-
-
Novus Dashboard - Agent Installation Confirmation
-
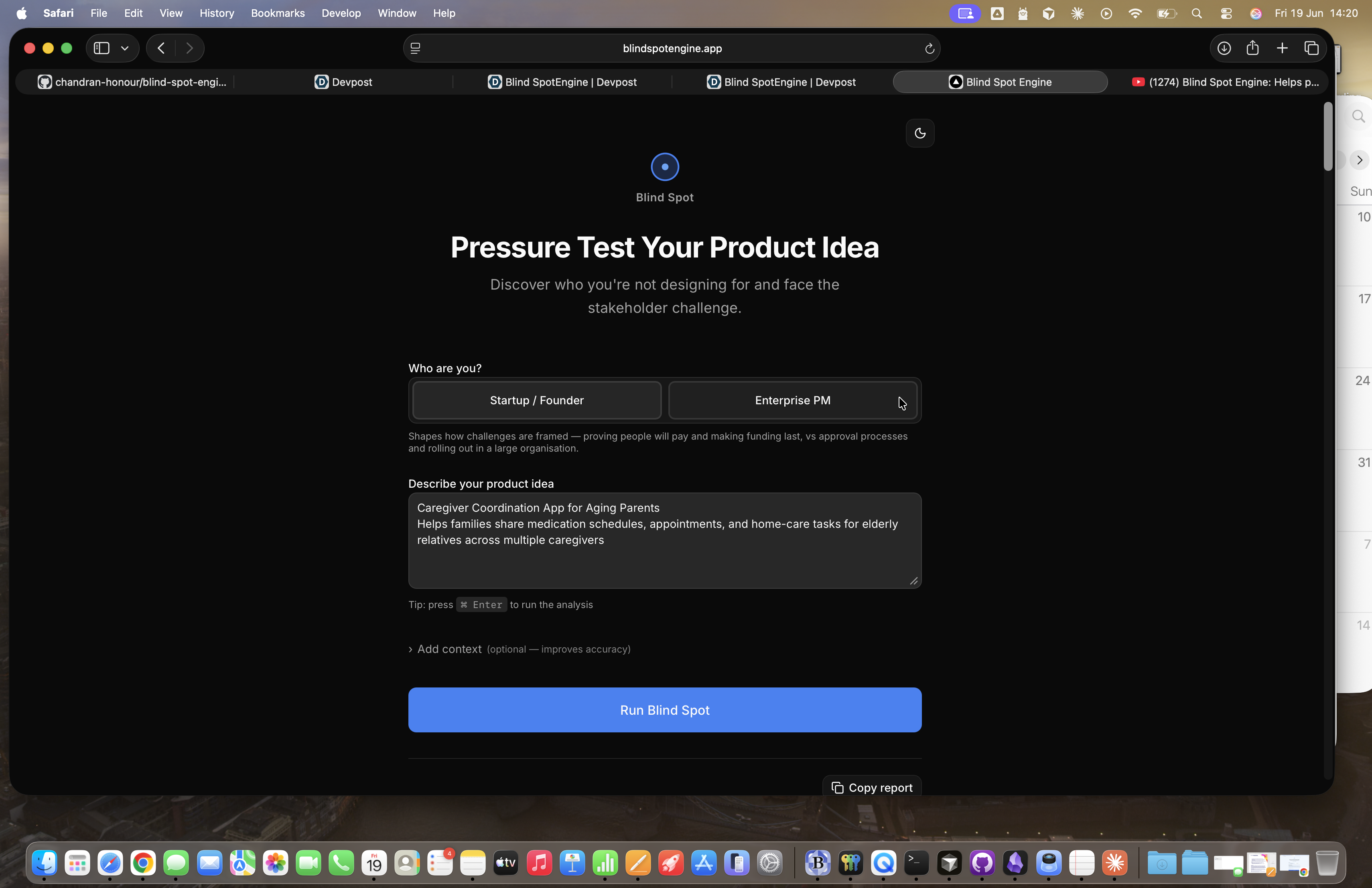
Blind Spot Engine Homepage Form
-
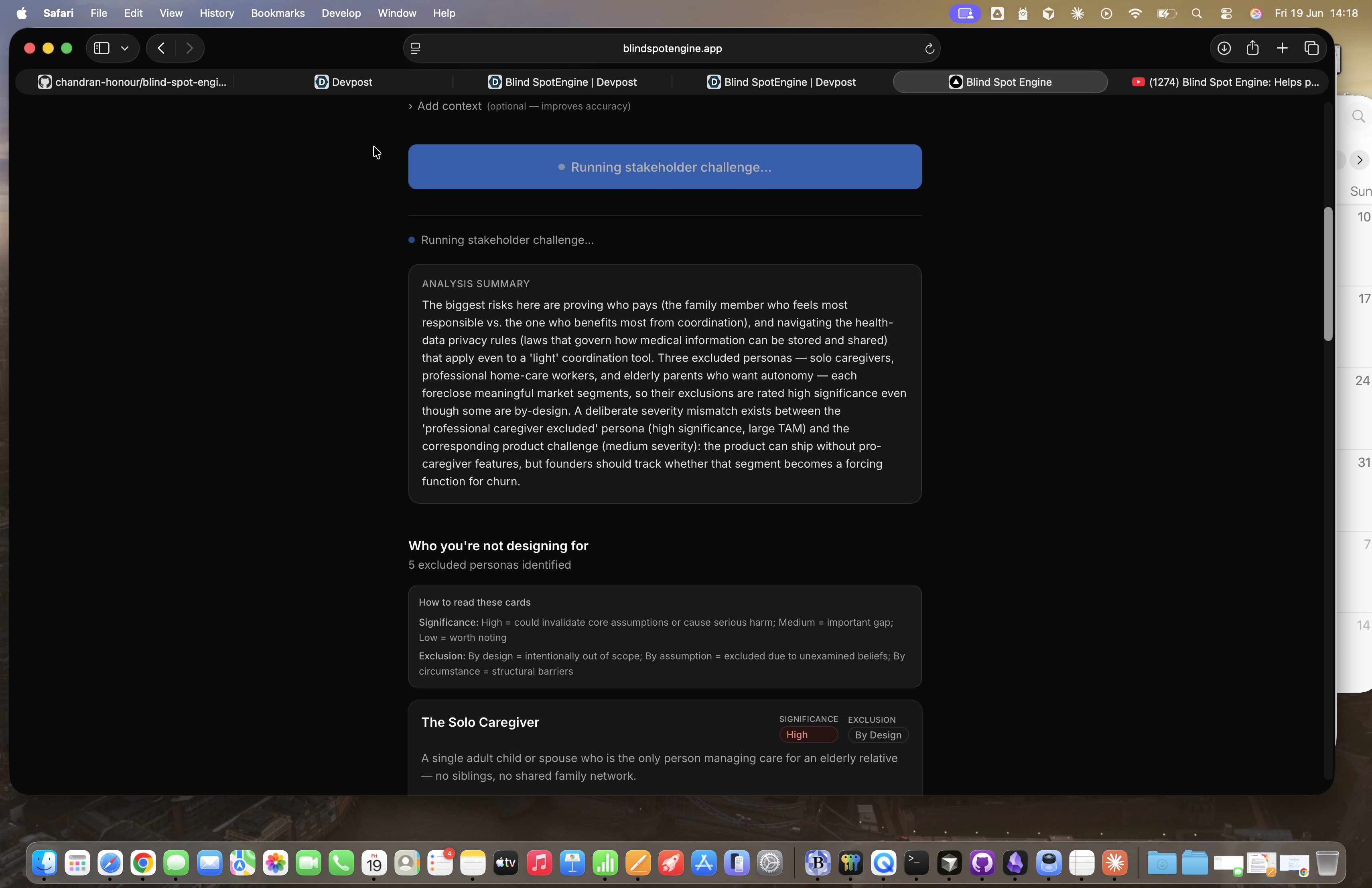
Blind Spot Engine - Analysis Summary - Who you're not designing for
-
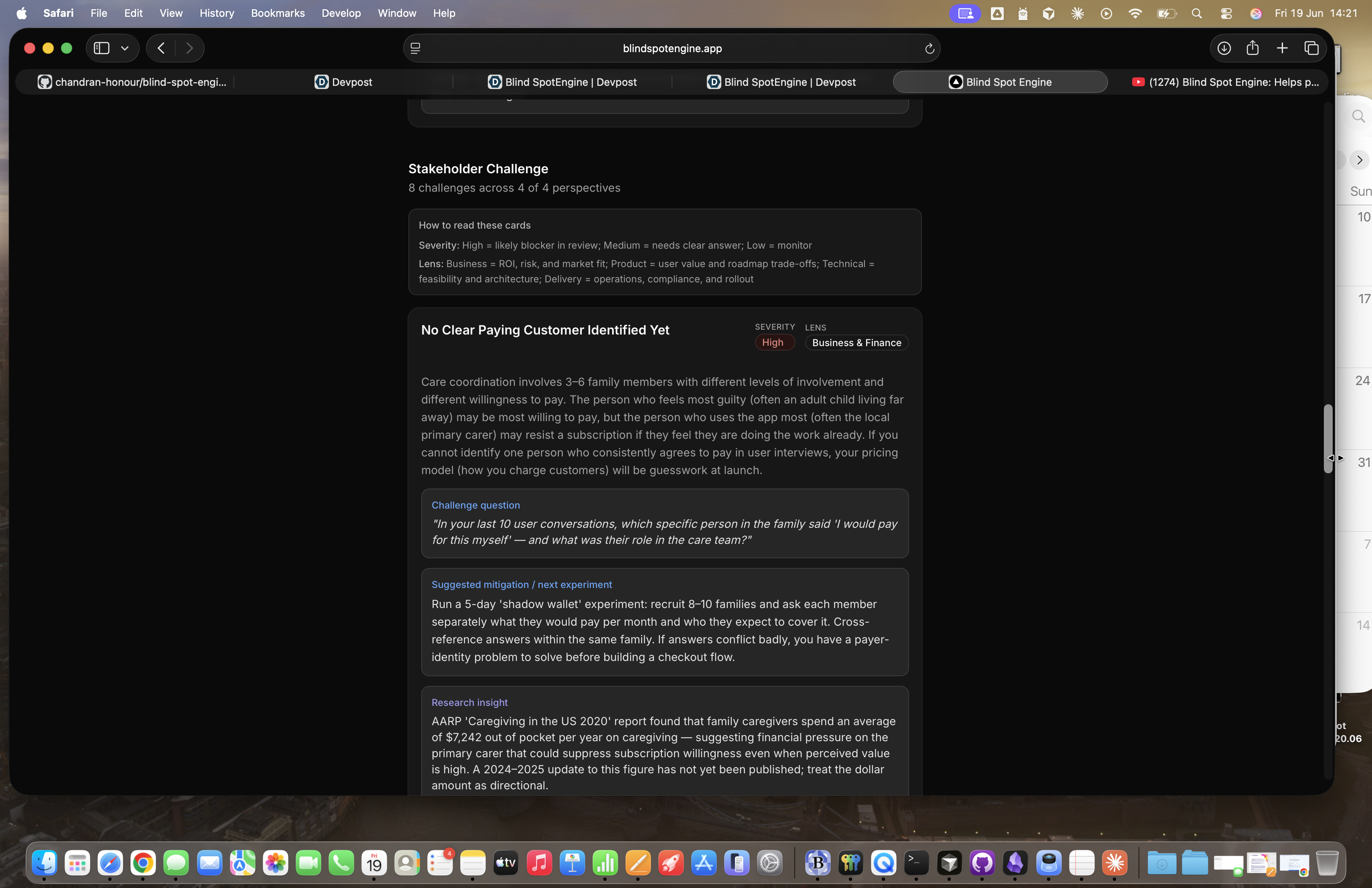
Blind Spot Engine - Stakeholder Challenges
Blind Spot Engine — Project Write-Up
Mind the Product Hackathon · June 2026
Inspiration
I've spent my career building products from two different angles; running my own web development company as a founder, and working as a product manager inside organisations. The problems look different from each side of that fence, but one thing has been consistent throughout: it's surprisingly hard to get genuinely useful, well-informed challenge on a product idea before you've committed to it.
As a founder, the advisers available to me weren't always close enough to the specific context, the market, the customer, the technical constraints to give advice that was more than general. As an organisational PM, colleagues are often working from their own functional lens, which is valuable but partial. In both cases, the structured, cross-discipline challenge that would surface the risks you haven't thought of the finance concern, the operational blocker, the technical edge case, the user segment you're quietly excluding, tends not to happen, or happens too late, or only surfaces after someone has already made a costly assumption.
