-
-

The landing page of The PaperBook
-
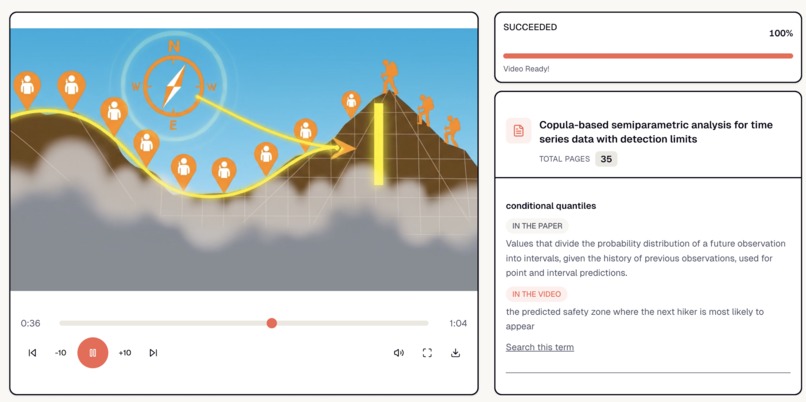
The PaperBook processed a 35-page paper
-
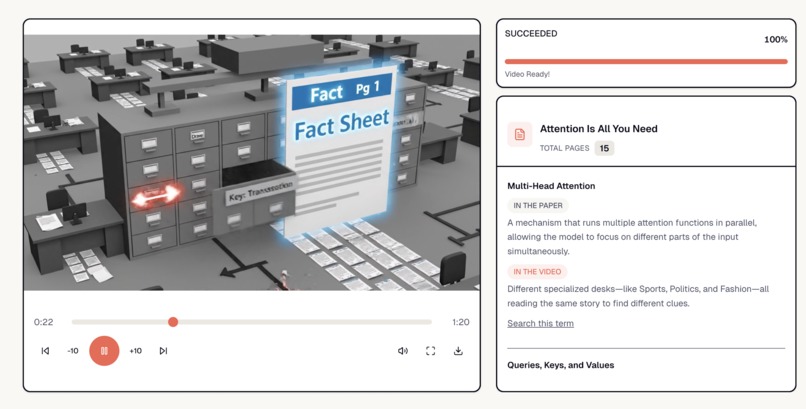
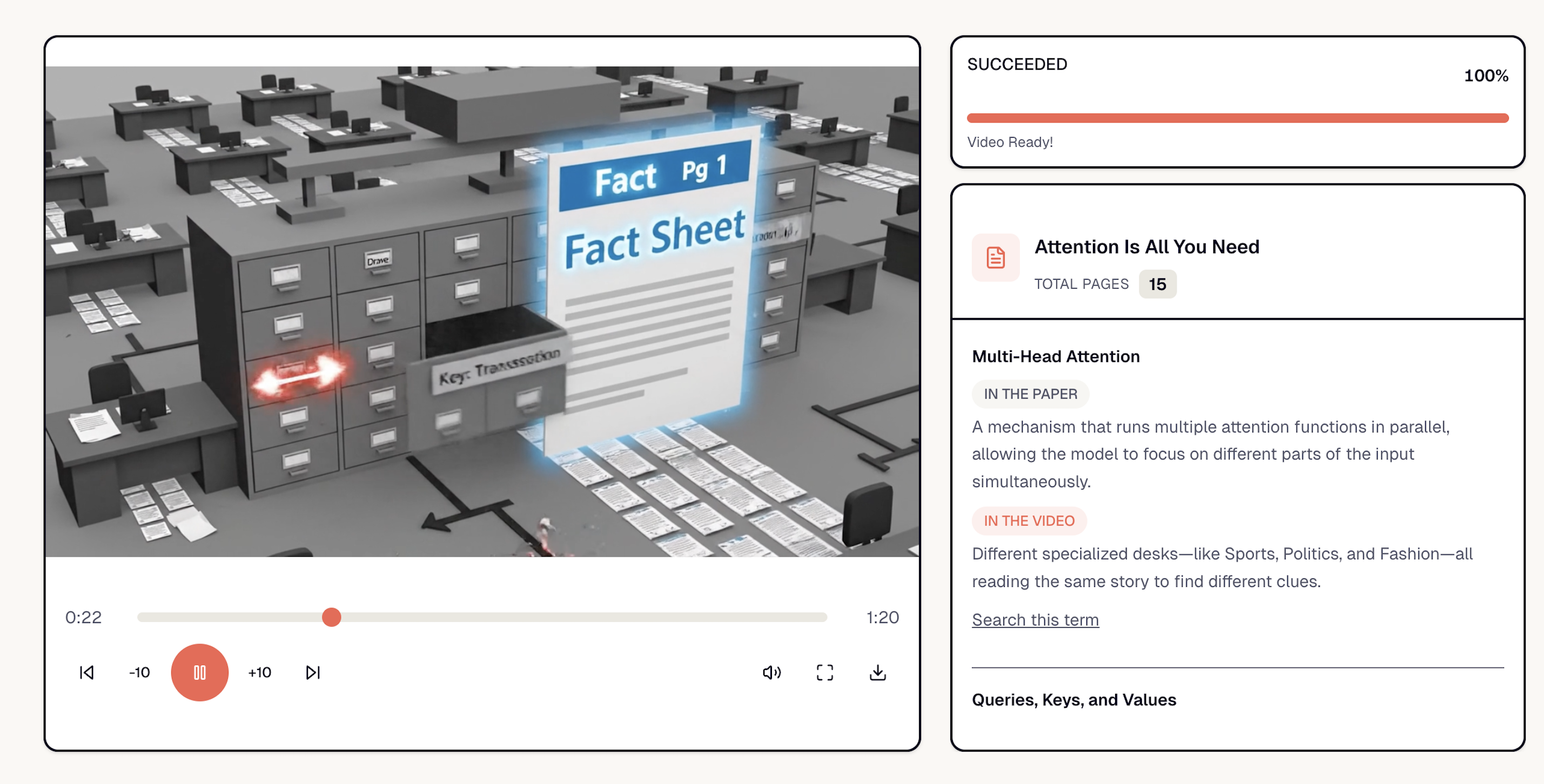
The PaperBook generated explainer video with native on-screen-text and audio


Inspiration
Every year, millions of scientific papers are published, yet only a small fraction of their ideas are widely understood beyond expert circles. This is not a problem of complexity, but of representation.
Research papers are designed for scholarly audiences, and even educated readers often need significant time and background knowledge to grasp their core ideas.
Existing AI tools mainly summarize text, and even video-based systems treat visuals as background rather than explanation. They do not produce true science explainers.
PaperBook addresses this gap.
It enables AI to understand a research paper’s core ideas and reconstruct them into explainer videos using everyday analogies, so complex research can be understood by a much broader audience.
What It Does
PaperBook takes a research paper, digests its core reasoning, and translates key ideas into everyday analogies—reconstructing them as short explainer videos for fast, intuitive understanding by non-experts.
Each scene is grounded in a traceable internal reasoning chain, ensuring the visuals explain the science rather than decorate a text summary.
How We Built It
We built a verifiable multimodal reasoning system that reconstructs scientific knowledge, using Gemini 3 as the intelligence layer and Veo as the video generation layer.
Instead of chunking or retrieval-based generation, the system ingests the full research paper with holistic document awareness, allowing Gemini 3 to reason over text, formulas, and figures together.
The paper is distilled into a structured, traceable intermediate representation that captures core claims and their dependencies. This ensures every visual metaphor is grounded in the paper’s original logic rather than free-form generation.
Guided by this representation, Gemini 3 orchestrates Veo to generate video scenes that stay semantically aligned with the underlying reasoning—so the visuals explain the science, not just decorate the narration.
Challenges We Ran Into
Latency vs. Consistency
Because Veo can only generate short video clips at a time, multi-minute explainer videos must be stitched from many segments. Video extension remains sequential and slow, while naïve parallel generation causes visual and semantic drift across scenes.
We solved this by using Gemini 3’s long-context reasoning as a shared global memory, maintaining scientific and visual consistency across parallel video generation.
