-
-
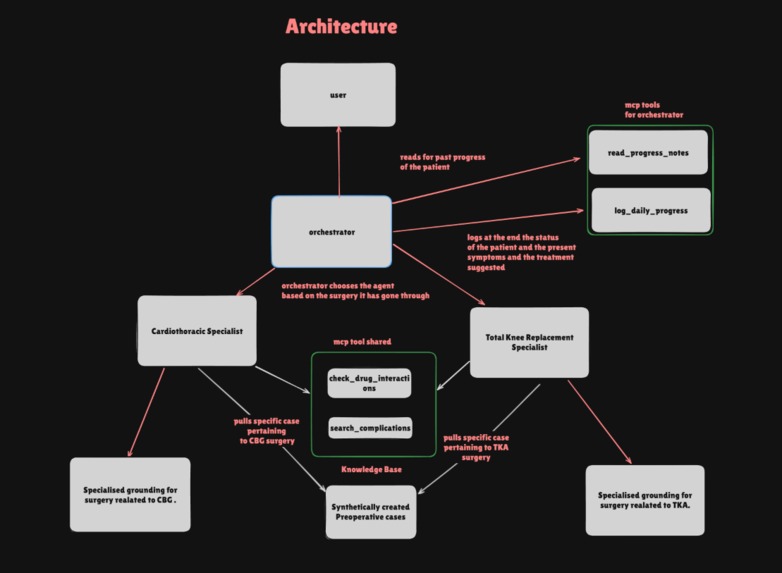
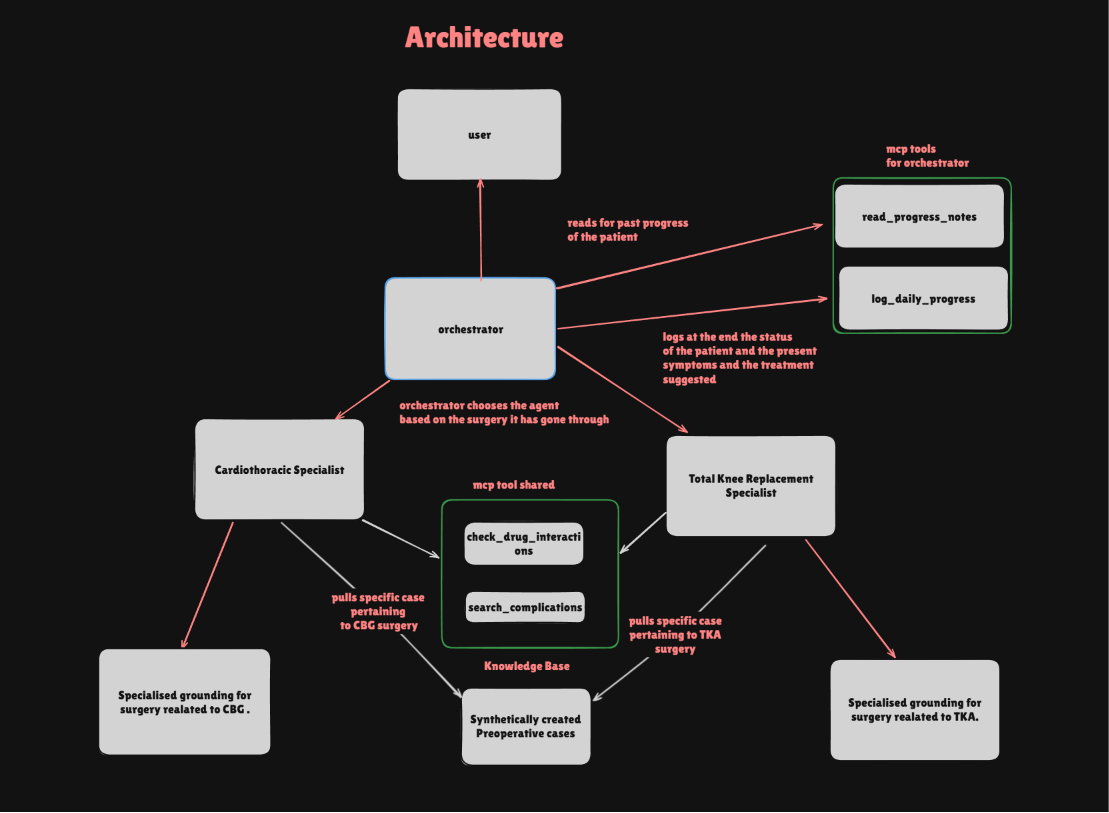
Propose Architecture
-
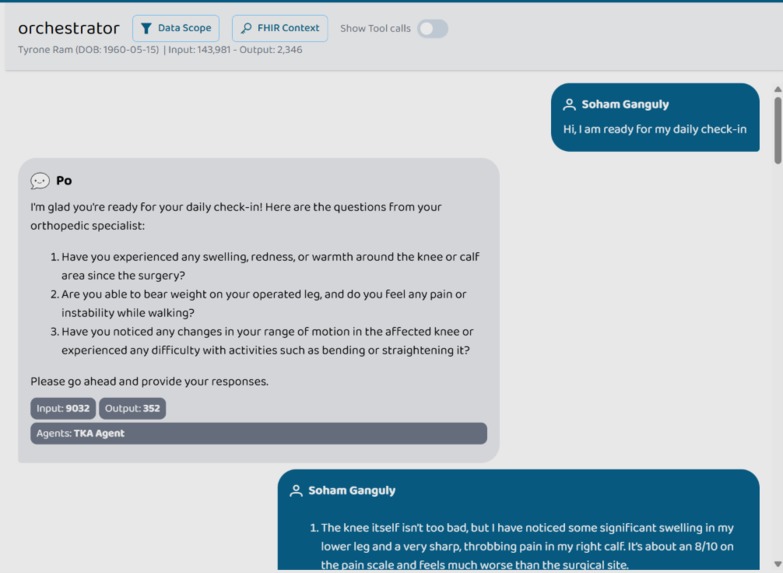
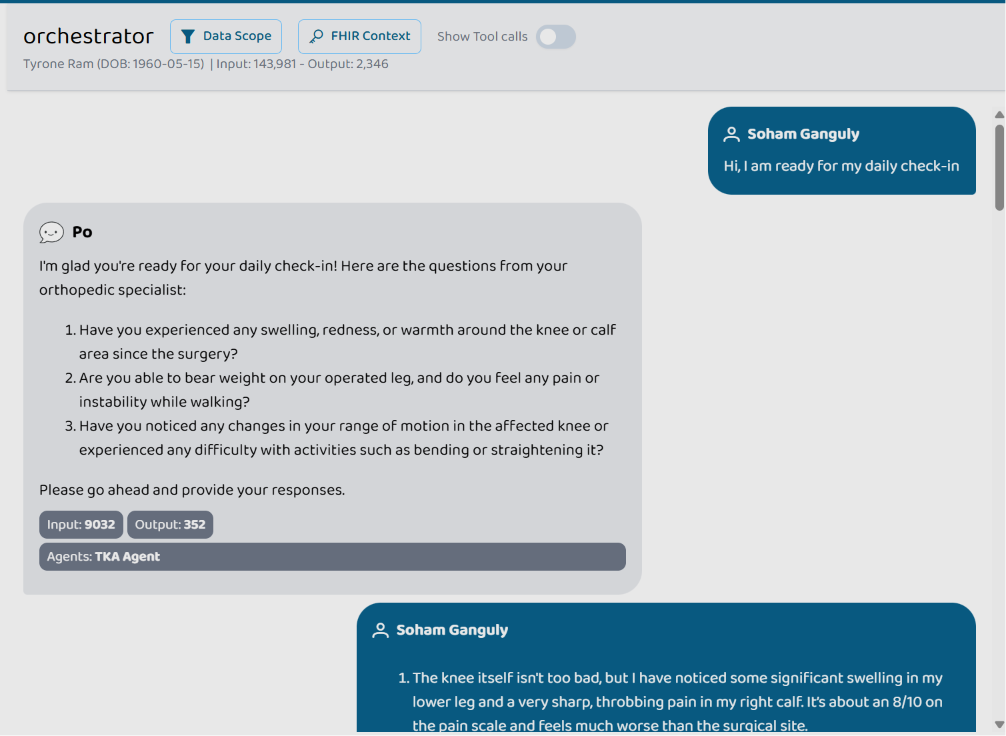
Conversation with orchestrator after consultation with tka agent
-
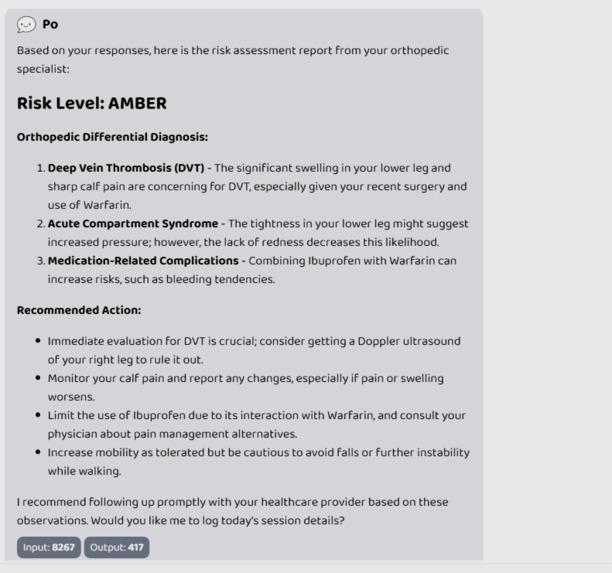
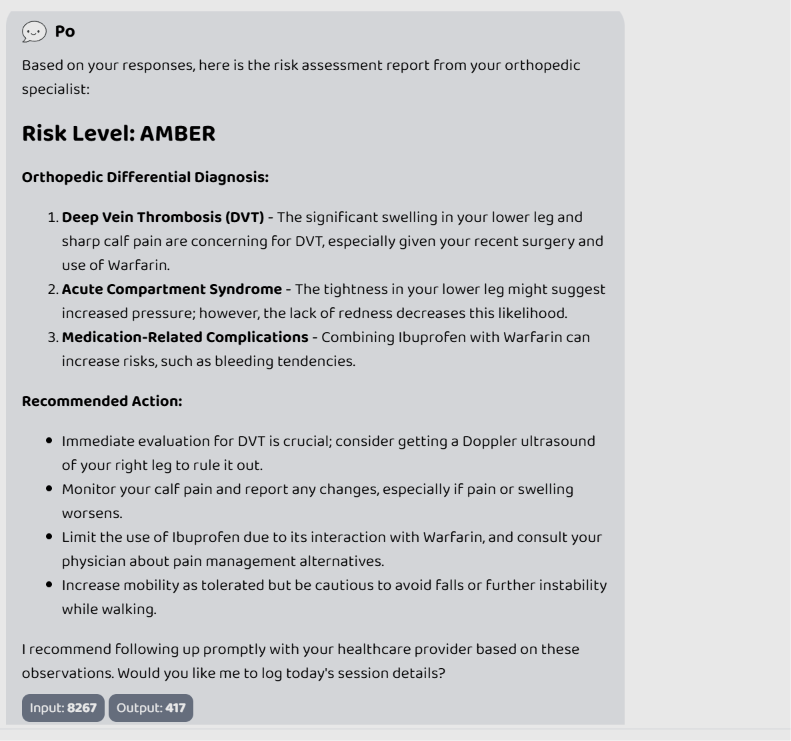
Risk level analysis by the TKA agent
-
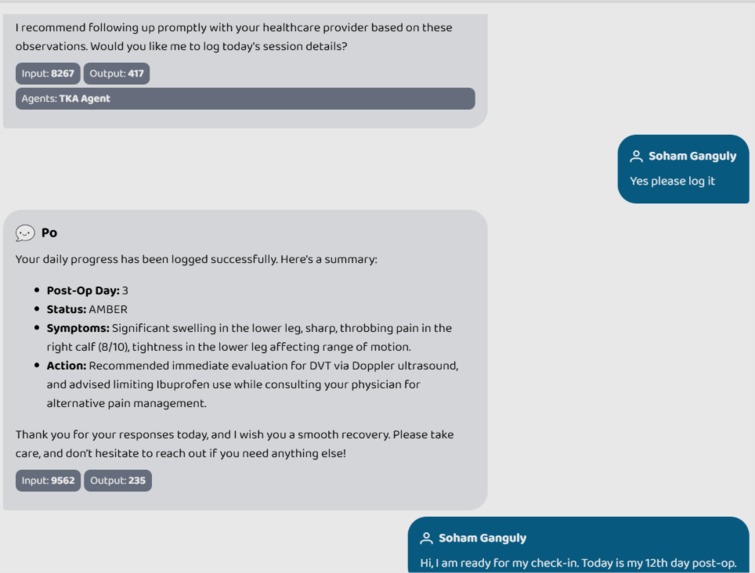
logging of the progress by orchestrator

PostOp Guardian
Inspiration
Post-operative care is one of the most dangerous gaps in modern healthcare. Patients are sent home after major surgery with a discharge pamphlet and a follow-up appointment weeks away. In that window, life-threatening complications—such as DVT, pulmonary embolism, and surgical site infections—can develop silently. I asked: What if an AI agent could perform the daily check-in that busy surgeons cannot?
What it does
PostOp Guardian is an autonomous multi-agent system that conducts daily post-operative check-ins with patients. It:
- Reads FHIR medical records to understand the patient's demographics, medications, and clinical history.
- Consults surgical domain specialists for expert-level diagnostic reasoning.
- Asks personalized, targeted questions based on the specific recovery stage and previous day's progress.