What I needed, in both contexts, was access to a knowledgeable sparring partner who understood the specifics of what I was building well enough to push back with authority. Someone who could play the sceptical CFO, the burned ops lead, the engineer who'd seen this exact architecture before and watched it struggle and who would tell me the truth rather than be encouraging.
The insight was that large language models, given the right frame and enough context, can do exactly that. Not as generic advice-givers, but as specific, contextually grounded personas with legitimate concerns about your idea, not product building in the abstract. A handful of informal conversations with fellow builders have confirmed I wasn't alone: structured risk analysis was the step everyone knew they should and didn't do at all or didn't do enough of. It's uncomfortable, it takes time, and when you're working without ready access to the right expertise there's nobody to push you into it.
Blind Spot Engine is the attempt to make that step automatic, specific, and crucially, honest.
What It Does
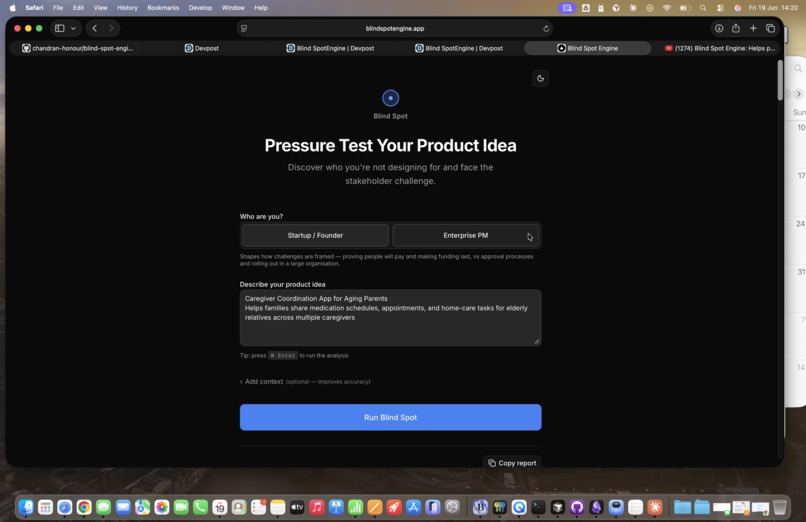
The engine takes a product idea and optional structured context (target market, development stage, team constraints, what's already been validated), then runs two phases of analysis powered by Claude.
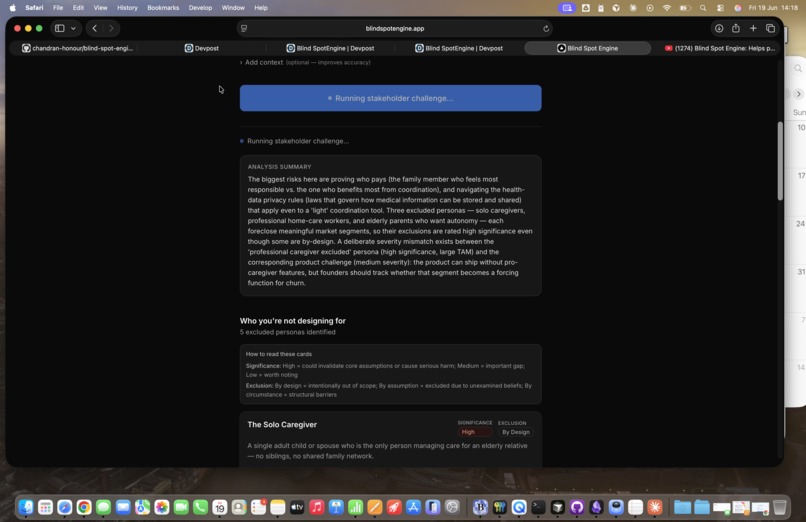
Phase 1 — Excluded Personas. Who does your product structurally leave out, and why does that matter? Each persona is tagged with its exclusion type (By Design, By Assumption, or By Circumstance), a significance rating, and a design implication. The goal is to surface the users you're unconsciously building for and the ones you're not — before a customer points it out.
