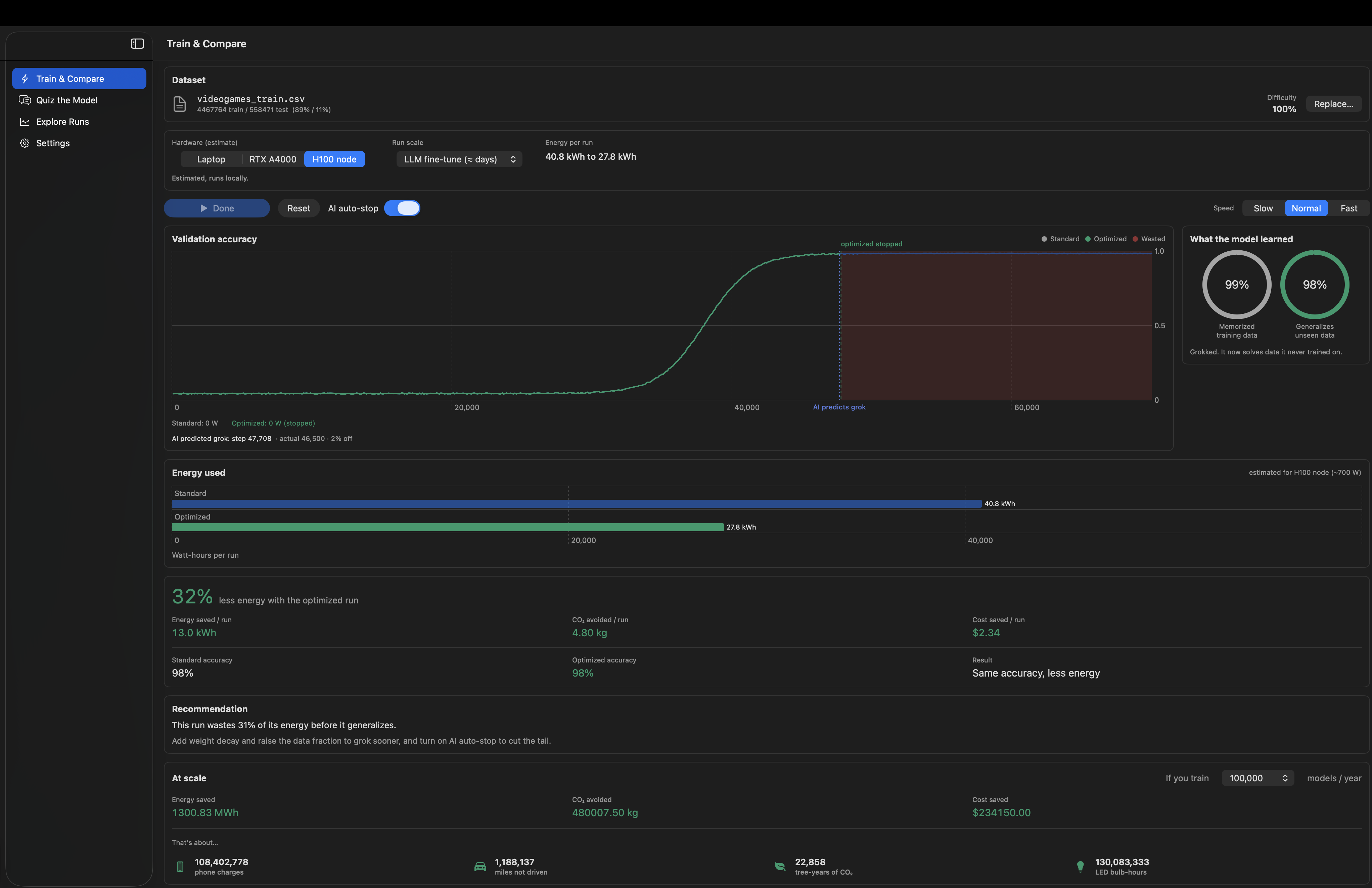
- Train & Compare runs a usual training session and an optimized one side-by-side. Optimization stops when accuracy plateaus; the difference is the energy wastage, measured live in Watt hours, CO₂, and dollars plus, extrapolated to fleet-scale (1,000-1,000,000 runs per year), in terms such as charges and distances not traveled. Since we can't simulate a huge run in a couple minutes, we can scale the results so that we can see the true scope of this project.
- AI auto-stop applies a machine-learning model trained on real PowerDown runs and stops the model proactively after the initial few thousand steps where the grok step is predicted.