This reduced end-to-end latency from >20 minutes to ~5 minutes, while keeping scenes visually and semantically consistent.
Fidelity vs. Creativity
In scientific storytelling, visually compelling metaphors fail if they misrepresent the science. Early experiments showed that unconstrained generation often traded rigor for visual flair.
We addressed this by grounding every visual metaphor in a traceable, auditable reasoning structure generated by Gemini 3, so each analogy must pass a consistency check against the paper’s logic before being rendered.
Accomplishments That We’re Proud Of
We shifted scientific communication from Text-First to Intuition-First, building a system that reconstructs research papers into explainer videos that preserve scientific logic and intent, rather than summarizing text with decorative visuals.
High-fidelity reasoning at scale.
By leveraging Gemini 3’s long-context, multimodal reasoning, the system compresses entire papers into concise visual explanations without losing the underlying “why.”
Video as meaning, not decoration.
Gemini 3 acts as a reasoning director, ensuring visual metaphors are derived from the paper’s internal logic, so the video itself carries the scientific explanation.
Production-ready reliability.
A structured, auditable reasoning layer enables parallel video generation, reducing end-to-end latency from ~20 minutes to ~5 minutes while maintaining scientific rigor.
Together, these advances demonstrate that generative AI can deliver intuition at scale without sacrificing correctness.
What We Learned
Reasoning over prompting.
Gemini 3 is most effective when treated as a reasoning system rather than a black-box generator, enabling logic-grounded explanations instead of surface-level outputs.
Multimodal systems don’t scale like text.
Video generation requires asynchronous, parallel orchestration to achieve low latency and practical user experience.
Trust requires structure.
Reliable scientific explanation depends on auditable reasoning, not just better prompts—turning free-form generation into verifiable logic.
What’s Next for PaperBook
Interactive co-reasoning.
Move from static explainer videos to a bi-directional experience, where users can pause an analogy and trace it back to the exact claims or evidence in the original paper.
This is a low-hanging feature: the system already preserves step-by-step intermediate reasoning, and Gemini 3’s long-context reasoning and context caching make it possible to retrieve and explain these links on demand without reprocessing the paper.
From papers to ideas.
Connect related studies into a living research graph, helping users understand how scientific ideas evolve across time rather than in isolation.
Because PaperBook reconstructs papers into structured representations, linking papers becomes a matter of connecting compatible reasoning structures rather than re-reading raw text.
Cross-domain discovery.
Reveal structural similarities across fields by reconstructing papers into shared representations, enabling insights and solutions to transfer between disciplines.
With Gemini 3’s long-context reasoning across multiple papers, structural patterns can be compared directly, even when domains use different surface language.
Gemini 3 Integration
PaperBook leverages Gemini 3 as a multimodal reasoning engine powering a logic-grounded video generation pipeline. Gemini integration is central to the system in four key ways:
1. Holistic Reasoning.
Unlike lossy RAG pipelines, we use Gemini 3’s long-context window to ingest full research papers as unified documents—including text, technical notation, and visual elements. This preserves the paper’s global scientific logic, which is essential for faithful explanation rather than fragmented summarization.
2. Semantic Grounding.
Using Gemini 3’s JSON-mode, the system generates a schema-validated semantic DAG capturing scientific claims, definitions, and dependencies. This structured intermediate layer replaces unconstrained generation with an auditable reasoning chain, ensuring every visual metaphor is grounded in verifiable source logic.
3. Distributed Multimodal Orchestration.
Gemini 3 acts as a Multimodal Director for the Veo video generation API. By treating the long-context state as shared global narrative and style memory, it orchestrates parallel video generation calls while maintaining semantic and visual consistency. This reduces end-to-end latency from ~20 minutes to under 5 minutes.
4. Controllable Reasoning Depth.
We dynamically tune Gemini 3’s behavior—enforcing deterministic logic for scientific claims while allowing exploratory synthesis for intuitive analogies.
Together, these capabilities make Gemini 3 the indispensable intelligence layer, enabling a transition from Text-First to Intuition-First scientific communication at production scale.
Built With
- firebase
- gemini
- google-cloud
- python
- react
- vercel
- vertex

Log in or sign up for Devpost to join the conversation.