Inspiration
We were motivated by the need for tools that are not only powerful, but also practical and intuitive for medical professionals. The NSMP group represents a particularly complex clinical challenge, and our primary objective was to support clinicians by simplifying how this complexity is handled.
We aimed to develop a platform that strengthens confidence in clinical decision-making and ultimately contributes to better patient outcomes. By focusing on usability and real-world applicability, we sought to bridge the gap between complex data and everyday clinical practice, enabling clinicians to work more efficiently and effectively.
What it does
NEST (NSMP Endometrial Stratification Tool) is a comprehensive clinical decision support system designed specifically for patients within the NSMP subgroup of endometrial cancer.
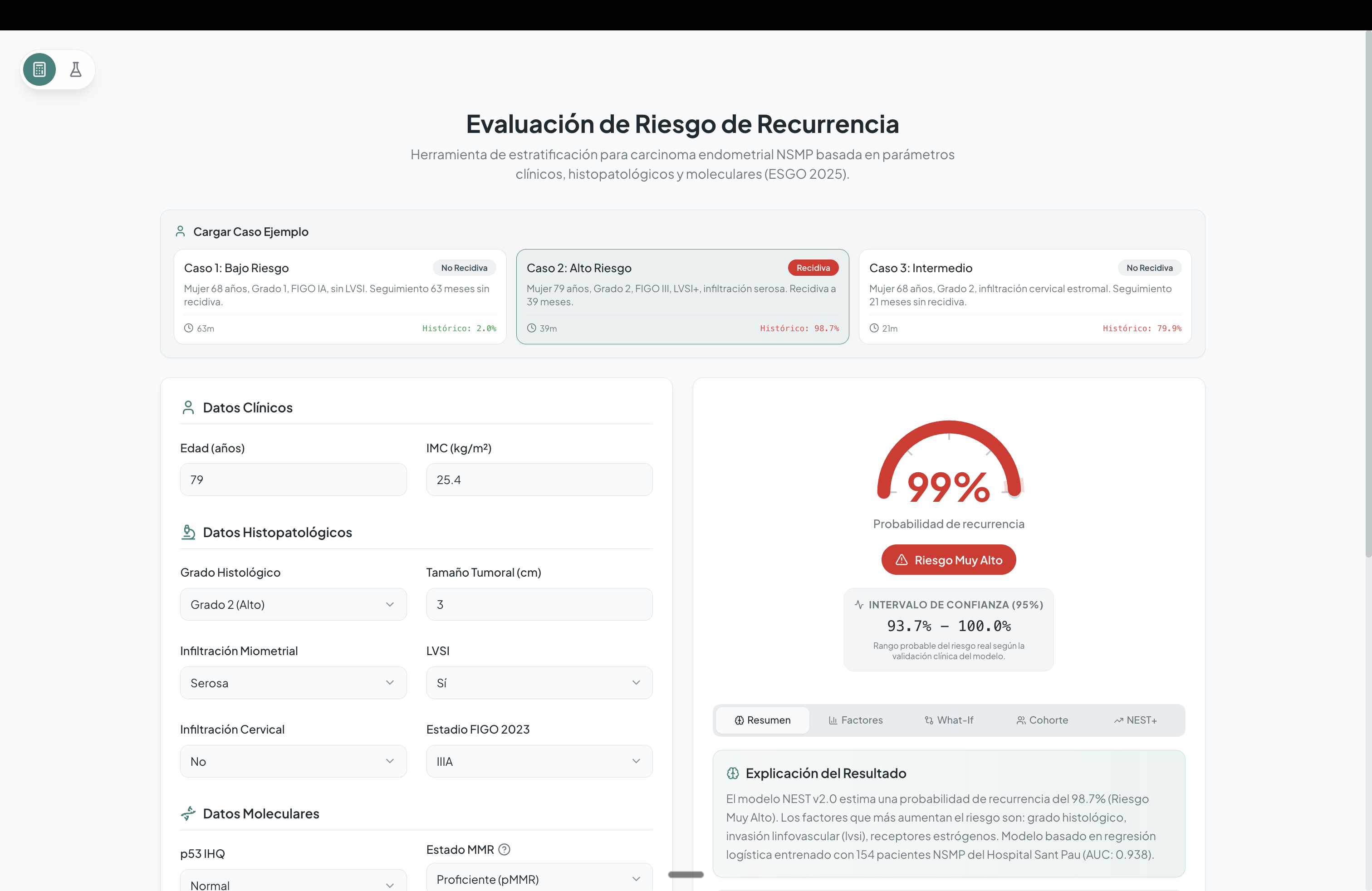
Risk Stratification Using a calibrated Logistic Regression core, NEST integrates clinical, pathological, and molecular variables (such as p53 status, LVSI, and tumor size) to compute an individualized probability of recurrence.