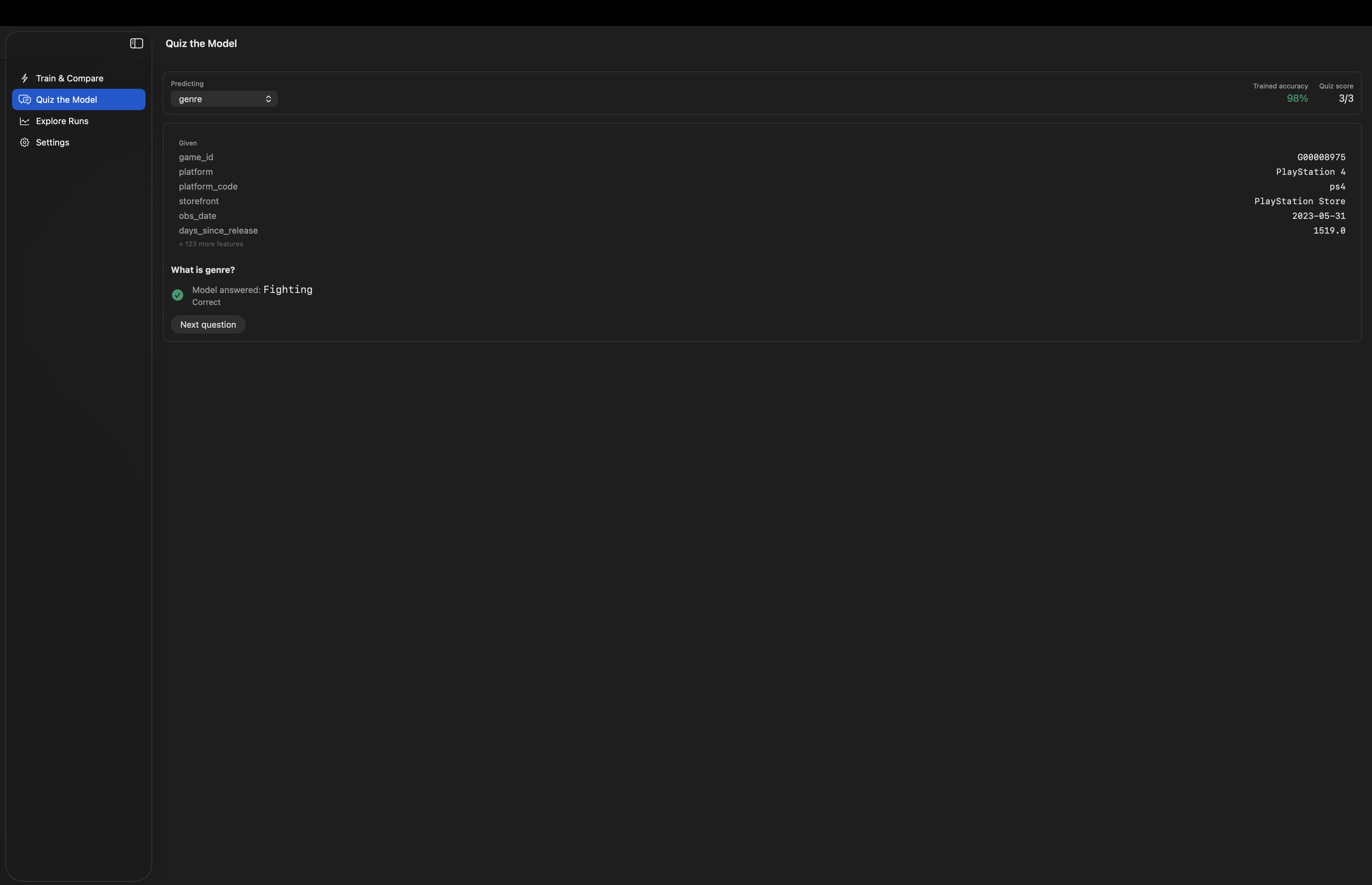
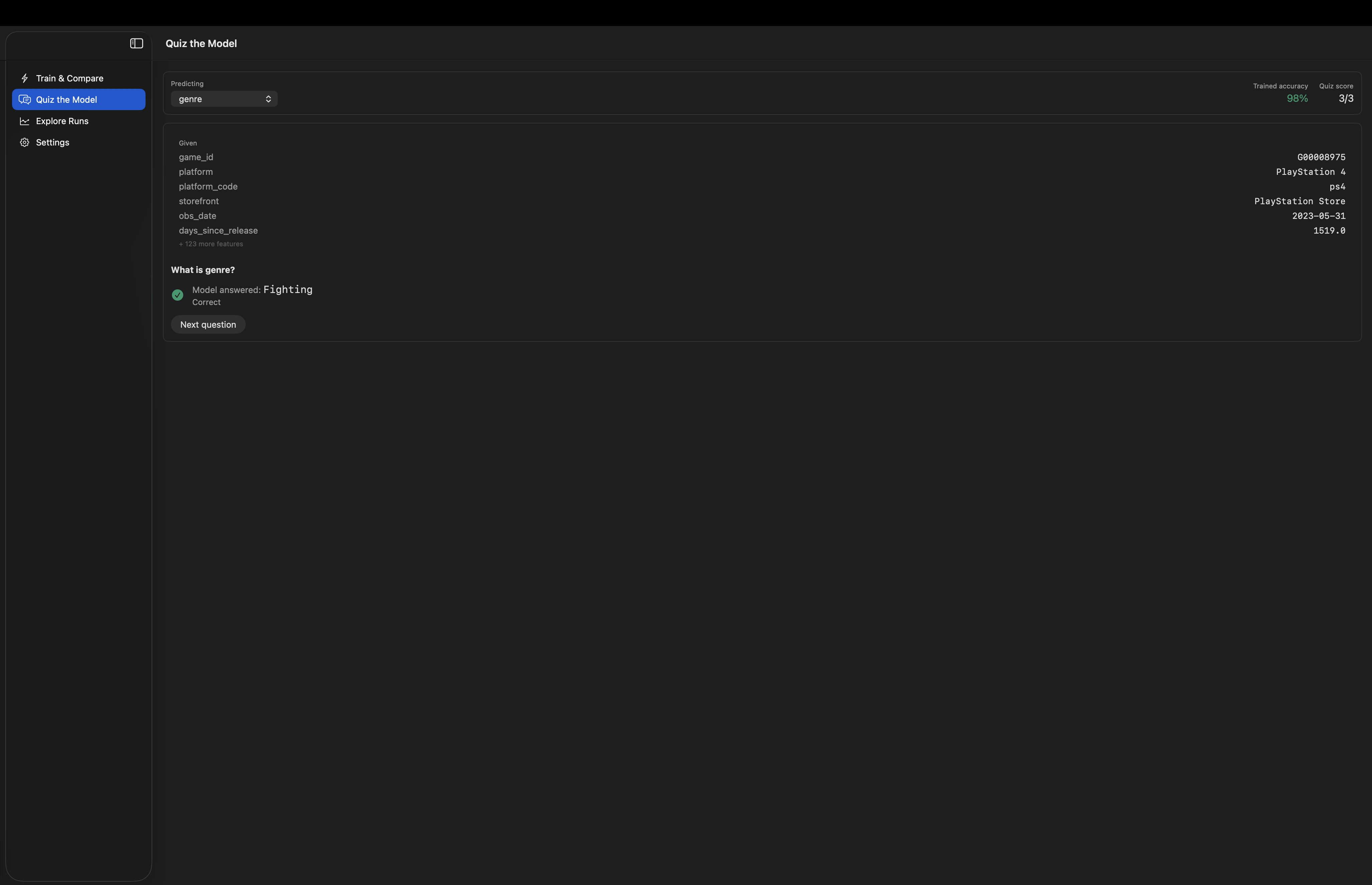
- Quiz the Model: it asks held-out questions from your dataset to the model: it gives the wrong answer before groking and corrects after, this way, you experience generalization in real time.