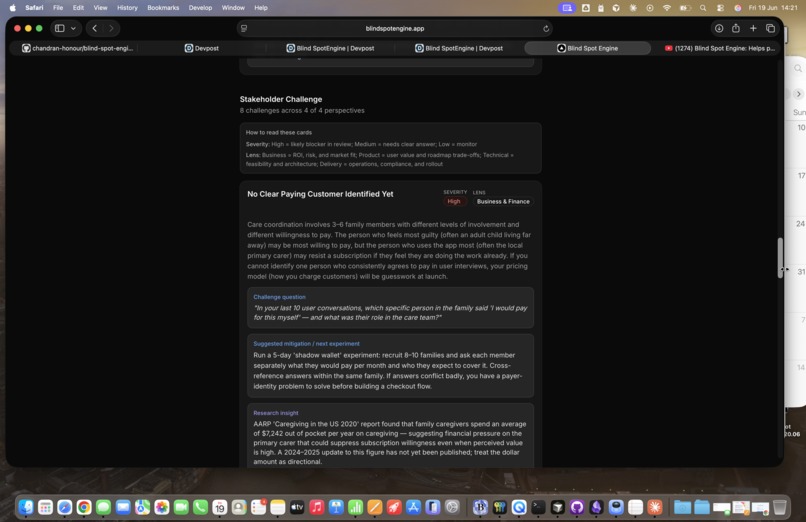
Phase 2 — Stakeholder Challenges. Four lenses — Business & Finance, Product & PM, Technical & Engineering, and Delivery & Operations — each surfacing two high-stakes concerns with a concrete challenge question and a suggested mitigation or next experiment. The framing is deliberately prescriptive, not just diagnostic. A challenge question without a suggested next step is just diagnosis; what builders need is something they can actually act on.
The output is streamed as structured JSON and rendered in the browser. No accounts, no persistence, no friction between idea and analysis. You paste in an idea and you get a report. That's it.
How We Built It
This was an agentic engineering project, AI-assisted development throughout, using
Cursor as the primary coding agent, with a structured and disciplined process maintained
from start to finish. The stack is Next.js 14 + TypeScript + Tailwind + shadcn/ui,
deployed to Vercel, with Claude (claude-sonnet-4-6) powering the analysis via a
server-side streaming API route.
The initial system did start as a vibe-coded sketch, a single prompt to Cursor, a rough scaffold, something to look at. That got the idea out of my head and onto a screen quickly, which was the point. But it became clear almost immediately that a single-prompt approach wasn't going to hold. The data model needed to be thought through properly. The API call structure, the streaming logic, and the prompt architecture all had enough moving parts that working without a clear design was creating debt faster than the prototype was creating value. So the approach shifted: requirements written down, a data model defined, API and prompt logic documented before being built, and a project plan maintained throughout. The vibe-coded sketch became the starting point, not the method.
The productivity comparison is striking. Time spent with Cursor at approximately mid way through the one month timeline came in at approximately:
$$T_{\text{actual}} \approx 30 \text{ hours}$$
Estimated equivalent time for the same deliverable without an AI coding agent — a PM re-learning Next.js, TypeScript, and streaming API patterns from scratch, fitting it in around a day job:
$$T_{\text{manual}} \approx 80\text{–}120 \text{ hours} \quad \Rightarrow \quad \text{multiplier} \approx 2.5\text{–}4\times$$
For the full project to hackathon deadline, the comparison is even starker:
$$T_{\text{full, with Cursor}} \approx 75 \text{ h} \qquad T_{\text{full, manual}} \approx 150\text{–}220 \text{ h}$$
That difference — roughly ΔT ≈ 100–145 hours — is the difference between a solo part-time builder shipping and not shipping. Cursor handled scaffolding, explained framework errors, generated the streaming boilerplate, and kept iteration cycles short enough to survive on 1–2 hour evening sessions after the kids are in bed. The constraint stopped being "can I build this?" and became "do I know what I'm building?"
That shift is, I think, the more interesting story.
Challenges We Ran Into
The blank canvas problem
A solo builder with a fresh repository and no design system faces a surprisingly paralysing decision: what does the first version actually look like? The temptation is to scope up, to add persistence, accounts, sharing, history. Several of those got built and reverted, including a share-link feature that took longer than it should have and ultimately came out. Every feature that was cut saved time that went into the prompt quality that actually mattered. That's easy to say in retrospect and genuinely hard to do in the moment.
Prompt iteration is slow to converge
Each meaningful prompt change required a full test run against a realistic product idea, manual scoring against a five-criterion rubric, and a careful read of the output for both what it said and what it didn't. Across 11 major runs and several variants, failure mode patterns emerged — but slowly. That's time-consuming to do well, and I think it's an underappreciated constraint for anyone building products like this. The quality floor is only as high as the evaluation framework, and building a good evaluation framework is its own project.