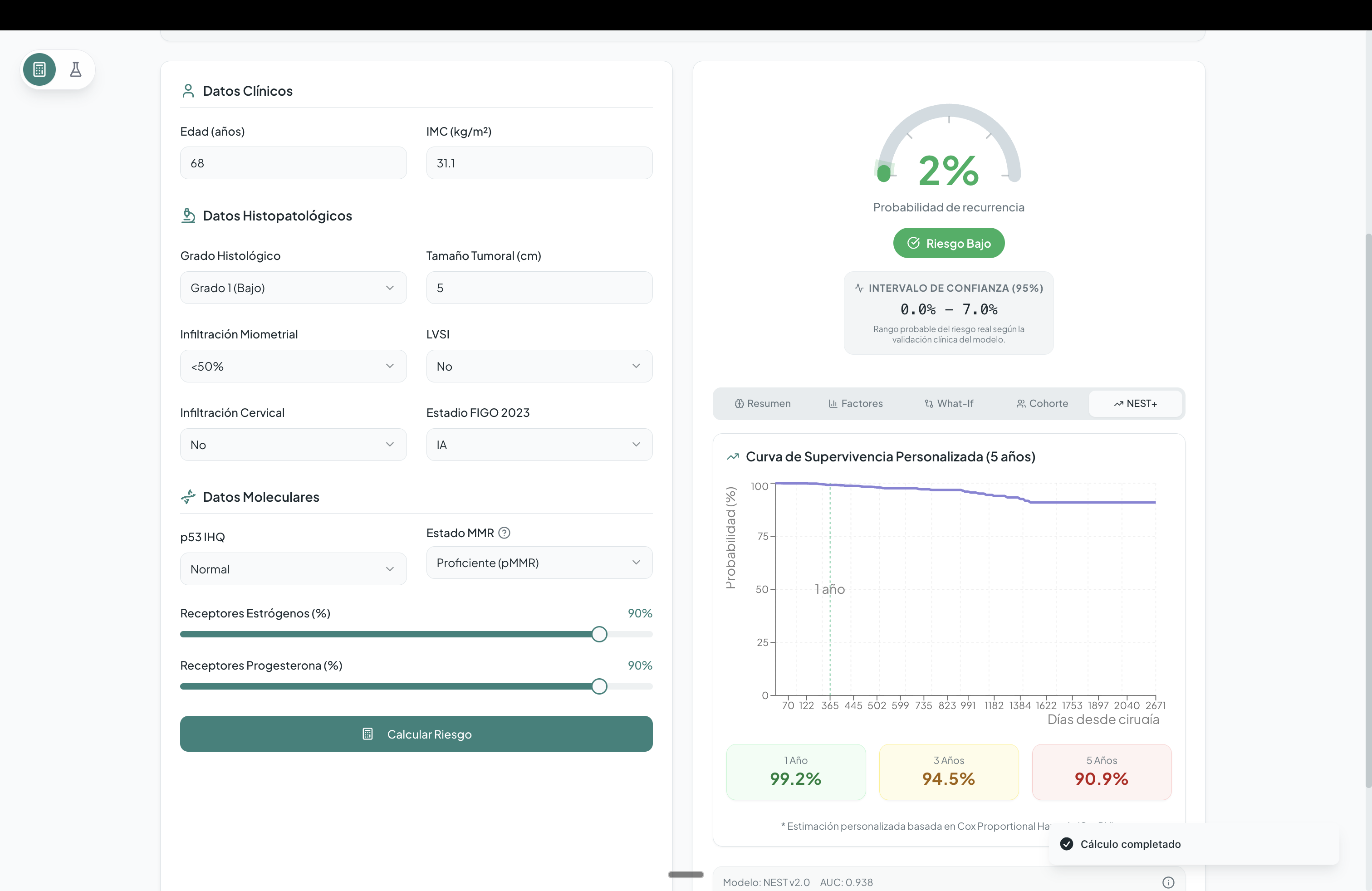
Temporal Risk Projection Rather than providing a simple binary prediction, NEST incorporates a Cox Proportional Hazards model to generate personalized survival curves. These curves estimate when a relapse is most likely to occur (e.g., at 1, 3, or 5 years), supporting informed follow-up and surveillance planning.
