-
-

Anticholinergic Burden Scoring and Recommendation
-

Risk Scoring System
-

Moderate Level Concern Suggestion
-
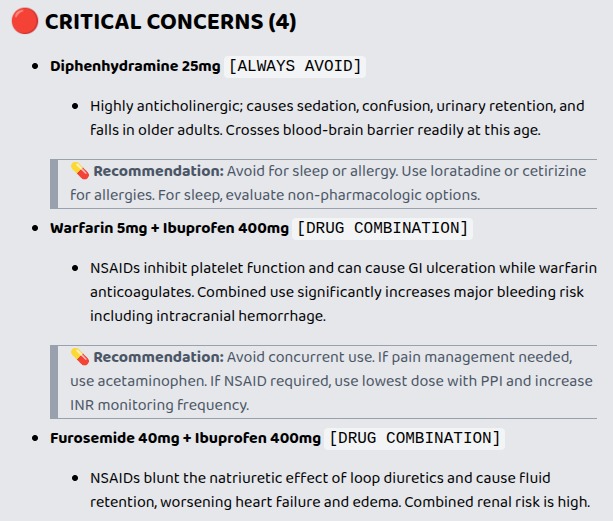
Critical Level Concern Suggestion
-

FDA Recall Notices




Inspiration
Adverse drug reactions are among the leading preventable causes of hospitalization in adults over 65. The AGS Beers Criteria review that could catch them is recommended annually — but in practice it requires 30–60 minutes of pharmacist time per patient, a resource most practices don't have at prescription renewal.
The Beers Criteria lives in a PDF. Clinicians consult it manually, if at all. We wanted to automate that review entirely — running it in under 3 seconds, inside the EHR workflow, for every patient on 5+ medications — and make it available as an AI superpower on any FHIR-compatible EHR.
What It Does
Polypharmacy Safety Checker screens a patient's active medication list and conditions against five evidence-based safety frameworks:
- Beers Criteria Table 1 — always-avoid drugs in patients 65+
- Beers Criteria Table 2 — disease-drug contraindications (e.g. NSAIDs in heart failure, benzodiazepines in dementia)
- Beers Criteria Table 3 — dangerous drug-drug combinations (e.g. Warfarin + Ibuprofen → major bleeding risk)
- Renal-adjusted flags — severity escalates as eGFR drops below clinical thresholds
- Anticholinergic Cognitive Burden (ACB) scale — cumulative score predicting falls, delirium, and cognitive decline
The tool produces a 0–10 risk score, a severity-ranked flag list (critical / moderate) with reason and clinical recommendation for each flag, and a plain-English narrative formatted for physician review — all in under 3 seconds.
How We Built It
The system is split into two deliberate layers.
The AI layer — powered by the platform's LLM — handles everything language requires: extracting structured patient data from free-text descriptions, selecting the right clinical tool for the context, orchestrating FHIR credential injection, and presenting findings conversationally to the clinician. A pharmacist can describe a patient in plain English and the AI correctly extracts age, medication list, eGFR, and active conditions before a single safety check runs.
The scoring layer beneath it is entirely deterministic. This was not a limitation — it was the correct clinical engineering decision. Medication safety checks must be reproducible, auditable, and traceable to published evidence. An LLM that generates a flag it cannot cite is a liability in a clinical setting. Every flag our engine produces maps directly to a specific entry in the 2023 AGS Beers Criteria, the Indiana University ACB scale, or FDA drug labeling. No hallucinations. No fabricated interactions.
This division of labor — AI for language, deterministic logic for clinical safety — is how production clinical decision support should be built. The AI makes the tool usable by anyone. The engine makes it trustworthy enough to act on.
Three tools are exposed:
| Tool | Input |
|---|---|
CheckPatientSafety |
Plain-text (age, meds, conditions, eGFR) |
CheckBundleSafety |
Inline FHIR R4 Bundle JSON |
CheckFhirPatientSafety |
Live FHIR server via platform-injected credentials |
Stack: Python 3.13 · FastMCP · FastAPI · FHIR R4 · RxNorm (NLM RxNav API) · OpenFDA · Google Cloud Run · Prompt Opinion Marketplace
Potential Impact
Our hypothesis: if a Beers Criteria review runs automatically at every prescription renewal for patients 65+ on 5 or more medications, preventable adverse drug events drop measurably.
The tool makes that review instantaneous. A pharmacist review today costs $100–300 per patient encounter and takes 30–60 minutes of lookup time. This tool eliminates the lookup entirely, running a complete 52-drug Beers Criteria check, 12 dangerous combination checks, eGFR- adjusted renal flags, and anticholinergic burden scoring in under 3 seconds — inside the EHR workflow, not as a separate consultation.
The immediate target is clinical pharmacists and hospitalists conducting medication reconciliation at discharge and prescription renewal. The longer-term target is embedding this check into every ambulatory care renewal for patients 65+, where the volume of unchecked polypharmacy is highest and the consequences of a missed flag are most severe.
Feasibility
The tool is live today. It is deployed on Google Cloud Run, published on the Prompt Opinion Marketplace, and tested against HAPI FHIR — the reference FHIR R4 server used in hospital system integrations.
FHIR R4 is mandated for all US EHR vendors under the 21st Century Cures Act. Any Epic, Cerner, or athenahealth system that exposes its FHIR API can connect to this tool without a custom integration — no vendor negotiation, no ETL pipeline.
Privacy and compliance: No patient data is stored or transmitted beyond the request session. The scoring engine runs on public-domain clinical data only — CMS Part D, AGS Beers Criteria public categories, Indiana University ACB scale, and FDA OpenFDA. There is no patient data at rest, no model training on patient records, and no HIPAA surface area beyond the ephemeral request.
Challenges
FHIR condition code resolution was the hardest problem. Real FHIR servers — including HAPI FHIR — return conditions coded in SNOMED CT by default, not ICD-10. Our disease-drug flag data uses ICD-10. We built a two-stage resolution pipeline: prefer ICD-10 from structured FHIR coding, fall back to a curated display-name → ICD-10 lookup table covering 130+ conditions for SNOMED-only resources. Beers Table 2 flags now fire correctly regardless of what coding system the EHR uses.
MCP transport debugging took significant iteration. The streamable-http transport uses a persistent SSE stream for tool results. A logging middleware that buffered GET responses was silently deadlocking all tool call results — held until the SSE connection closed, causing the platform to time out and retry. The fix was detecting SSE streams and passing them through untouched.
RxNorm normalization at scale — with 9 medications, the first cold request hits the NLM RxNav API up to 9 times. We added a two-layer cache (in-memory + disk) so subsequent requests for any previously seen drug resolve in microseconds, keeping total response time under 3 seconds even for high-polypharmacy patients.
What We Learned
- Deterministic scoring is the right model for clinical safety — LLM-generated clinical flags are a liability without a citation. The right architecture is AI for language, deterministic code for decisions that must be auditable.
- FHIR R4 in production is messier than the spec — code systems vary by vendor, display names are inconsistent, and defensive parsing is essential. Assuming ICD-10 will come from a FHIR server is wrong.
- MCP's streamable-http transport has non-obvious SSE semantics — any middleware that buffers the GET response body will deadlock all tool result delivery silently.
What's Next
- Synthea-generated patient profiles for richer real-world demo scenarios
- Deduplication of flags when multiple Beers criteria fire on the same drug
- Expand disease-drug contraindications beyond the current 12 conditions
- Validated integration test against a live Epic sandbox FHIR endpoint

Log in or sign up for Devpost to join the conversation.