To speed things up, I built two Claude agent skills that automated most of the mechanical
work: /blindspot-tester and /blindspot-evaluator. Together they take advantage of
Claude's agent skill system and the Claude browser plugin.
/blindspot-tester reads the test plan, launches the BlindSpot app in Chrome via the
Claude browser extension, enters the product idea and context fields, runs the analysis,
and saves the output to a numbered run file in the test-results folder — all without
manual intervention. /blindspot-evaluator then picks up that output, scores it against
the five-criterion rubric (Relevance, Blind Spot Novelty, Stakeholder Authenticity,
Actionability, Output Quality), runs verification checks for lens coverage, severity
consistency, and any cited statistics, and writes the results back into the tracking file.
That pipeline compressed what had been a slow, manual loop into something much faster. That said, automation handled the mechanical steps, not the judgment. I still reviewed every run myself — reading what the engine actually said, checking whether a blind spot felt genuinely non-obvious or just plausible-sounding, and deciding what the prompt change should be next. That part remained human throughout, and rightly so. Automating the evaluation scoring is useful; outsourcing the judgment about whether an insight is actually good is a different thing entirely.
The vague requirement problem
Early in the build, requirements like "make the output more useful" or "add more actionability" were too fuzzy to act on. The breakthrough was writing an explicit scored rubric — five criteria, 1–5 each — before changing anything. That gave prompt changes something to optimise against and made regressions visible. For AI-driven products specifically, you need an evaluation framework before you need more features. Without it, you're tuning by feel, which tends to produce local maxima.
Alongside the rubric, a living requirements document helped considerably. Rather than keeping requirements in my head or buried in chat threads, I maintained a structured doc that captured what the product needed to do, why, and what "good" looked like for each part. Cursor updated it frequently as the build evolved, which meant the documentation stayed genuinely current rather than drifting out of sync with the code. That sounds like a small thing, but for a solo builder working in short sessions it made a real difference: requirements that are written down and up-to-date are requirements you can actually reason about and hand to an AI agent as a reliable source of truth.
Context-switching cost
Building in 1–2 hour windows, evenings after the kids are in bed, with a full week of work or other activities in between, creates a specific kind of friction that's easy to underestimate. The context-switching cost of re-entering a codebase when sessions are short and infrequent is high. Two things helped more than anything else. Cursor's ability to hold and re-explain project context meant it could remind me why a decision was made and where things currently stood, so I wasn't starting cold each session. And having a clear process in place — a project plan that Cursor created and maintained throughout the build, tracking tasks, progress, and what was coming next — meant the structure was always there waiting, regardless of how long I'd been away. The build worked not just because an AI could write code, but because it could also plan, document, and remember — which turns out to matter quite a lot when you're the only person on the project.
Accomplishments That We're Proud Of
Shipping a working product solo and part-time, in under a month, around family commitments, is the thing I'm most proud of. It would not have been possible without the agentic engineering approach — and quantifying that honestly, with the 2.5–4× productivity multiplier, made clear just how much the tooling changed what was possible for a builder in this position.
Beyond shipping, a few specific things stand out. The two-mode design — genuinely distinct startup and enterprise prompts rather than a single one-size-fits-all analysis — was not the original plan, and discovering it through testing rather than upfront design felt like the right kind of product instinct working. The prompt quality improvement across the test runs was also satisfying: early runs were technically correct and practically useless, and by the refined runs the output was scoring consistently at the top of the rubric, with blind spots that felt genuinely non-obvious rather than recycled startup advice.
Building the /blindspot-tester and /blindspot-evaluator skills was a highlight in its
own right. Using Claude's agent skill system and the browser plugin to automate the
test-and-evaluate loop turned a painfully slow manual process into something repeatable
and fast — and the fact that those skills now live as reusable tools beyond this project
gives them a longer life than the hackathon itself.
What We Learned
Prompt design is the core engineering challenge
The gap between a system prompt that produces generic advice and one that produces genuinely useful, idea-specific insight is large, and it's not visible from the output structure alone. Early runs of the engine looked good on paper: valid JSON, complete sections, all the right fields. But they told founders things they already knew. Technically correct, practically useless.
