-
-
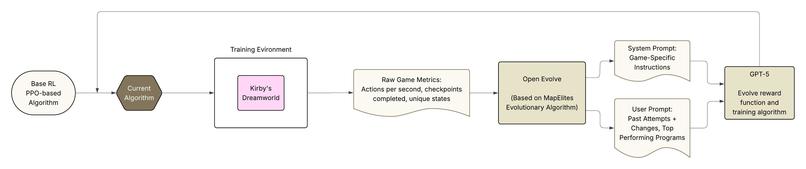
Flowchart of how Popstar iteratively improves PPO runs
-
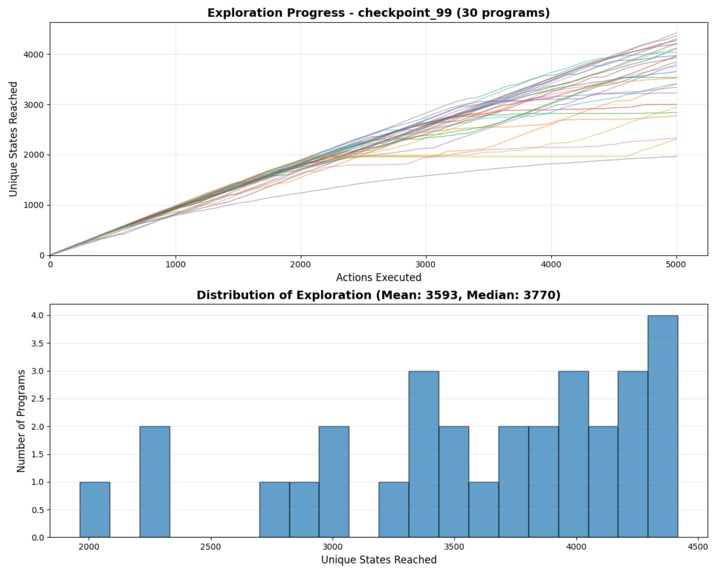
Agent runs
-
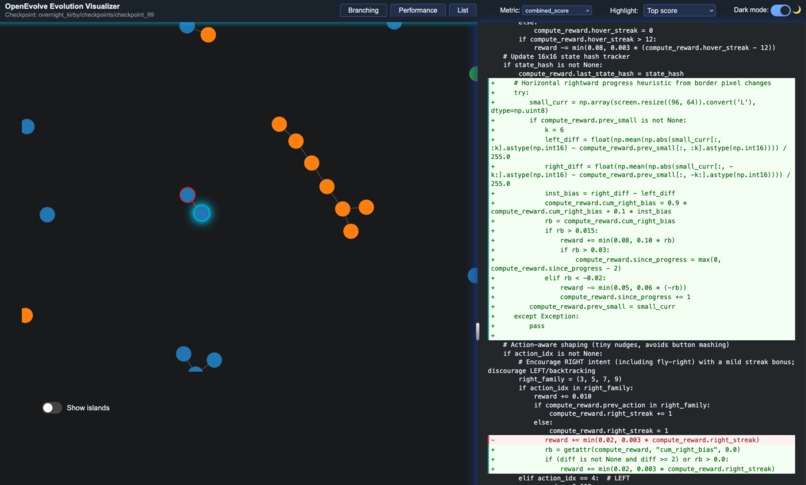
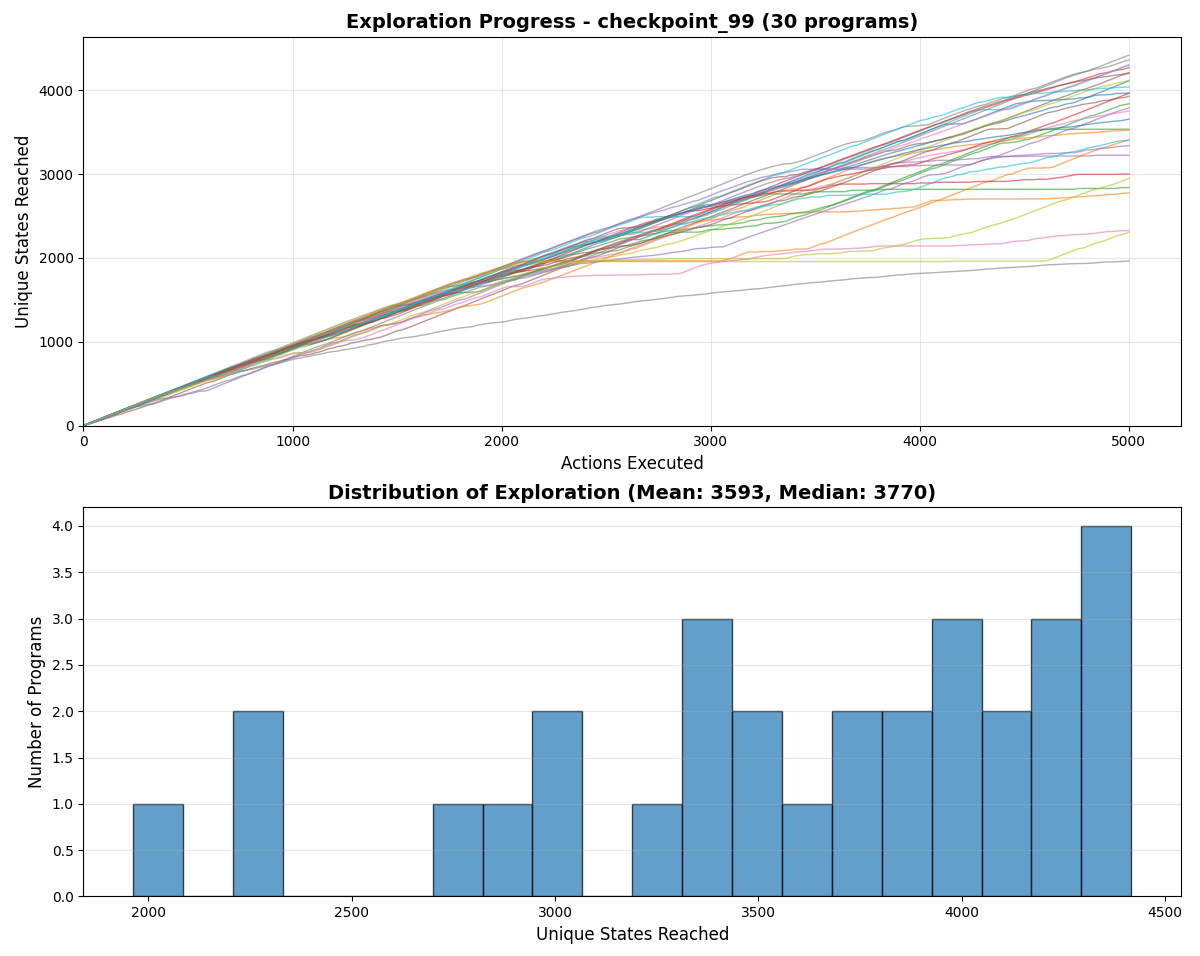
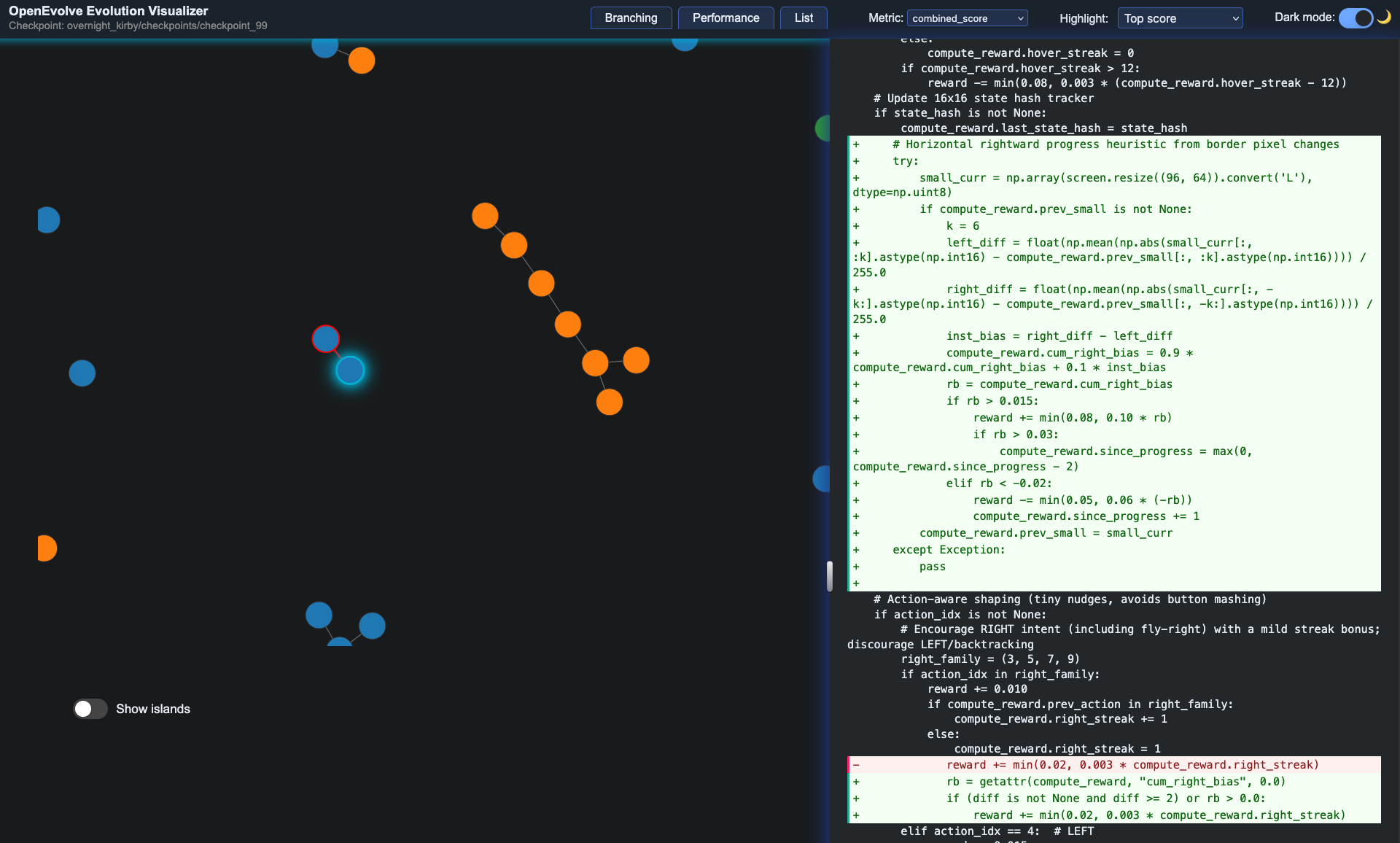
Visualization of diffs in code
Inspiration
Popstar was inspired by a simple question:
Can reinforcement learning, large language models, and evolutionary search work together to produce agents that learn and evolve autonomously, just like humans?
Classic PPO agents can learn to play games, but they rely on fixed hyperparameters and static reward functions. They often have trouble in environments where external rewards are extremely sparse.
With OpenEvolve, we wanted to combine the adaptability of LLM reasoning with the precision of reinforcement learning to create agents that can self-improve by proposing novel intrinsic rewards to help guide RL exploration.
The key idea in our approach is to use evolutionary algorithms like those in AlphaEvolve to propose novel intrinsic reward functions and modifications to the training algorithms (i.e. PPO), to ultimately maximize the sparse external rewards.
