-
-
1
-
2
Inspiration
Prediction markets are one of the most efficient mechanisms for aggregating collective intelligence into prices. Polymarket on Polygon and Kalshi on Solana together represent over $1B in daily volume — but they're fragmented.
The same event ("Will the Colorado Avalanche win the Stanley Cup?") is priced at 20.5% on one platform and 10% on another. That's a detectable, exploitable inefficiency.
Meanwhile, LLMs have shown remarkable capability in probabilistic reasoning when properly prompted. Research from Science Advances (2024) demonstrated that ensembles of 12 LLMs match the accuracy of 925 human forecasters. But raw LLM outputs are systematically biased — RLHF training pushes them toward hedged 50/50 estimates.
We hypothesized that combining multi-model ensembles with probability calibration and superforecaster prompting could create a system that consistently finds edges the crowd misses.
The Synthesis.trade API was the missing piece — a single integration point for both Polymarket and Kalshi data, wallets, and order execution. Instead of managing two chains, two APIs, and two wallets, we built everything on one unified layer.
What It Does
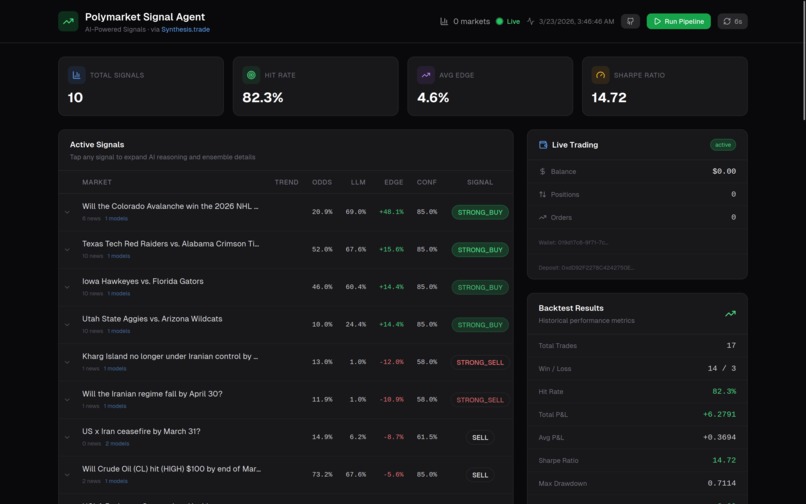
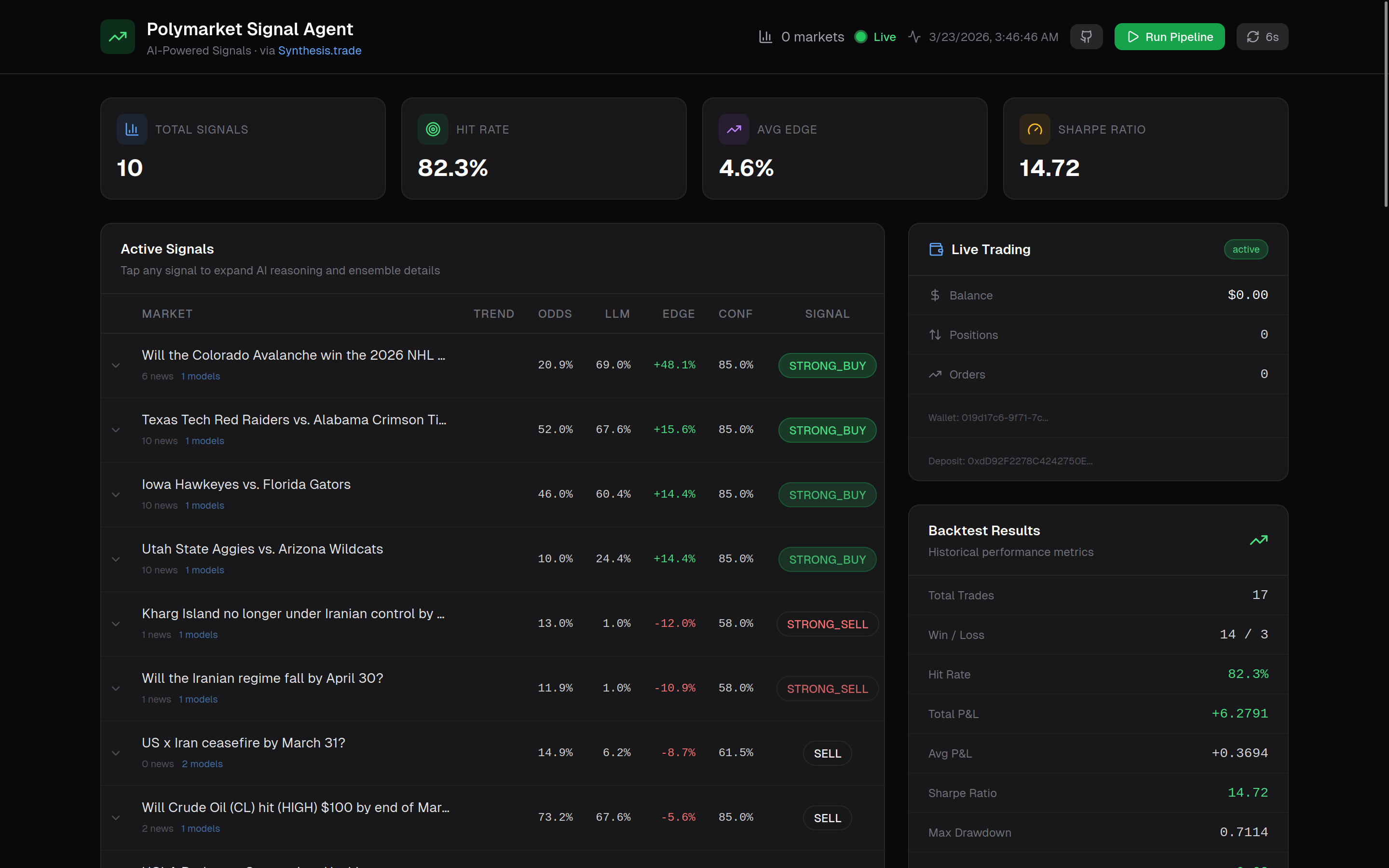
Polymarket Signal Agent is a complete AI trading pipeline:
1. Market Discovery — Fetches 50+ live events from Polymarket and Kalshi via Synthesis.trade's unified API. Flattens nested event/market structures, filters extreme tail odds (<10% or >90%), and selects the highest-volume markets for analysis.
2. News Intelligence — For each market, extracts keywords from the question and searches Google News RSS for real-time context. Articles are deduplicated by title hash and cached for 6 hours to avoid redundant API calls.
3. Multi-LLM Ensemble Analysis — Each market is analyzed by three models via Groq's inference API:
- Llama 3.3 70B (primary, highest reasoning quality)
- Llama 3.1 8B (fast, provides diversity)
- Qwen3 32B (different architecture, different training data)
Each model follows a superforecaster prompt:
- Identify the base rate
- List evidence for and against
- Adjust from base rate
- Commit to a decisive estimate
The system takes the median probability across models for robustness.
4. Probability Calibration — We apply Platt scaling:
( P_{calibrated} = \frac{1}{1 + e^{-1.5 \cdot \text{logit}(P_{raw})}} )
This pushes:
- 0.60 → 0.65
- 0.70 → 0.78
5. Signal Generation — Edge is calculated as:
( \text{Edge} = P_{calibrated} - P_{market} )
Signals are classified into STRONG_BUY, BUY, HOLD, SELL, STRONG_SELL. Position sizing uses Kelly criterion:
( f^* = \frac{p \cdot b - q}{b} \times 0.25 )
Capped at 5% per market.