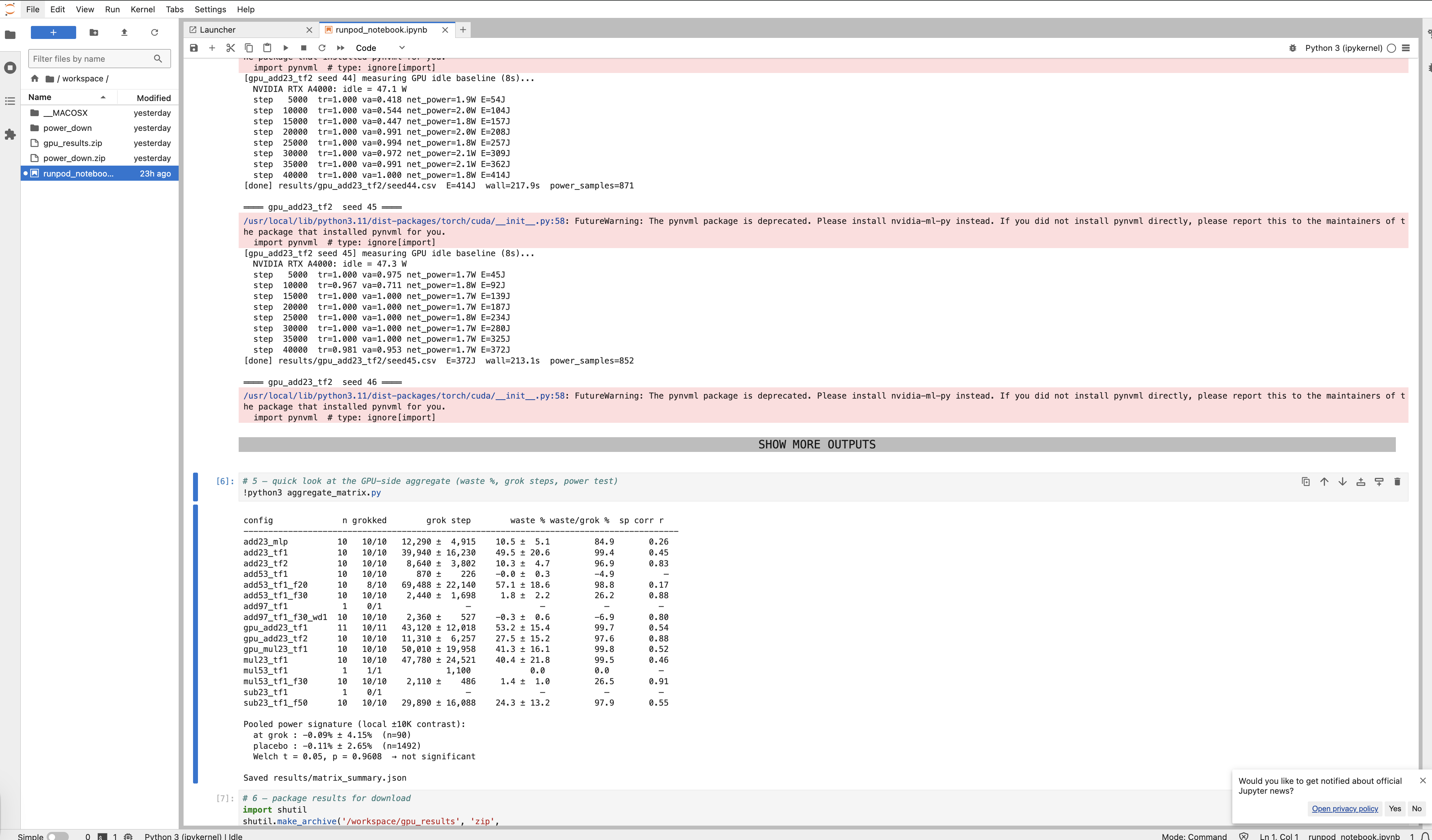
- Explore Runs shows our real experiment logs (on two different types of GPU hardware) and predicts grok on them with our predictor.
How we built it
We have trained dozens of transformers and MLP models on modular arithmetic using PyTorch with various hyperparameter configurations and across seeds. While doing that, we recorded the power metrics on each step on real hardware (Apple M4 Max and RTX A4000 GPU rented from RunPod), subtracted an idle power baseline for the actual energy consumed. And then we discovered that ~24% of training energy in average, and 57% for more complicated tasks, is consumed post-generalization. Across two very different kinds of hardware as well.
Machine learning: Then, a linear scikit-learn model has been trained to predict the grok moment with high accuracy, given the early features of training (norm of gradients, activation sparsity, training-validation gap).
Application UI. An application written with the help of SwiftUI framework in a native macOS app, running a fast and accurate simulation of grok dynamics in real-time, so it takes seconds to compare the usual and the energy-optimized training, with the predictor integrated in native code (thus eliminating all network calls). Most of the design of this app was coded by Rudra in Xcode
Challenges we ran into
- A GPU consumes power even while idle, so we had to take into account to record and subtract the baseline to get the real power of training.
- Early stopping in grokking is hard as well. Validation accuracy of the model is low during memorization and remains flat for a while until it jumps during grokking, which means that the classical "stop training once improvement stops" approach will result in a premature stop. It was necessary to detect the high rather than any plateau. Having a premature stop will result in a MASSIVE decrease in accuracy around ~30%.
- Integrating ML without a backend. scikit-learn won't run in native code, so we had to retrain a standardized linear ML predictor and have learned weights.
Built With
- scikitlearn
- swift

Log in or sign up for Devpost to join the conversation.