We decided to use Kirby’s Dream Land from VideoGameBench (https://arxiv.org/abs/2505.18134) as our training environment :) Current SOTA, using frontier VLMs like Gemini 2.5 Pro, achieve ~4.8% progress through the game. Our goal was to match or exceed this benchmark using much smaller models and in a much shorter timespan.
What it does
Popstar (our nickname for the Kirby PPO agent) learns to play Kirby’s Dream Land using only raw pixel inputs and reward feedback. Normally you set up PPO once (or a human experiments with the hyperparameters and intrinsic rewards), but in Popstar you only give it an initial PPO implementation and basic intrinsic rewards, and let frontier LLMs guided by the map-elites evolutionary algorithm perform the scientific process to discover the best reward + training algorithm.
This leads to a single framework that merges LLM-driven experimentation, evolutionary optimization, and reinforcement learning into one adaptive system.
The agent:
- Observes game frames through a Game Boy emulator
- Decides on actions (button presses) via a CNN-based policy network
- Learns through a Proximal Policy Optimization (PPO)
- Is evaluated and evolved within OpenEvolve’s orchestration layer, where LLMs (we used GPT-5) proposes new intrinsic reward functions, improvements to PPO itself, or both.
In essence, Popstar is an evolving, self-improving AI player that gets better at the game through both gradient-based learning and evolutionary trial-and-error adaptation. Through changing the system prompt, Popstar can be adapted to other games, including Mario Bros and Pokemon. Experiments can be found in our GitHub.
How we built it
- Framework: OpenEvolve — coordinates agent evaluation, LLM reasoning, and evolution
- RL Algorithm: Custom basic PPO implementation to act as a starting point
- Language: Python
- Environment: Game Boy Emulator (PyBoy or Gym Retro) wrapped in a Gym-style API through VideoGameBench
- Logging: TensorBoard and Weights & Biases for tracking learning curves
- Hardware: Inference and training on Modal for scalability
We trained each agent by running tens of thousands of time steps through the emulator, using OpenEvolve to manage agent evolution, runs, visualize progress, and evolve new policy variants.
Challenges we ran into
- Environment instability: Retro emulators can desync or crash when run headlessly at scale.
- Sparse rewards: Platformer games don’t always give clear feedback, making credit assignment difficult.
- Death detection: videogamebench provides no death detection, only pure emulation of the game.
- Hyperparameter tuning: PPO’s stability depends heavily on learning rate, clip range, and batch size — requiring evolutionary search to find optimal configurations.
- Integration complexity: Merging LLM-based reasoning and RL workflows required careful orchestration between asynchronous processes.
Accomplishments that we're proud of
- Built a fully functional reward function evolutionary process to optimize agents against sparse reward environments including Kirby's Dreamland on videogamebench.
- Integrated OpenEvolve to allow evolutionary tuning and LLM-driven adjustments of the training process.
- Visualized meaningful improvement in the agent’s gameplay behavior — surviving longer, avoiding enemies, and navigating levels.
- Created a reproducible framework for open-ended RL experiments that can extend to other games and domains.
What we learned
- Evolutionary program optimization can be applied to reinforcement learning problems.
- LLMs can propose new ideas (rewards, architectures, hyperparameters) that make significant progress.
- Game environments are excellent RL testbeds — visually interpretable and diverse in dynamics.
- Open-ended systems need orchestration layers. Without proper control loops, self-improvement becomes chaotic.
- Simplicity beats overengineering — even small PPO setups can produce surprisingly robust behaviors when evolved with frontier LLMs.
What's next for Popstar - Agentic RL Training
Next, we plan to:
- Expand to multi-agent experiments where agents collaborate or compete within the same environment.
- Integrate LLM-based policy summarization, letting models describe why they acted a certain way.
- Scale experiments to new emulated worlds (e.g., Pokémon, Mario) to study generalization.
- Release a public OpenEvolve Playground — a web app where anyone can evolve and train agents visually in real-time.







Log in or sign up for Devpost to join the conversation.