- Triangulates evidence across peer-reviewed literature (PubMed) and pharmacovigilance data (OpenFDA).
- Maintains a longitudinal recovery log that persists across sessions, giving every patient a continuous care narrative rather than a one-off chatbot interaction.
How I built it
I built the system on the Prompt Opinion agentic platform using a robust three-layer architecture:
- Layer 1 — Orchestrator: A conversational agent that interacts with the patient, fetches FHIR data, and routes to specialists via A2A messaging.
- Layer 2 — Specialist Agents (TKA, CABG): Domain experts that apply a structured Decision Tree. They consult the Knowledge Base, run PubMed searches with demographic-aware queries, and check OpenFDA data.
- Layer 3 — Custom MCP Servers: Two Python-based Model Context Protocol (MCP) servers providing longitudinal memory and real-time clinical grounding.
Agents on the Platform
| Agent | Role | Tools Available |
|---|---|---|
| Orchestrator | Patient Interface & Routing | read_progress_notes, log_daily_progress |
| TKA Specialist | Orthopedic Evidence Auditor | check_drug_interactions, search_complications |
| CABG Specialist | Cardiothoracic Evidence Auditor | check_drug_interactions, search_complications |
MCP Servers & Clinical Tools
1. Orchestrator MCP Server (Memory Layer)
-
read_progress_notes: Returns the last 7 days of patient history to ensure the agent understands the "trend" of recovery (e.g., pain worsening over 3 days). -
log_daily_progress: Persists a structured daily entry containing patient status, symptoms, and actions taken.
2. Clinical Assessor MCP Server (Grounding Layer)
-
check_drug_interactions: Queries OpenFDA FAERS database to identify if patient symptoms (like nausea or dizziness) are known side effects of their specific medication regimen. -
search_complications: Queries PubMed to find titles and conclusions of peer-reviewed papers matching the patient's symptoms, surgery type, and age.
Challenges I ran into
- The "Generic Assessor" Flaw: A single generic agent lacked the depth to spot nuanced surgical risks. Guided by a senior anesthesiologist(my father), I pivoted to a domain-specialist model and synthesized an expert case history (
dr_smith_case_history) as the primary grounding source. - The "If/Else" Trap: Initially, the Knowledge Base acted as a strict gate. If a case wasn't in the KB, the agent escalated immediately. I realized a 20-case database is too small for TKA complications, so I built a Triangulation Engine: PubMed → KB → OpenFDA. The system only escalates if all three fail.
- Agent Hallucination: The Orchestrator would often say "I am launching an interface" instead of actually asking the specialist's questions. I fixed this with HARD CONSTRAINT language in the prompts to prohibit conversational filler.
- Infinite Tool Loops: Specialists would occasionally call the same tool in a loop. I implemented an in-memory result cache to detect duplicate calls and force the agent to finalize its clinical report.
Accomplishments that I am proud of
- Clinical Standard Integration: Risk levels follow the NEWS2 (National Early Warning Score 2) protocol. 🔴 RED, 🟡 AMBER, and 🟢 GREEN statuses are defined by clinical semantics, making them immediately actionable for doctors.
- True Longitudinal Care: The system remembers a "Day 3 AMBER" status and proactively asks follow-up questions on Day 12 to check for resolution.
- Clinical Humility: When presented with nonsensical symptoms (e.g., "neon green rash" post-knee surgery), the system correctly found no link in the literature and triggered an Out-of-Scope Override rather than hallucinating a diagnosis.
- Demographic-Aware Retrieval: PubMed queries now dynamically include age, gender, and comorbidities, ensuring the evidence is clinically specific to the patient profile.
What I learned
- Multi-Agent Prompting: It is fundamentally different from single-agent prompting. Every instruction must account for what the agent should do when data is missing or ambiguous.
- Standards Matter: Using the NEWS2 protocol gave the outputs immediate clinical legitimacy. A doctor cannot act on a "yellow" status unless they know the semantic rules behind it.
- Interoperability: FHIR transaction bundles require
urn:uuid:internal references to ensure resources remain linked after server-side ID generation.
What's next
- Direct EHR Write-back: Enabling the agent to post structured daily logs directly back to Epic/Cerner via FHIR.
- Multi-Modal Wound Tracking: Using vision models to analyze photos of surgical sites for signs of infection or dehiscence.
- Wearable Integration: Pulling real-time vitals (HR, SpO2, step count) via Apple Health or Fitbit into the NEWS2 score.
- Agentic Scheduling: Automatically booking emergency follow-up appointments the moment a "RED" status is detected via the hospital's scheduling API.


Log in or sign up for Devpost to join the conversation.