The refinements that actually changed this were threefold. Requiring idea-specificity by instruction: an explicit directive to deprioritise table-stakes generic risks (moat, willingness-to-pay, team size) in favour of non-obvious, context-specific blind spots changed the character of the output entirely, and the engine stopped flagging things founders had already thought about. Adding a "Suggested mitigation / next experiment" field: the difference between a challenge question and a concrete, time-boxed next action is the difference between diagnosis and treatment, and once the schema required a mitigation the output became something a builder could actually do something with. Severity consistency checks: an early failure mode was marking a persona as Medium significance even when the rationale effectively excluded an entire market segment — if the conclusion is "all regulated industries can't use this product," that's a High severity finding and should be scored accordingly.
After these changes, the blind spots started feeling genuinely non-obvious: positioning traps where the underlying platform was actively commoditising the space, unit economics where the cost to onboard a customer exceeded months of projected revenue, data ingestion constraints that quietly foreclosed entire markets. The kind of things an honest fellow entrepreneur would tell you, if they were close enough to the context and dispassionate enough to say it.
Two modes, not one
Early testing used a single startup-oriented framing. When enterprise product ideas (internal dashboards, procurement tools, compliance products) were put through the same prompt, the output was wrong in specific ways. It focused on customer acquisition when the real risk was internal adoption. It underweighted regulatory and data governance concerns. It missed the political dynamics of cross-team dependencies entirely — the kind of thing that stops internal products dead while they're waiting on a data platform team with a six-month backlog.
Adding a dedicated Enterprise PM mode with a different system prompt structure, different stakeholder lens weighting, and explicit attention to governance, InfoSec sign-off, and stakeholder politics made a material difference. The two modes now feel qualitatively distinct, which is the right outcome — the risks facing an indie founder validating an idea are genuinely different from those facing a PM getting an internal tool through a bank's model governance process.
Structured context is a force multiplier
The optional context fields (target market, development stage, team constraints, what's been validated) have a non-linear effect on output quality. Without them, the engine produces competent but generic analysis. With them, it can make specific, grounded claims: it knows the team can't yet support enterprise security reviews, so it flags the integration scope risk early; it knows only three of five required data feeds are confirmed, so it surfaces the model governance risk before the builder has committed further. The analysis becomes relevant to this stage of this product, not product development in general.
The practical lesson: more context leads to exponentially more specific output. The UI now prompts for structured context by default.
Streaming matters more than you'd expect
The analysis takes 10–20 seconds end-to-end. Streaming the JSON output — so that cards appear progressively rather than after a full wait — transforms the experience from "waiting for a spinner" to "watching thinking happen." This generalises: for AI-heavy workflows, perceived latency is less about milliseconds and more about progressive disclosure. Something appearing is always better than nothing appearing, even if the total time is the same.
Vibe coding gets you a sketch; discipline gets you a product
The initial vibe-coded prototype was genuinely useful — it proved the idea was buildable, gave me something concrete to react to, and surfaced questions I wouldn't have thought to ask upfront. But a sketch is not a foundation. The prompt-to-scaffold approach works well for the first hour and starts working against you in the second. Without a clear data model, the JSON schema drifts. Without documented API and prompt logic, changes in one place break things in another in ways that are hard to trace. Without a requirements document, "make it better" stays fuzzy indefinitely.
The pattern that emerged: use vibe coding to generate the sketch, then stop and do the design work properly before building further. Define the data model explicitly. Write down what each API call needs to do and why. Document the prompt logic as a specification, not just as a string in the code. That shift from exploratory to disciplined is where the project actually stabilised — and it's a transition I'd make earlier next time, not after the first round of accumulated debt.
What's Next for Blind Spot Engine
The obvious gaps are persistence (saving and comparing analyses across sessions), a conversational layer (continuing the discussion with each stakeholder persona after the initial output), a case study retrieval step using RAG over a database of documented product failures so the blind spots are grounded in evidence rather than synthetic reasoning, and support for local AI models as a fallback for when frontier models are unavailable or rate limits have been reached. All four are in the backlog.
But the deeper question is whether outputs that are this specific and prescriptive actually change the decisions builders make. That's what remains unvalidated. It's the next experiment, and it's probably the only one that matters.
Built solo, part-time, June 2026. Agentic engineering powered by Claude Sonnet 4.6 and Cursor.
Built With
- claude
- cursor
- github
- next.js-15
- shadcn/ui
- supabase
- tailwind
- typescript
- vercel


Log in or sign up for Devpost to join the conversation.