Inspiration
Having just learned AWS, we had stumbled upon this hackathon and what better way to apply what we just learned then through something fun and exciting as the global power rankings hackathon.
What it does
PoroRank is a simple web application that allows you to view the top ranking esports teams in league of legends with the option to filter the rankings by team names.
How we built it
We decided early on we wanted to build the application using the server less model to reduce friction with infrastructure management and to enable all the benefits of the cloud such as auto scaling with no additional work required.
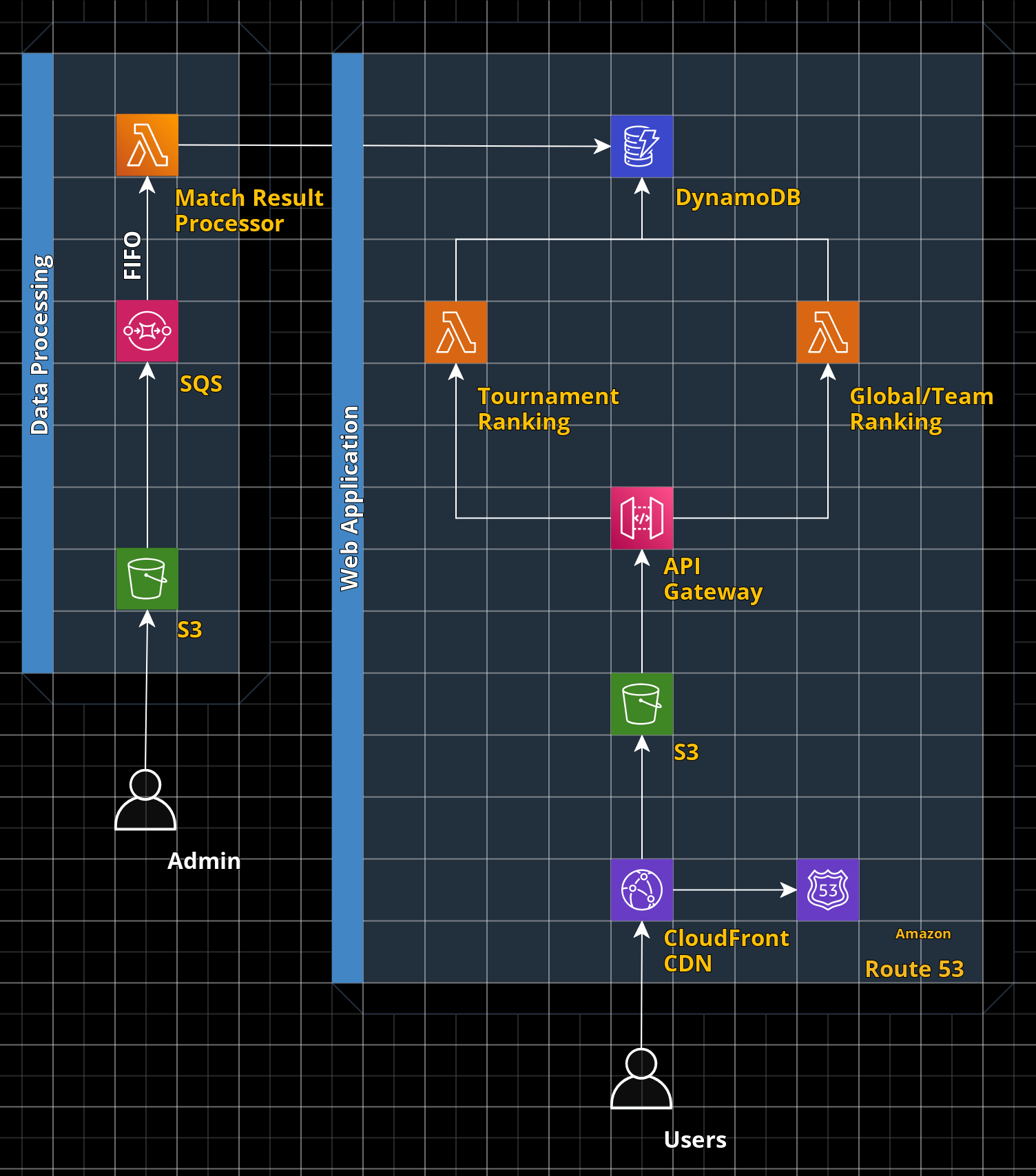
Goals
Our main goals were to build a web application that was performant that confirms to the current best practices and standards with modern scalable cloud based applications. These goals led us to creating a common yet performant pattern of creating a restful api fronted by AWS API Gateway and integrated with multiple lambda functions per endpoint, allowing each endpoint to scale up and down as needed.
Backend Services
As the defacto serverless option, we chose Lambda to run all of our backend services that bridges our datastore with our API gateway. We did explore containerized options but Lambda was just so easy to work with we didn't spend much more time exploring other options. We did, however, containerize our Lambda code to give us the flexibility to define at the Lambda code level what runtime it would use. We did not like the idea of defining in the CDK what runtime the lambda code used, and wanted the flexibility to swap runtimes on a function if we desired.
Datastore
We also decided on DynamoDB as our data store after countless read/write unit compute exercises finding that for our use case DynamoDB was actually quite cheap. However, this did not come without extensive research on DynamoDB cost optimizations and best practices which led us to the wonderful concept of single-table design. It was actually quite difficult at first getting into the mindset of single-table design thinking about what our access patterns will look like, but after a while it eventually started to click and we truly unlocked the power DynamoDB provides at a much much lower cost then if we were to create multiple tables.