Evidence-Based Similarity NEST includes a “Similar Patients” module powered by K-Nearest Neighbors (KNN). This feature identifies historical patients with highly similar clinical profiles and presents clinicians with real-world outcomes: “Here are patients like yours, and this is how their disease evolved.”
Automated Clinical Reporting The platform automatically generates professional, Tumor Board–ready clinical reports, reducing administrative burden and streamlining multidisciplinary discussions.
How we built it
Data Science We began with rigorous Exploratory Data Analysis (EDA) on the provided dataset. Missing values were handled using median imputation, and clinically meaningful features were engineered based on established medical literature, including FIGO staging criteria.
Modeling Multiple machine learning models were trained and compared (Random Forest, Gradient Boosting, XGBoost, SVM). Ultimately, Logistic Regression was selected due to its strong interpretability, reliable calibration, and robustness in small-to-medium clinical datasets. Survival analysis was implemented using the lifelines library for Cox Proportional Hazards modeling.
Backend The backend was developed using FastAPI (Python), exposing low-latency endpoints for risk prediction, survival analysis, and patient similarity search. This architecture enables seamless integration with hospital systems.
Frontend The user interface was built with React, Vite, and Tailwind CSS, prioritizing clarity, high contrast, and ease of use in clinical environments. Medical visualizations—including survival curves and risk distributions—were implemented using Recharts.