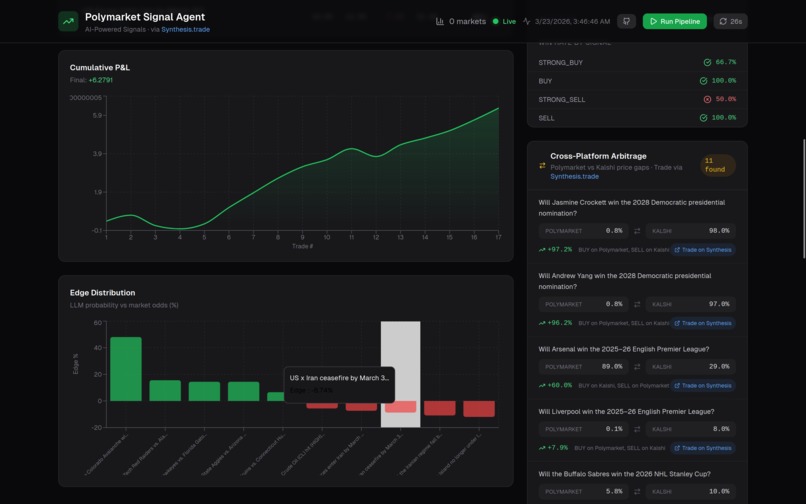
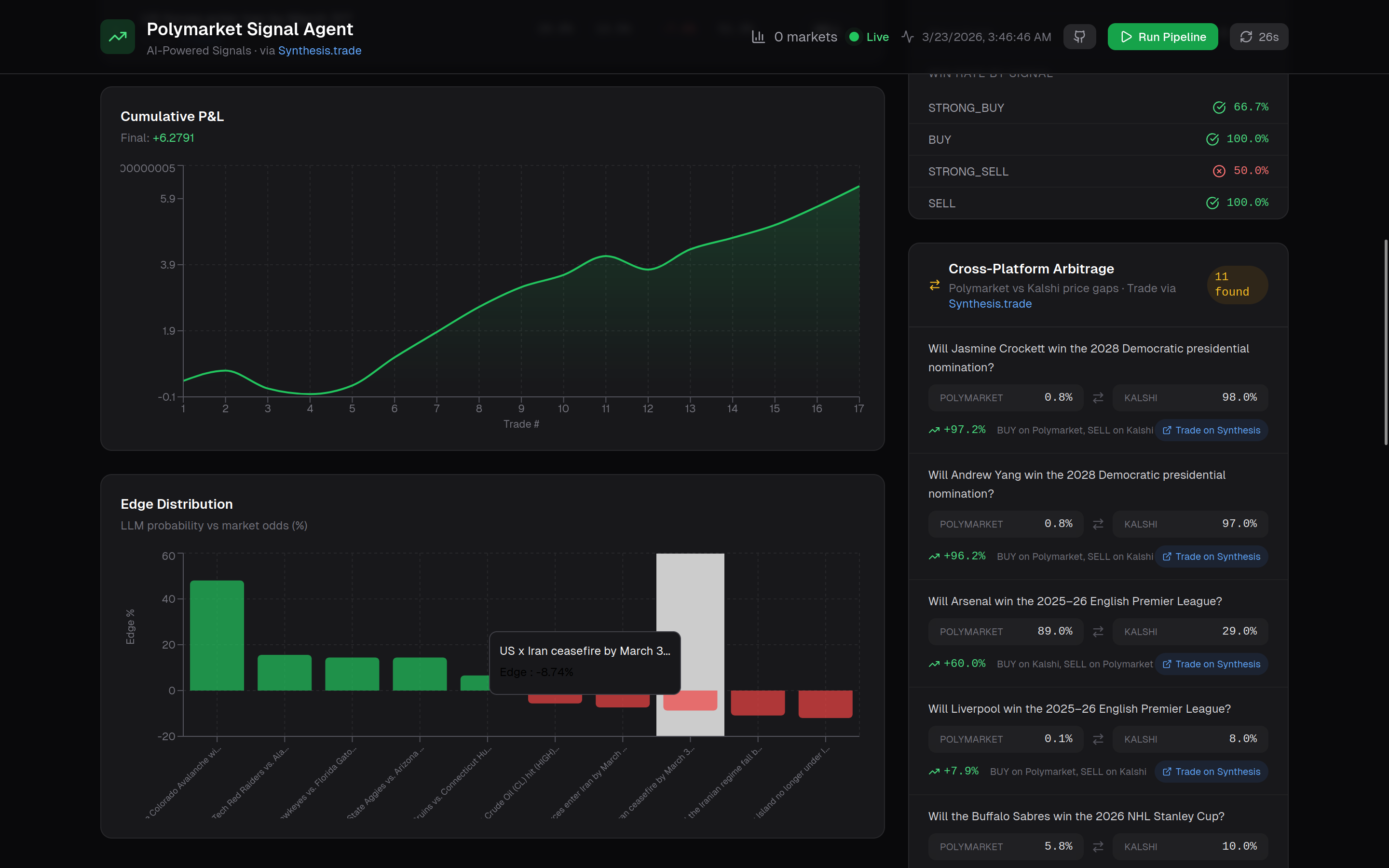
6. Cross-Platform Arbitrage — The system scans 664 Polymarket and 709 Kalshi outcomes, matches by name, and verifies via normalized title similarity to eliminate false positives.
Example opportunities:
- Buffalo Sabres: 5.8% vs 10.0% (+4.2%)
- Luka Doncic MVP: 8.3% vs 12.0% (+3.7%)
- Dallas Stars: 9.0% vs 12.0% (+3.0%)
7. Trade Execution — Automatically creates Synthesis accounts, wallets, and API keys. Trades can be executed via CLI or dashboard with one-click BUY/SELL.
8. Real-Time Dashboard — Next.js 14 trading terminal with:
- Run Pipeline button
- Live progress tracking (7 stages)
- AI reasoning panel per signal
- Arbitrage panel
- One-click trading
- Auto-refresh every 30 seconds
How We Built It
Architecture:
Python signal engine (14 modules) + Next.js dashboard (13 components, 10 API routes). Communication via JSON files — no database required.
Synthesis.trade Integration:
Unified endpoints:
GET /api/v1/polymarket/marketsGET /api/v1/kalshi/marketsPOST /api/v1/walletPOST /api/v1/wallet/pol/{id}/order
Single API, single format, both platforms.
LLM Pipeline:
Groq API via OpenAI SDK. Structured prompting (~400 tokens). Robust JSON parsing with multiple fallback strategies.
Dashboard:
Next.js App Router. Pipeline triggered via child_process.exec. Status tracked via JSON polling every 1.5s.
Challenges We Faced
- LLM Probability Calibration: Raw outputs clustered around 0.4–0.6. Platt scaling provided the most effective correction.
- Cross-Platform Matching: Naive matching caused false positives. We implemented normalized title similarity (>25% overlap).
- Groq Rate Limits: 100K tokens/day constraint required fallback to 2-model ensemble.
- Synthesis API Structure: Nested event-market structures required flattening and filtering.
- Token ID vs Condition ID: Trading required correct token IDs, not condition IDs — fixed via full pipeline tracing.
What We Learned
- Ensemble diversity > model size
- Calibration is critical for actionable signals
- Cross-platform arbitrage is real and persistent
- Unified APIs accelerate development dramatically
- Kelly criterion is essential for risk management
What's Next
- Live performance tracking
- WebSocket real-time updates
- Whale wallet tracking
- Multi-chain simultaneous execution
- Fine-tuned calibration using resolved market data
Built With
- feedparser
- framer-motion
- groq
- httpx
- kalshi
- llama-3.3
- next.js
- polymarket
- python
- qwen3
- recharts
- sonner
- synthesis.trade
- tailwind-css
- typescript


Log in or sign up for Devpost to join the conversation.