Infrastructure management
We know early on manually managing infrastructure would be a pain, and we had this vision of allowing anyone who wants to explore our application in their environment to be able to do just that. This led us to explore different IAC (Infrastructure-as-code) options ultimately landing on using the AWS CDK for all backend related services and SST for our web application. This made it where we could get our entire application up onto a new AWS account in literally two commands! This also made infrastructure management incredibly easy when making changes or adding additional endpoints to our API Gateway.
Challenges we ran into
There were numerous challenges that we ran into while building PoroRank, below are just a few:
Lambda Container CI/CD Strategy
As mentioned, we decided on using images attached to our Lambda instances to give us the flexibility of choosing our lambda runtime within the lambda code/dockerfile. One challenge we faced was that the AWS CDK is setup to host both application code as well as the IAC that deploys your infra. To us, it did not make sense to use the same deployment pipeline for infrastructure vs code changes as both typically have different deployment cadences. AWS provides alot of options here with storing your build artifact somewhere like CodeArtifact and loading that into your CDk for deployment, but these solutions still require to run the entire CDK stack for what could a singular lambda code change. We decided to place some dummy Lambda image in the CDK stack for deployment updates and created separate ci/cd pipelines for each lambda function. This also allowed us to separate each Lambda function and all of its deployment assets into separate assets for cleaner code management. Our thought was that once our Lambda functions are in a stable state, we would then load it into the CDK for any third-party that wanted to quickly load our application into their AWS account, giving us the flexibility during deployment to individually deploy each on changes.
DynamoDb Design
One major challenge we faced was how we were going to store our data and how it was going to be structured in that data store. We explored standard RDS options, DynamoDB, and even S3. Our first option was DynamoDB for its serveries nature, aligning with our goals, but we were worried about cost. We iterated multiple table designs and calculated our read/write units for our data processing function as well as our restful lambda implementations. While looking up DynamoDB best practices, we stumbled upon Rick Houlihan's "Fundamentals of Single-Table Design" video on YouTube and to say we were blown away would be an understatement. All of a sudden cost become much less of a concern as we redesigned our data to conform to the single-table design and started calculated our expected costs. The biggest challenge we faced was storing separate rankings for each stage in a tournament. Our initial solution had us create a primary key with "TOURNAMENT#SOMEID" as the partition key and "STAGE#NAMETEAM#SOMEID" as the sort key, but it felt unnatural to have two identifiers in a single key. We ended up creating a primary key with "STAGE#SOMEID" as the the partition key and "TEAM#SOMEID" as the sort key, but because there was no id for stages in our data we ended up generating them in our data processor by taking the tournament id and incrementing 1 for each stage in said tournament. So for tournament id 123 with two stages the first stage would have id 124 and the second stage would have id 125. Once we figured this part out everything else was much easier.

IAC Openapi Integration
One of the first exercises we performed in the project was generate an openapi specification file for our API Gateway with the intention of using this in our IAC to easy generate the required endpoints. However, linking the respective lambda's to each endpoint was significantly more challenging then anticipated so we ended up manually creating our API Gateway routes or "resources" as they are called in the CDK and manually connecting the lambda integration to each route.
CDK Web App
Unfortunately we got a start on our web site extremely late and were scrambling to get a good enough ci/cd implementation in place. We initially planned for this to be in our CDK, but as we started to vet our web application we discovered we needed SSR and could not host a statically generated site. We had decided to use Remix.js for our web app framework as we had used it in previous projects and luckily SST had a very easy and similar to CDK construct to quickly deploy Remix web applications with all the required components, including a Lambda edge function for the server rendered pieces. if we had more time, we would have liked to keep this in our CDK for a much more seamless experience spinning up and down our web application and ultimately staying aligned with our goals.
Rating processing
This piece was also fleshed out much later in the challenge resulting with some compromises made. Our initial plane constituted of an S3 bucket which we would load our data to, this would then trigger a lambda event and get processed by some "data cleaner" Lambda that would clean the data and store the match results in a FIFO SQS queue. This queue would then trigger another event on a separate "data processor" Lambda which would compute the rating changes and update our DynamoDB table. However, with the Glicko 2 model, a subset of the match data is required to effectively computing the rating changes and we could not compute the rating change on a per match result bases. Because of time constraints, we ended up running the data cleaning and data processing in a single python script and used boto3 to export the processed data into our DynamoDB table. We would like to revisit this and see if we can go back to some queue processing design for our rating updates as this could also allow us to continue to process new matches as they come in, this may require moving away from Glicko 2 but we are still exploring this piece.
Accomplishments that we're proud of
Creating our very first anything in AWS was honestly really exciting, let alone the fact that we did it all serverless! Creating a performant yet cost effective solution was something we were very proud of and honestly was not extremely difficult with the tools AWS provided. It just required looking in the right places to fit the pieces into the solution we have now.
Our DynamoDb single table design is something we were also extremely proud of. We went through countless different iterations of our single-table design before we landed on the one use today and we are quite proud with the current product.
What we learned
We learned quite a lot on AWS, Lambda types, API Gateway, API Gateway fronted by Lambda, DynamoDb single-table design, AWS boto3 client vs resource, rating system history and their differences (elo vs truskill vs glicko), etc...
What's next for PoroRank
There were quite a few features we wanted to add that were in our wireframes but ran out of time unfortunately such as: Tournament filtering, Match processing lambda, Rank history, team-specific view with match history, player lists, current events list, etc.. We decided we are going to continue working on PoroRank albeit a bit slower implementing the missing features we wanted to add and creating a truly polished and delightful experience.

Log in or sign up for Devpost to join the conversation.