Challenges we ran into
Clinical data complexity The dataset contained missing values and heterogeneous clinical variables, requiring careful preprocessing and medically informed feature engineering.
Model selection and interpretability We needed to balance predictive performance with clinical interpretability. Choosing models that clinicians can trust and understand was a key challenge.
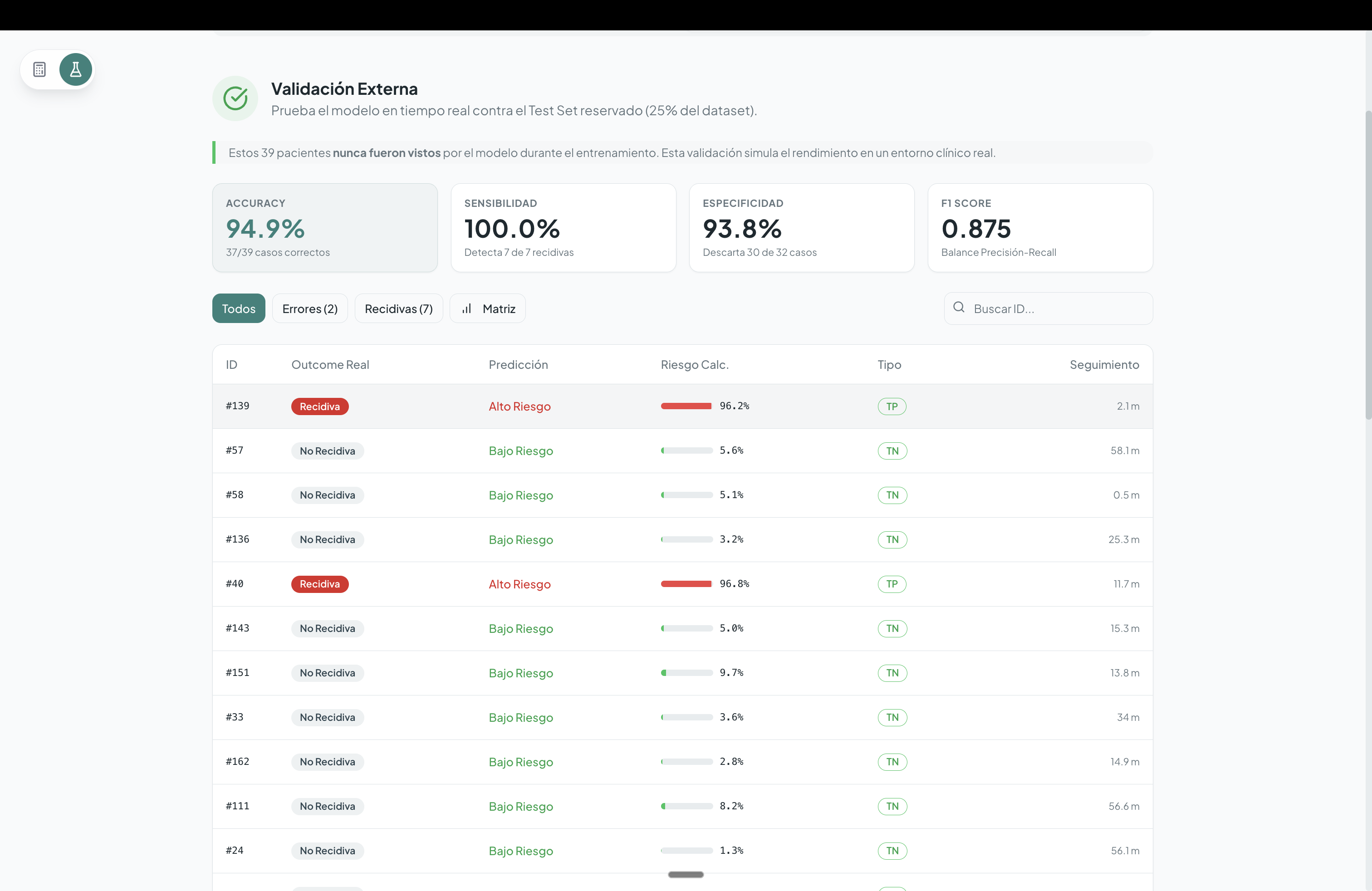
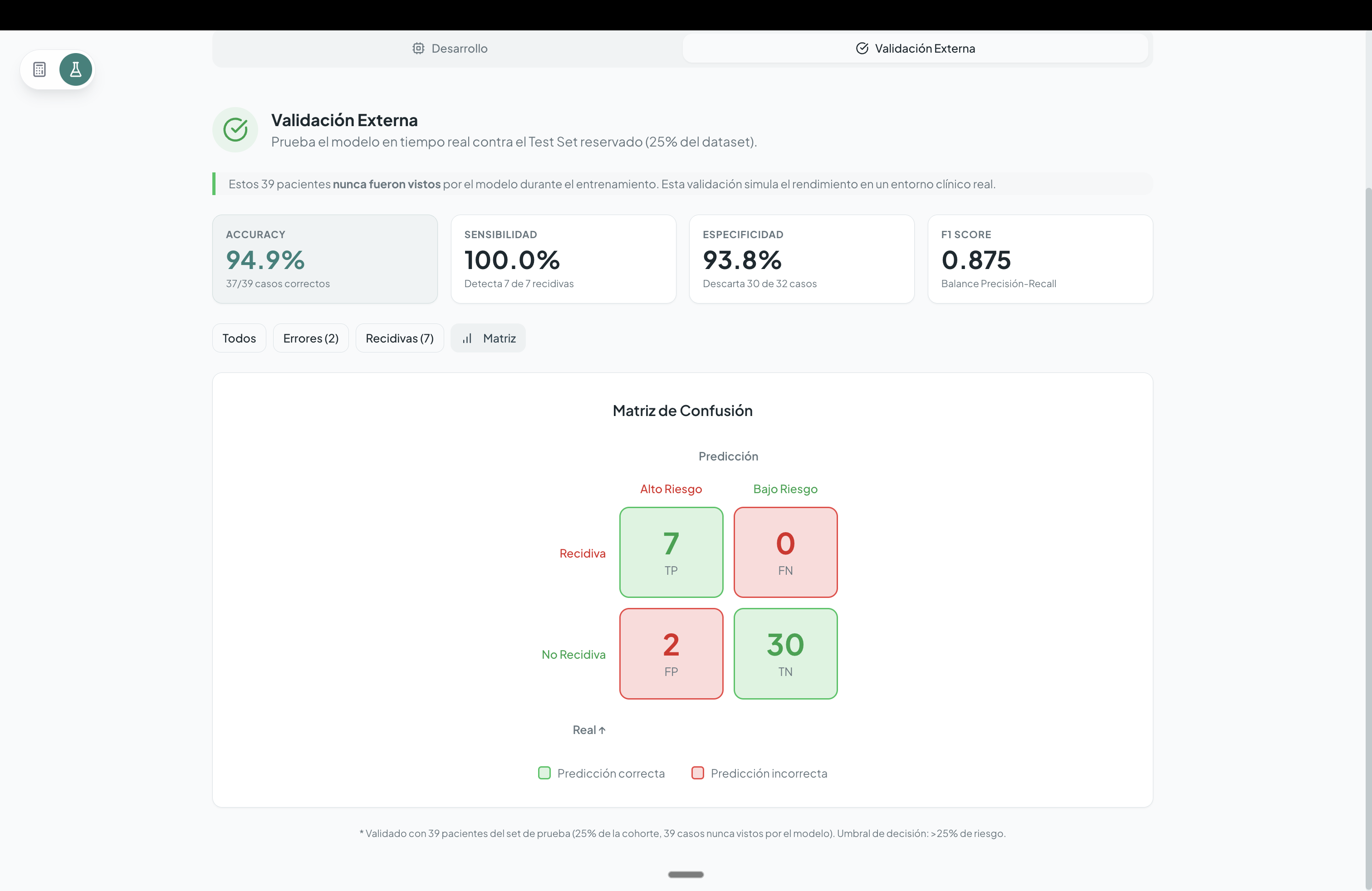
Class imbalance Relapse events were less frequent than non-relapses, which required specific strategies to prevent biased predictions.
Probability calibration Ensuring that predicted risks accurately reflected real-world probabilities was essential for clinical usefulness.
Multi-model integration Combining risk prediction, survival analysis, and patient similarity into a single, coherent system required careful coordination of different modeling pipelines.
Accomplishments that we're proud of
We are proud of the solution we developed for the challenge proposed by Hospital Sant Pau. In just 24 hours, we built a fully functional, end-to-end prototype that translates advanced data science into a tool that feels natural and useful in a clinical setting.
Bridging the gap We successfully connected a robust predictive backend with an intuitive frontend, making complex risk modeling accessible without requiring technical expertise.
Focus on real clinical value Rather than chasing metrics alone, we prioritized features that directly support clinical workflows, such as personalized survival curves and patient similarity analysis.
Team synergy Our team effectively combined expertise in data science, backend development, and frontend design to deliver a cohesive and impactful solution under tight time constraints.
What we learned
We gained deep insights into endometrial cancer and the specific challenges of the NSMP subgroup. This project reinforced how thoughtfully applied data science can meaningfully support patient care.
We learned that the most complex model is not always the best choice. In this context, interpretable and well-calibrated models proved more valuable than opaque, black-box approaches.
Finally, we strengthened our ability to collaborate under pressure, aligning technical implementation with clinical usability to deliver a compelling demo on time.
This platform has significant potential for future expansion:
Continuous learning: The system could be designed to retrain as new patient data becomes available, improving accuracy and robustness over time. Also investigate using more sophisticated ensemble models.
Federated learning: To address data privacy across institutions, a federated learning framework could allow models to learn from multiple hospitals without sharing sensitive data.
Clinical trial matching: An additional module could recommend relevant clinical trials for high-risk patients, helping clinicians connect patients with emerging treatment options.
Deep Learning: Another idea would be to incorporate of histopathological images by using Deep Learning

Log in or sign up for Devpost to join the conversation.